Chapter 14 - Queueing Models
advertisement

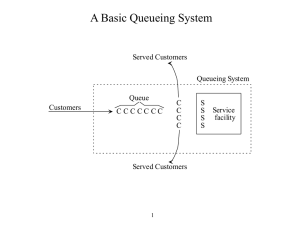
Chapter 14 Queueing Models 14.1 Introduction A basic fact of life is that we all spend a great deal of time waiting in lines (queues). We wait in line at a bank, at a supermarket, at a fast-food restaurant, at a stoplight, and so on. Of course, people are not the only entities that wait in queues. Televisions at a television repair shop, other than the one(s) being repaired, are essentially waiting in line to be repaired. Also, when messages are sent through a computer network, they often must wait in a queue before being processed. The same type of analysis applies to all of these. The purpose of such an analysis is generally twofold. 1. First, we want to examine an existing system to quantify its operating characteristics. For example, if a fast-food restaurant currently employs 12 people in various jobs, the manager might be interested in determining the amount of time a typical customer must wait in line or how many customers are typically waiting in line. 2. Second, we want to learn how to make a system better. The manager might find, for example, that the fast-food restaurant would do better, from an economic standpoint, by employing only 10 workers and deploying them in a different manner. The first objective, analyzing the characteristics of a given system, is difficult from a mathematical point of view. The two basic modelling approaches are analytical and simulation. With the analytical approach, we search for mathematical formulas that describe the operating characteristics of the system, usually in “steady state.” The mathematical models are typically too complex to solve unless we make simplifying (and sometimes unrealistic) assumptions. For example, at a supermarket, customers typically join one of several lines (probably the shortest), possibly switch lines if they see that another line is moving faster, and eventually get served by one of the checkout people. Although this behaviour is common—and is simple to describe in words—it is really difficult to analyze analytically. The second approach, simulation, allows us to analyze much more complex systems, without making many simplifying assumptions. However, the drawback to queueing simulation is that it usually requires specialized software packages or trained computer programmers to implement. In this chapter, we employ both the analytical approach and simulation. For the former, we discuss several well-known queueing models that describe some—but certainly not all— queueing situations in the real world. These models illustrate how to calculate such operating characteristics as the average waiting time per customer, the average number of customers in line, and the fraction of time servers are busy. These analytical models generally require simplifying assumptions, and even then they can be difficult to understand. The inputs are typically mean customer arrival rates and mean service times. The required outputs are typically mean waiting times in queues, mean queue lengths, the fraction of time servers are busy, and possibly others. Deriving the formulas that relate the inputs to the outputs is mathematically very difficult, well beyond the level of this book. Therefore, many times in this chapter you have to take our word for it. Nevertheless, the models we illustrate are very valuable for the important insights they provide. 14.2 ELEMENTS OF QUEUEING MODELS Almost all queueing systems are alike in that customers enter a system, possibly wait in one or more queues, get served, and then depart. Characteristics of Arrivals First, we must specify the customer arrival process. This includes the timing of arrivals a well as the types of arrivals. Regarding timing, specifying the probability distribution of interarrival times, the times between successive customer arrivals, is most common. These interarrival times might be known—that is, nonrandom. For example. the arrivals at some doctors’ offices are scheduled fairly precisely. Much more commonly, however, interarrival times are random with a probability distribution. In real applications, this probability distribution must be estimated from observed customer arrival times. Regarding the types of arrivals, there are at least two issues. 1. First, do customers arrive one at a time or in batches—carloads, for example? The simplest system is when customer’ arrive one at a time, as we assume in all of the models in this chapter. 2. Second, are all customers essentially alike, or can they be separated into priority classes? At a computer centre, for example, certain jobs might receive higher priority and run first, whereas the lower- priority jobs might be sent to the back of the line and run only after midnight. We assume throughout this chapter that all customers have the same priority. Another issue is whether (or how long) customers will wait in line. A customer might arrive to the system, see that too many customers are waiting in line, and decide not to enter the system at all. This is called balking. A variation of balking occurs when the choice is made by the system, not the customer. In this case, we assume there is a waiting room size so that if the number of customers in the system equals the waiting room size, newly arriving customers are not allowed to enter the system. We call this a