What Can Be Inferred From A Kiss
advertisement

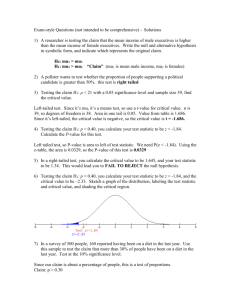
Rectangularity: Part III. Hypothesis Test on the Population Mean Purpose: This activity is intended to illustrate properties of hypothesis testing and describe how to perform hypothesis tests on a mean. Statistical Guide: We want to test a hypothesis about a population mean, . The null hypothesis is H 0 : 0 , where 0 is the hypothesized value for . The data are assumed to be a random sample of size n from a population that has a normal distribution with unknown standard deviation, . If the sample size is large, the assumption of normality is not so crucial. However, outliers are always a concern. From the sample data, we calculate the sample mean, x , and the sample standard deviation, s. We base x 0 our decision about on the standardized sample mean, tn 1 . This is the test statistic, and s n under H 0 it has a t-distribution with n 1 degrees of freedom. We calculate the p-value (observed level of significance) for the test. The p-value depends on how the alternative hypothesis is expressed: (1) If H A : 0 , then the p-value is the area to the right of the observed test statistic, under the H 0 model. (2) If H A : 0 , then the p-value is the area to the left of the observed test statistic, under the H 0 model. (3) If H A : 0 , then the p-value is the sum of the area to the left of negative the absolute value of the observed test statistic and the area to the right of the absolute value of the observed test statistic, under the H 0 model. The p-value is the probability, computed under the assumption that H 0 is true, of obtaining a test statistic value at least as favorable to H A as the value that actually resulted from the data. If the pvalue is small enough, H 0 is rejected. Rejecting the null hypothesis, when in fact it is true, is called a Type I error. The significance level, , is the chance of committing a Type I error. If the p-value , H 0 is rejected. If the pvalue , H 0 is not rejected. Failing to reject the null hypothesis, when in fact it is not true, is called a Type II error. The chance of committing a Type II error is . The chance of rejecting the null hypothesis, when in fact it is false, is called the Power of the test. The Power is 1 . 1 Instructions: The Population of Rectangles Sheet shows a population of size 100 consisting of rectangles of varying areas. Each square counts as one unit towards a rectangle’s area. The true average (mean) area of the rectangles in this population is 6.26. 1. Select a simple random sample of 25 rectangles (sample with replacement -- so that it is possible to select the same rectangle more than once). 2. List your selected rectangle numbers and the corresponding areas in the table below. Rectangle Number Rectangle Number Area Area 3. Calculate the mean and the standard deviation of the areas of your sampled rectangles: 2 Questions: Throughout answering the following questions, remember that the true value of = 6.26. 1. Test H 0 : 9 versus H A : 9. Use p-values (observed significance levels) to perform the tests. Take calculations to two significant digits. Since H 0 is false, a correct decision would be to reject H 0 . An incorrect decision would be to fail to reject H 0 . (This would be a Type II error.) (a) Use a 5% level of significance ( .05). calculated test statistic = p-value = Suppose your calculated test statistic = - 2.6, then you can find the p-value by the following R commands: > n=25 > test.stat = -2.6 > > pt(test.stat,n) [1] 0.007712645 Repeat the above p-value calculations for a total of 30 times. Each p-value is coming from a random sample of size 25, thus the 30 p-values are all different. Write your 30 p-values on Part III a. Stem-and-leaf Plot for thirty p-values. decision = P(Type II error) = . For the 30 times, Power = 1 . For the 30 times, 1 (b) Use a 20% level of significance ( .20). calculated test statistic = p-value = decision = P(Type II error) = . For the 30 times, 3 Power = 1 . For the 30 times, 1 (c) Explain how to interpret a Type II error rate in terms of repeatedly performing the procedure of selecting a sample and using the sample data to test a null hypothesis that should be rejected. (d) Explain how the Type I error rate ( ) is related to the Type II error rate ( ). In addition, give an intuitive explanation as to why this relationship holds. 2. Test H 0 : 6.26 versus H A : 6.26. Use p-values (observed significance levels) to perform the tests. Take calculations to two significant digits. Since H 0 is true, a correct decision would be to fail to reject H 0 . An incorrect decision would be to reject H 0 . (This would be a Type I error.) (a) Use a 5% level of significance ( .05). calculated test statistic = p-value = Suppose your calculated test statistic = 1.29, then you can find the p-value by the following R commands: > n=25 > test.stat = 1.29 > > 2*pt(-1.29,n) [1] 0.2088562 Repeat the above p-value calculations for a total of 30 times. Each p-value is coming from a random sample of size 25, thus the 30 p-values are all different. Write your 30 p-values on Part III b. Stem-and-leaf Plot for thirty p-values. decision = expected number of rejections of H 0 for the 30 times = number of rejections of H 0 for the 30 times = (b) Use a 20% level of significance ( .20). calculated test statistic = 4 p-value = decision = expected number of rejections of H 0 for the 30 times = number of rejections of H 0 for the 30 times = (c) Explain how to interpret a Type I error rate in terms of repeatedly performing the procedure of selecting a sample and using the sample data to test a null hypothesis that should not be rejected. 3. Explain why we used the sample mean of n 25 rectangle areas and not the sample mean of n 5 or n 15 rectangle areas to perform our hypothesis tests. 5 Parts I, II, and III. Population of Rectangles: (The population of rectangles sheet is adapted from Scheaffer et al. 1996.) 6 Parts I, II, and III. Histogram and Frequency Table of the Areas of the Rectangles in the Population: Histogram of the Areas of the Rectangles in the Population: 25 15 10 5 24.0 21.0 22.0 23.0 17.0 18.0 19.0 20.0 13.0 14.0 15.0 16.0 9.0 10.0 11.0 12.0 5.0 6.0 7.0 8.0 2.0 3.0 4.0 0 1.0 Frequency 20 Area AREA 1.00 2.00 3.00 4.00 5.00 6.00 7.00 8.00 9.00 10.00 11.00 12.00 14.00 15.00 18.00 20.00 21.00 22.00 24.00 Total Frequency 23 11 11 5 4 8 4 7 3 7 1 5 2 1 3 1 1 1 2 100 Frequency Table of the Areas of the Rectangles in the Population: 7 Part III a. Stem-and-leaf Plot for thirty p-values: .0| .0| .1| .1| .2| .2| .3| .3| .4| .4| .5| .5| .6| .6| .7| .7| .8| .8| .9| .9| 1| 8 Part III b. Stem-and-leaf Plot for thirty p-values: .0| .0| .1| .1| .2| .2| .3| .3| .4| .4| .5| .5| .6| .6| .7| .7| .8| .8| .9| .9| 1| 9