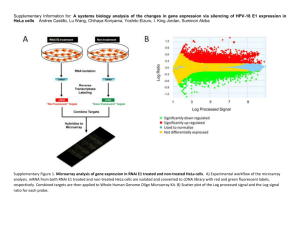
View/Open - AUC DAR Home - The American University in Cairo
advertisement

The American University in Cairo School of Sciences and Engineering META-ANALYSIS OF MICROARRAY DATA TO ASSESS GENDER BIASED DIFFERENTIAL GENE EXPRESSION IN HEPATIC TISSUE A Thesis Submitted to The Biotechnology Graduate Program In partial fulfillment for the pre-requisite requirement for full admission to the Ph.D Program in Applied Sciences By: Amira ElBakry Under the Supervision of: Dr. Rania Siam Chair of the Biology Department May/2015 ACKNOWLEDGMENTS My unreserved gratitude goes to Dr. Rania Siam, for her unconditional support, invaluable help and constant encouragement. Thank you for making this thesis possible, and for pushing everything forward for me and with me. Working with you is a pleasure and a privilege. Additionally, Mustafa Adel has provided much-needed help in many aspects of this thesis. Thank you for taking the time, putting the effort, and always replying to my emails and answering my many questions. Appreciation is directed to Dr. Ahmed Moustafa, for supporting my idea and his invaluable coaching in bioinformatics. I learned an incredible amount in a very short time. Special thanks to Dr. Sherif El-Khamisy for inspiring this thesis, it was his idea I built most of the foundation for the work on. Also, acknowledgment is due for Ali El Behery, for helping me multiple times with my hopeless programming and resolving every single error. Also, my appreciation for Yasmeen El Howeedy, for taking time to share her experience and providing valuable help. Thank you for everyone in the biology department that made my day easier, happier or just listened to my complaining. Finally, my eternal gratitude goes for my family, for their endless support every step of the way. ii ABSTRACT Hepatocellular carcinoma (HCC) is the second deadliest cancer globally, and with an estimated 782,000 new cases in 2012, it is the fifth most common cancer in men and ninth in women. HCC is of particular concern in Egypt because of the high prevalence of Hepatitis C Virus (HCV). Due to its poor prognosis, HCC is the leading cause of cancer-related deaths in Egypt. A gender disparity is observed in liver cancer cases, with higher prevalence in men by three to five fold. This sex bias is even more pronounced in mouse models of HCC, which was found to be sex hormone-dependent. Some studies have attempted to elucidate the molecular mechanisms of this disparity; but with inconclusive and sometimes contradicting outcomes, they remain largely unresolved. Understanding the natural protective mechanisms in females would allow for the development of preventative and therapeutic strategies for patients at risk for HCC or already inflicted with the disease. In this study, we applied a meta-analysis approach on already available microarray data from human normal liver tissues to identify differentially expressed genes between males and females. Microarray datasets were downloaded from the Gene Expression Omnibus database, Robust Multiarray Average pre-processed and analyzed for differential expression. The combination of 2 distinct datasets and analysis using a p-value cut-off of 0.05 and fold change cut-off of 2 revealed male up-regulated genes including RPS4Y1, EIF1AY, CYorf15B, UTY, DDX3Y and USP9Y. Female up-regulated genes included XIST, PNPLA4 and PZP. Our results confirm gender-specific differential expression patterns found in other tissues and call for further investigation using a larger sample size and more sensitive approaches such as RNA-Sequencing and, targeted protein-level studies. iii TABLE OF CONTENTS LIST OF TABLES .............................................................................................................................................. v LIST OF FIGURES ........................................................................................................................................... vi ABBREVIATIONS .......................................................................................................................................... vii 1. Introduction .......................................................................................................................................... 1 1.1 Gender Bias in Hepatocellular Carcinoma .......................................................................................... 1 1.2 Molecular Mechanisms of Gender Bias in HCC................................................................................... 2 1.3 Studying Gene Expression using Microarrays ..................................................................................... 4 1.4 Microarray Data pre-processing ......................................................................................................... 6 1.5 Differential Expression Analysis .......................................................................................................... 8 1.6 Accounting for Batch Effects ............................................................................................................. 10 2. Materials and Methods ....................................................................................................................... 12 2.1 Data Collection and Processing ......................................................................................................... 12 2.2 Data Exploration and Differential Expression Analysis ..................................................................... 12 2.3 Dataset Merging and Batch Effect Removal ..................................................................................... 13 2.4 Gene ID conversion and functional annotation ................................................................................ 14 3. Results ..................................................................................................................................................... 14 3.1 Dataset Collection and Processing .................................................................................................... 14 3.2 Individual Dataset Analysis Using the T-test Method ....................................................................... 15 3.3 Individual Dataset Analysis Using the Limma Package and Bayesian statistics ................................ 16 3.4 Analysis of Merged Datasets Using the Student’s T-test .................................................................. 16 3.5 Batch Effects Removal ...................................................................................................................... 17 3.6 Gene Signature Validation ................................................................................................................ 18 4. Discussion............................................................................................................................................ 18 TABLES......................................................................................................................................................... 26 FIGURES....................................................................................................................................................... 35 REFERENCES ................................................................................................................................................ 43 iv LIST OF TABLES Table 1. Summary of the datasets of microarray studies using human normal liver tissue. ......... 26 Table 2. Sample information of three microarray datasets with gender information ................... 27 Table 3. Summary of differentially expressed probes found in all three data set and their corresponding gene names ............................................................................................................ 28 Table 4.Summary of differentially expressed probes identified in GSE14323 using the Limma Package ......................................................................................................................................... 29 Table 5. Differentially expressed probes identified in GSE 23343 using the Limma Package. ... 30 Table 6. Differentially expressed probes and their corresponding gene names, identified in merged datasets using the t-test method. ...................................................................................... 31 Table 7. Differentially expressed probes and their corresponding genes in dataset GSE14343 after batch effect removal using fRMA.. ...................................................................................... 32 Table 8. Differentially expressed probes and their corresponding genes in dataset GSE23343 after batch effect removal using fRMA. ....................................................................................... 33 Table 9. Differentially expressed probes and their corresponding genes in merged datasets after batch effect removal using fRMA or using ComBat .................................................................... 34 v LIST OF FIGURES Figure 1: Hierarchical Cluster Analysis of 3 microarray datasets…………………………….…35 Figure 2: Differentially Expressed probes in individual datasets (t-test)………………………..36 Figure 3: Differentially Expressed probes in individual datasets (Limma)……………………...37 Figure 4: Differentially Expressed probes in merged datasets…………………………………..38 Figure 5: Hierarchical Cluster Analysis of merged microarray datasets………………….