Statistical models for secure steganographic systems
advertisement

Digital Rights Management Seminar
SS 2006
Statistical models for Secure Steganography
Systems
Submitted by,
Muthiyalu Jothir Navaneetha Krishnan
271120
15th May 15, 2006
Table of Contents
1. Introduction .............................................................................................. 3
2. Steganography.......................................................................................... 4
3. Information Theory .................................................................................. 5
4. Security Model – Proposed ...................................................................... 6
5. One Time Pad Systems ............................................................................. 10
6. Universal Data Compression .................................................................... 10
7. Conclusion and Future work ..................................................................... 12
1.
Introduction:
Until recently, information hiding techniques received very much less attention
from the research community and from industry than cryptography. This situation is,
however, changing rapidly and the first academic conference on this topic was organized
in 1996.
The main driving force is concern over protecting copyright; as audio, video and
other works become available in digital form, the ease with which perfect copies can be
made may lead to large-scale unauthorized copying, and this is of great concern to the
music, film, book and software publishing industries. At the same time, moves by various
governments to restrict the availability of encryption services have motivated people to
study methods by which private messages can be embedded in seemingly innocuous
cover messages. There has therefore been significant recent research into ‘watermarking’
(hidden copyright messages) and ‘fingerprinting’ (hidden serial numbers or a set of
characteristics that tend to distinguish an object from other similar objects); the idea is
that the latter can be used to detect copyright violators and the former to prosecute them.
But there are many other applications of increasing interest to both the academic and
business communities, including anonymous communications, covert channels in
computer systems, detection of hidden information, Steganography, etc.
In this report, we are particularly interested in one of the above mentioned
applications namely, Steganography. We discuss in depth the challenges in designing a
secure steganographic system. This report is based on the paper, “An InformationTheoretic Model for Steganography”, Christian Cachin, MIT Labs, US. As the name
suggests the paper discusses a mathematical model for achieving security in a
steganographic system with passive adversary. Cachin has chosen an information
theoretic approach for this model.
The report is organized as follows. A brief discussion about Steganography is presented
in the second section. We also discuss the key difference between Steganography and
Cryptography. In the third section, we present the important concepts of information
theory. Then we discuss the proposed security systems in the fourth section. The
performance of one time pad systems is discussed in fifth section. We also discuss briefly
about compression algorithm in sixth section.
2.
Steganography
Steganography is the art and science of writing hidden messages in such a way
that no one apart from the intended recipient knows of the existence of the message.
Steganography works by replacing bits of useless or unused data in regular computer files
(such as graphics, sound, text, HTML, or even floppy disks) with bits of different,
invisible information. This hidden information can be plain text, cipher text, or even
images.
Steganography sometimes is used when encryption is not permitted. Or, more
commonly, Steganography is used to supplement encryption. An encrypted file may still
hide information using Steganography, so even if the encrypted file is deciphered, the
hidden message is not seen. Special software is needed for Steganography, and there are
freeware versions available at any good download site.
Steganography (literally meaning covered writing) dates back to ancient Greece,
where common practices consisted of etching messages in wooden tablets and covering
them with wax, and tattooing a shaved messenger's head, letting his hair grow back, then
shaving it again when he arrived at his contact point. Generally, a steganographic
message will appear to be something else: a picture, an article, a shopping list, or some
other message - the covertext. Classically, it may be hidden by using invisible ink
between the visible lines of innocuous documents, or even written onto clothing. In WW2
a message was once written in morse code along two-colored knitting yarn. Another
method is invisible ink underlining, or simply pin pricking of individual letters in a
newspaper article, thus forming a message. It may even be a few words written under a
postage stamp, the stamp then being the covertext.
2.1 Steganography Vs Cryptography
Steganography is different from cryptography, where the existence of the message
itself is not disguised, but the content is obscured. Steganogrpahy could be considered as
the dark cousin of cryptography. Cryptography assures privacy whereas Steganography
assures secrecy. For e.g. Sending of encryted credit card details over the internet is well
known to a mailicious user. But, the actual content is randomized or confused and hence
not revealed. But, in Steganography the fact that the credit card details is being sent is
kept secretly (as the message or the image appears innocent). The advantage of
steganography over cryptography alone is that messages do not attract attention to
themselves, to messengers, or to recipients. An unhidden coded message, no matter how
unbreakable it is, will arouse suspicion and may in itself be incriminating, as in some
countries encryption is illegal.
