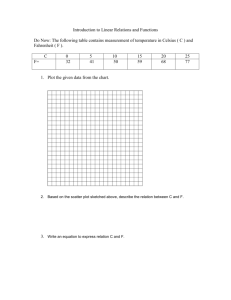
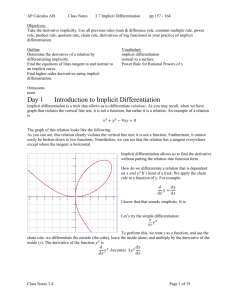
and we showed
advertisement

To begin, we reviewed the questions from Talking Points. Our first example was 𝑔(𝑥) = 𝑙𝑛(𝑥 + 2) and we showed that there are two fixed points for this function by graphing it along with the line 𝑦 = 𝑥. This is so because 𝑔(𝑥) and 𝑓(𝑥) intersect twice. Being a fixed point means that your input equals your output. We started with a guess of 𝑥0 = 0 and showed (with more iterations) how 𝑥𝑛 gets closer to the fixed point value 𝑝 = 1.14619. We then took the 1 derivative of 𝑔(𝑥) and found it to be ′(𝑥) = . We discussed how the 𝑥+2 derivative evaluated at 𝑥 = 1 is attracting and the derivative evaluated at 𝑥 = −1 is not attracting. Our next example was 𝑔(𝑥) = 2𝑥(1 − 𝑥). We took the derivative of this 1 function and evaluated it at the fixed point 𝑝 = and saw an example of a 2 numerical analysis quadratic function. Similarly we looked at 𝑔(𝑥) = 3𝑥(1 − 𝑥). We took the derivative of this function 2 and evaluated it at the fixed point 𝑝 = and saw that the function may converge, 3 and if it does, it will very slowly. (It was noted that over the next couple of weeks, we will look at the general function 𝑔(𝑥) = 𝑎𝑥(1 − 𝑥). We will change the value of 𝑎 and observe what happens to the fixed points.) We then looked at the graphical reason why fixed points are the same for the function and its inverse (problem 2a from Talking Points). For 2b, considering the fact that a function and its inverse have the same fixed points, there is a theorem from calculus that says that inverses have reciprocal slopes. With the inverse function, you do the same iterations, but backwards, so if the function attracts, 1 the inverse repels. For example, 𝑚1 = attracts, while 𝑚2 = 2 repels. 2 We defined inverse and then showed that any fixed point of a given function is also a fixed point of its inverse. It was also shown that if |𝑔′(𝑝)| < 1 then |ℎ′(𝑝)| > 1, hence the opposing characteristics. It was noted that there are dangers when the derivative is equal to zero. Moving on to composition functions, we began to discuss problem 3 from Talking Points. Taking the composition is like taking two steps at once. If ℎ = 𝑔(𝑔(𝑥)), then ℎ calculates every other value of 𝑥𝑛 , so you get a subsequence. By using our work from problem 3, we showed that if 𝑝 is a fixed point of 𝑔, then 𝑔(𝑝) = 𝑝 and ℎ(𝑝) = 𝑔(𝑔(𝑝)) = 𝑔(𝑝) = 𝑝 and therefore 𝑝 is a fixed point of ℎ. Helen asked about the property of the composition function taking two steps at once. She wanted to know what happens in the case of the problem that we 1 discussed in a previous class that bounced back and forth between and 2. To 1 2 address this question, we looked at the function 𝑔(𝑥) = . We found the fixed points to be 𝑝 = ±1. Then ℎ(𝑥) = 𝑔(𝑔(𝑥)) = 1 1 𝑥 𝑥 = 𝑥. Therefore all values of 𝑥 are fixed points and furthermore ℎ has more fixed points than 𝑔. Summing up our Fibonacci discussion, we looked at the Talking Points related to the topic. We reproduced the Fibonacci sequence in Excel and then showed (by induction) that ∑𝑛𝑘=0 𝐹𝑘2 = 𝐹𝑛+1 𝐹𝑛 − (𝐹1 − 𝐹0 )𝐹0 for any 𝐹0 , 𝐹1 . Moving along to matrices, it is noted that capital letters will represent matrices and 𝑥⃗ will represent a column vector. It is further noted that all vectors will be column vectors unless otherwise noted. Next, we looked at an example using Fibonacci numbers and matrices. If 𝑥⃗𝑛 = 𝐹 𝐹 𝐹 [ 𝑛+1 ] and 𝑥⃗0 = [ 1 ] we showed that 𝑥⃗𝑛+1 = [ 𝑛+2 ] = 𝐴𝑥⃗𝑛 . As a result, we 𝐹𝑛 𝐹0 𝐹𝑛+1 𝑛 got 𝑥⃗𝑛 = 𝐴 𝑥⃗0 . We used this in an example with 𝑛 = 12. Our discussion about matrices resulted in a linear algebra review. We discussed that a matrix is singular if the inverse does not exist, the determinant of the matrix is zero and 𝐴𝑥⃗ = 0 has a nontrivial solution (𝑥⃗ ≠ ⃗0⃗). We also discussed that a matrix is non-singular if it has an inverse, the determinant does not equal ⃗⃗ only. zero, and 𝐴𝑥⃗ = 0 has the trivial solution 𝑥⃗ = 0 We did some examples and it was noted that in order to make a singular matrix, make the rows and the columns multiples of each other. ⃗⃗ that I didn’t quite (There was a drawing showing arrows to and from 𝑥⃗ and 0 understand.) Our discussion moved on from matrices to eigenvalues and eigenvectors. The definition of an eigenvalue was given and a few comments were made: (1) 𝐴 must be a square matrix (otherwise the dimensions wouldn’t match up) (2) 𝑥⃗ ≠ ⃗0⃗ is essential (because if any 𝜆 would work, the definition becomes meaningless) (3) 𝜆 = 0 is permissible (then 𝐴𝑥⃗ = 0 ∙ 𝑥⃗ = ⃗0⃗ has a nontrivial solution, then 𝐴 is singular and the determinant of 𝐴 is zero) (4) eigenvectors are not unique (because if 𝑥⃗ is an eigenvector, then so is 𝑐𝑥⃗ for any constant 𝑐 ≠ 0.) We derived the equation for a characteristic polynomial, which is 𝑝(𝜆) = det(𝜆𝐼 − 𝐴), and stated that eigenvalues are the roots of 𝑝; 𝑝(𝜆) = 0. We followed this definition with some examples.