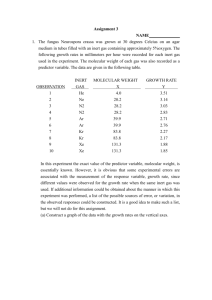
Solutions to PQ2
advertisement

Solutions to practice problems for Exam 2 1. a) 0, 1 and 2 are the parameters; b0, b1 and S2 are the respective estimates. Zero is not a parameter, it is just a number and is a random variable. 2. b) Correct answer is R2, r, and F do not give the proportion of variation explained by the regression model. 3. c) We have been using Spooled = √MSE, so S2 = MSE and S2 is an estimator of 2. 4. c) The df for the t-test = df for error = n – (number of parameters estimated) = n – (p+1) 5. b) It is obvious that you will fail to reject H0 when = 0.05. When gets smaller, the confidence level = (1 – )×100 becomes larger. The larger the confidence level the wider will the confidence interval will be, hence the CI will still include zero, so we will fail to reject Ho for any ≤ 0.05. 6. b) In this case, predicted value of Y will be equal to the sample mean of y’s, i.e., ŷ y for all X values. So X is not a good predictor of Y; we do not know if there is a quadratic relation or not (need to see a plot of the residuals for that). We cannot say “there is NO RELATIONSHIP” since we did not check for other types of relations. Finally, the predictor is X, not Y (Y is the response). 7. d) You need to draw a scatter diagram which indicates that a quadratic fit will be better than a linear fit. The coefficient of X2 should be positive (why?) 8. d) We are looking for association, not causation, between X and Y, so (a) or (b) cannot be true. Since Y depends on X, a change in X will be associated to a change in Y. Also, (c) cannot be true since the question states that “X is found to be highly significant.” 9. a) Remember the additional term (1) in the SE(predictor) which makes it larger, hence the PI is always larger than a CI for the mean response. 2 10. a) Note the ( x* X ) in the formula for the SE. The closer x* is to the sample mean, the smaller the SE will be and hence both PI and CI will be narrower as x* gets closer to the sample mean. [In 2 an old version of notes, the square on ( x* X ) did not appear. Please correct it.] 11. b) The slope gives the average change in Y for one unit increase in X, hence the change in Y will always be , whenever X changes by one unit from any value. It does not depend one the value of Y or the error term and 0 does not affect the values of Y. 12. c) No interaction means the regression lines are parallel, i.e., they have the same slop. The intercepts may or may not be different. Thus there must be one slope but the intercept CAN be more than one. 13. a) When two or more predictors are highly correlated, they do not give any extra information about Y and hence the information provided by such predictors is redundant, not complementary. However, we cannot say that ALL of these predictors are bad (useless), we may need one of them in our model. 14. Using the estimation formula (you should have learned in STA 2023 and will not be given in this test) we obtain SY 54.2 ( 0.774 ) 2.589555556 and SX 16.2 a y bx 874.1 ( 2.589555556 )( 163.5 ) 1297.492333 . Hence the prediction equation is ŷ 1297.49 2.59 X br 15. (i) d. When one of the predictors has a curvilinear relationship with the response we use a quadratic regression model. 15. (ii) m. Influential points are those that can change the direction of the association. 15. (iii) f. We use residual plots to check the assumptions of the regression models. 15. (iv) c. Adjusted R2 is used when comparing different regression models, when the number of predictors in them are different. 15. (v) e. Interaction is used when the effect of one predictor on Y depends on other predictors. 15. (vi) k. R2 gives the proportion of variation in Y explained by the regression model. 15. (vii) l. Residual = y ˆy = observed value of y minus the predicted value for an given value of x. 15. (viii) n. An outlier is a point that lies far from other observed points. 15. (ix) b. Extrapolation (predicting y for a value of X outside the range of observed values of X) can give bad predictions if the conditions (linear relation between X and Y) do not hold for the values outside the range of observed values of X. 15. (x) i. Cause and effect can be erroneously assumed in an observational study. 15. (xi) j. This is how multiple linear regression model is shown. 15. (xii) g. This is how the fitted (or prediction) equation is shown in a multiple linear regression model. 15. (xiii) a. Multicollinearity problem can occur when the information provided by several predictors overlaps (i.e., they are highly correlated). 15. (xiv) h Dummy variables are used in a regression model to represent categorical variables. 16. b) Since the scatter diagram shows no relation between length of life-line and age, correlation between them should be close to zero. 17. b) With a correlation close to zero, we can say that the length of life-line is a poor predictor of age 18. a) We expect F to be close to one since the length of life-line is not a good predictor of age at death. 19. c) Since the length of life-line is not a good predictor of age at death, we might use the average age of death as the predictor of the age of death. 