Lecture: 6
advertisement

Lecture: 6
Interpolation and Curve Fitting to Measured Data
The lecture discusses the basic aspects of polynomial interpolation and curve fitting to
measured data.
Introduction: Statement of the problem
We know the values of a function f(x) at a set of points x1, x2,..., xN, but
we don’t have an analytic expression for f(x) that lets us calculate its
value at an arbitrary point.
The task is to estimate f(x) for arbitrary x.
If the desired x is in between the largest and smallest of the xi’s, the
problem is called interpolation. If x is outside that range, it called
extrapolation.
There is main question: how to find some plausible functional form. The
form should be sufficiently general so as to be able to approximate large
classes of functions which might arise in practice. By far most common
among the functional forms used are polynomials, rational functions,
trigonometric functions and related Fourier methods. Also we consider
radial function interpolation methods and method based on finite-element
approach which give interpolated values f(x) that do not, in general, have
continuous first or higher derivatives.
The number of points (minus one) used in an interpolation scheme is
called order of the interpolation. Increasing the order does not
necessarily increase the accuracy, especially in polynomial interpolation.
Interpolation can be done in more than one dimension and is often
accomplished of one-dimensional interpolation.
1.
Interpolation
using
Newtons’s
,
Gauss’s
and
Stirling’s
interpolating polynomials
Suppose that we are given a set of a data points yi = (xi, fi), i = 0, 1, ... ,
n, giving the values of an unknown function f at evenly spaced points x0,
x1, ..., xn a distance h apart and that we wish to estimate the value of f at
t some points. Newtons’s general interpolating polynomial P n(x) has a
form
y(x) = y0 + qy0 + q(q-1) 2y0 /2+ q(q-1)...(q-n+1) ny0 /n
where
q = (x-x0)/h,
yi = yi+1 - yi
2yi = yi+1 - yi
Stirling’s formula is obtaining by averaging Gauss’s forward and
backward formulas:
P(x) = y0 + qy0 + q(q-1) 2y-1 /2 + (q+1)q(q-1) 3y-1 /3 +
+ (q+1)q(q - 1)(q - 2) 4y-2 /4 + (q+2)(q+1)q(q-1)(q-2) 4y-2 /5+
... + (q + n-1)...(q-n+1) 2n-1y-(n-1) /(2n-1) + (q+n-1)...(q-n) 2ny-n /(2n-1)
P(x) = y0 + qy-1 + q(q+1) 2y-1 /2 + (q+1)q(q-1) 3y-2 /3 +
+ (q+2)(q+1)q(q-1) 4y-2 /4 +... + (q+n-1)...(q-n+1) 2n-1y-n /(2n1)
+ (q+n)(q+n-1)...(q-n+1) 2ny-n /(2n)
Thus, we have
P(x) = y0 + q(y-1 + y0)/2+ q2/2 2y-1 + q(q2-12)/3 (3y-2 + 3y-1)/2 +
q2(q2-12)/4 4y-2 + q(q2-12)(q2-22)/5 (5y-3 + 5y-2)/2+
q2(q2-12)(q2-22)/6 6y-3+...
q(q2 -12)(q2-22)...[q2 - (n - 1)2]/(2n -1) (2n-1y-n + 2n-1y-(n-1))/2 +
q2(q2 -12)...[q2 - (n - 1)2]/(2n) 2ny-n
2. Polynomial Interpolation and Extrapolation
Through any two points there is a unique line. Through any three points,
a unique quadratic. Et cetera. The interpolating polynomial of degree N -
1 through the N points y1 = f(x1), y2 = f(x2), ... , yN = f(xN) is given
explicitly by Lagrange’s classical formula,
P(x) = y1(x - x2) (x - x3)... (x - xN)/ (x1 - x2) (x1 - x3)... (x1 - xN) +
y2(x - x1) (x - x3)... (x - xN)/ (x1 - x2) (x1 - x3)... (x1 - xN) +... +
yN(x - x1) (x - x2)... (x - xN-1)/ (x1 - x2) (x1 - x3)... (x1 - xN_!)
