Comparing the Discrete and Continuous Logistic Models
advertisement

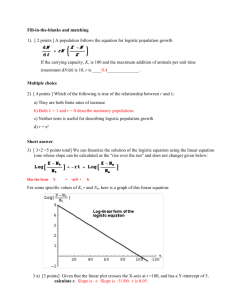
Comparing the Discrete and Continuous Logistic Models Sheldon P. Gordon Department of Mathematics Farmingdale State College Farmingdale, NY 11735 gordonsp@farmingdale.edu Mailing Address: 61 Cedar Road, E. Northport, NY 11731 Abstract The solutions of the discrete logistic growth model based on a difference equation and the continuous logistic growth model based on a differential equation are compared and contrasted. The investigation is conducted using a dynamic interactive spreadsheet. Keywords logistic growth, discrete logistic model, continuous logistic model, comparison of solutions One of the more “fun” topics that have entered the mathematics curriculum in the last few decades is the logistic growth model. Originally developed by the Belgian biologist Verhulst to model the growth of a population subject to an inhibiting effect as the population size increases toward a maximum sustainable level, the model has since been applied to a host of other applications in many different fields. For instance, it is used to model the spread of technological innovations and the sales of most products. There are actually two different logistic models that are in wide use. The original model is a continuous one based on the differential equation P’ = aP – bP2 and a subsequent discrete model based on the difference equation ∆Pn = aPn – bPn2. (1) In both models, a represents the initial growth rate of the population P or other phenomenon and b represents the inhibiting coefficient that eventually comes into play to slow the increase in the population growth when the population size becomes large relative to the maximum sustainable level (or product saturation or whatever else corresponds to an eventual horizontal asymptote as time passes). (2) In both models, the solution has the same logistic Figure 1: Graph of a Logistic shape shown in Figure 1. Curve (3) In both models, the limiting value L turns out to be equal to a/b. The horizontal asymptote corresponds to there being no further change in the population, so either P’ = 0 or ∆P = 0 and therefore P = L = a/b. (4) In both models, the solution achieves its inflection point at a height of ½a/b, or midway to the limiting value. The inflection point represents the point where the function is growing most rapidly, so that either P’ or ∆P must achieve its maximum and both are quadratic functions of P with negative leading coefficients, so the maximum occurs midway from P = 0 to P = L. The solution of the continuous model can be found by integrating the differential equation, using either partial fractions (perhaps the only reason for including partial fractions in calculus) or by the simple substitution P = 1/x (which totally avoids the need to do partial fractions). The solution is P(t ) P0 L P0 ( L P0 )e at , where P0 is the initial population and L = a/b is the limit to growth. There is no known closed form solution to the discrete logistic model; however, the defining difference equation can be rewritten as ∆Pn = Pn+1 - Pn = aPn – bPn2, so that Pn+1 = (1 + a)Pn – bPn2, and all subsequent terms after P0 can be readily calculated. That brings us to the subject of this article: Just how do the two solutions compare to one another? Or perhaps more importantly: How do the two solutions differ from one another? To begin, let’s define what we mean by compare, since one solution is continuous while the other is discrete. We will consider the values of the continuous solution only for the points t = 0, 1, 2, …, so that we can have a direct comparison between the values predicted by the two models. Moreover, consider the differential equation for the continuous model. We can approximate the derivative P’ using a Newton difference-quotient, so that P ( t h ) P (t ) h P’(t) = aP(t) – bP(t)2 . If we take the step size h = 1, we get the approximation P(t + 1) – P(t) aP(t) – bP(t)2 and this is effectively equivalent to the difference equation model. However, a step-size of h = 1 is rather large, which suggests that there should be major differences in the values predicted by the two models. To answer the two questions posed above, the author has developed a Dynamic Interactive Graphical (DIGMath) spreadsheet in Excel investigate precisely how the two solutions compare to 300 P one another. It is available for downloading from the 250 author’s website [1], along with a large variety of other 200 DIGMath modules for College Algebra/ Precalculus, Calculus, and Statistics. This spreadsheet allows the user 150 to change both of the parameter values a and b using 100 sliders, and also to change the initial population value P0, 50 with a slider. As a result, one has the ability to see the t, n 0 resulting changes in the two populations on a continuous 0 20 40 60 80 100 basis for ease of comparison. For instance, in Figure 2, Figure 2: Comparing the continuous (solid) and the discrete (dotted) logistic curves we show the results of this spreadsheet based on a = 0.50, b = 0.0018, and P0 = 19. With these parameter values, the maximum sustainable population is L = a/b = 284, which is represented in the figure by the upper horizontal line; the respective inflection points occur at a height of ½L = 142 and this is represented in the figure by the lower horizontal line. Clearly, the two curves are very similar, but one can see that there are some significant differences between them in the portion where both are increasing rapidly. On the other hand, if we change the parameters to a = 0.30, b = 0.0017, and P0 = 100, we get the solution curves shown in Figure 3, and the two curves are virtually indistinguishable from one another, even though the window used is somewhat smaller that that in Figure 2 to make the difference more apparent.. 