20. b) The null hypothesis specifies that none of the predictors are providing significant information about the response and hence 1 = 2 = … = p = 0. 21. d) The alternative hypothesis specifies that at least one of the predictors is providing significant information about the response and hence at least one of i 0. 22. d) The method of finding estimates of the coefficients of the regression method is called the least squares estimation because it minimizes the sum of the squared errors. 23. c) This is a misuse of causation. More fire fighters are sent to worse fires that cause large financial damages, i.e., firefighters are not the cause of the financial damage but there is another intervening variable (size of fire) that influences both variables (financial damage and number of fire fighters dispatched) 24. a) In this problem response is the number of Elvis impersonators and the predictor is year. Assuming this quotation is the result of a regression analysis, based on data between 1977 and 2007, we are talking about a prediction for the year 2012 which is outside the observed values of the predictor. Hence here we are using extrapolation which does not give reliable results. 25. d) The response variable is sales, denoted by y and it is a quantitative variable. Hence the correct answer is “all of the above.” 26. b) The slope is – 1418. This means as the price (predictor) increases by one dollar, sales will decrease by $1418. 27. d) The intercept is the average value of response (sales) when predictor (price) is zero. But this makes sense when zero is within or close to the values of the predictor used for estimating the coefficients. In this problem since we are talking about sales a price of zero is not within the values of price used in the analysis and hence the intercept should NOT be interpreted. 28. c) R2 gives the proportion of variability in response (sales) accounted for (or explained by) the predictor (price). Hence we can say that 59.70% of variability in sales accounted for (or explained by) price. 29. The correlation coefficient = r Sign of slope R2 59.70% 0.773 . Two 100 100 common mistakes in this type of problems is to ignore the fact that the square root of any number can be either positive or negative and we decide on the sign by looking at the slope (Slope and correlation must have the same sign, why?). Hence r = + 0.773 is NOT the correct answer. The second common problem is the meaning of % (per cent = divide by 100): So R2 = 59.70% = 59.70 / 100 = 0.5970 and hence r = – √0.5970. So 7.73 or – 7.73 are wrong. You should also remember that r (the correlation coefficient) CANNOT be less than – 1 or more than + 1. 30. b) You are asked to predict sales when price = $1.10. Putting this value in the prediction equation we get predicted-sales = 2259 – 1418×1.10 = $699.20 31. a) Yes, since the p-value is small, but the low R2 says there is room for improvement and we may add other predictors to the model to improve it. The values (and the signs) of the slope and the intercept do not give us any information about how good a predictor is, so b and d are wrong.) 32. c) The vertical axis of a residual plot is always the residuals (standardized or not). On the horizontal axis we put the predictor (X) to see if a quadratic term in X may improve the model (it does in this case). 33. c) It seems that a quadratic model will fit the data better, i.e., a simple linear regression model does not seem to be the best model. 34. Both b and c are correct answers, with the understanding that in b X1 = price and X2 = (price)2 or in c we let X = price and hence X2 = (price)2. Note that a is not the correct answer because it ignores the quadratic term (which has a p-value < 0.0005 and hence is significant and d means adding a cubic term (X1X2 = (price)×(price)2 = (price)3. 35. b) To find R2 from the ANOVA we calculate the ratio of SSReg to SST: R2 SS Re g 16 ,060,569 0.8066 80.7% SST 19,911,800 36. d) The test statistic for testing if the coefficient of price2 is significantly different from zero is T defined as T = coefficient/SE(Coefficient). Hence Tcal = 3522.3/436/8 = 8.06. 37. d) as can be seen by the sign of the coefficient for the quadratic term; b is wrong because it means as price increase so does sales, whereas we have a negative slope in the SLR model. If we have to choose between c and d, we choose d (the quadratic model) since the p-values for both coefficients are extremely small (<0.0005). 2 38. Since the prediction equation for the quadratic model is ŷ b0 b1 X b2 X we have ŷ 7990.0 10660 1.10 3522.3 ( 1.10 )2 525.98 39. c) We decide by looking at the p-value for the coefficient of the quadratic term. Since the p-value is (almost) zero, we reject Ho: 2 = 0. Hence the quadratic term should be in the model. 40. a) The coefficient for flyer is 804.12 and it is significantly different from zero as indicated by the corresponding p-value. Hence, on the average sales will increase by 804 units when the product is advertised by a flyer. 41. d) Since the p-value corresponding to display is large (0.558) this variable should not be in the model and hence we cannot interpret the coefficient. 42. a) Since the p-values for both are small, we conclude that both price and price2 are good predictor of sales. 