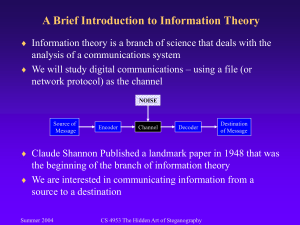
3. Information Theory
Our ability to transmit signals at billions of bits per second is due to an inventive
and innovative Bell Labs mathematician, Claude Shannon, whose “Mathematical Theory
of Communications” published 50 years ago in the Bell System Technical Journal has
guided communications scientists and engineers in their quest for faster, more efficient,
and more robust communications systems. If we live in an “Information Age,” Shannon
is one of its founders.
Shannon’s ideas, which form the basis for the field of Information Theory, are
yardsticks for measuring the efficiency of communications systems. He identified
problems that had to be solved to get to what he described as ideal communications
systems – a goal we have yet to reach as we push today the practical limits of
communications with our commercial gigabit- and experimental terabit-per-second
systems.
Information Theory regards information as only those symbols that are uncertain
to the receiver. For years, people have sent telegraph messages, leaving out non-essential
words such as "a" and "the." In the same vein, predictable symbols can be left out, like in
the sentence, "only infrmatn esentil to understandn mst b tranmitd." Shannon made clear
that uncertainty is the very commodity of communication.
3.1 Entropy
The amount of information, or uncertainty, output by an information source is a
measure of its entropy. In turn, a source's entropy determines the amount of bits per
symbol required to encode the source's information
According to Shannon, the entropy of an information source S is defined as:
H(S) = i pi log (1 / pi )
where pi is the probability that symbol Si in S will occur.
log (1 / pi ) indicates the amount of information contained in Si, i.e., the number of
bits needed to code Si.
For example, in an image with uniform distribution of gray-level intensity, i.e. pi
= 1/256, then the number of bits needed to code each gray level is 8 bits. The
entropy of this image is 8.
3.2 Relative Entropy
Suppose there is a random variable with true distribution p. Then we could
represent that random variable with a code that has average length H (p). However, due
to incomplete information we do not know p; instead we assume that the distribution of
the random variable is q. Then the code would need more bits to represent the random
variable. The difference in the number of bits is denoted as D (p | q). The quantity
D (p | q) comes is known as the relative entropy.
D (p || q) is a measure of the inefficiency of assuming that the distribution is q when the
true distribution is p.
4.
Security Model – Proposed
The work by Cachin addresses the issues of designing a secure Steganographic system in
the presence of passive adversaries. As mentioned in previous sections, the system is
modeled using the statistical parameters like entropy, relative entropy etc. Steganography
with a passive adversary is illustrated by Simmons' “Prisoners' Problem".
4.1 Prisoners’ Problem
The two prisoners Alice and Bob wish to devise an escape plan. Eve, the warden
(the adversary) will observe the messages exchanged between them. She would take
extreme measures if she found out the secret escape plan and would transfer them to a
high-security prison as soon as she detects any sign of a hidden message. Alice and Bob
succeed if Alice can send information to Bob such that Eve does not become suspicious.
In the case of hiding information from active adversaries, the existence of a
hidden message is publicly known, such as in copyright protection schemes.
Steganography with active adversaries can be divided into watermarking and
fingerprinting. Watermarking supplies digital objects with an identification of origin; all
objects are marked in the same way. Fingerprinting, conversely, attempts to identify
individual copies of an object by means of embedding a unique marker in every copy that
is distributed. Since most objects to be protected by watermarking or fingerprinting
consist of audio or image data, these data types have received most attention so far. A
number of generic hiding techniques have been developed whose effects are barely
perceptible for humans but can withstand tampering by data transformations that
essentially conserve its contents.
We now introduce some of the basic terminologies of information hiding. Cover text is
the original unaltered message or image. Digital images are preferred for information
hiding as there is more capacity or space for securely hiding the information; the sender
Alice tries to hide an embedded message by transforming the cover text using a secret
key. The resulting message is called the stegotext and is sent to the receiver Bob. Similar
to cryptography, it is assumed that the adversary Eve has complete information about the
system except for a secret key shared by Alice and Bob that guarantees the security.