……..39 Figure 6: Differentially Expressed probes in individual datasets after batch effect removal……40 Figure 7: Differentially Expressed probed in merged datasets after batch effect removal………41 Figure 8: Gene Signature Validation………………………………………………………….....42 vi ABBREVIATIONS ANOVA ComBat DAVID DDX3Y DEN DWD EIF1AY FC fRMA GEO HBV HCC HCV IL-6 KDM5D LARP4B MM PM PNPLA4 PRL PRLR PZP RMA RNA-Seq RPS4Y1 RVM SAM SVA TLR TNF-α USP94 UTY WT XIST Analysis of variance Combining Batches of Gene Expression Microarray Data Database for Annotation, Visualization and Integrated Discovery DEAD (Asp-Glu-Ala-Asp) box polypeptide 3Y Diethylnitrosamine Distance-weighted discrimination Eukaryotic translation initiation factor 1A-Y Fold Change Frozen robust multichip average Gene Expression Omnibus Heptitis B Virus Hepatocellular carcinoma Hepatitis C Virus Interleukin 6 (K)-specific demethylase 6A La ribonucleoprotein domain family, member 4B Mismatch Perfect Match Patatin-like phospholipase domain containing 4 Prolactin Prolactin Receptor Pregnancy Zone Protein Robust Multichip Average RNA Sequencing Ribosomal protein S4 random variance model significance analysis of microarrays Surrogate variable analysis Toll-like Receptor Tumor Necrosis Factor-α ubiquitin specific peptidase 9 ubiquitously transcribed tetratricopeptide repeat gene Wild Type X (inactive)-specific transcript vii 1. Introduction 1.1 Gender Bias in Hepatocellular Carcinoma Hepatocellular carcinoma (HCC) is one of the most common cancers in the world, with an estimated 782,000 new cases in 20121. HCC is the fifth most common cancer in men and ninth in women and with about 746,000 deaths in 2012, it is the second deadliest cancer globally 1. Risk factors for HCC include alcoholic liver disease, infection with Hepatitis C virus (HCV) or Hepatitis B Virus (HBV) , and aflatoxin exposure2. HCC is of particular concern in Egypt because of the high prevalence of HCV. A recent study showed that more than 91% of HCC patients surveyed tested positive for HCV 3, which is in agreement with a previous report showing that almost 89% of surveyed HCC patients were HCV positive4. Owing to its poor prognosis, HCC is the leading cause of cancer-related death in Egypt, and second in incidence to breast cancer 1. One important aspect of HCC is a global gender disparity, with a higher prevalence in men by two to four fold, despite equal exposure to risk factors such as HCV and HBV 5. This female protection seems to be hormone-dependent, as indicated by the rise in liver cancer incidence amongst women who undergo menopause 6. Furthermore, hormone replacement therapy in women is associated with lower HCC incidence 7. This sex bias is even more pronounced in mouse models of HCC, which was also found to be sex hormone-dependent 8,9 . HCC is chemically induced in mice using a post natal injection of diethylnitrosamine (DEN), which causes DNA damage and hepatocyte death. This triggers inflammatory responses from Kupffer cells, which further promotes compensatory hepatocyte proliferation and leads to tumor formation 10,11 . In experiments with DEN- induced HCC , almost all male mice develop the disease, while only 30% of female mice progress to HCC 9. This effect is significantly reduced 1 by estrogen administration or castration. On the other hand, ovariectomy and / or testosterone supplement significantly reduced female protection9. This disparity has also been shown to be androgen-receptor-dependent in DEN-induced HCC mouse models12. Mice lacking functional androgen receptors showed resistance to DEN-induced carcinogenesis, and females treated with testosterone showed a higher incidence of liver tumors than untreated females 12 . In another study, transgenic mice expressing Hepatitis B Surface Antigen and/or p53 were exposed to aflatoxin in different combinations 8. All male mice with these three risk factors developed tumors, compared to only 62% of females 8. Furthermore, males in all other groups developed HCC more frequently than their female counterparts. Some studies have addressed the molecular mechanisms of this disparity in an attempt to elucidate the underlying causes to this phenomenon, but the picture is far from complete. 1.2 Molecular Mechanisms of Gender Bias in HCC Liver cancer is strongly associated with inflammation13, and thus studies investigating the molecular mechanisms underlying the observed gender bias in HCC found links between sex hormones and inflammatory responses in the liver. In a key article published in 2007, Naugler et al. found that interleukin-6 (IL-6) plays an important role in promoting DEN-induced liver carcinogenesis in mice through signaling via a Toll-like receptor (TLR) adaptor protein 14 . Males had a higher level of serum IL-6 after DEN administration and a higher level of liver injury than females. IL6 -/- males had lower HCC incidence than wild type (WT), while no difference was observed between WT and IL6-/-. Estrogen administration to males and ovariectomized females reduced liver injury through suppression of IL-6 production. While this study identified the estrogen receptor ERα as the receptor responsible for this effect, this was later questioned by another group. Bigsby et al. 2 found that ERα status did not affect tumorigenesis in females, and its absence in male mice resulted in less tumors 15. Interestingly, estradiol treatment reduced the number of tumors in WT male mice, but not in ERα-/- mice, suggesting a protective effect of ERα only for exogenously administered estradiol 15. Another hormone, prolactin (PRL), has also been indicated as an important factor in HCC resistance in women. Hartwell et. al. found that the pituitary hormone PRL (expressed more in females) restricts innate immune responses in the liver by inhibiting c-Myc activation16. PRL was found to signal through a hepatocyte-predominant short-form prolactin receptors (PRLR-S) to inhibit IL-1β, TNF-α, and TLR-4 induced innate responses. PRL acts by ubiquitinating a group of proteins in a “Trafasome” thereby inhibiting their downstream interactions with c-Myc activating pathways. This is in contrast to previous studies which show no role for PRL in HCC gender bias. Tumor incidence in PRLR knockout was comparable to WT, and in famles, ovariectomy induced tumorigenesis regardless of PRLR status15. This difference has been attributed mainly to the biological differences between PRLR and PRL knockout mice. In an attempt to identify potential oncogenes and their role in sex-bias occurrence on a larger scale, one group used the sleeping beauty transposon system to screen for potential oncogenes in mice. They found that transposon insertions in the epidermal growth factor receptor (EGFR) gene were more common in tumors from male mice than female mice 17 . Additionally, gene expression analysis in human liver samples revealed differences in male and female liver tissues predominantly pertaining to inflammation, carcinogenesis and reproduction16. Together, these results indicate a role for sex hormones, pituitary hormones and the innate immune system in the gender disparity observed in HCC, the details of which remain largely uncharacterized. 3 The paradoxical results obtained by different groups highlight important points of consideration while studying this aspect of HCC. First, the use of DEN-induced HCC model represents a point of variation as the treatment regimen varies in dose, age of mice at administration, and time of sample collection post DEN administration. Another factor to be considered is the mice genetic background, which as demonstrated by Bigsby et al., affects the number of tumors obtained by a certain treatment and the sex-dependent response15. For example, ovariectomy did not affect the tumorigenesis in C57Bl/6J females, but showed an effect in the mixed background strain 129Ola-X-C57Bl/6J. Additionally, HCC in humans is largely associated with a other external factors2 (such as alcohol, viral infection, chemical exposure), which are not represented in animal models. Therefore, it is evident that while mice provide an invaluable experimental tool, they do not accurately reflect the pathogenesis of HCC in humans, nor the sex bias observed. A valuable source of information would be clinical samples from HCC patients and human liver tissues to provide a more accurate and reliable 1.3 Studying Gene Expression using Microarrays One way to extract valuable information from clinical data is to utilize already available genomewide microarray data from human liver tissues to identify genes with potential roles in the sex bias observed in HCC. High density oligonucleotide arrays represent a very useful tool for studying gene expression as they allow the quantitative detection of mRNA. Microarray chips, such as the Affymetrix GeneChip, use tens of thousands of synthetic oligonucleotides (25 bases long) that hybridize to specific sequences of target genes18,19. Commercially available platforms allowed the widespread use of microarrays for high throughput transcriptome studies, and the accumulation of large amounts of gene expression data. Microarray studies are often used to study disease pathogenesis or treatment effectiveness by comparing gene expression in normal 4 and diseased tissues, treated and untreated samples or multiple stages of one disease, among many other alternatives. These approaches allow the large-scale identification of genes that are up-regulated and down-regulated in experiment versus control, allowing subsequent downstream functional analyses. For example, microarray studies have been used to identify gene expression signatures in cancers of the colon20, prostate21, breast22, liver23,24 and lung25 to identify diagnostic and prognostic biomarkers and therapeutic targets. Public databases, such as the NCBI Gene Expression Omnibus (GEO)26,27 and ArrayExpress28 allow access to a huge number of microarray data. Although various gene expression studies addressed different aspect of HCC pathogenesis, only one study attempted to dissect the molecular basis of the observed gender bias. Hartwell et al. carried out gene expression analysis on 7 male and 7 female human liver samples to identify a gene signature that could be protective of females as compared to males16. Their findings distinguished about 500 genes that are differentially expressed between the 2 groups, many of which have functions in cell cycle, inflammation and cancer16. Our aim in the current study is to build on these results by using a larger sample size to define a more specific signature, which can be followed in patients that develop HCC. One approach to achieve this is to use data from multiple studies that are already published. However, lack of correlation between platforms and experimental variations among labs do not allow a direct comparison between heterogeneous studies 29,30. One way to overcome this is to carry out a meta-analysis of the data. Meta-analysis is a statistical approach, consisting of a set of statistical techniques that allow the combination of data from independent, but relevant, studies 31 . Combining data from various studies using a meta-analysis approach increases the statistical power to allow the detection of small, but consistent changes that are otherwise missed in single5 study analyses 32. Furthermore, statistical approaches directed to overcome heterogeneity among the different datasets increases the sensitivity and reproducibility of the result, when compared to individual studies33. Another advantage of meta-analysis is its relative low-cost, as the data are already available and many analysis tools are open-source. The success of this approach is evident by the increasing number of researchers employing it to generate novel information from already existing data, such as common transcriptional profiles or gene signature of certain cancers, and even new prognostic biomarkers 34–37 . Rhodes et al. used meta-analysis on 40 independent microarray cancer studies and identified a “meta-signature” of cancer transformation and progression35. In a more clinicallydriven approach, Mehra et al. combined 417 samples and identified GATA3 as a prognostic marker for breast cancer34. Also, Ewald et al. used patient-derived microarray data to identify pathways involved in the stage-wise progression of bladder cancer from papillary to muscleinvasive tumors38. In addition, efforts to compare and unify meta-analysis approaches and workflows have been emerging to enhance the applicability of such studies and enhance their outcome 31,39,40 . Overall, meta-analysis is a powerful approach to use already-available data to answer novel questions, which is what we aim to accomplish in this study. However, as explained below, careful consideration must be given to using public microarray datasets for differential expression analysis, owing to the heterogeneity of their experimental design, the platforms used, and the data processing methods. 