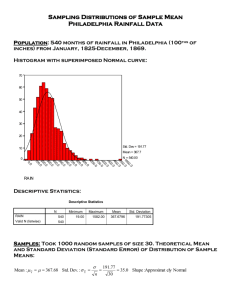
MATH371 – Introduction to Probability and Statistics

Take-Home Assignment 3
MATH371 – Introduction to Probability and Statistics
Fall 2005 – Dr. Lunsford
Directions: Please turn in a typed document clearly showing your answers to the questions below (feel free to cut and paste the questions into your document). Make sure you clearly describe your methods and results, including the pseudo code (i.e. logic) you used to compute your simulated values of random variables. You should also place histograms and other graphics in your document near where you describe their features.
In addition to your write-up, please turn in a disk with your Excel file (or other appropriate file if you generated your data via some other program). You may work with one partner on this assignment. Please turn in one write-up with both of your names and pledges on it.
Let X equal the larger outcome when a pair of four-sided dice is rolled. The p.m.f. of X is
2 x
1
, x
1, 2, 3, 4 . Please answer the following:
16
(a) Derive, using basic principles, the p.m.f. of X .
(b) Find the mean,
, variance,
2
, and standard deviation,
, of X .
Now we are going to simulate this random experiment using two different methods:
(c) First we will simulate the fair dice. Create two columns of 100 uniform random numbers (from zero to one). Now use those columns to simulate each die roll (i.e. you should be able to generate two columns, one for each die, from the uniform data columns.). Lastly, create a column for the values of the random variable X (Hint: You will want to use Excel’s built in Max function).
Create a histogram of your empirical p.m.f. for X (Note: Since the data is discrete, you may want to use the qualitative histogram option in Megastat).
Compare your empirical p.m.f. to the theoretical p.m.f.
Find the average value of your simulated values of X . This average value is an empirical estimate of
, the theoretical mean you computed in part (b).
Compare these two values.
Find the standard deviation of your simulated values of X . This number is an empirical estimate of
, the theoretical standard deviation you computed in part
(b). Compare these two values.
(d) Next we will directly use the p.m.f. of X to simulate the experiment. Use the inverse c.d.f. method discussed in class to generate 100 simulated values of X .
Create a histogram of your empirical p.m.f. for X (Note: Since the data is discrete, you may want to use the qualitative histogram option in Megastat).
Compare your empirical p.m.f. to the theoretical p.m.f.
Find the average value of your simulated values of X . This average value is another empirical estimate of
, the theoretical mean you computed in part (b).
Compare these three values (your two empirical estimates and the theoretical value).
Find the standard deviation of your simulated values of X . This number is another empirical estimate of
, the theoretical standard deviation you computed in part (b). Compare these three values (your two empirical estimates and the theoretical value).
What we have done in parts (c) and (d) is to run this random experiment 100 independent times. Thus we have taken 100 independent random samples from the distribution of X .
This is called a random sample of size 100 from the distribution of X . For each of these random samples, we computed the average value of our simulated values of X . Each of these averages is the sample mean of the random sample. Notice that the values of your sample means are (most likely) not equal but should be “close” to the value of your theoretical mean computed in part (b). The point of this is that the value of the sample mean will vary from sample to sample (for a fixed sample size). Thus the sample mean is also a random variable! We denote this random variable by the symbol X . The distribution of a random variable that is obtained via a random sampling is called a sampling distribution . In this case we have the sampling distribution of the sample mean .
In the last part of this assignment, we will get an empirical sampling distribution of X for random samples of size 100. The theoretical sampling distribution of X is the distribution of the sample means from all possible random samples of size n (in our case n
100 ) from the distribution of X .
(e) Before you work the remaining part of this assignment, make a guess about the answers to the following questions:
How will the mean of the sample means, i.e.
X
E X compare to the theoretical mean of X , i.e. [ ] , computed in part (b) above?
How will the standard deviation of the sample means, i.e. theoretical standard deviation of X , i.e.
, compare to the
X
, computed in part (b) above?
How will the shape of the distribution of the sample means compare to the shape of the p.m.f. of X ?
(f) Now use the method of part (d) to create 110 random samples each of size 100 from the distribution of X (Hint: Create your 110 columns of uniform random variables first and then use those to create your 110 columns of simulated values of X ). For each of those 110 random samples, compute the sample mean (use the Average function in
Excel). Thus you should have a row of 110 sample means below your row of simulated values of X .
Make a histogram of your simulated sample means (you may have to transpose this row into a column first via the “paste special” option). This histogram shows an empirical distribution for X . Compare this histogram to the p.m.f. of X . Are you surprised?
Find the mean and standard deviation of your sample means. These are empirical estimates of
X
E X and
. Compare these values to the theoretical mean
X and standard deviation of X you computed in part (b). What do you find particularly interesting?
The purpose of parts (e) and (f) of this assignment is to introduce you to the powerful concept of “averaging reduces variation.” The sampling distribution of X describes how
X varies about its mean and thus gives us an indication of how much error we will have when we use a value of X obtained via a random sample of size n from a distribution with mean
and standard deviation
in order to estimate
. We will be examining these ideas in detail when we cover sampling distributions and the Central Limit
Theorem!