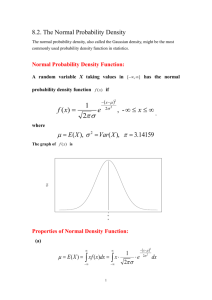
Normal Random Variables
advertisement

Normal Random Variables
We have determined how to compute probabilities for a normal random variable
if µ = 0 and σ = 1. What happens if µ ≠ 0 or σ ≠ 1? It turns out that the problem can be
reduced to a problem about Z using the following three facts.
Fact 1: If X has a normal distribution, then adding or subtracting a constant from X only
shifts the distribution. For example, Y = X – 5 has a normal distribution shifted 5 units
left from the distribution of X, while W = X + 7 has a normal distribution shifted 7 units
to the right of X.
If E[X] = µ, then what is the distribution of T = X - µ?
Fact 2: If X has a normal distribution, then Y = cX has a normal distribution, where c is
a non-zero constant.
Fact 3: If X has a normal distribution, then T = X - µ has a normal distribution from Fact
T X
1. So
has a normal distribution for any constant c by Fact 2. Let σ2 = Var(T)
c
c
= Var(X). Then this tells us that
X
has a normal distribution. Notice that
X 1
E
E[ X ]
1
{E[ X ] E[ ]}
and
90
X 1
Var
2 Var ( X )
1
2 Var ( X )
Given Fact 3, if X has a normal distribution with mean µ and standard deviation σ, then
X
has a normal distribution with mean 0 and standard deviation 1, that is a standard normal
distribution! We therefore write
Z
X
.
The following example shows how this can be used to compute a probability.
Example 1: Suppose X is normally distributed with µ = 5 and σ2 = 9. What is P{X <
11}?
Consider first the event {X < 11}.
{X < 11}
Thus
P{X < 11}
↔
{X – 5 < 11 – 5}
↔
X 5 11 5
3
3
X 5 11 5
3
3
= P
= P{Z < 2}
= 0.9772
91
and
P{X > 11} = P{Z > 2} = 0.0228
Can you interpret the standardized value 2 in example 1?
We can say the following about any normal random variable: All normal random
variables have exactly 0.0228 of the distribution above the value that falls 2 standard
deviations above the mean.
More generally, the value that falls k standard deviations above (below) the mean cuts off
the same area on any normal distribution.
To prove this, just note that no matter what µ and σ are (that is, no matter which normal
distribution you are interested in, we have:
X ( k )
PX k P
P{Z k}
which is a number you can determine depending on the value k selected.
Example 2:
Suppose that the lifetime of a tire, T, is normally distributed with µ = 40,000
miles and σ = 3000 miles. Determine
P{T < 37,000} =
P{38, 500 < T < 43,000} =
Now assume that it is desired to set a warranty on these tires such that 10% of the tires
fall under warranty. What is the required value (in miles)? What does this look like on a
diagram?
92
Let
a = Mileage limit of warranty,
T = Lifetime of a tire.
Two approaches
(1) We know that we wish to find a so that
P{T < a} = .10
Standardizing:
T a 40000
P{T a} P
3000
a 40000
P Z
3000
.10
But we know that
P{Z < -1.28} = .10
This implies
a 40000
1.28
3000
Or
a = 40,000 – 1.28(3000)
= 36,160
(2) We know z.10 = 1.28. To cut off 10% on any normal distribution, walk out 1.28
standard deviations. This gives us
a = 40,000 – 1.28(3000)
= 36,160
(Note you should check to see that P{T < 36,160} = .10)
93
Example 3:
Assume that the scores on an entrance exam for admittance into a particular
college are normally distributed with µ = 500 and σ = 100. If only the top 8% of the
students are to be admitted, what should the grade cut-off be?
Let
X = score on the exam, and
a = the cut off value.
What does the diagram look like?
Then
a = µ + z.08σ
= 500 + (1.41)(100)
= 641
(You should check to see that P{X > 641} = .08)
Computing Normal Probabilities in EXCEL
The function Norm.dist(X,mean,standard_dev,cumulative) returns the cumulative
probability to the point X for a normal random variable with mean and standard
deviation given as arguments 2 and 3. You should type the word true for the last
argument.
The function Norm.inv(prob,mean,standard_dev) returns the value that accumulates
or cuts off prob in the left hand tail of a normal distribution with mean and standard
deviation given as arguments 2 and 3.
94