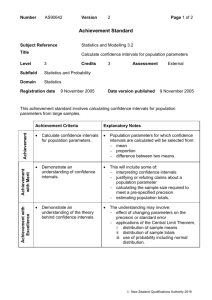
Lab Assignment 8
advertisement

Math 58B - Introduction to Biostatistics
Spring 2015
Jo Hardin
Lab Assignment 8
Lab Goals:
1.
To understand the process of creating t-intervals for both one sample (quantitative
response) and two independent samples (quantitative response).
2.
To understand why we use a t-multiplier in the interval instead of the z-multiplier.
3.
To experience the effect of sample size on the need for a t-multiplier.
4.
To connect power with confidence intervals (note: as before, we can only compute
power if we know the actual value in the alternative hypothesis, and we know that
value to be true).
In class
For the first part of the lab today, we aren't following along an investigation. Instead, you
will create confidence intervals using R to see how well you can capture the true
population parameter. Your code should mimic the simulating confidence intervals applet
we've used in class previously.
The purpose of this lab is to explore standard normal distributions versus t distributions.
Initially, the population is completely known. Additionally, the first part of the lab will
involve a single sample mean from the known population.
Scottish Militiamen (from Chance and Rossman, ISCAM) The data associated with this lab
contains population of chest measurements (in inches) for 5738 Scottish militiamen in the
early 19th century. The observations will be considered to be the population. The data are
at:
militiamen =
read.table("http://pages.pomona.edu/~jsh04747/courses/math58/Math58Data/MILIT
IAMEN.TXT", sep="\t", header=TRUE)
militiamen = unlist(militiamen)
Note 1: if you can't remember what an ISCAM function does, pass it the argument "?". Also,
remember to look at the back of each chapter for R summaries.
load(url("http://www.rossmanchance.com/iscam2/ISCAM.RData"))
iscamsummary("?") # page 187
## Error in iscamsummary("?"): iscamsummary(x, explanatory, digits)
## This function calculates the five number summary, mean, and standard
deviation
## of the quantitative variable x
## Optional: A second, categorical variable can also be specified
## and values will be calculated separately for each group.
## Optional: Specify the number of digits in output to be different from 3.
Note 2: You should be writing your R code in a script file (in RStudio) or in a text editor
(e.g., Notepad). Ideally your file will be titled something like ``rcodelab7.r" or something
equally descriptive. Then you can go back to remember what you did if need be.
.1. Generate three histograms by typing the following commands into R. Describe what each
histogram represents. It may help to type par(mfrow=c(3,1)) so that all three histograms
are on the same page. Note that all of the histograms are on the same scale.
hist(militiamen,xlim=c(33,48))
hist(sample(militiamen,5),xlim=c(33,48))
mil.smean <- c()
for( i in 1:10000){
mil.samp <- sample(militiamen,5)
mil.smean <- c(mil.smean,mean(mil.samp))
hist(mil.smean,xlim=c(33,48))
}
Explain each of these three histograms to your neighbor.
.2. Compute 10000 95% confidence intervals as follows: First, repeatedly draw samples of
size 5 from the population and compute the mean and standard deviation of each sample.
mm.mean <- c()
mm.sd <- c()
for(i in 1:10000){
mil.samp <- sample(militiamen,5)
mm.mean <- c(mm.mean,mean(mil.samp))
mm.sd <- c(mm.sd,sd(mil.samp))
}
Next, use the standard normal distribution multiplier 𝑧 ∗ (1.96) to compute the lower
endpoint and upper endpoint of each such interval.
lower<-mm.mean - 1.96 * sd(militiamen)/sqrt(5)
lower[1:10]
##
##
[1] 38.40343 38.20343 38.60343 36.80343 38.40343 37.00343 37.20343
[8] 39.40343 38.80343 38.40343
upper<-mm.mean + 1.96 * sd(militiamen)/sqrt(5)
upper[1:10]
##
##
[1] 41.99657 41.79657 42.19657 40.39657 41.99657 40.59657 40.79657
[8] 42.99657 42.39657 41.99657
Notice that the standard deviation of the entire population is used in the above
computation. Finally, count how many of these intervals do not contain the population
mean.
sum(mean(militiamen) < lower)
## [1] 186
sum(mean(militiamen) > upper)
## [1] 284
What is the true population average of the chest measurements? How many of the 10000
confidence intervals above captured the true mean? How many would you expect to
capture the true mean? Do the confidence intervals all have the same width?
.3. Assume you didn't know the population standard deviation, as is highly likely in real
world applications. What would you use instead of sd(militiamen)? Hint: you've already
computed it! Using that substitution, find endpoints of 10000 new confidence intervals.
How many of these new confidence intervals contain the true mean? How many would you
expect to contain the true mean? Do the confidence intervals all have the same width?