1.4 Microarray Data Pre-processing The output of microarray experiments, i.e. raw data, has to be pre-processed in order to reach meaningful, informative values. Affymetrix microarray chips contain around 11-20 probes for 6 each gene, arranged in pairs known as “probe pairs”. Probe pairs consist of perfect match (PM), which match the target gene completely, and mismatch (MM) probes, which are the same sequences as PM probes, but with a mismatched base in the middle (13th base) to account for non-specific binding18. Therefore, in order to have a single expression value for each probe, the data from all probes in a probe set needs to be summarized in an expression value. In addition, normalization of the data is crucial to account for obscuring variations that occur during sample preparations, handling, production and processing of the arrays. One of the most widely-used methods for pre-processing of Affymetrix microarray data is the Robust Multichip Average (RMA) method. The RMA expression measure is generated by background correction of probe-level PM values, followed by quantile normalization of the data and then linear fitting using the median polish method, to generate log expression values 41. The quantile normalization approach utilizes information from all arrays with the goal of making the distribution of probe intensities the same for all arrays in a particular set analyzed 42. Therefore, it is important to process all arrays from an experiment together as one batch when using RMA. When compared to other normalization methods, such as non-linear and scaling methods (used in the Affymetrix algorithms), quantile normalization was most successful at reducing variance and produced the smallest distances between arrays in pairwise comparisons which remained constant across intensities42. It also performed better in terms of bias and speed. This improvement in performance could be attributed to using all arrays in the normalization process, rather than a single baseline, which is less representative of the complete data42. 7 Additionally, algorithms such as the Affymetrix MAS 5.0 algorithm and dChip software developed by Li and Wong rely on subtracting the MM signal to correct for non-specific binding 43 . However, RMA does not use the MM probes for subtraction, and relies only on PM values, as studies have shown that MM probes detect signal in addition to non-specific binding, and that methods utilizing PM- MM or PM/MM values add noise and result in a respectively 41,44 biased signal, . In a series of spike-in experiments, RMA was compared to other expression measures, such as Li and Wong’s model-based expression indexes (MBEI) and the MAS 5.0 signal, in which it performed better in 3 criteria: (1) precision, as estimated by the gene-specific standard deviations (SD) across replicates; (2) consistency of estimates for fold change; and (3) the specificity and sensitivity when using fold change to detect differential expression41,45. 1.5 Differential Expression Analysis The simplest way to identify differentially expressed gene is using the Fold Change (FC) indicator, which evaluates the average log ratio between 2 conditions or groups and considers gene with FC above a certain (arbitrary) threshold differentially expressed. For example, if the FC threshold is set at 2, genes that are found to be more abundant under one condition or less abundant in the other by more than 2 fold are considered to be differentially expressed. However, FC is not a statistical test; it does not provide any level of confidence and does not account for variance across samples. Therefore, it is important to employ a statistical method to account for this variance and to standardize differential expression. A simple and popular method to employ is a standard t-test, which has been widely used to detect differentially expressed gene for microarray studies46. The t-test is conducted for each gene and the error variance is estimated based on the log ratios. For each gene, a t-statistic is computed and then converted to a p-value. Typically, genes with p-values falling below a 8 specific threshold are considered significant. Despite the popular application of the t-test to microarray data analysis, this approach has its drawbacks, particularly with low-variance genes and small sample size, where some bias is introduced and the statistical power is compromised, respectively 47,48 . Consequent to these criticisms, numerous statistical approaches have been developed to address different areas of concern, in attempts to improve variance estimates, accuracy and statistical power. The abundance and variety of these methodologies make it difficult to decide on which method would is most effective in analyzing gene expression data and which method would be most appropriate to specific experimental settings. Fortunately, studies were designed to specifically address this issue, and some have utilized data in which the differentially expressed genes are already known (for example, using spike-in experiments) to evaluate the performance of statistical tests 47–50 . For example, one study has compared the performance of 8 statistical methods of variance modeling in gene expression data analysis: Welch's t-test, analysis of variance (ANOVA), Wilcoxon's test, significance analysis of microarrays (SAM), random variance model (RVM), Limma, VarMixt and SMVar 47 . Using Limma resulted in the best overall performance compared to the other 7 methods, where the most improvement was achieved compared to the t-test, especially with small sample size, and in terms of ease of use and speed of execution. Limma is a popular method used for microarray data analysis, which has recently been adapted for RNA-sequencing (RNA-Seq) data as well. The principal idea in Limma is the use of gene-wise linear model fitting to analyze an entire experiment as a whole 51 . The linear models are fitted to each row, and regression coefficients and standard error generated for the compared group. The parallel nature of gene expression experiments motivates the use of empirical Bayes statistics which allows sharing of information between genes to account for variances across 9 genes and samples to obtain Bayes posterior variance estimators51. The estimated sample variances are squeezed towards a common variance, leading to more stable inferences from small sample size52. In addition, the use of gene-wise linear modeling allows flexibility in handling different experimental designs. In testing for differential expression, empirical Bayes statistics, such as moderated t-statistic and p-values are generated for each coefficient of the linear model in order to assess the significance of these changes. Limma is able to reduce the false positive rate in genes with low variance and improve the power for detecting genes with large variances. The use of empirical Bayes statistics in Limma has been found favorable to other significance testing methods in gene expression analysis, and its performance favored especially with small samples49,50. 1.6 Accounting for Batch Effects Another important source of variation in microarray data that needs to be addressed is the variation introduced by non-biological factor that causes differences between samples, known as the “batch effect”. Batch effects are introduced when samples are run in different “batches”, which could be different runs, different days, using different reagents or different technicians 55 53– . Batch effects can affect the downstream processing of the data, resulting in lower power to detect real changes, or more the serious consequences of false or misleading biological conclusions. Although batch effects have been demonstrated in early microarray experiments 56, surprisingly, they have been reported only in small percentage of studies. For example, one study reported that out of 219 papers published using microarray data, less than 10% addressed batch effects 53. Moreover, upon examining data from 9 high throughput studies, Leek et al. found all of them had considerable batch effects, with substantial percentages (32.1-99.5%). While batch effects can be minimized through careful experimental design, the only way to avoid them 10 completely is by running samples as one batch. Therefore, several methods for batch effect removal have been developed, including Distance-weighted discrimination (DWD) 57 , mean- centering (PAMR)58, Surrogate variable analysis (SVA)59, Geometric ratio-based method (Ratio_G)60 and Combating Batch Effects When Combining Batches of Gene Expression Microarray Data (ComBat)54. When all these 5 methods were compared and performance assessed based on accuracy, precision and variation reduction (batch effect removal), using ComBat resulted in the best overall performance. In addition, ComBat was robust for handling small batches that other methods did not perform well with53. This is attributable to the empirical Bayes framework employed in the ComBat approach, which estimates location and scale adjustment parameters for each gene independently by borrowing information across genes to “shrink” the batch effect parameter estimates towards an overall mean of the estimates54. These estimates are then used to adjust the data for batch effects, providing robust adjustment for small batches (10<)54. Although normalization of microarray data does not account for batch effects, some modifications of existing methods attempt to address these effects in batches of datasets or single arrays that can be analyzed individually or after before combining them with others. The frozen robust multichip average (fRMA) is used to achieve the advantages of multichip processing to single-array analysis by using a large dataset of representative samples to create a reference distribution for the subsequent quantile normalization. Pre-computed estimates of probe effects are used in concert with data from the set being analyzed to generate the summary expression values. fRMA was found to perform similarly to RMA when the data was preprocessed as one batch, but outperformed RMA in terms of precision when analyzing multiple batches. 