43. c) We must run the regression analysis one more time without display in the model. This may change the estimates of the coefficients. We must also carry out an analysis of residuals to check if the assumptions are satisfied and see if the model can be further improved (although it seems satisfactory with the high R2 values.. 44. b) Since the effect of one of these two predictors on sales may be more than the sum of their individual effects, i.e., there may be significant interaction. 45. d) Note that although this looks similar to b, the error term () in b is wrong since it should not appear in the equation of the fitted line (prediction equation). 46. b) The p-values of all predictors are very small, thus strongly supporting the alternative hypothesis in ANOVA test. 47. d) The p-value reported in the output is for a two-sided alternative; we are asked for a one sided alternative thus should take half of the reported p-value = 0.032/2 = 0.0016. 48. c) The p-value corresponding to papers is the smallest of all the p-values indicating a strong support in explaining the variation in salary. 49. c) The 95% CI for 1 is b1 t × SE(b1) = 1.1031 t × 0.3596. [Note that 3.068 is NOT SE(b1), it is the calculated value of the test-statistic, Tcal for testing Ho: 1 = 0 vs. Ha: 1 0.] 50. c) The df for the t is the df for error = n – p – 1 = 35 – 1 – 4 = 30. 51. d) We assume that the response (Y = Salary) has a normal distribution. 52. a) It seems that there is a very weak increasing linear relationship between age of mother and the weight of baby. 53. d) All of the first three alternatives serve the same purpose, to help us determine if age of mother is a significantly god predictor of the weight of baby. 54. b) Positive, since the linear relation seems to be increasing, but not significantly different from zero since the points are far from the fitted line (and hence the correlation is close to zero). 55. d) Since there is no quadratic term (square of any of the X’s) in the model, it is not a quadratic model (the product term is for interaction). It IS a multiple regression model with dummy variables and uses least squares to estimate the parameters hence all of a, b and c are true statements. 56. c) Since X2 = 0 for those who had prenatal care, that group is the baseline group. 57. d) When we put the values of X2 into the model, it simplifies to y 0 1 X 1 for the baseline (prenatal care) group and y ( 0 2 ) ( 1 3 )X 1 for the “no prenatal care” group. Hence, 3 reflects the change in slope 58. a) Using the simplified models in # 57, we see that 2 is the change in the intercept 59. c) Using the simplified models in # 57, we see that 1 is the slope for the baseline group 60. b) Using the simplified models in # 57, we see that 0 is the intercept for the baseline group. 61. b) We can see that the slopes of the lines for the two groups seem to be significantly different from zero, since the (visually) fitted lines are not parallel to the x-axis. We are not so sure about the interaction in c, there may or may not be interaction. Similarly, a is wrong since the coefficient of age (slope) is different from zero and d is wrong since there is one correct statement. 62. a) We need to test for the change in slope since we are interested in the rate at which weight increases, hence we will test Ho: 3 = 0 vs. Ha: 3 0. 63. a) Here we will use the estimates of the parameters in the second equation of # 57 since we are interested in those who did not receive prenatal care (X2 = 1). So the prediction equation is wt ( 1.84 1.79 ) ( 0.53 0.003 )X 1 0.05 0.527 X 1 64. b) Here we will use the estimates of the parameters in the first equation of # 57 since we are interested in those who did receive prenatal care (X2 = 0). So the prediction equation is wt 1.84 0.53X 1 65. c) Since the two fitted lines intersect, we should use a model with interaction. 66. d) In ANOVA we test Ho: 1 = 2 = 3 = 0 vs. Ha: At least one of ’s 0. 67. d) Since the p-value < 0.0005, we conclude that at least one of the ’s 0, i.e., at least one of the variables (including the variable for interaction) in the model is a good predictor of weight. 68. a) We would like to find if a model with interaction term is appropriate so we must first test if there is any significant interaction, i.e., test Ho: 3 = 0 vs. Ha: 3 0. 69. d) The p-value corresponding to the test Ho: 3 = 0 vs. Ha: 3 0 is 0.098. Thus we will reject H0 at = 0.10 but not at other levels of significance. This is not a strong support. Hence none of the options in this question is the correct conclusion of the test. 70. a) Since there is very weak support for interaction, we will exclude it from the model and run the analysis again without that variable in the model. 71. d) The p-values for height and gender are small so we reject the null hypotheses which state that the corresponding parameters are zero. However, the p-value for the intercept (Constant) is large. So we fail to reject Ho: 0 = 0. Hence, all of the statements in a, b and c are correct. 72. b) We have already eliminated the interaction from the model and also forced the regression line to pass through the origin; hence the model does not have an intercept nor an interaction term, leaving us with Weight 1 Height 2Gender