Bootstrapping
advertisement

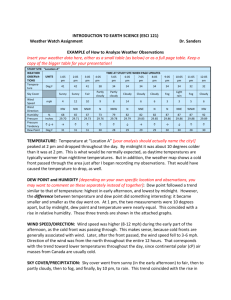
Bootstrapping. A way to estimate a sampling distribution. Example: Recall the pigeons data. Birds were released on cloudy days and sunny days. The measurement was the absolute error angle as the bird disappeared over the horizon. cloudy 8 10 sunny 6 48 7 51 38 9 52 43 17 53 18 55 45 18 56 57 22 57 73 28 58 76 32 63 83 35 72 36 83 105 42 91 112 42 97 126 42 141 48 Research hyp: Birds released on cloudy days will tend to have larger error angles than those released on sunny days. Mann-Whitney Test and CI: cloudy, sunny N 13 28 cloudy sunny Median 73.00 45.00 Point estimate for ETA1-ETA2 is 25.00 95.2 Percent CI for ETA1-ETA2 is (0.00,54.00) W = 344.0 Test of ETA1 = ETA2 vs ETA1 > ETA2 is significant at 0.0241 Recall further: W in the Minitab output is the sum of ranks of the first named column (cloudy in this case). 85% CI-Boxplot 140 120 comb 100 80 60 40 20 0 cloudy sunny subs Hence, W = sum of ranks of cloudy data = 344. There are other forms for the MWW which were discussed in class. As an exercise, go back to those formulas and show that an estimate of p = P(C > S) is given by: (n 1) U W 344 (14) p P(C S ) 1 .695 n1 n2 n1 n2 2n 2 13x 28 56 where n1 = 13 (cloudy) and n2 = 28 (sunny). This is an estimate and, hence, has a sampling distribution. We do not assume a null hypothesis is true in this case. A 90% confidence interval is determined by finding the .05 quantile and the .95 quantile of the sampling distribution to capture the middle 90% of the sampling distribution. Again from earlier in the course we approximated the sampling distribution of the MWW statistic (under the null hypothesis) using permutations of the combined data. This will no longer work. Since we don’t assume the null hyp, we can’t assume that all permutations are equally likely. (Permutation Prinicple) How does the sampling distribution of MWW arise? a. We generate a sample from the population of cloudy birds. b. We generate a sample from the population of sunny birds. c. We compute MWW and store it. d. Repeat a, b, and c B = 1000 times and then we have 1000 values of the MWW statistic. e. The histogram of the 1000 values of MWW is an approximation to the sampling distribution. The difficulty is that we do not have the two populations to take samples from. Solution: We let the sample of cloudy bird data represent (estimate) the cloudy bird population. So we can sample from the cloudy bird sample (with replacement). This called a bootstrap sample. In Minitab the command is in the menu: Calc>random data>sample from columns: Sample 13 'cloudy' c22; Replace. Similarly for the sunny data. Hence, we approximate the sampling distribution of MWW by carrying out a-e above with sampling from populations replaced by sampling from the cloudy and sunny samples. The following macro implements the bootstrap for P(Y > X): MTB > %bootp ‘cloudy’ ‘sunny’ c21 (c21 contains the bootstrap values of p) ESTIMATE OF P(Y > X) AND 90% CONFIDENCE INTERVAL Data Display .05-quantile Pr(Y>X) .95-quantile 0.530220 0.692308 0.837912 Histogram of P(Y>X) 90 80 Frequency 70 60 50 40 30 20 10 0 40 0. 48 0. 53 56 0. 0. 64 69 72 0. 0. 0. P(Y>X) 80 0. 84 0. 88 0. 96 0. Exercise: Get the coins data from website. Get the CI-Boxplots. Get a 90% confidence interval for P(first > fourth). Get the histogram approximation of the sampling distribution of p and mark confidence interval and estimate on the histogram.