(1)
It is not wrong to implement the Lagrange formula straightforwardly,
but it is better to use Neville’s algorithm [1].
Let P1 be the value at x of the unique polynomial of degree zero (i.e., a
constant) passing through the point (x1,y1), so P1 = y1. Likewise define
P1, P2 , ... , PN. Now let P12 be the value at x of the unique polynomial
of degree one passing through both (x1, y1) and (x2, y2). Likewise P23 ,
P34 , ... , P(N-1)N . Similarly, for higher-order polynomial through all N
point, i.e., the desired answer.
The various P’s form a “tableau”, for example, with N= 2,
x1
: y1 = P1
P12
x2
: y2 = P2
(2)
Neville’s algorithm is a recursive way of filling in the numbers in the
tableau a column at a time, from left to right. It is based on the
relationship between a “daughter” P and its two “parents”,
Pi(i+1)...(i+m) = (x - xi+m) Pi(i+1)...(i+m-1) + (xi - x) P(i+1)(i+2)...(i+m) /
(xi - xi+m)
(3)
This recurrence works because the two parents already agree at points
xi+1 ... xi+m-1.
An improvement on the recurrence (3) is to keep track of the small
differences between parents and daughters, namely to define
(for m = 1,2,..., N-1),
Cm,i = Pi...(i+m) - Pi...(i+m-1)
Dm,i = Pi...(i+m) - P(i+1)...(i+m)
Then one can derive from (3) the relations
Dm+1,i = (xi+m+1 - x )( Cm,i+1 - Dm,i ) / (xi - xi+m+1)
Cm+1,i = (xi - x )( Cm,i+1 - Dm,i ) / (xi - xi+m+1)
At each level m, the C’s and D’s are the corrections that make the
interpolation one order higher. The final answer P1...N is equal to the
sum of any yi plus a set of C’s and/or D’s that form a path through the
family tree to the rightmost daughter.
3. Rational Function Interpolation and Extrapolation
A rational function passing through the m + 1 points (xi, yi) ... (xi+m,
yi+m) is given by formula
Ri(i+1)...(i+m) = P(x)/Q(x) = (p0 + p1x + px )/(q0 + q1x + ... qx) (4)
Since there are + + 1 unknown p’s and q’s , we must have
m+1= ++1
(5)
For the interpolation problem, a rational function is constructed so as to
go through a chosen set of tabulated functional values.
Bulirsch and Stoer algorithm
A tableau like that of equation (2) is constructed column by column,
leading to a result. The Bulirsch-Stoer algorithm [1] produces the socalled diagonal rational function, with the degrees of numerator and
denominator equal ( if m is even) or with the degree of the denominator
larger by one (if m is odd). The algorithm is summarized by a recurrence
relation exactly analogous to equation (3) for polynomial approximation:
Ri(i+1)...(i+m) = R(i+1)...(i+m)
+ (R(i+1)...(i+m) - Ri...(i+m-1) ) / {(x - xi)/(x - xi+m)
(1 - (R(i+1)...(i+m) - Ri...(i+m-1) )/ (R(i+1)...(i+m) - R(i+1)...(i+m-1) ))- 1}
(6)
This recurrence generates the rational functions through m + 1 points
from the ones through m and ( the term R(i+1)...(i+m-1) in equation 6) m -1
points. It is started with
Ri = yi
and with
R = [Ri(i+1)...(i+m) with m = -1] = 0
The recurrence (6) can be converted to one involving only small
differences.
4. Interpolation in two or more dimensions
The simplest interpolation in two dimensions is bilinear interpolation on
the grid square.
Fig. 1.
In multidimensional interpolation, we seek an estimate of f(x1,...,xn) from
an n-dimensional grid of tabulated values f.
For one dimension interpolation formula is well known:
f(x1) = (1-x1)f(0) +x1f(1).