11 Using the above tools for analyzing gene expression data from human liver tissues, we aim to identify differentially expressed genes between males and females that could be responsible for the inherent HCC resistance in females, which would be a starting point for subsequent in silico analysis and in vitro and in vivo experiments. 2. Materials and Methods 2.1 Data Collection and Processing The NCBI GEO database ((http://www.ncbi.nlm.nih.gov/geo/) was searched for “human liver”, with the search filters set as follows: “Organism” set to “Homo sapiens”, “Data type” set to “expression profiling by array”, “Attribute name” set to “tissue to satisfy our inclusion criteria for whole-transcriptome studies using human tissues from normal livers. In order to unify gene IDs and normalization, we only selected data produced using Affymetrix chips. Studies using cell lines, animals, non-coding RNA profiling, or different platforms were excluded. For the selected datasets, raw (.cel) files were downloaded and pre-processed using the RMA method to generate expression value output41,45, which is summary measure of background-corrected, normalized log-transformed probe intensities. RMA was applied by implementing the “just RMA()” function in the Bioconductor Affy Package 61. As with all other statistical analyses used in this study, all methods were implemented in the R statistical computing environment (http://www.r-project.org/), and all packages are available from the open source Bioconductor project62,63 (http://www.bioconductor.org/about/). 2.2 Data Exploration and Differential Expression Analysis As an initial exploratory step, hierarchical cluster analysis was carried out using the “hclust” function in R, with the default method of complete linkage, which defines the distance between 2 clusters as the maximum distances between its components. Distance matrices were constructed 12 by using the Pearson distances between columns (1- Pearson’s correlation coefficient), and the analysis displayed as a dendrogram. To identify differentially expressed genes between male and female groups, we used 2 methods: a standard t-test between the 2 groups and the Limma Bioconductor package which implements linear modeling and Bayesian statistics51. Using the t-test, p-values were calculated for each probe, and a cut-off of 0.05 was set so that only probes with p-values below this limit are selected. Absolute fold change cut-off was set as 2, so genes which are up- or downregulated by at least 2 fold are selected. Probes that met both of these criteria were filtered for further downstream analysis. For the Limma Package, the “lmFit” function was used for the estimation of fold changes and standard errors through fitting a linear model, which is specific by the design matrix, for each gene52. The fitted model was then processed using the “eBayes” function to apply empirical Bayes statistical methods and generate statistics such as the moderated t-statsitic and its associated p-value, adjusted p-values for multiple testing and average log expression values52. The selection cut-off for differentially expressed genes was set to a p-adjusted value of 0.05 (using the Holm’s sequential Bonferoni multiple testing correction method)64. This ensures that errors introduced due to testing multiple hypotheses are corrected for and so minimizes false positives. 2.3 Dataset Merging and Batch Effect Removal The datasets were combined together using the inSilicoMerging Bioconductor package65, which allows the merging of different datasets and the use of different methods for batch effect removal 65 . Using this package, we used the ComBat approach, which utilizes empirical Bayes statistics 13 to correct for variations between arrays due to use of different methodology, or data generated in different laboratories, such as the case in this study 54. Another method for batch effect adjustment that was employed was the fRMA method, which allows pre-processing of individual datasets by using pre-computed probe effects and variances during the normalization process 66 . This way, individually fRMA-processed datasets can be computed without the need for further batch effect removal. Datasets were fRMA preprocessed using the “fRMA” function in the fRMA Bioconductor package, then combined using the inSiliocMerging package and then analyzed for differentially expressed probes using the Limma package. 2.4 Gene ID conversion and functional annotation To convert probe IDs to gene names and identify the location and function of these genes, The Database for Annotation, Visualization and Integrated Discovery version 6.7 (DAVID, http://david.abcc.ncifcrf.gov/) tool was used 67,68. Each list of probes was copied and pasted into the Gene List Manager and analyzed either by the Gene ID Conversion tool to identify the gene corresponding to the selected probes or the Gene Functional Classification tool to group genes into functional groups. 3. Results 3.1 Dataset Collection and Processing The GEO search yielded 739 studies on Januray 2015, of which 7 studies were selected (summarized in Table 1) that provided expression data for normal human liver. All selected datasets were generated using the Affymetrix Human Genome U133 Plus 2.0 Array, except GSE14323, which was generated using the Affymetrix GeneChip Human Genome U133A 2.0 14 Array. Out of those, only 2 (GSE2334369, GSE1495170) had gender information readily available in the database. We contacted the principal author for each study, and only the author for GSE143323 provided the missing gender data 71 . Consequently we had a total of 3 studies qualifying for the subsequent analysis. Collectively, the datasets included 27 male and 19 female normal liver samples, adding up to 46 samples in total (summarized in Table 2). As the data provided in the expression matrices was processed differently by each group, raw .cel files were downloaded and pre-processed using the same RMA method45. 3.2 Individual Dataset Analysis Using the T-test Method For each dataset, hierarchical clustering analysis was performed, using the complete linkage method72, and plotted as dendrograms (Figure 1). Hierarchical clustering for all three datasets did not generate a distinct gender cluster (data not shown). Each dataset was then divided into 2 groups of male and female samples and compared using a t-test statistic and FC. A cut-off of 0.05 for p-value and 2 for FC was used to filter the probes that were differentially expressed between the 2 groups. The data are represented in a form of a heat maps depicting up-regulated and down-regulated probes in each dataset (Figure 2). For dataset GSE14323, a total of 6 probes were deferentially expressed and in GSE23343 a total of 19 deferentially expressed probes were identified. Finally, dataset GSE14951 showed only 2 differentially expressed probes, that did not produce complete segregation of the 2 groups. The DAVID67,68 tool was used to map the probe ID to genes names. Table 3 summarizes the differentially expressed probes in all datasets, highlighting their overlapping probes and their corresponding genes. Since multiple probes are used to monitor the same gene, the total number of genes is sometimes smaller than the number of probes. Therefore, for GSE 14323, 6 probes corresponded to 5 genes including genes involved in spermatogenesis, X-inactivation and protein biosynthesis. For GSE23343, 19 probes 15 corresponded to only 11 genes, including genes involved in hexose metabolism, histone demethylatoin and protein deubiquitination. Only one gene was found to be differentially expressed in all three datasets, which is the Ribosomal protein S4 (RPS4Y1), a Y-linked gene. Most of the genes found were either Y-linked or X-linked, with only 3 out of 20 found on autosomes. Additionally, none of the genes in all datasets clustered into functional groups when using the DAVID gene functional classification tool. Finally, for the apparent heterogeneity of the GSE14951 dataset sample pool, it was excluded from further analysis. 3.3 Individual Dataset Analysis Using the Limma Package and Bayesian statistics The Limma Bioconductor package51 was used to further analyze the data as an alternative method to determine differentially expressed genes between the 2 groups in 2 datasets: GSE14323 and GSE23343 (figure 3). For GSE14323, 9 probes were found to be differentially expressed which included 5 of the 6 probes found by the t-test method. The 4 “new” probes were already identified for the other dataset (GSE23343) using the t-test. On the other hand, only 8 probes were indentified for GSE23343, and again, considerable overlap was observed, as 7 out of the 8 probes were also differentially expressed among the 19 probes identified in the t-test method (data summarized in tables 4 and 5). Using the Limma package added only one new gene, which is La ribonucleoprotein domain family, member 4B (LARP4B), found on chromosome 10. 3.4 Analysis of Merged Datasets Using the t-test To test if combining these 2 datasets would provide additional information, or allow for the detection of changes that were not previously detected, the 2 datasets were merged together and a t-test was used to identify significantly up- or down- regulated probes (figure 4). Ten probes were identified to be differentially expressed, corresponding to 7 genes. All of these probes have 16 been identified in individual dataset analysis, and the genes they correspond to are Y- or Xlinked genes, with the exception of just one (summarized in table 6). A hierarchical cluster analysis of the merged datasets resulted in the clustering of the 2 datasets into separate groups (figure 5), regardless of the gender of the sample 3.5 Batch Effects Removal To correct for differences between data generated in different laboratories, or at distinct time periods, various batch effect removal tools were used. Two methods were employed to correct for batch effect correction: either the fRMA normalization66 prior to merging the datasets or using the ComBat54 tool after merging the datasets. In both cases, the Limma package51 was employed to identify differentially expressed genes. For GSE14323, 12 probes were identified, corresponding to 9 genes (figure 6A). Three new genes for this dataset were identified after batch effect removal: patatin-like phospholipase domain containing 4 (PNPLA4), ubiquitously transcribed tetratricopeptide repeat gene (UTY), and ubiquitin specific peptidase 9 (USP94) (table 7). PNPLA4 is X-linked while UTY and USP94 are Y-linked. Also, USP94 was identified before for the other dataset using Limma. For GSE23433, 9 probes were found to be differentially expressed (figure 6B). As shown in table 8, these probes correspond to only 4 genes, none of which are new compared to previously identified probes for this dataset. After merging the 2 fRMA-normalized datasets, we obtained 10 differentially expressed probes figure 7). These corresponded to 8 genes, 7 of which were sex-chromosome linked, and all of which have been already identified in earlier individual dataset analyses. Using the ComBat method for batch effect removal, 13 probes were identified as differentially expressedcorresponding to 10 genes, with considerable overlap with those identified using fRMA (table 9). 