.4. It looks like the standard normal distribution did not provide an appropriate multiplier
when the population standard deviation was not known. Instead of 1.96, find the
appropriate multiplier 𝑡 ∗ from the t distribution using the R function iscaminvt. Repeat the
computations in 3., continuing to assume that the population standard deviation is
unknown. How many of this third batch of 10000 confidence intervals contain the true
mean? How many would you expect to contain the true mean? Do the confidence intervals
all have the same width?
.5. Summarize the properties of the three different kinds of intervals computed using: z
with known population standard deviation, z with unknown population standard deviation,
and t with unknown population standard deviation. What do you think would happen if
you used t with a known population standard deviation?
To turn in
Follow up from the militiamen:
.1. Consider the following two statistics:
stat1<-(mm.mean-39.832)/(2.05/sqrt(5))
stat2<-(mm.mean-39.832)/(mm.sd/sqrt(5))
Make boxplots and histograms for each of the two statistics (making 4 separate plots is
fine, you might want to use the command par(mfrow=c(2,2))). Remember to use freq=F
in the histogram plot so that we get the density instead of the actual count. Also, within the
histogram and boxplot commands, use xlim=c(-10,10) to force all 4 plots to have the same
x-axis limits.
For each of the histograms (one for stat1, one for stat2) overlay a standard normal curve
using the following command directly after each of the histogram functions
hist(stat1, freq=F, xlim=c(-10,10))
lines(seq(-4,4,.1),dnorm(seq(-4,4,.1),0,1))
Comment on the fit of the normal curve to the tails of each of the two histograms. Also,
calculate the percent of both statistics which are above 1.96 or below -1.96. The first bit of
the command is below, but you'll need to extend the code to count everything you need.
sum(stat1 > 1.96) / length(stat1)
this command
# convince yourself that you understand
## [1] 0.0186
.2. By giving as much commentary as you think necessary (and the results from the plots
and intervals above), explain to someone who hasn't done this lab why the normal
multiplier (i.e., 1.96) doesn't "work" for creating confidence intervals, but the 𝑡-multiplier
(i.e., 2.77) does "work". Your answer should have something to do with the coverage rate of
the confidence intervals (that is what I mean by "work"). That is, you might start your
discussion by saying that "A 95% confidence interval should...".
(Moving forward) Two independent samples:
Consider the set up in Investigation 3.9. The two files
oz17 =
unlist(read.table("http://pages.pomona.edu/~jsh04747/courses/math58/Math58Dat
a/oz17.txt", sep="\t"))
oz34 =
unlist(read.table("http://pages.pomona.edu/~jsh04747/courses/math58/Math58Dat
a/oz34.txt", sep="\t"))
contain (let's pretend) the two populations from where these data came. The following R
code generates 10000 random samples from each of the two populations. Notice the
sample sizes.
diff.mean = c()
oz17.sd = c()
oz34.sd = c()
for(i in 1:10000){
oz17.samp = sample(oz17,20)
oz34.samp = sample(oz34,17)
diff.mean = c(diff.mean,mean(oz17.samp) - mean(oz34.samp))
oz17.sd = c(oz17.sd,sd(oz17.samp))
oz34.sd = c(oz34.sd, sd(oz34.samp)) }
.3. What is the true difference in population means? Adding code similar to that of the
militiamen, compute 10000 95% confidence intervals (for the true difference in means)
using the two populations' true standard deviations. How many of these 10000 confidence
intervals contain the true difference in population means? How many would you expect to
contain the true difference in population means?
.4. If you didn't know the two populations' standard deviations, what would you use
instead? Compute 10000 new 95% confidence intervals using the best possible estimate of
standard error that you have and the same multiplier as above (1.96). The following code
may be useful:
diff.sd = sqrt(oz17.sd^2 / 20 + oz34.sd^2 / 17)
Count how many of your intervals contain the true difference in population means. How
does that compare with how many intervals should contain the true difference?
.5. Repeat the computations in 4., but replace 1.96 with the appropriate multiplier from the
t distribution (use iscaminvt). Count how many of your intervals contain the true
difference in population means. How does that compare with how many intervals should
contain the true difference?
.6. Recall that a confidence interval contains all values of the parameter for which we would
not reject the null hypothesis in favor of a two sided alternative hypothesis. Consider the
null hypothesis 𝐻0 : 𝜇17 − 𝜇34 = 0. How many of your confidence intervals in 5. do not
contain zero? What is the approximate power of this hypothesis test? Explain. (Remember,
here we know the true difference in population means; that is, we know the specific
alternative hypothesis to use in computing the power. You should mention the specific
alternative hypothesis in your explanation.)
Hint: go back to the definition of power. This problem will take very little additional R code.



![The Average rate of change of a function over an interval [a,b]](http://s3.studylib.net/store/data/005847252_1-7192c992341161b16cb22365719c0b30-300x300.png)

