Before dropping so-called insignificant variables from a regression
advertisement

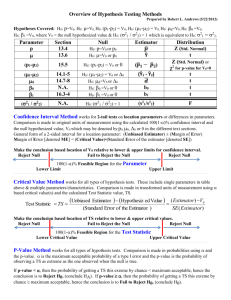
Before dropping so-called insignificant variables from a regression, we should be careful to consider (1) what we mean by “insignificant” (2) why the variable was included in the first place and (3) what potential costs arise if the variable is excluded. To practitioners, insignificance arises if the p-value is less than some “critical” level, like .05. In probability theory, this is the level of Type I error; it is the risk of falsely rejecting the null hypothesis (Ho: the coefficient on the variable is insignificantly different from zero). Lower p-values mean lower probabilities of committing Type I errors. In a capital murder trial, for example, the judge typically instructs the jury to consider the evidence in such a way as to minimize this risk – that is, to minimize the risk of convicting an innocent defendant (the null is that the defendant is not guilty). In statistical tests, the 5% level sets a limit on the amount of risk we are willing to take. In five out of one-hundred random samples, we’d reject the null incorrectly, i.e., five percent of the time. If we set the p-value lower, say at one percent, then we are making it even harder to reject the null. That is, we are making it harder to commit a Type I error. So, the first question is, what p-value should we select? Well, there’s no answer to that but suppose it is 5%. Then in a standard t-test, we’d conclude that the variable has no explanatory power in the model if the p-value is 0.05001? Probably not. Rather, we’d conclude that the probability of making a Type I error (rejecting the null of zero when we shouldn’t) is slightly higher than we’d otherwise like. But in no way does the decision to reject or not, mean that the variable is somehow uninformative. That’s lesson number one. Now consider why the variable is in there to begin with. Suppose I have a scientific experiment for which the “theory” states that X and Y cause Z. I collect a sample of data on all three and regress Z on X and Y jointly. Suppose the estimated coefficient on X is deemed insignificant because its p-value is 0.0499. Theoretically, this can’t happen (it’s like rejecting gravity because the apple that fell from the tree onto Isaac Newton’s head didn’t fall fast enough). X is supposed to cause Z. But in random samples, there is measurement error and coefficients are necessarily measured imprecisely. Noisy data cause standard errors to rise and t-statistics to fall. So, should we reject X? Or should we say that the contribution X has in explaining Z is measured imprecisely? That’s lesson number two. X was included because it should be there. Even rejecting X’s contribution has risk – in this case 0.0499 risk of Type I error. Because this number is less than 0.05 is not a legitimate reason to exclude X. Which finally brings us to our third consideration on what potential costs there are to excluding a so-called “insignificant” variable. Suppose we go ahead and exclude X. In the statistics literature, X is formally an erroneously excluded variable and so the equation governing Z is now misspecified. Forget that though. Think instead of where X is. X now resides in the error term (it is now part of the unobserved, albeit random, part of Z. The error term in any regression is the composite of all excluded unobserved influences on Z. We usually assume this term is zero on average and uncorrelated with any of the included regressors. Now, it includes X too. Well, if X is correlated with Y, and there is no reason to think otherwise, then excluding X will make the estimate on the coefficient on Y biased. And that’s lesson number three. In sum, the decision to say a variable is insignificant is a subjective choice and practitioners falsely think p-values are somehow objectively applied. They are not. Secondly, so-called insignificance is a statement about precision in estimation and not about causality. So there is absolutely no reason to drop variables whose coefficients are somehow deemed insignificant. Thirdly, dropped variables are now part of the error term and to the extent these dropped variables are correlated with any included regressors then coefficients on those regressors will be estimated with bias. This is a much more serious problem than leaving in regressors with imprecisely estimated coefficients.