David Goldberg CS 1950 Proposal Paper The directed study task
advertisement

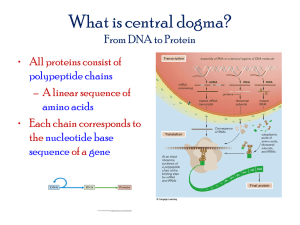
David Goldberg CS 1950 Proposal Paper The directed study task that I am doing is programming for the biology department. Specifically, I am coding a program that parses RNA sequences and searches for patterns. RNA sequences are the building blocks for life. Every cell of every living thing on this planet has RNA. From the leaf of the tallest tree, to the smallest bacterium, all need RNA to function. Similarly to lines of code, RNA is instructions on how to make the most fundamental parts of living things. RNA is read by ribosomes in cells, which then are used to create a functional product. This product is the proteins for which all life is built by. Needless to say, RNA is an important topic in biology. Unlocking what sequences correspond to what attributes is a very significant quest. For my research project, the code I will be programming searches RNA containing 2 patterns that the scientist has deemed important. This is done to help understand more about RNA. For example, understanding what causes some attributes to be expressed in the person, while other times that attributes, despite appearing in the RNA, is skipped, due to something in the code preceding it. The RNA sequences that I will be dealing with include the possible characters: ‘A’, ‘C’, ‘G’, ‘T’, ‘Y’, ‘R’, ‘N’. In the RNA code itself, only ‘A’, ‘C’, ‘G’, and ‘T’ exist. In the RNA sequence they represent both the amino acids that make up what the RNA is trying to build as well as procedural information, with commands such as ‘start transcribing here’ and ‘end transcribing here’ . Y, R, N are used only used in the pattern that is inputted by the user. A ‘Y’, stands for either a ‘C’ or a ‘T’. An ‘R’ corresponds to either an ‘A’ or a ‘C’. And a ‘N’ corresponds to any of them, so ‘A’, ‘C’, ‘G’, or ‘T’ will be an acceptable character. The current program reads in for a flat file containing all of the RNA sequence. The file is broken up into several parts. There are 2 RNA sequences that correspond to one another. One is the sequence in human RNA; the other is the sequence in mouse RNA. Both sequences have their own identification number, which is separated from the sequence by a tab. The 2 sequences are separated from the next pair of sequences by a new line character. The RNA sequences are broken up into 3 different parts, each separated by an ‘X’. The 3 parts are called the up intron, the exon, and the down intron, in that order. For this research project, I will be improving an already existing code. The code that I will be improving is very minimalistic in its functionality. The existing code has no user interface. The 2 patters being looked for are entered as command line arguments. It will not accept ‘Y’, ‘R’, or ‘N’ characters. In order for the user to have the functionality that those characters provide they need to manually construct their definition. For example, an ‘N’, which can be any of the 4 characters, ‘A’, ’C’, ’G’, and ’T’, the user would need to put this in the pattern [A|C|G|T]. The file containing all of the RNA sequences contains both human RNA patters, and the corresponding pattern in a mouse RNA sequence. However, the current program only checks for the patterns in the human RNA sequence. Also, it only checks the down intron for the patterns and completely ignores both the up intron and the exon. The 2 patterns are checked for in the last 75 characters of the down intron. This distance is fixed. Also, the patterns are searched for separately. Therefore, the matches found can overlap. This overlap is undesirable. Lastly, the patterns where both matches are found are stored in a results file. The human RNA sequences identification number is put into the file, followed by a tab, followed by the 75 character string that was searched. There are several desired changes to this program, which I will implement. My improved program will provide a better user interface, over just the command line arguments. My program will add the functionality of the ‘Y’, ‘R’, and ‘N’ characters. My program will also give the user the ability to control what part of the RNA sequence they are searching in, either the up intron, the down intron, or the exon. My program will also check the mouse RNA for the matching patter. In addition to that it will print to the results file if it matches just the human, just the mouse, or both. My program will also greatly increase the options available to the user in how they define their search. Instead of having a fixed value for the section of the sequence that it is checking, currently is 75, the user can specify this length. My program will also allow the user to specify whether this section is taken from the beginning or the end of the part of the RNA that is being checked. (i.e. length of 50, for the beginning of the up intron.) Also, the patterns will be checked for matches together, so the distance between the patters will also be able to be specified by the user. Finally, the readability of the results file will be improved. My program will make the matches apparent. This will be done by separating the parts of the sequence. There will be tabs in between the beginning of the sequence and the first match, the first match and the middle of the sequence, the middle of the sequence and the second match, and the second match and the end of the sequence. My program will also shave off part of the beginning and end of the sequence, farther away from the matches, to make it more readable. There are several problems I have the potential to encounter while working on this project. First off, the current program is written in Perl, as will my updated version of it. The problem with this is I do not have any knowledge of Perl, or any other scripted language at this point. Also this program relies on somewhat complex regular expressions. I do not currently have any knowledge of regular expressions. More general problems will be the difficulty in understanding of the material I am working with, as well as trying to ascertain what the person I am working for is looking to be done. The last biology course I took was in 9 th grade, so my knowledge of biology is rather limited. Therefore, it may be harder to figure out what exactly they are talking about and that will make my job of figuring out what needs to be done harder. Similarly to my lack of biology knowledge, the people I am working for have a limited knowledge of computer science. Therefore, I will also need to make sure that what they are looking to be done can in fact be done.