5811 Lab 3
advertisement

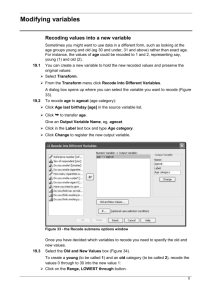
Agenda Soc 5811 Lab #3 09.26.05 I. Welcome 1. Second problem set tomorrow. 2. Review first problem set and last week’s lab activity. 3. Lab handouts, datasets, and other information can be found at: http://www.tc.umn.edu/~long0324/ II. Objectives 1. Learn how to calculate quantiles (quartiles, deciles, etc.) and z-scores with data from the General Social Survey. 2. Practice previous SPSS procedures with larger datasets and more complex variables, including recoding variables to catch missing values and create dummy variables. 3. If time allows, learn other helpful SPSS commands and perhaps start probability. II. A quick note on missing values 1. Not all missing values are coded as such when we get a dataset. For example, in the GSS, a possible value for respondent’s income is “REFUSED.” This is useful knowledge, but not very helpful in most analyses. So, we need to recode this value as missing. Be sure to check for tricky values when analyzing any variable. III. Quantiles (review from last week) 1. Quantiles are another univariate tool that is very useful in social science research. Quartiles, deciles, and percentiles are examples of quantiles, or fixed groups of data that give an indication of where cases lie in relation to one another. 2. Using SPSS, we can calculate quantiles in two ways. First, we can check the cumulative frequency list, which represents the percent of cases that fall at or below a certain value. Use the cumulative frequency list to calculate the first, second, and third quartile for the highest year of education for respondents. 3. We can also calculate quantiles using the Frequencies command. Use the Frequencies command to determine the deciles for age and quintiles for income. Verify your results with the cumulative frequency list. 4. Looking at income, what quartile do graduate assistants fall in? Don’t answer that. 5. Determine the interquartile range for income by locating the bounds for the 25th and 75th percentiles. What does this represent? IV. Z-Scores 1. Z-scores, or standardized scores, are another useful statistic. Z-scores allow us to compare across variables because the units are standard deviations. a. What is the formula for calculating a z-score? What is the mean of a zscored variable? The standard deviation? 2. We can calculate z-scores in SPSS by creating a new variable using the Compute command and the z-score formula, but we can also ask SPSS to save standardized values when we analyze descriptive statistics. Keep in mind that when we ask SPSS to save standardized scores, the new variable is named the same as the original variable, but preceded with a “z.” 3. Calculate the standardized score for respondent’s education. Check the distributions of both the original variable and the z-scored variable. What do you notice about the two distributions? 4. Create z-scores for both education and income. Pick one case out of the dataset and compare the z-scores for each variable. How many standard deviations above or below the mean is the respondent on each variable? Are they higher on one than the other? Why are z-scores ideal for this type of comparison? V. Dummy Variables and Comparing Means (review from last week) 1. Using the Recode command, create a dummy variable for either sex or race. Compare the descriptive statistics for education and income between the two groups. 2. We can also create dummy variables from ordinal variables with more than two or three categories. Create a dummy variable for high school degree, and then compare incomes for those who have a high school degree and those who do not. Are there differences in incomes between the two groups? What about a college degree? VI. Introduction to Sampling and Inferential Statistics (if time allows) 1. Inferential statistics involves making generalizations about a population using information from a sample along with statistical laws. For example, information in the General Social Survey is used to make broader generalizations about the American population. We will draw random samples of the 2002 General Social Survey to get a “hands-on” feel for how samples and populations are related. 2. First, a review on population and sampling distributions… a. What is the difference between a sample and a population? What is a random sample? b. What notation do we use for population parameters and sample statistics? c. Recall that the sampling distribution of the mean is made up of mean estimates from all possible samples of a fixed size. Because we rarely know the sampling distribution, we often think of it as a probability distribution. We can then use the probability distribution to judge how close our population estimate is likely to be. (There will be more on this next week.) 2. For now, we will treat the GSS as our population. Calculate the mean and standard deviation for variable hrs1, or the number of hours the respondent worked last week, for the entire GSS. 3. Next, draw a random sub-sample of 10 cases, and recalculate the mean and standard deviation for hours worked last week. Record the mean and standard deviation. We will need it later. 4. Repeat this process nine times, selecting a new sub-sample each time. Then, open up a new SPSS data file and create two new variables, mean1 and stdev1. Enter the 10 values for each mean and standard deviation for each sub-sample. While this is not an actual sampling distribution because we have not taken all possible 10-case samples, it does give us a flavor for how a sampling distribution works. 5. Calculate the mean and standard deviation of the sub-sample means and standard deviations. How close are they to the actual mean of the survey population? 6. Repeat steps 3-5 with random sub-samples of 100 cases. Enter the new variables, mean2 and stdev2, into your new dataset. Compare the means and standard deviations of the two sub-sample sizes. What did you find? Which set of mean estimates are more spread out? Which is likely to provide a better estimate of the population mean? GENERAL SPSS INSTRUCTIONS I. To recode variables 1. Click on Transform, then Recode. 2. To recode a variable that already exists into a new variable with the same name (i.e. when recoding missing values only), click on Into same variables. 3. To create a new variable, select Into different variables. 4. In the recode window, select the variable you are recoding from the left window and move it into the input/output window. 5. Type in a new name for the Output variable, and click Change. 6. Click on Old and New Values. 7. Type in the old value you want to recode on the right, and give the new value on the left. 8. To recode an existing value as missing, select the System missing button on the right. 9. To keep any old values in the new variable, select Copy old values on the right. 10. Be sure to click Add after recoding each value, or else they will be erased. 11. Click Continue, Paste, and Run. II. Quantiles and Z-scores 1. SPSS can calculate quantiles in the Frequencies window. Here you can click on quartiles, or ask SPSS to divide the dataset into bunches, such as deciles or quintiles. 2. Z-scores are calculated in the Descriptives window. Click the box labeled Save standardized values as variables. The new z-scores for the variable can then be found in the dataset labeled zvariable.