limited waiting room system. Another type of behaviour, called reneging, occurs when a customer already in line becomes impatient and leaves the system before starting service. Systems with balking and reneging are difficult to analyze, so we do not consider any such systems in this chapter. However, we do discuss limited waiting room systems. Service Discipline When customers enter the system, they might have to wait in line until a server becomes available. In this case, we must specify the service discipline. The service discipline is the rule that states which customer, from all who are waiting, goes into service next. The most common service discipline is first-come-first-served (FCFS), where customers are served in the order of their arrival. All of the models we discuss use the FCFS discipline. However, other service disciplines are possible, including service-in-random-order (SRO), last- come-first-served (LCFS), and various priority disciplines (if there are customer classes with different priorities). For example, a type of priority discipline used in some manufacturing plants is called the shortest-processing-time (SPT) discipline. In this case, the jobs that are waiting to be processed are ranked according to their eventual processing (service) times, which are assumed to be known. Then the job with the shortest processing time is processed next. One other aspect of the waiting process is whether there is a single line or multiple lines. For example, most banks now have a single line. An arriving customer joins the end of the line. When any teller finishes service, the customer at the head of the line goes to that teller. In contrast, most supermarkets have multiple lines. When a customer goes to a checkout counter, she must choose which of several lines to enter. Presumably, she will choose the shortest line, but she might use other criteria in her decision. After she joins a line—inevitably the slowestmoving one, from our experience!—she might decide to move to another line that seems to be moving faster. Service Characteristics In the simplest systems, each customer is served by exactly one server, even when the system contains multiple servers. For example, when you enter a bank, you are eventually served by a single teller, even though several tellers are working. The service times typically vary in some random manner, although constant (nonrandom) service times are sometimes possible. When service times are random, we must specify the probability distribution of a typical service time. This probability distribution can be the same for all customers and servers, or it can depend on the server and/or the customer. As with interarrival times, service time distributions must typically be estimated from service time data in real applications. In a situation like the typical bank, where customers join a single line and are then served by the first available teller, we say the servers (tellers) are in parallel (see Figure 14.1). A different type of service process is found in many manufacturing settings. For example, various types of parts (the “customers”) enter a system with several types of machines (the “servers”). Each part type then follows a certain machine routing, such as machine 1, then machine 4, and then machine 2. Each machine has its own service time distribution, and a typical part might have to wait in line behind any or all of the machines on its routing. This type of system is called a queueing network. The simplest type of queueing network is a series system, where all parts go through the machines in numerical order: first machine 1, then machine 2, then machine 3, and so on (see Figure 14.2). We examine mostly parallel systems in this chapter. Short-Run versus Steady-State Behaviour If you run a fast-food restaurant, you are particularly interested in the queueing behaviour during your peak lunchtime period. The customer arrival rate during this period increases sharply, and you probably employ more workers to meet the increased customer load. In this case, your primary interest is in the short-run behaviour of the system—the next hour or two. Unfortunately, short-run behaviour is the most difficult to analyze. But how do we draw the line between the short run and the long run? The answer depends on how long the effects of initial conditions persist. Analytical models are best suited for studying long-run behaviour. This type of analysis is called steady-state analysis and is the focus of much of the chapter. One requirement for steady-state analysis is that the parameters of the system remain constant for the entire time period. Another requirement for steady-state analysis is that the system must be stable. This means that the servers must serve fast enough to keep up with arrivals—otherwise, the queue can theoretically grow without limit. For example, in a single-server system where all arriving customers join the system, the requirement for system stability is that the arrival rate must be less than the service rate. If the system is not stable, the analytical models discussed in this chapter cannot be used. 14.4 IMPORTANT QUEUEING RELATIONSHIP We typically calculate two general types of outputs in a queueing model: time averages and customer averages. Typical time averages are L, the expected number of customers in the system LQ, the expected number of