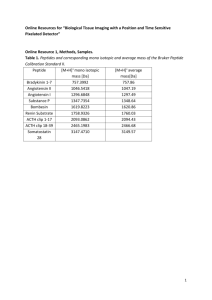
invited_reviewer1_mzTab_comments_anon
advertisement

mzTab: exchange format for proteomics and metabolomics results
Review of specification documentation in DocProc
General thoughts:
Though the PSI has put much effort into the development of vendor-independent formats for mass
spectrometry data, these formats are not easily parsable XML files. These data contain all relevant
information to grasp the workflow of an analysis, starting with the machine settings and including
the whole data analysis workflow. The main purpose of these formats is the compact and complete
storage of the whole workflow up to the point of the generation of the reported file. This makes a
re-analysis of the data possible and gives interested scientists as well as journals as much
information about the proceedings and findings as possible.
The proposed mzTab does not follow these guidelines. Instead it is proposed as a lightweight,
easy to parse and human readable format. But it is also not intended to replace the other formats
(especially mzIdentML and mzQuantML), but to give a recommendation for an interchange format,
only containing the data used by most tools for further analysis. This is a good idea as it, but it also
contains the thread, that the “heavier” formats won’t be used at all and instead only mzTab will be
used.
Apart from this thread I think, a well-defined, easily read- and parsable format for data interchange
is a good idea and the specification is mainly well done, though some more work should be
performed.
Specific comments:
Page 7: protein inference
Allowing only one accession per peptide is very counter intuitive. One very simple example: the
mzTab file is only used to give peptide information (what should be possible), how would it be
possible to report the connection to all possible proteins of the peptide? Referring to a protein via
the "reported" accession for an ambiguity group as in the given specification may be confusing.
This group may have accessions in the "ambiguity group", which are not valid for the given
peptide, depending on the resource.
Page14: Unit IDs
'IDs MUST NOT contain the prefix "_rep[1-n]" unless [...]' -> I think suffix is meant here.
Page 14 (or anywhere):
Every section must obviously start with the header line (e.g. PRH), though this is nowhere stated in
the specification nor the 10-minute-guide. It is also not stated, that the each header row must only
appear once in the document.
Page 14-20:
There should be a metadata-field allowing software-settings to at least capture the most important
settings of the used software. Though it is possible via the custom-field, a defined settings field
would be much easier.
Page 20, also applies for peptides and small molecules:
Is there any specific reason, why the columns MUST be in the order of the document? There is
also the header-row, specifying which columns appear in the protein block and thus also the
ordering will be given.
Page 24 "uri", "go_terms" and "protein_coverage":
They should be optional, as they are not easily found after a peptide search (and not even given by
many search engines).
Page 25:
Why must the peptide section follow the (optional) protein section? I don't see any reason for this,
except a possible accession-parsing. Though, the accessions in the peptide don't have to match
any accessions in the protein section, neither must there be any protein section at all.
Page 26:
The "unique" column may be very useful, but as mzTab should be an easy generated format, it
should be optional and not every search engine reports this value.
The type is specified as “Boolean”, but in the example the values "0" and "1" are used. Though it is
obvious, what is meant, another way would be using "true" and "false" (or these written in capitals).
It would be easier for parses to further specify, whether to use 0/1, true/false or both.
Page 27:
Also "retention_time" is neither given by every search engine, nor by every method in MS relevant
(e.g. direct injection), and thus should be optional.
Page 28:
As the charge (with today’s machines) can only be an Integer, the type should be Integer rather
than Double.
The uri should be optional with the same reason as above.
In the description of the metadata it is said, that the {UNIT_ID}_ms-file is an optional value (as all
metadata is). But the mandatory field "spectra_ref" uses these fields information. If it is not given in
the metadata, there is no use of this mandatory reference format for the "spectra_ref". So either
this field should be optional or rather the ms-file in the metadata mandatory.
Page 29:
Why must the small molecule section follow the (optional) protein and peptide section?
Page 31:
charge: type should be Integer
retention_time: should be optional with same argument as in peptide section
Page 32:
uri: Though I am not used to small molecule identification, I think, it should be optional (same as in
proteins and peptides).
spectra_ref: see comment for peptides