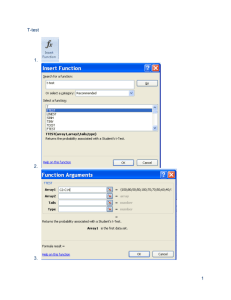
LGCS 121: Psycholinguistics Lexical decision programming To get a
advertisement

LGCS 121: Psycholinguistics Lexical decision programming To get a sense for how to design and program an experiment, we’ll be programming a pilot lexical decision experiment. The lexical decision task is a task in which a subject must decide whether a string of letters is a word of English (e.g., horse) or not (e.g., troim) as quickly as possible. There are many variations, e.g., semantic categorization, but the basic task is pretty much the same in most cases. You’ll want to decide on an experimental hypothesis and a suitable manipulation – the crucial difference in materials that you want to test. Since we can’t test every English word on a subject, we’ll need to sample words while controlling for possible confounds between the groups. Sampling just means that we’re picking out a manageable, representative portion of a population to test. A confound is a difference in experimental items (or procedure) that could possibly explain the results in different way than the experimental hypothesis. In other words, having confounds prevents you from concluding that the results confirm or disconfirm your experimental hypothesis, since there are other possible explanations for the result of interest. Suppose you want to test the effect of frequency on lexical decision times and accuracy – subjects are known to respond more quickly and accurately to more frequent words. Your manipulation is frequency and so you want to make sure that there is a difference in frequency between your items. For concreteness, call the list of low frequency words the Low condition and the list of high frequency words the High condition. To get a measure of frequency, you could go to the English Lexicon Project, which has many lexical characteristics for words. Use the HAL or SUBTLEX frequency measure rather than the outdated Kucera-Francis (KF) measure. We’ll discuss how to use ELP more in class. http://elexicon.wustl.edu/ One easy confound to control for is word length. You can limit yourself to words of only one length, or have even variation across Low and High. To determine whether the Low and High conditions differ, you enter the values into an Excel sheet and use the TTEST() function to compare values. For each manipulation (experimental variable) and control you consider, you should collect the mean for the each condition, the standard deviation (the amount of variation in your items), and run a t-test, which is a simple test comparing the means of two lists to estimate whether they are likely to be drawn from the same population (in which case the means do not differ significantly) or not (in which case they do differ significantly). For example, suppose I have 10 items in each of the Low and High conditions in Excel. I’ve created some numbers here on the next page. (See Excel sheet for formulae.) Item Low 1 2 3 4 5 6 7 8 9 10 High 12 5 100 234 98 11 3 54 44 87 982 4300 436 7784 209 3212 555 332 1200 6500 You can take the mean by using the AVERAGE() function and giving the array of values as its argument. Low High = AVERAGE(B2:B11) = 64.80 = AVERAGE(C2:C11) = 2551 The standard deviation can be calculated in much of the same way: Low High = STDEV(B2:B11) = 70.78 = STDEV (C2:C11) = 2781.46 To test whether the two groups are significantly different in terms of frequency, you can use a t-test which takes 4 arguments: = TTEST(array1, array2, Tails, Type) In the example above, array1 is simply the array corresponding to the Low items, B2:B11, and array2 corresponds to the High items C2:C11. The value for Tails depends on what you’re testing, but we can just use a two-tailed test in all cases here. So set Tails to 2. Finally, we can set the Type to 3 (for two-sampled test, without assuming equal variance). Note that if you want to control for confounds and are looking for no difference between samples, use Type = 2, since you’ll be assuming that the samples have the same variance (that is, are distributed in roughly the same shape). = TTEST(B2:B11, C2:C11,2,3) which gives us a value p < 0.05, indicating that the difference of means between Low and High is likely to have been sampled from different populations. That is, the mean differences are genuine. You can read more about the t-test here: http://office.microsoft.com/en-us/excel-help/ttest-HP005209325.aspx http://en.wikipedia.org/wiki/Student's_t-test To report this difference, you could write something like: In a paired t-test, items from the Low condition (M = 64.80, SD = 70.78) were significantly less frequent than items from the High condition (M = 2551, SD = 2781.46), p < 0.05. In addition, your experiment should have enough fillers to mask the manipulation from the subject. Ideally, you’ll have an even number of Yes and No responses in the experiment, so that subjects don’t develop a strategy (for example, a bias towards Yes responses if the majority of items are genuine words). So, if you’re showing your subjects 20 words each, then you should have 20 fillers, for 40 items total. You’ll want to think carefully about how to describe the experiment to your subjects. It’s crucial that they understand the task well enough before starting the experiment. I recommend programming in written in instructions and a practice session for them to complete before starting the task. You may wish to give the instructions to a friend to spot any ambiguities or misleading language. Write up, due October 11. You should write up a very short report (3-4 pages) detailing what you’ve done. The report should have the following sections. Please use the section numbering indicated here. 1. Introduction Lay out the background here along with any assumptions you’re making. Cite any relevant work and clearly state your hypothesis and the prediction you are testing. 2. Experiment 2.1 Materials and Method Provide examples of the items you used, and the number of items presented, along with fillers. Give means, standard deviations, and t-test probabilities for relevant lexical characteristics. Describe your method. 2.2 Participants How many people did you test? How did you recruit and compensate them? Did you exclude any one? If so, why? 2.3 Results Briefly describe your results in terms of means, standard deviations, and ttest probabilities for reaction times (time it took to make the lexical decision). Report the percent accuracy for the entire experiment and by condition. Provide a graph to illustrate the results. 3. General discussion What can we conclude from your experiment? What open questions are there? 4. References Complete citations in APA format if possible: http://myrin.ursinus.edu/help/resrch_guides/cit_style_apa.htm The writing style should be simple, impersonal, and direct. In addition, you’ll need to provide your program, the items, any data you collected, and the Excel sheet you used to calculate the means, standard deviations, and t-tests.