customers in the queue LS, the expected number of customers in service P(all idle), the probability that all servers are idle P(all busy), the probability that all servers are busy If you were going to estimate the quantity LQ, for example, you might observe the system at many time points, record the number of customers in the queue at each time point, and then average these numbers. In other words, you would average this measure over time. Similarly, to estimate a probability such as P(all busy), you would observe the system at many time points, record a 1 each time all servers are busy and a 0 each time at least one server is idle, and then average these 0’s and 1’s. In contrast, typical customer averages are W, the expected time spent in the system (waiting in line or being served) WQ, the expected time spent in the queue Ws, the expected time spent in service Little’s Formula λ = arrival rate (mean number of arrivals per time period) μ = service rate (mean number of people or items served per time period) U = server utilization (the long-run fraction of time the server is busy) 14.5 ANALYTICAL STEADY-STATE QUEUEING MODELS We will illustrate only the most basic models, and even for these, we provide only the key formulas. In some cases, we even automate these formulas with behind-the-scenes macros. This enable you to focus on the aspects of practical concern: (1) the meaning of the assumptions and whether they are realistic, (2) the relevant input parameters, (3) interpretation of the outputs, and possibly (4) how to use the models for economic optimization. The Basic Single-Server Model (M/M/1) We begin by discussing the most basic single-server model, labelled the M/M/1 model. This shorthand notation, developed by Kendall, implies three things. The first M implies that the distribution of interarrival times is exponential. The second M implies that the distribution of service times is also exponential. Finally, the “1” implies that there is a single server. Mean time between arrivals = 1/ λ The mean service time per customer = 1/ μ ρ = traffic intensity = λ/μ This is called the traffic intensity, which is a very useful measure of the congestion of the system. In fact, the system is stable only if ρ < 1. If ρ ≥ 1, so that λ ≥ μ, then arrivals occur at least as fast as the server can handle them; in the long run, the queue becomes infinitely large—that is, it is unstable. Therefore, we must assume that ρ < 1 to obtain steady-state results. Assuming that the system is stable, let pn, be the steady-state probability that there are exactly n customer in the system (waiting in line or being served) at any point in time. This probability can be interpreted as the long-run fraction of time when there are n customers in the system. For example, p0 is the long-run fraction of time when there are no customers in the system, p1 is the long-run fraction of time when there is exactly one customer in the system, and so on. The Basic Multi-Server Model (M/M/s) Many service facilities such as banks and postal branches employ multiple servers. Usually, these servers work in parallel, so that each customer goes to exactly one server for service and then departs. In this section, we analyze the simplest version of this multiple- server parallel system, labelled the M/M/s model. Again, the first M means that interarrival times are exponentially distributed. The second M means that the service times for each server are exponentially distributed. (We also assume that each server is identical to the others, in the sense that each has the same mean service time.) Finally, the s in M/M/s denotes the number of servers. (If s = 1, the M/M/s and M/M/1 models are identical. In other words, the M/M/1 system is a special case of the M/M/s system.) If you think about the multiple-server facilities you typically enter, such as banks, post offices, and supermarkets, you recognize that there are two types of waiting line configurations. 1. The first, usually seen at supermarkets, is where each server has a separate line. Each customer must decide which line to join (and then either stay in that line or switch later on). 2. The second, seen at most banks and post offices, is where there is a single waiting line, from which customers are served in FCFS order. We examine only the second type because it is arguably the more common system in real-world situations and is much easier to analyze mathematically. There are three inputs to this system: the arrival rate λ, the service rate (per server) μ, and the number of servers s. To ensure that the system is stable, we must also assume that the traffic intensity, now given by ρ = λ /(sμ), is less than 1. In words, we require that the arrival rate λ be less than the maximum service rate sμ (which is achieved when all s servers are busy). If the traffic intensity is not less than 1, the length of the queue eventually increases without bound. The steady-state analysis for the M/M/s system is more complex than for the M/M/1 system. As before, let pn be the probability that there are exactly n customers in the system, waiting or in service. Then it turns out that all of the steady-state quantities depend on p0, which can be calculated from the rather complex formula in equation (14.12). Then the other quantities can be calculated from p0, as indicated in equations (14.13) to (14.17).