17 Out of these ten, only one was not previously identified for either dataset, which is lysine (K)specific demethylase 6A (KDM5D), an X-linked gene. 3.6 Gene Signature Validation Recently published microarray data showed around 500 genes to be significantly differentially expressed between normal male and female human liver tissue16. Since our analysis did not reveal gender bias in human liver tissues gene expression, we tested if this gene set would produce a similar signature using our two datasets. The gene set was successful in distinguishing between their male and female samples, as they clustered into two distinct classes, but there was no clear signature of up- and down-regulated genes that could be distinguished. 4. Discussion We used data from microarray studies of human liver tissue to compare female and male gene expression and identify differential expression patterns. We identified a subset of X- and Ylinked genes that are up-regulated in females and males, respectively. As microarray data available from public data bases are found in a host of different formats, it is usually recommended to start any analysis with raw files to be pre-processed in a unified manner, to make the output comparable. We chose the RMA pre-processing approach due to its effectiveness and precision, as it is becoming the method of choice for Affymetrix microarray data processing. The initial clustering of the individual datasets did not show any gender-based segregation, but as the analysis was done for all probes for each dataset, subsets of differentially expressed genes could not be determined or visualized using this exploratory step. Therefore, the t-test statistical analysis was carried out to identify differentially expressed genes between males and females. Although using the t-test for this application has been criticized, it was used in the 18 initial exploration of the data because the experimental design is simple (only 2 groups compared, representing 2 conditions) and also for comparison to other methods. Furthermore, the fold change was used as an additional filtering criterion in the selection for biologically meaningful differences. Although the number of identified probes was small for each dataset (19 for GSE23343, 6 for GSE14323, and 2 for GSE14951), there was considerable overlap between them, indicating consistency for those genes. The most notable is RPS4Y1, that is up-regulated in males in all datasets, which is not surprising given it is a Y-linked gene (functional analysis for relevant probes will be discussed in later sections). To verify these results and refine our analysis by using improved statistical approaches that are more appropriate for small sample size, we used the Limma package for differential expression. The Limma package has been shown to be superior in performance and accuracy than various other statistical and increased power compared to the t-test. When we used Limma for individual dataset analysis, we identified more probes for GSE14323 and less for GSE23343, and overall identified just one new gene: LARP4B, an autosomal gene found on chromosome 10. It is worth noting that the cut-off used for Limma was a p-adjusted value that corrects for multiple testing, which is a stricter cut-off than using standard p-values in a t-test. This indicates that Limma is indeed more powerful than the t-test, and was able to detect changes that are more significant than the t-test could account for, and therefore Limma was used for all subsequent differential expression analysis. This would also explain the lower number of probes obtained for GSE23343. Similar to the individual analysis using the t-test, considerable overlap was found between the differentially expressed genes identified using Limma for the 2 datasets. Merging the two datasets together in a “meta-analysis” approach is expected to increase the statistical power and allow for the detection of other small changes in gene expression. 19 However, using a t-test and fold change to filter out differentially expressed genes did not add any new probes compared to those identified by individual analysis. To further explore the data, a hierarchical analysis revealed that the datasets clustered into 2 different groups, regardless of the gender. This indicates that non-biological differences arising due to the different origin of the samples (i.e. batch effects) are interfering with the analysis and could be obscuring genderspecific changes. Therefore, before carrying out any further analysis on the merged datasets, we used batch effect removal tools to overcome this variation. For this purpose, 2 methods were used: fRMA and ComBat. fRMA was used to preprocess the raw data for both sets before merging. The advantage of this approach is that each set is analyzed individually and more datasets can be added to the analysis without the need to repeat pre-processing or batch effect removal steps that were already done. For GSE14323, three new genes were identified using Limma, while none were newly found for GSE23343. This could mean that the inter-sample non-biological variations are marginal, or that these batch effects were not obscuring considerable biological changes. Finally, for the purpose of the meta-analysis approach we are employing in this study, the 2 datasets were merged and processed using ComBat for batch effect removal and limma for the identification of differentially expressed genes. This was compared to merging the fRMAprocessed datasets. Again, similar previous results, merging the fRMA datasets did not result in detecting new or different genes, and using ComBat only added one new gene: KDM5D. Throughout our analysis, the differences in output we observed were obtained when we used different statistical methods, e.g. t-test versus Limma, or RMA versus fRMA or ComBat. Merging the datasets using the same pre-processing and downstream analysis algorithms resulted in almost the same outcome, which indicated that merging the 2 datasets together does not 20 provide additional power to the analysis and does not add information that would have been otherwise undetected. However, we only used 2 (relatively small) datasets, with sample sizes below 25 for each group, which may have reduced the power of the study. Compared to the ~500 genes identified by Hatrwell et al. to be differentially expressed between males and females in human normal liver tissues, our identified genes are very few. Although using these genes in hierarchical analysis allowed us to cluster male and females in each dataset, they did not exhibit any consistent pattern for up-and down-regulated genes. However, we examine below the genes that were found in common between this study and ours, and additionally, genes that were found to be consistently deferentially expressed in our analysis. For the male-dominated genes, we identified 6 that are consistently found to be up-regulated in males: RPS4Y1, EIF1AY, CYorf15B, UTY, DDX3Y and USP9Y, all of which are Y-linked. The first three were also found to be up-regulated in males by Hartwell et al. The most prominent gene that is identified by all approaches employed in this study is RPS4Y1, which is part of the 40S ribosomal small subunit73. The sex-bias in RPS4Y1 expression was observed in human brain74, heart75 and was found to be pronounced in human prostate cancer tissues and cell lines76. RPS4Y1 has a homologue on the X chromosome, RPS4X, which is known to escape Xinactivation, but was not found to be differentially expressed in our sample pool73. Therefore, upregulation of RPS4Y1 seems to be tissue non-specific, and its role in any potential tumor transformation is unknown. DEAD (Asp-Glu-Ala-Asp) box polypeptide 3Y (DDX3Y) is an RNA helicase that is essential for spermatogensis. DDX3Y was found to be widely transcribed but the protein was only found in the testis77. The X-linked homologue, DDX3X is also ubiquitously expressed and both function as nucleo-cytoplasmic shuttles for RNA77,78. DDX3Y was also up-regulated in 21 human heart, while DBY (another member of the DEAD box protein family) was also upregulated in male brain tissue. Another protein that is important for spermatogenesis is USP9Y, is ubiquitously expressed in embryonic and adult tissues and is found up-regulated also in brain, heart and prostate tissues of males74–76. It is a ubiquitin-specific protease that functions in the deubiquitination of target proteins, and thus plays a role in protein turnover and regulation 79,80. Eukaryotic translation initiation factor 1A-Y (EIF1AY) is a translation initiation complex that interacts with the ribosome, and is required for achieving the maximum rate in protein biosynthesis81. It also may function in stabilizing the binding of the initiator Met-tRNA to 40S ribosomal subunits82. UTY is also found to be up-regulated in male prostate, heart and brain tissues, and it encodes a protein with tetratricopeptide repeats that has been found to have multiple splice variants, the functions of which are unknown83. It has been found to code for a male-specific minor histocompatability antigen involved in stem cell graft rejection84. Finally, CYrof15B has also been found to be up-regulated in liver and heart tissue, but so far is found to be a pseuodogene of the human taxilin gamma (TXLNG). For the genes found to be up-regulated in females, 2 are X-linked: X (inactive)-specific transcript (XIST), PNPLA4 , and the third, PZP, is autosomal, found on chromosome 12. XIST is found on the X inactivation center (XIC) 85and which functions in silencing of X-linked genes through Xchromosome inactivation. XIST was found to be non-protein coding and instead functions as structural RNA in the nucleus86. XIST is found to be up-regulated in human brain (specifically neurons), heart and liver16,74,83. PNPLA4 belongs to a family of lipid hyrolases and is a potent retinylester hydrolase in keratinocytes, affecting their morphology87. It is expressed in a variety of tissues, albeit in different transcript lengths, suggesting differential processing across tissues88. Finally, the only autosomal gene