200 P To get a better feel for how the two solutions 180 compare, the spreadsheet also produces a second graph, 160 140 one showing the difference in the two solutions as a 120 function of time. The result corresponding to the 100 parameters used for Figure 2 are shown in Figure 4 and 80 those corresponding to Figure 3 are shown in Figure 5. 6040 One of the striking features of the graph in Figure 4 is the 20 t, n 0 presence of a pair of spikes, or surges, in the values of the 0 20 40 60 80 100 difference function, but only a single spike in Figure 5. (We note that it is also possible to get situations where the differences are essentially identically zero with no Figure 3: Continuous (solid) vs. discrete (dotted) logistic curves for other indication of such a spike.) parameter values Difference of Populations vs. Time Difference of Populations vs. Time 30 0 0 20 40 60 80 100 25 20 -1 15 10 -2 5 0 0 20 40 60 80 100 -5 -3 Figure 4: Graph of the difference between the continuous and discrete logistic curves. Figure 5: Graph of the difference between a different set of continuous and discrete logistic curves To understand what is happening here, think about the situation. Both solutions start with the same initial population value P0, so we can think of them as being pinned to the same starting point and so the initial difference must be zero. Moreover, both tend to the same horizontal asymptote and so, eventually, the difference between the two solutions must become virtually zero. Furthermore, as mentioned previously, the point of inflection for both solutions corresponds to the level where each function is increasing most rapidly. Therefore, it makes sense that the greatest discrepancy between the two functions would occur at about the time that each is passing its point of inflection. Think of the curve that reaches this level first (to the left) as the “leading” function and the other as the “trailing” function. If you compare the graphs in Figures 2 and 4 and in Figures 3 and 5, it is evident that the principal spike in each occurs at the same time as the respective pair of functions pass the horizontal line representing the height of the inflection point. In fact, the greater the horizontal separation between the leading and trailing functions at this level, the more time that the leading function has to grow at its greatest rates, and so the taller the spike is likely to be. As for the second, minor spike in Figure 4, we speculate that this may also be related to the horizontal separation between the two curves at the inflection point level. Again, the larger the separation, the further ahead the leading function gets, and so the closer to the horizontal asymptote it gets before the trailing function reaches its maximum rate of growth. However, that means that the leading function would then be growing at a relatively much slower rate and so the trailing function will be growing considerably faster. In turn, it is reasonable to expect that the trailing function, which has a lot of ground to make up, will be growing so rapidly that it sometimes overshoots the leading function before it subsequently slows relatively quickly as it too begins to approach the horizontal asymptote. This would account for the second spike. Incidentally, if the two functions have minimal separation when they cross the inflection point level, it is reasonable to expect that there will not be a significant spike. In conclusion, we note that, based on the above two examples and many others that the author has examined, the two solutions are surprisingly close to each other. Consequently, it does not seem to make a significant difference which model we opt to work with, and so the choice may be based either on whether it is more convenient or desirable to have a closed form expression in terms of t or a recursion relation in terms of n from which all subsequent terms in the solution sequence can be calculated easily. The former approach can certainly be desirable, if not necessary, in performing various algebraic analyses, as in [2] where the author uses the closed form expression for a logistic function to calculate the doubling time for such a function as a function of time t. On the other hand, most practical applications are likely better served by the recursive approach. Finally, the author is reminded of Richard Hamming’s famous quote: “The purpose of computing is insight, not numbers.” Certainly, the use of Dynamic Interactive Graphical spreadsheets such as the one described here supports that perspective solidly! We encourage interested readers to experiment with these ideas personally and with their students to gain those deeper insights personally. Acknowledgement The work described in this article was supported by the Division of Undergraduate Education of the National Science Foundation under grant DUE-0442160. However, the views expressed are those of the authors and do not necessarily reflect those of the Foundation. References 1. The DIGMath Excel spreadsheet Comparing Discrete and Continuous Logistic Models can be found at and downloaded from farmingdale.edu/~gordonsp. 2. Gordon, Sheldon P., Doubling Times for Non-Exponential Families of Functions, (submitted). Biographical Sketch Dr. Sheldon Gordon is SUNY Distinguished Teaching Professor of Mathematics at Farmingdale State College. He is a member of a number of national committees involved in undergraduate mathematics education. He is a co-author of Functioning in the Real World and Contemporary Statistics: A Computer Approach and co-editor of the MAA volumes, Statistics for the Twenty First Century and A Fresh Start for Collegiate Mathematics: Rethinking the Courses Below Calculus. He is also a co-author of the texts developed under the Calculus Consortium based at Harvard.