4.2 Hypothesis Testing
A security notion that is based on hypothesis testing is proposed by Cachin: The
task of the adversary is to decide whether the message sent by Alice is an original
covertext C or contains an embedded message and is a stegotext S. For making such a
decision, the adversary makes use of the statistical information (probability distribution
etc) of the cover text and compares it with the Stego text. This type of problem analysis is
investigated in statistics and in information theory as “hypothesis testing." The quantity
relative entropy is used as the basic measure of the information contained in an
observation. Thus, the author proposes to use the relative entropy D (PC | PS) between PC,
(Probability distribution of Cover text C) and PS (Probability distribution of stego text S)
to illustrate the security of a steganographic system against passive attacks. It could be
inferred that, the Stegosystem would be perfectly secure if the cover text and stegotext
distributions are equal. This fact also implies that if D (PC | PS) = 0 then the system
would be perfectly secure.
There are two hypotheses H0 and H1 for an observed measurement Q. The task of
hypothesis testing is to decide which of the two hypotheses holds true for Q. A decision
rule is a binary partition of Q that assigns one of the two hypotheses to each possible
measurement q Є Q. There are two possible errors that can be made in a decision. A type
I error is said to be done for accepting hypothesis H1 when H0 is actually true and a type
II error for accepting H0 when H1 is true. The probability of a type I error is denoted by ά,
the probability of a type II error by β.
The basic information measure of hypothesis testing is the relative entropy or
discrimination between two probability distributions PQ0 and PQ1, defined as
Properties of Relative entropy,
1. Relative entropy of two distributions is always non-negative
2. Is equal to 0 iff the two distributions are equal.
4.3 Secure Stego System
Fig. I
The Fig. I illustrates the stego system under discussion. At the sender’s end, Alice
could either send the unaltered cover text C or use the Key (K), private random source
(R) and embed the message E and send the resulting stego text S. The passive adversary
Eve observes a message that is sent from Alice to Bob. She does not know whether Alice
sends legitimate cover text C or stegotext S containing hidden information for Bob. Alice
is assumed to operate strictly in one of two modes: either she is active (and her output is
S) or inactive (sending cover text C).
Bob must be able to recover E from his knowledge of the stegotext S and from the
key K.
4.3.1 Observations
1. H (S / CEKR) = 0 With the presence of C, E, K and R the event of having a stego
text is certain. Hence the entropy is zero. The stegotext is determined uniquely by Alice's
inputs.
2. H (E) > 0. There is uncertainty about the embedded message.
3. H (E / SK) = 0. Bob must be able to decode the embedded message uniquely given the
Stegotext S and the key K.
4.4 Security Definition
Eve, upon observing the message sent by Alice, has to decide whether Alice is
active or inactive. Since this task is a hypothesis testing problem, the security of a
stegosystem is quantified in terms of the relative entropy distance between PC and PS.
Definition 1: A stegosystem as defined above with cover text C and stegotext S is called
Є –secure against passive adversaries if
D (PC|PS) < Є:
If Є = 0, the stegosystem is called perfectly secure.
Eve's decision process for a particular decision rule is given by a binary partition (C0,
C1) of the set C of possible cover texts. Alice is active if and only if the observed
message c is contained in C1. If Eve fails to detect that she observed stegotext S, she
makes a type II error whose probability is denoted by β.
In this paper the author assumes that Eve never makes a type I error and accuses
Alice of sending hidden information when she is inactive (ά = 0).
Theorem 2: “In a stegosystem that is Є-secure against passive adversaries, the
probability β that the adversary does not detect a hidden message and the probability ά
that the adversary falsely detects a hidden message satisfy
d (ά , β ) < Є:
In particular, if ά = 0, then
β = 2-Є
In a perfectly secure system we have D (PC | PS) = 0 and therefore PC = PS; thus, Eve can
obtain no information about whether Alice is active by observing the message.”