to be up-regulated in liver of females in our study that has been 22 previously reported is PZP. PZP is a plasma protein that functions as a peptidase inhibitor89. It has been found to associate with TGF-beta-1 and TGF-beta-2 and regulates their plasma clearance90. Since TGF-beta signaling is highly implicated in hepatic carcinogenesis, PZP may play a role in this pathway. This is further corroborated by data from Genome-wide associated study where single nucleotide polymorphisms in PZP associated with high serum AST91. It is not unexpected to find X- and Y-linked genes to be differentially expressed among females and males, but to explain why only a few of the >1300 gene on the X-chromosomes have been found to be up-regulated in females and only a few Y-linked genes have been upregulated in males, some considerations have to be taken. X-inactivation of the X-chromosome in somatic cells of females results in similar expression patterns for X-linked genes in males and females. Dosage compensation for the active X-chromosome results in hypertrasncription of the X-linked genes to reach the level of autosomal genes (present in 2 copies). This could explain the lack of differential expression of most X-linked genes observed in our study93. To add another level of complication, some genes are found to escape this X-inactivation, which results in higher expression of these genes in females compared to males 92 . However, this inactivation is found not be consistent between individuals, or within cells and tissues of an individual, leading to variations in expression that are yet to be further analyzed94. Additionally, due to the presence of various X-Y homologues (homologues of the same gene serving the same function), crosshybridization of the Y-specific probes to X-homologues has been reported and could compromises the ability of the Y-chromosome probes to differentiate male and female samples, thereby resulting in similar expression levels74,95. Additionally, a lack of correlation between mRNA levels and protein levels has been observed for some genes, as the case for DDX3Y, 23 necessitating downstream functional analysis on the protein level before solid conclusions can be made77. Overall, while the differentially expressed genes identified in this study did not produce any functional clusters using the gene functional classification tool in DAVID, they are consistent with other studies comparing male and female human tissues. The expression of these genes is not specific to the liver, as they are found in other tissues as well including brain, heart and prostate. However, several studies have linked sex chromosomal aberrations and Y-linked gene expression to cancer. For example, up-regulation of Y-linked gene such as RPS4Y1, UTY, EIF1AY and USP9Y has been found in prostate cancer tissue and cell lines, compared to benign prostatic hyperplasia and normal testis76,96. In contrast, Y-chromosomal deletions have been also associated with prostate cancer97–99, male breast carcinomas100 and pancreatic adenocarcinomas101. Loss of Y-Chromosome in peripheral blood cells was found to be associated with higher risk of cancer in men102. Additionally, rearrangements of the X- chromosomes, including deletions and gains, have been associated with breast103, ovarian104 and uterine cervix cancer105. Loss of heterozygousity (LOH) has been found in endocrine carcinomas of the gastroenteropancreatic tract, lung and colorectal cancer106–108. Therefore there is a link between sex-chromosome genes and both gender-specific and non-specific cancer, which remains to be fully elucidated. Although this study provides a preliminary meta-analysis of the gender-bias in normal liver tissue utilizing two microarray datasets, further studies should analyze more samples, with gender information for the utilized datasets. A larger sample pool would allow the stratification of patients into age groups. As cancer is largely a disease of ageing, analyzing data from more uniform age groups could be more informative. In addition, more advanced techniques, such as 24 RNA-Seq could provide more information about mutations in X- and Y- chromosome genes, as well as a more accurate and sensitive measurement of X-Y homologues that could have interfered with the microarray analysis. Finally, specific studies of already identified genes in the liver and their corresponding proteins would provide more information about their role in liver biology and regulation during carcinogenesis. 25 TABLES Table 1. Summary of the datasets of microarray studies using human normal liver tissue. Datasets with available gender information are highlighted Accession Sample size Sample types Gender 19 4 7 10 Normal Liver Normal liver (prior to transplantation) Normal liver Normal liver( with diabetes) Yes yes GSE13471 4 Normal liver none Affymetrix (GPL570) GSE6222 2 Normal liver none GSE45436 39 Normal liver None Affymetrix (GPL570) Affymetrix (GPL570) GSE38941 10 Normal liver None Affymetrix (GPL570) GSE14323 GSE14951 GSE23343 26 Platform Affymetrix (GPL571) Affymetrix (GPL570) yes Affymetrix (GPL570) Table 2. Sample information of three microarray datasets with gender information Acession GSE14323 GSE14951 GSE23343 Total Male 12 5 10 27 Female 7 5 7 19 27 Table 3. Summary of differentially expressed probes found in all three data set and their corresponding gene names. Common probes found between datasets are highlighted. GSE14951 GSE143233 201909_at 201909_at 224590_at GSE23343 201909_at 224590_at Gene Name Ribosomal protein S4, Y-linked 1 X (inactive)-specific transcript (non-protein coding) 203649_s_at Phospholipase A2, group IIA (platelets, synovial fluid) 204409_s_at 204409_s_at Eukaryotic translation initiation factor 1A, Ylinked 205000_at 205000_at DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Ylinked 214218_s_at 214218_s_at X (inactive)-specific transcript (non-protein coding) 221728_x_at 221728_x_at X (inactive)-specific transcript (non-protein coding) 206700_s_at Lysine (K)-specific demethylase 5D 207063_at Chromosome Y open reading frame 14 207330_at Pregnancy-zone protein 214131_at Chromosome Y open reading frame 15B 204410_at Eukaryotic translation initiation factor 1A, Ylinked 223645_s_at Chromosome Y open reading frame 15B 223646_s_at Chromosome Y open reading frame 15B 224588_at X (inactive)-specific transcript (non-protein coding) 205001_s_at DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Ylinked 227614_at Hexokinase domain containing 1 227671_at X (inactive)-specific transcript (non-protein coding) 228492_at Ubiquitin specific peptidase 9, Y-linked 235942_at Hypothetical LOC401629 28 Table 4.Summary of differentially expressed probes identified in GSE14323 using the Limma Package compared to those found using the T-test method, common probes are highlighted. Limma T-test 201909_at 204409_s_at 201909_at 204409_s_at 203649_s_at GSE14323 Gene Name Ribosomal protein S4, Y-linked 1 Eukaryotic translation initiation factor 1A, Y-linked Phospholipase A2, group IIA (platelets, synovial fluid) 204410_at Eukaryotic translation initiation factor 1A, Y-linked 205000_at 205000_at DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked 205001_s_at DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked 206700_s_at Lysine (K)-specific demethylase 5D 214131_at Chromosome Y open reading frame 15B 214218_s_at 214218_s_at X (inactive)-specific transcript (non-protein coding) 221728_x_at 221728_x_at X (inactive)-specific transcript (non-protein coding) 29 Y or Xlinked Y Y Chr. 1 Y Y Y Y Y X X Table 5. Differentially expressed probes identified in GSE 23343 using the Limma Package compared to those found using the T-test method, common probes are highlighted. Limma T-test 201909_at 204409_s_at 201909_at 204409_s_at 204410_at 205000_at 205000_at 205001_s_at 221728_x_at 224588_at 224590_at 227671_at 214216_s_at 206700_s_at 207063_at 207330_at 214131_at 214218_s_at 221728_x_at 223645_s_at 223646_s_at 224588_at 224590_at 227614_at 227671_at 228492_at 235942_at GSE23343 Gene Name Ribosomal protein S4, Y-linked 1 Eukaryotic translation initiation factor 1A, Y-linked Eukaryotic translation initiation factor 1A, Y-linked DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Ylinked DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Ylinked Lysine (K)-specific demethylase 5D Chromosome Y open reading frame 14 Pregnancy-zone protein Chromosome Y open reading frame 15B X (inactive)-specific transcript (non-protein coding) X (inactive)-specific transcript (non-protein coding) Chromosome Y open reading frame 15B Chromosome Y open reading frame 15B X (inactive)-specific transcript (non-protein coding) X (inactive)-specific transcript (non-protein coding) Hexokinase domain containing 1 X (inactive)-specific transcript (non-protein coding) Ubiquitin specific peptidase 9, Y-linked Hypothetical LOC401629 La ribonucleoprotein domain family, member 4B 30 Y or Xlinked Y Y Y Y Y Y Y Chr. 12 Y X X Y Y X X Chr. 10 X Y Y Chr. 10 Table 6. Differentially expressed probes and their corresponding gene names, identified in merged datasets using the t-test method. Probe ID 201909_at 204409_s_at 204410_at 205000_at 205001_s_at 206700_s_at 207330_at 214131_at 214218_s_at 221728_x_at Merged Datasets (GSE14323 & GSE 23343) Gene Name Ribosomal protein S4, Y-linked 1 Eukaryotic translation initiation factor 1A, Y-linked Eukaryotic translation initiation factor 1A, Y-linked DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked Lysine (K)-specific demethylase 5D Pregnancy-zone protein Chromosome Y open reading frame 15B X (inactive)-specific transcript (non-protein coding) X (inactive)-specific transcript (non-protein coding) 31 Table 7. Differentially expressed probes and their corresponding genes in dataset GSE14343 after batch effect removal using fRMA. Newly identified genes are highlighted. Probe ID 214131_at 204410_at 205001_s_at 206700_s_at 204409_s_at 205000_at 201909_at 209739_s_at 221728_x_at 214218_s_at 206624_at 211149_at GSE14323 fRMA Gene Name Chromosome Y open reading frame 15B Eukaryotic translation initiation factor 1A, Y-linked DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked Lysine (K)-specific demethylase 5D Eukaryotic translation initiation factor 1A, Y-linked DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked Ribosomal protein S4, Y-linked 1 patatin-like phospholipase domain containing 4 X (inactive)-specific transcript (non-protein coding) X (inactive)-specific transcript (non-protein coding) ubiquitin specific peptidase 9, Y-linked ubiquitously transcribed tetratricopeptide repeat gene, Y-linked 32 Table 8. Differentially expressed probes and their corresponding genes in dataset GSE23343 after batch effect removal using fRMA. Probe ID 221728_x_at 227671_at 214218_s_at 224588_at 224590_at 