In two dimensions, we imagine that we are given a matrix of functional
values. Bilinear interpolation on the grid square is
f(x1,x2) = (1-x1) (1-x2)f(0,0) + x1(1-x2)f(0,0) + (1 - x1)x2f(0,1) +
x1x2f(1,1).
To write this formula in compact form we define indexes k1 and k2 with
1 - xi, ki =0
c(ki) =
xi, ki =1.
Bilinear interpolation gives the interpolation formula
1
f(x1,x2) =
c(k1)c(k2)f(k1,k2)
k 1,k 2 0
For n variables the interpolating polynomial is writen as
1
f(x1,...,xn) =
c(k1)...c(kn)f(k1,...,k2)
k 1,...,k 2 0
Fig. Bilinear interpolation of tooth data
---------------------------------------------------------------------------------------CURVE FITTING TO MEASURED DATA
Here we discus the basic aspects of curve fitting to measured data.
Introduction
In engineering and computer graphics, curve fitting techniques plays a
very important role. In the most general sense, curve fitting involves the
determination of a continuous function
y = f(x)
(1)
which results in the most “reasonable” or “best” fit of experimentally
measured values of (x1,y1), (x2,y2), and so forth.
Figure 1. Data suggesting straight line
Figure 2. Data suggesting quadratic equation
In fitting a curve to given data points, there are two general approaches.
One is to have the approximating curve pass exactly through all of the
known data points, which can be used when the data values are known to
be very accurate.
The other one uses an approximating function, which graphs as a smooth
curve having the general shape suggested by the distribution of the data,
but not actually passing through all of them. For example, the plot of the
x and y values shown in Figure 1 suggests a straight-line fit, using a
function such as
y = c1 + c2x.
(2)
The constants c1 and c2 can be determined using a least-squres criterion,
which will result in a best-fit straight-line representation of the
experimental data. Figure 2 might suggest a curve fitted by the pure
quadratic equation.
Method of Least Squares
Let us suppose that for function f(x) experimental data values b0, b1, ...,
bn are given for x-coordinates a0, a1, ..., an and a fitting function (x)
has some known or assumed form,
(x) = A00(x) + A11(x) +... + App(x) , p < n ,
(3)
such that the sum of the squares of the deviations of the measured y
values from the function values is a minimal:
=
n
2i
i 0
where
i = bi - A00(ai) - A11(ai) -... - App(ai)
This sum will be either a maximum or minimum if /Ak = 0. Since the
second derivative is always positive setting
n
n
i 0
i 0
/Ak = A0 k(ai) o(ai) +... + Ap k(ai) p(ai) -
n
k(ai)bi = 0 ,
i 0
k =0, 1, ..., p,
gives us the set of coefficients Ak.
Curve fitting with polynomials
In approximating functions for which experimentally determined values
are available at discrete points, the most commonly used form of the
fitting function (3) is a polynomial function such as
A0xp + A1xp-1 +... + A p-1x + Ap,
which is obtained by letting
0 = xp, 1 = xp-1, ... , p-1= x, p= 1
Considering the residuals 0 , 1, ..., n , for a least-squares fit, it follows
that
0 = b0 - (A0ap0 + ... + Ap)
1 = b1 - (A1ap1 + ... + Ap)
...
n = bn - (A0apn + ... + Ap)
For the sum of the squares of the residuals (statistic called the residual
variance)
n
=
2i
i 0
to be a minimum , it is necessary that
/A0 = 0, /A1 = 0, ...
which may be written as a system of linear forms to calculate A0, A1, ... ,
Ap
n
n
n
i 0
i 0
i 0
A0 a2pi+ A1 a2p-1i+... + Ap api =
n
n
n
i 0
i 0
i 0
n
b i ap i
i 0
A0 a2p-1i+ A1 a2p-2i+... + Ap ap-1i =
n
biap-1i
i 0
...
n
n
i 0
i 0
A0 api+ A1 ap-1i+... + Ap1 =
n
bi
i 0
Mean error M of the estimate can be expressed as
n
M = E/(n +1) = 1/(n + 1)
[bi - (A0api + ... + Ap)]2
i 0
Example 1. Determine coefficients A0,A1, A2 for the quadratic equations
that fits the given data:
a1 = 0.15, a2 = -0.05, a3 = 0.05, a4 = 0.15
b1 = 4401, b2 = 4709, b3 = 4983, b4 = 5220
Solution.