4.4.1 External Information
In the presence of external information like weather forecast etc, the cover text
distribution might be influenced. The modified stegosystem with external information Y,
cover text C, and stegotext S is called Є -secure against passive adversaries if
D (PC|Y || PS|Y ) ≤ Є
5. One Time Pad Systems
As per the proposed model we obtain a secure stegosystem if the distributions of
cover text and stegotext are close without knowledge of the key. It has been discussed
that the distribution of cover text is known and design corresponding embedding
functions. Based on this concept, one time pad systems could be perfectly stego secure
provided, the cover text consists of independent and uniformly random bits. Assume the
cover text C is a uniformly distributed n-bit string for some positive n. The key generator
chooses the n-bit key K with uniform distribution and sends it to Alice and Bob. By using
a simple bitwise XOR of the particular n-bit message e and K, we obtain the S. Thus,
S=e
K, and
e=S
K.
Bob can decode by computing
The resulting stegotext S is uniformly distributed in the set of n-bit strings and therefore
D (PC | PS) = 0. Thus, the one-time pad provides perfect steganographic security if the
cover text is uniformly random.
The one-time pad system could be considered as a basic scheme of visual
cryptography. In this technique a monochrome picture is hidden by splitting it into two
random layers of dots. When these are superimposed, the picture appears. It is also
possible to produce two innocent looking pictures such that both of them together reveal
an embedded message.
5.1 Disadvantage
It is very obvious that the result of the one time pad system would be a sequence
of random bits. No warden will allow the prisoners to exchange random malicious
looking messages. Hence, the one time pad system, though statistically secure, will be
practically impossible to use in this scenario.
6. Universal Data Compression
The main difference between Traditional data compression techniques and
Universal data compression algorithms is that, in Traditional data compression such as
Huffman coding, require a priori knowledge about the distribution of the data to be
compressed. For example the probability distribution etc, should be known before the
compression algorithms begins. A universal data compression algorithm works when the
information is not known priory or if it changes with time. Essentially, this is
accomplished by learning the statistics of the data during operation as more and more
data is observed. The best known examples of universal data compression are the
algorithms by Lempel and Ziv.
6.1 Willems' Repetition algorithm
The parameters of the algorithm are the block length L and the delay D (also
considered as the memory size). Consider a stationary binary source X producing {Xt} =
{x1, x2…}. The output {Yt} is mapped to blocks of length L. Encoding is done at
repetition time, the length of the interval since its last occurrence. Within this period, if
there is any repetition occurs, the block of last occurrence is encoded. It should also be
noted that the block should be with the delay or memory D. If it occurs outside, then the
symbol is transmitted plain. The encoding is done according to following relation,
6.2 Modification for Information Hiding
In an attempt to hide information in a digital image, it would be best to put the
hidden data into location which has the highest Repetition time and lowest probability
distribution. Since the distribution of the whole image is not known priori, we try to find
some area on the image y’(t) which has almost the same distribution as y(t).
Information hiding takes place if the encoder or the decoder encounters a block y
such that ty ≥ 1 / ρ. If this is the case, bit j of the message m is embedded in y’ according
to,
According to the above equation, the r(y) is a ranking based on average repetition time. If
XOR operation results in 0, then the same y will be coded (as r-1(r(y)) will be y). If it
results in 1, then the next rank is taken and continued. The decoder computes the average
repetition times in the same way and can thus detect the symbols containing hidden
information and decode E similarly. Compared to data compression, the storage
complexity of the encoding and decoding algorithms is increased by a constant factor, but
their computational complexity grows by a factor of about L due to the maintenance of
the ranking.
7. Conclusion and Future work
In this report, we have investigated the proposal of Cachin for a secure
stegosystem. As discussed in the above sections, the model is based on information
theory. The stego system was assumed to have a passive adversary whose task was to
perform the hypothesis testing. Based on the statistically information of the cover text
and the stegotext the adversary decides whether Alice is active or not. Hence, it is the job
of Alice to make sure that these statistical parameters are either not disturbed or is within
a specified threshold (Є). By ensuring such measures the stego system achieves
maximum security.
In this paper, Cachin does not consider the influence of the factor called
Embedding Distortion DEmb. The future work done by Joachim et al. addresses this issue
and tries to enhance this model to decrease the DEmb
References
1. Christian Cachin, “An Information - Theoretic Model for Steganography”,
Cambridge, 1998.
2. Joachim, Bernd, “A Communications Approach to Image Steganography”,
Proceedings of SPIE, Jan 2002.
3. Thomas M. Cover, Joy A. , “Elements of Information Theory”, III Series