205001_s_at 204409_s_at 205000_at 201909_at GSE23343 Gene Name X (inactive)-specific transcript (non-protein coding) X (inactive)-specific transcript (non-protein coding) X (inactive)-specific transcript (non-protein coding) X (inactive)-specific transcript (non-protein coding) X (inactive)-specific transcript (non-protein coding) DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked Eukaryotic translation initiation factor 1A, Y-linked DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked Ribosomal protein S4, Y-linked 1 33 Table 9. Differentially expressed probes and their corresponding genes in merged datasets after batch effect removal using fRMA or using ComBat, common probes are highlighted. Probe ID Merged fRMA Merged ComBat 201909_at 201909_at 204409_s_at 204409_s_at 204410_at 204410_at 205000_at 205000_at 205001_s_at 205001_s_at 206700_s_at 206700_s_at 211149_at 211149_at 214131_at 214131_at 214216_s_at 221728_x_at 221728_x_at 214218_s_at 203992_s_at 206624_at 209739_s_at Gene Name Ribosomal protein S4, Y-linked 1 Eukaryotic translation initiation factor 1A, Y-linked Eukaryotic translation initiation factor 1A, Y-linked DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked Lysine (K)-specific demethylase 5D ubiquitously transcribed tetratricopeptide repeat gene, Y-linked Chromosome Y open reading frame 15B La ribonucleoprotein domain family, member 4B X (inactive)-specific transcript (non-protein coding) X (inactive)-specific transcript (non-protein coding) X (inactive)-specific transcript (non-protein coding) lysine (K)-specific demethylase 6A ubiquitin specific peptidase 9, Y-linked 34 FIGURES A. B. C. Figure 1: Hierarchical Cluster Analysis of 3 microarray datasets of human normal liver tissues: A. GSE14951 B. GSE14323 C. GSE23343 35 A. Female Male B. Female Male C. Figure 2: Differentially Expressed probes in individual datasets (t-test). Heat Maps of differentially expressed probes (t-test, P<0.05, fold change >2) between male and female samples of human normal liver: Datasets: A. GSE14951 B. GSE14323 C. GSE23343 36 A. Male Female B. Female Male Figure 3: Differentially Expressed probes in individual datasets (Limma). Heat maps of differentially expressed probes between male and female samples of human normal liver identified using the Limma Package (P<0.05). A. Dataset GSE14323 B. Dataset GSE23343. 37 Male Female Figure 4: Differentially Expressed probes in merged datasets. Heat map of differentially expressed probes between male and female samples of human normal liver tissues, identified in merged datasets (GSE14323, GSE23343) using the t-test method ((P<0.05, Fold Change>2). 38 Figure 5: Hierarchical Cluster Analysis of merged microarray datasets (GSE14323, GSE23343) of human normal liver tissues. 39 Male Female B. Male Female Figure 6. Differentially Expressed probes in individual datasets after batch effect removal. Heat maps of differentially expressed probes (Limma, P<0.05 )between male and female human normal liver samples in microarray datasets A. GSE14323 and B. GSE23343 after removal of batch effects using the fRMA method. 40 Male Female A. Female Male B. Figure 7: Differentially Expressed probes in merged datasets after batch effect removal. Heat maps of differentially expressed probes (Limma, P<0.05 ) between male and female human normal liver samples in merged microarray data sets (GSE14323 and GSE23343) after removal of batch effects using A. fRMA and B. ComBat methods. 41 A. B. Figure 8: Gene Signature Validation. Hierarchical cluster analysis for microarray datasets A. GSE14323 and B. GSE23343, using a subset of 500 genes identified previously by Hartewell et al16. 42 REFERENCES 1. Ferlay, J. et al. GLOBOCAN 2012 v1.0, Cancer Incidence and Mortality Worldwide: IARC CancerBase No. 11 [Internet]. Lyon Fr. Int. Agency Res. Cancer 2013 at <http://globocan.iarc.fr> 2. El-Serag, H. B. Hepatocellular Carcinoma. N. Engl. J. Med. 365, 1118–1127 (2011). 3. Shaker, M. K., Abdella, H. M., Khalifa, M. O. & Dorry, A. K. E. Epidemiological characteristics of hepatocellular carcinoma in Egypt: a retrospective analysis of 1313 Cases. Liver Int. n/a–n/a (2013). doi:10.1111/liv.12209 4. el-Zayadi, A.-R. et al. Hepatocellular carcinoma in Egypt: a single center study over a decade. World J. Gastroenterol. WJG 11, 5193–5198 (2005). 5. Bosch, F. X., Ribes, J., Díaz, M. & Cléries, R. Primary liver cancer: worldwide incidence and trends. Gastroenterology 127, S5–S16 (2004). 6. Mucci, L. A. et al. Age at menarche and age at menopause in relation to hepatocellular carcinoma in women. BJOG Int. J. Obstet. Gynaecol. 108, 291–294 (2001). 7. Yu, M.-W. et al. Role of reproductive factors in hepatocellular carcinoma: Impact on hepatitis B- and C-related risk. Hepatol. Baltim. Md 38, 1393–1400 (2003). 8. Ghebranious, N. & Sell, S. Hepatitis B injury, male gender, aflatoxin, and p53 expression each contribute to hepatocarcinogenesis in transgenic mice. Hepatol. Baltim. Md 27, 383–391 (1998). 9. Nakatani, T., Roy, G., Fujimoto, N., Asahara, T. & Ito, A. Sex hormone dependency of diethylnitrosamine-induced liver tumors in mice and chemoprevention by leuprorelin. Jpn. J. Cancer Res. Gann 92, 249–256 (2001). 10. Maeda, S., Kamata, H., Luo, J.-L., Leffert, H. & Karin, M. IKKbeta couples hepatocyte death to cytokine-driven compensatory proliferation that promotes chemical hepatocarcinogenesis. Cell 121, 977–990 (2005). 11. Verna, L., Whysner, J. & Williams, G. M. N-nitrosodiethylamine mechanistic data and risk assessment: bioactivation, DNA-adduct formation, mutagenicity, and tumor initiation. Pharmacol. Ther. 71, 57–81 (1996). 12. Kemp, C. J., Leary, C. N. & Drinkwater, N. R. Promotion of murine hepatocarcinogenesis by testosterone is androgen receptor-dependent but not cell autonomous. Proc. Natl. Acad. Sci. U. S. A. 86, 7505–7509 (1989). 13. Berasain, C. et al. Inflammation and Liver Cancer: New Molecular Links. Ann. N. Y. Acad. Sci. 1155, 206–221 (2009). 14. Naugler, W. E. et al. Gender Disparity in Liver Cancer Due to Sex Differences in MyD88-Dependent IL-6 Production. Science 317, 121–124 (2007). 15. Bigsby, R. M. & Caperell-Grant, A. The role for estrogen receptor-alpha and prolactin receptor in sex-dependent DEN-induced liver tumorigenesis. Carcinogenesis 32, 1162–1166 (2011). 16. Hartwell, H. J., Petrosky, K. Y., Fox, J. G., Horseman, N. D. & Rogers, A. B. Prolactin prevents hepatocellular carcinoma by restricting innate immune activation of c-Myc in mice. Proc. Natl. Acad. Sci. 111, 11455–11460 (2014). 17. Keng, V. W. et al. Sex bias occurrence of hepatocellular carcinoma in Poly7 molecular subclass is associated with EGFR. Hepatology 57, 120–130 (2013). 18. Lipshutz, R. J., Fodor, S. P. A., Gingeras, T. R. & Lockhart, D. J. High density synthetic oligonucleotide arrays. Nat. Genet. 21, 20–24 (1999). 43 19. Lockhart, D. J. et al. Expression monitoring by hybridization to high-density oligonucleotide arrays. Nat. Biotechnol. 14, 1675–1680 (1996). 20. Alon, U. et al. Broad patterns of gene expression revealed by clustering analysis of tumor and normal colon tissues probed by oligonucleotide arrays. Proc. Natl. Acad. Sci. 96, 6745– 6750 (1999). 21. Dhanasekaran, S. M. et al. Delineation of prognostic biomarkers in prostate cancer. Nature 412, 822–826 (2001). 22. Van ’t Veer, L. J. et al. Gene expression profiling predicts clinical outcome of breast cancer. Nature 415, 530–536 (2002). 23. Chen, X. et al. Gene expression patterns in human liver cancers. Mol. Biol. Cell 13, 1929–1939 (2002). 24. Okabe, H. et al. Genome-wide analysis of gene expression in human hepatocellular carcinomas using cDNA microarray: identification of genes involved in viral carcinogenesis and tumor progression. Cancer Res. 61, 2129–2137 (2001). 25. Garber, M. E. et al. Diversity of gene expression in adenocarcinoma of the lung. Proc. Natl. Acad. Sci. 98, 13784–13789 (2001). 26. Barrett, T. et al. NCBI GEO: archive for functional genomics data sets--update. Nucleic Acids Res. 41, D991–D995 (2013). 27. Edgar, R. Gene Expression Omnibus: NCBI gene expression and hybridization array data repository. Nucleic Acids Res. 30, 207–210 (2002). 28. Kolesnikov, N. et al. ArrayExpress update--simplifying data submissions. Nucleic Acids Res. 43, D1113–1116 (2015). 29. Kuo, W. P., Jenssen, T.-K., Butte, A. J., Ohno-Machado, L. & Kohane, I. S. Analysis of matched mRNA measurements from two different microarray technologies. Bioinforma. Oxf. Engl. 18, 405–412 (2002). 30. Irizarry, R. A. et al. Multiple-laboratory comparison of microarray platforms. Nat. Methods 2, 345–350 (2005). 31. Ramasamy, A., Mondry, A., Holmes, C. C. & Altman, D. G. Key Issues in Conducting a Meta-Analysis of Gene Expression Microarray Datasets. PLoS Med. 5, e184 (2008). 32. Choi, J. K., Yu, U., Kim, S. & Yoo, O. J. Combining multiple microarray studies and modeling interstudy variation. Bioinformatics 19, i84–i90 (2003). 33. Hong, F. et al. RankProd: a bioconductor package for detecting differentially expressed genes in meta-analysis. Bioinformatics 22, 2825–2827 (2006). 34. Mehra, R. Identification of GATA3 as a Breast Cancer Prognostic Marker by Global Gene Expression Meta-analysis. Cancer Res. 65, 11259–11264 (2005). 35. Rhodes, D. R. et al. Large-scale meta-analysis of cancer microarray data identifies common transcriptional profiles of neoplastic transformation and progression. Proc. Natl. Acad. Sci. 101, 9309–9314 (2004). 36. Grützmann, R. et al. Meta-analysis of microarray data on pancreatic cancer defines a set of commonly dysregulated genes. Oncogene 24, 5079–5088 (2005). 37. Lee, H. K. Coexpression Analysis of Human Genes Across Many Microarray Data Sets. Genome Res. 14, 1085–1094 (2004). 38. Ewald, J. A., Downs, T. M., Cetnar, J. P. & Ricke, W. A. Expression Microarray MetaAnalysis Identifies Genes Associated with Ras/MAPK and Related Pathways in Progression of Muscle-Invasive Bladder Transition Cell Carcinoma. PLoS ONE 8, e55414 (2013). 44 39. Hong, F. & Breitling, R. A comparison of meta-analysis methods for detecting differentially expressed genes in microarray experiments. Bioinformatics 24, 374–382 (2008). 40. Tseng, G. C., Ghosh, D. & Feingold, E. Comprehensive literature review and statistical considerations for microarray meta-analysis. Nucleic Acids Res. 40, 3785–3799 (2012). 41. Irizarry, R. A. Summaries of Affymetrix GeneChip probe level data. Nucleic Acids Res. 31, 15e–15 (2003). 42. Bolstad, B. M., Irizarry, R. ., Astrand, M. & Speed, T. P. A comparison of normalization methods for high density oligonucleotide array data based on variance and bias. Bioinformatics 19, 185–193 (2003). 43. Li, C. & Hung Wong, W. Model-based analysis of oligonucleotide arrays: model validation, design issues and standard error application. Genome Biol. 2, RESEARCH0032 (2001). 