Coefficients A0,A1, A2 can be find from the sytem
4
A0 a4i
4
i1
i1
A2 a2i =
i1
4
=
i1
4
a2 i b i
4
A1 a2i
A0 a2i
4
ai b i
i1
4
A2 1 =
i1
i1
4
bi
i1
in other words, from
0.001025A0 + 0.05A2 = 240.70
0.05A1 = 136.55
0.05A0 + 4A2 = 19313
which yields the coefficients
A0 = -1781.2, A1 = 2731, A2 = 4850.5
One of the problem encountered in polynomial curve fitting is
determining what degree of polynomial will provide the optimum fit to
the data. The least-squares fit of a polynomial of degree n-1 to n data
points, for example, will pass exactly through all of the points. However,
the resulting curve is generally not a smooth curve through the points,
because such a function would not only include the “noise” in the data,
but would also very likely fluctuate considerably between the data points.
In practice, the following procedure is suggested. First try a polynomial
for which m = 2, which is a straifght-line fit, and note the value of the
standart error of the estimate
e = (
n
[y(xi) - yi]2/(n - m))
i 0
where
yi = y data values corresponding to xi
y(xi)= y data values corresponding at x = xi
n = number of data points
m = number of values in polynomial (degree of polynomial plus 1).
Then try a second-degree polynomial for which m = 3, and again note
the value of e. Typically, the second try will yield a smaller standard
error then the first, although it may sometimes show an increase.
Curve fitting with Fourier series
As a second special case of the use of Equation (3) consider
trigonometric fits or the best fit of a Fourier series. In using series in
practical applications we must obviously use a finite number of terms
rather than an infinite number. A series consisting of a finite number of
terms is referred to as a truncated series, and such a series containing p
terms to represent f(x) will be only approximately equal to f(x), that is,
f(x) b0 +
p
k 1`
p
bk cos kxi +
k 1`
ak sin kxi
In the least-squares procedure for the best fit of a trigonometric series to
experimental data, the coefficients bk are determined from the equation
/bk =
p
n
cos kxi[yi - (b0 +
i 0
k ' 1`
p
bk’ cos k’xi + bk’ cos k’xi)] = 0 (4)
k ' 1`
For n + 1 iniformly distributed values xi contained in the interval 0,2,
that is
x0 = 0, x1 = 2/n, ... , xn-1 = 2(n - 1)/n, xn = 2
and for different k, k’ we note that
n
i 0
n
n
sin kxi = cos kxi
i 0
sin kxi sin k’xi =
i 0
n
n
cos kxi cos k’xi =
i 0
sin2 kxi =
i 0
n
cos2 kxi = (n + 1)/2,
i 0
n
cos kxi sin k’xi = 0
i 0
n
i 0
n
1=
cos2 kxi = n + 1
i 0
Having determined these summations, we obtain
n
bk = 2/(n+1)
yi cos kxi
i 0
In just the same way, we find
n
ak = 2/(n+1)
yi sin kxi
i 0
n
b0 = 1/(n+1)
yi
i 0
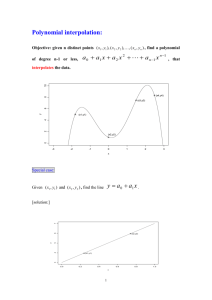
---------------------------------------------------------------------------------------Exercise
1. Determine a linear function fitted to the following data points by the
least square method.
-------------------i
xi
yi
-------------------1
1.0 2.0
2
1.5 3.2
3
2.0 4.1
4
2.5 4.9
5
3.0 5.9
-------------------