44. Naef, F., Hacker, C. R., Patil, N. & Magnasco, M. Empirical characterization of the expression ratio noise structure in high-density oligonucleotide arrays. Genome Biol. 3, RESEARCH0018 (2002). 45. Irizarry, R. A. Exploration, normalization, and summaries of high density oligonucleotide array probe level data. Biostatistics 4, 249–264 (2003). 46. Cui, X. & Churchill, G. A. Statistical tests for differential expression in cDNA microarray experiments. Genome Biol. 4, 210 (2003). 47. Jeanmougin, M. et al. Should We Abandon the t-Test in the Analysis of Gene Expression Microarray Data: A Comparison of Variance Modeling Strategies. PLoS ONE 5, e12336 (2010). 48. Murie, C., Woody, O., Lee, A. Y. & Nadon, R. Comparison of small n statistical tests of differential expression applied to microarrays. BMC Bioinformatics 10, 45 (2009). 49. Jeffery, I. B., Higgins, D. G. & Culhane, A. C. Comparison and evaluation of methods for generating differentially expressed gene lists from microarray data. BMC Bioinformatics 7, 359 (2006). 50. Kooperberg, C., Aragaki, A., Strand, A. D. & Olson, J. M. Significance testing for small microarray experiments. Stat. Med. 24, 2281–2298 (2005). 51. Ritchie, M. E. et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 43, e47–e47 (2015). 52. Smyth, G. K. Linear models and empirical bayes methods for assessing differential expression in microarray experiments. Stat. Appl. Genet. Mol. Biol. 3, Article3 (2004). 53. Chen, C. et al. Removing Batch Effects in Analysis of Expression Microarray Data: An Evaluation of Six Batch Adjustment Methods. PLoS ONE 6, e17238 (2011). 54. Johnson, W. E., Li, C. & Rabinovic, A. Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostatistics 8, 118–127 (2007). 55. Leek, J. T. et al. Tackling the widespread and critical impact of batch effects in highthroughput data. Nat. Rev. Genet. 11, 733–739 (2010). 56. Lander, E. S. Array of hope. Nat. Genet. 21, 3–4 (1999). 57. Benito, M. et al. Adjustment of systematic microarray data biases. Bioinforma. Oxf. Engl. 20, 105–114 (2004). 58. Sims, A. H. et al. The removal of multiplicative, systematic bias allows integration of breast cancer gene expression datasets – improving meta-analysis and prediction of prognosis. BMC Med. Genomics 1, 42 (2008). 45 59. Leek, J. T. & Storey, J. D. Capturing heterogeneity in gene expression studies by surrogate variable analysis. PLoS Genet. 3, 1724–1735 (2007). 60. Luo, J. et al. A comparison of batch effect removal methods for enhancement of prediction performance using MAQC-II microarray gene expression data. Pharmacogenomics J. 10, 278–291 (2010). 61. Gautier, L., Cope, L., Bolstad, B. M. & Irizarry, R. A. affy--analysis of Affymetrix GeneChip data at the probe level. Bioinforma. Oxf. Engl. 20, 307–315 (2004). 62. Gentleman, R. C. et al. Bioconductor: open software development for computational biology and bioinformatics. Genome Biol. 5, R80 (2004). 63. Huber, W. et al. Orchestrating high-throughput genomic analysis with Bioconductor. Nat. Methods 12, 115–121 (2015). 64. Holm, S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 65–70 (1979). 65. Taminau, J. et al. Unlocking the potential of publicly available microarray data using inSilicoDb and inSilicoMerging R/Bioconductor packages. BMC Bioinformatics 13, 335 (2012). 66. McCall, M. N., Bolstad, B. M. & Irizarry, R. A. Frozen robust multiarray analysis (fRMA). Biostatistics 11, 242–253 (2010). 67. Huang, D. W., Sherman, B. T. & Lempicki, R. A. Bioinformatics enrichment tools: paths toward the comprehensive functional analysis of large gene lists. Nucleic Acids Res. 37, 1–13 (2009). 68. Huang, D. W., Sherman, B. T. & Lempicki, R. A. Systematic and integrative analysis of large gene lists using DAVID bioinformatics resources. Nat. Protoc. 4, 44–57 (2008). 69. Misu, H. et al. A liver-derived secretory protein, selenoprotein P, causes insulin resistance. Cell Metab. 12, 483–495 (2010). 70. Conti, A. et al. Wide gene expression profiling of ischemia-reperfusion injury in human liver transplantation. Liver Transplant. Off. Publ. Am. Assoc. Study Liver Dis. Int. Liver Transplant. Soc. 13, 99–113 (2007). 71. Mas, V. R. et al. Genes involved in viral carcinogenesis and tumor initiation in hepatitis C virus-induced hepatocellular carcinoma. Mol. Med. Camb. Mass 15, 85–94 (2009). 72. Everitt, B. S., Landau, S. & Leese, M. Cluster Analysis. (London: Arnold.). 73. Fisher, E. M. et al. Homologous ribosomal protein genes on the human X and Y chromosomes: escape from X inactivation and possible implications for Turner syndrome. Cell 63, 1205–1218 (1990). 74. Vawter, M. P. et al. Gender-Specific Gene Expression in Post-Mortem Human Brain: Localization to Sex Chromosomes. Neuropsychopharmacology 29, 373–384 (2004). 75. Isensee, J. et al. Sexually dimorphic gene expression in the heart of mice and men. J. Mol. Med. 86, 61–74 (2008). 76. Dasari, V. K. et al. Expression analysis of Y chromosome genes in human prostate cancer. J. Urol. 165, 1335–1341 (2001). 77. Ditton, H. J., Zimmer, J., Kamp, C., Rajpert-De Meyts, E. & Vogt, P. H. The AZFa gene DBY (DDX3Y) is widely transcribed but the protein is limited to the male germ cells by translation control. Hum. Mol. Genet. 13, 2333–2341 (2004). 78. Yedavalli, V. S. R. K., Neuveut, C., Chi, Y.-H., Kleiman, L. & Jeang, K.-T. Requirement of DDX3 DEAD box RNA helicase for HIV-1 Rev-RRE export function. Cell 119, 381–392 (2004). 46 79. Lee, K. H. et al. Ubiquitin-specific protease activity of USP9Y, a male infertility gene on the Y chromosome. Reprod. Fertil. Dev. 15, 129–133 (2003). 80. Brown, G. M. et al. Characterisation of the coding sequence and fine mapping of the human DFFRY gene and comparative expression analysis and mapping to the Sxrb interval of the mouse Y chromosome of the Dffry gene. Hum. Mol. Genet. 7, 97–107 (1998). 81. Marintchev, A., Kolupaeva, V. G., Pestova, T. V. & Wagner, G. Mapping the binding interface between human eukaryotic initiation factors 1A and 5B: a new interaction between old partners. Proc. Natl. Acad. Sci. U. S. A. 100, 1535–1540 (2003). 82. Luna, R. E. et al. The Interaction between Eukaryotic Initiation Factor 1A and eIF5 Retains eIF1 within Scanning Preinitiation Complexes. Biochemistry (Mosc.) 52, 9510–9518 (2013). 83. Laaser, I., Theis, F. J., de Angelis, M. H., Kolb, H.-J. & Adamski, J. Huge splicing frequency in human Y chromosomal UTY gene. Omics J. Integr. Biol. 15, 141–154 (2011). 84. Vogt, M. H. J. et al. UTY gene codes for an HLA-B60–restricted human male-specific minor histocompatibility antigen involved in stem cell graft rejection: characterization of the critical polymorphic amino acid residues for T-cell recognition. Blood 96, 3126–3132 (2000). 85. Brown, C. J. et al. The human XIST gene: analysis of a 17 kb inactive X-specific RNA that contains conserved repeats and is highly localized within the nucleus. Cell 71, 527–542 (1992). 86. Brockdorff, N. et al. Conservation of position and exclusive expression of mouse Xist from the inactive X chromosome. Nature 351, 329–331 (1991). 87. Kienesberger, P. C., Oberer, M., Lass, A. & Zechner, R. Mammalian patatin domain containing proteins: a family with diverse lipolytic activities involved in multiple biological functions. J. Lipid Res. 50, S63–S68 (2008). 88. Lee, W. C., Salido, E. & Yen, P. H. Isolation of a new gene GS2 (DXS1283E) from a CpG island between STS and KAL1 on Xp22.3. Genomics 22, 372–376 (1994). 89. Valnickova, Z. et al. Activated human plasma carboxypeptidase B is retained in the blood by binding to alpha2-macroglobulin and pregnancy zone protein. J. Biol. Chem. 271, 12937– 12943 (1996). 90. Philip, A., Bostedt, L., Stigbrand, T. & O’CONNOR-McCOURT, M. D. Binding of transforming growth factor-beta (TGF-beta) to pregnancy zone protein (PZP). Comparison to the TGF-beta-alpha2-macroglobulin interaction. Eur. J. Biochem. 221, 687–693 (1994). 91. Chalasani, N. et al. Genome-Wide Association Study Identifies Variants Associated With Histologic Features of Nonalcoholic Fatty Liver Disease. Gastroenterology 139, 1567– 1576.e6 (2010). 92. Nguyen, D. K. & Disteche, C. M. Dosage compensation of the active X chromosome in mammals. Nat. Genet. 38, 47–53 (2006). 93. Sudbrak, R. et al. X chromosome-specific cDNA arrays: identification of genes that escape from X-inactivation and other applications. Hum. Mol. Genet. 10, 77–83 (2001). 94. Heard, E. Dosage compensation in mammals: fine-tuning the expression of the X chromosome. Genes Dev. 20, 1848–1867 (2006). 95. Skaletsky, H. et al. The male-specific region of the human Y chromosome is a mosaic of discrete sequence classes. Nature 423, 825–837 (2003). 96. Lau, Y. F. & Zhang, J. Expression analysis of thirty one Y chromosome genes in human prostate cancer. Mol. Carcinog. 27, 308–321 (2000). 47 97. Jordan, J. J., Hanlon, A. L., Al-Saleem, T. I., Greenberg, R. E. & Tricoli, J. V. Loss of the short arm of the Y chromosome in human prostate carcinoma. Cancer Genet. Cytogenet. 124, 122–126 (2001). 98. König, J. J. et al. Loss and gain of chromosomes 1, 18, and Y in prostate cancer. The Prostate 25, 281–291 (1994). 99. Lundgren, R. et al. Cytogenetic analysis of 57 primary prostatic adenocarcinomas. Genes. Chromosomes Cancer 4, 16–24 (1992). 100. Teixeira, M. R. et al. Chromosome banding analysis of gynecomastias and breast carcinomas in men. Genes. Chromosomes Cancer 23, 16–20 (1998). 101. Wallrapp, C. et al. Loss of the Y chromosome is a frequent chromosomal imbalance in pancreatic cancer and allows differentiation to chronic pancreatitis. Int. J. Cancer 91, 340–344 (2001). 102. Forsberg, L. A. et al. Mosaic loss of chromosome Y in peripheral blood is associated with shorter survival and higher risk of cancer. Nat. Genet. 46, 624–628 (2014). 103. Piao, Z. & Malkhosyan, S. R. Frequent loss Xq25 on the inactive X chromosome in primary breast carcinomas is associated with tumor grade and axillary lymph node metastasis. Genes. Chromosomes Cancer 33, 262–269 (2002). 104. Choi, C. et al. Loss of heterozygosity at chromosome segment Xq25-26.1 in advanced human ovarian carcinomas. Genes. Chromosomes Cancer 20, 234–242 (1997). 105. Kersemaekers, A. M., van de Vijver, M. J., Kenter, G. G. & Fleuren, G. J. Genetic alterations during the progression of squamous cell carcinomas of the uterine cervix. Genes. Chromosomes Cancer 26, 346–354 (1999). 106. Azzoni, C. et al. Xq25 and Xq26 identify the common minimal deletion region in malignant gastroenteropancreatic endocrine carcinomas. Virchows Arch. 448, 119–126 (2006). 107. Bottarelli, L. et al. Sex Chromosome Alterations Associate with Tumor Progression in Sporadic Colorectal Carcinomas. Clin. Cancer Res. 13, 4365–4370 (2007). 108. D’Adda, T. et al. Malignancy-associated X chromosome allelic losses in foregut endocrine neoplasms: further evidence from lung tumors. Mod. Pathol. 18, 795–805 (2005). 48