Steps for Statistical Inference - the Department of Statistics Online
advertisement

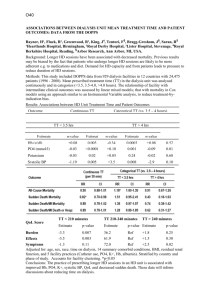
Steps for Statistical Inference For our class statistical interference will fall into one of the following categories: 1. Confidence Intervals - primarily used to estimate some unknown parameter 2. Hypothesis Testing - used when we disagree with a hypothesized parameter Step 1: Identify which inference method to use. The wording of the question will lead you to which choice to make. For example, if the problem asks “to estimate” or “what is” this would indicate the use of confidence intervals. For instance, if the research question was, “What is the true mean GPA difference between males and females” or “Estimate the true mean GPA difference between males and females” we would calculate a confidence interval. However, if the question states a current parameter exists and we disagree with this value or we want to demonstrate statistically that the true parameter differs from some value, we would employ Hypothesis Testing. If the question were “We want to show that there is a difference between mean GPA of males and females” this would infer that a hypothesis test should be conducted where the hypothesized value is zero (i.e. no difference). Step 2: After determining the inference method we then have to identify the variable type and how many to select either a proportions or means technique. From the example in step 1 GPA is continuous, plus the wording states “mean” and therefore we know the inference method would involve a means method. Then since we are comparing males and females, two independent categories, the inference method would invoke a two-means analysis. Step 3: From here the process should become straightforward. If doing the work by hand we just plug the sample statistics into the formula based on our decisions in Steps 1 and 2. If using statistical software we simply need to select the correct method based on our previous steps. Step 4: Use the output or by hand results to make conclusions and decisions remember that these relate back to the population of interest. So if calculating a confidence interval: “We are 95%(or whatever level of confidence) confident that the true mean GPA difference between males and females is (enter the confidence interval limits).” If conducting a hypothesis test then provide the pertinent details. “With a p-value of 0.002 and using a 0.05 level of significance, we reject Ho that there is no difference in mean GPA between males and females.” EXAMPLES BELOW!! 1 Examples Eg 1: In a marketing survey for an automobile manufacturer, 90 randomly selected adults are asked which car color they would choose, if a particular car were available in either blue or red body colors. Of the 90 respondents, 53 said “blue.” Let p = population proportion that would say “blue.” The manufacturer wants to learn if a majority of buyers would pick blue. Step 1: The problem asks “to learn if a majority of buyers would pick blue”. This implies more than 50% suggesting a hypothesis test would be used with 0.5 as the hypothesized value. Step 2: Color is a categorical variable and we are counting how many blue cars would be bought. This relates to proportion and since there is only one proportion of interest, (that is we are only interested in the percentage of blue cars and not comparing the percentage of blue cars from one year to another year nor are we comparing the percentage of blue cars to the percentage of another color) Step 3: Use the steps for a hypothesis test of one proportion 1. Ho: p = 0.5 Ha: p > 0.5 2. Significance level is 0.05 3. Test statistic: z pˆ p0 p0 (1 p0 ) n 53 / 90 0.5 0.5(1 0.5) 90 1.69 and verify that the use of normal approximation is appropriate: n*p = 45 and n*(1-p) = 55 which are both large enough (greater than 15) so use of normal approximation is supported. 4: p-value: Since our Ha is “greater than” our p-value will be found by P(Z > 1.69). From the standard normal table the cumulative probability for a z-value of 1.69 is 0.9545. Since we want “greater than” 1.69 we get the p-value by subtracting this cumulative probability from one, or 0.0455 is the p-value. 5. Decision: Since the p-value of 0.0455 is less than 0.05 we reject Ho. 6. Conclusion: With a p-value of 0.0455 and an alpha value of 0.05, we reject Ho and conclude that a majority of adults would prefer a blue car over red. Eg 2: PSU claims that the average SAT Math (SATM) score for the incoming fall 2005 class at University Park was approximately 610. You believe this to be too high. The descriptive statistics are: sample size is 216; sample mean is 599; and the sample standard deviation is 85.3 Step 1: The problem states that you believe that the true mean SATM score is less than 610. The 610 represents a hypothesize value and therefore a test of hypothesis is in order. Step 2: SATM is a quantitative variable plus the question uses the word “mean”. Since we are only interested in one population, SATM scores for the fall 2005 class, the correct procedure to use is an one-mean hypothesis test. If we wanted to compare SATM scores between say two different years or between incoming freshman males and females then a two-means test would be appropriate. 2 Step 3: Use the steps for a hypothesis test of one mean 1. Ho: μ = 610 Ha: μ < 610 2. Significance level is 0.05 3. Test statistic: t x o 599 610 1.89 s 85.3 n 216 4: p-value: Since our Ha is “less than” our p-value will be found by P(T < -1.89). However, since the t-distribution is symmetric P(T < -1.89) is the same as P(T > 1.89). This is why we use P(T > absolute value of the t-test statistic) when using the table. The degrees of freedom (df) for this test is equal to the sample size minus one, or 215. Since the T-table does not have 215 we will use 100. Going across the row for DF of 100 we look for the absolute value of our test statistic: 1.89 which we cannot find but notice that it falls between 1.660 and 1.984. Going to the top of these two columns to find the “right tail probability” we see t0.05 and t0.025 respectively. Since the t-test statistic falls somewhere between 1.660 and 1.984 this says that the p-value is between 0.025 and 0.05, or 0.025 < p-value < 0.05 [Note that we write the smaller value first. Some make the mistake of writing 0.05 < p-value < 0.025 but if you look carefully at this it is not possible: How could a p-value be greater than 0.05 at the same time being less than 0.025?] 5. Decision: Since the range of possible p-values are all less than 0.05 we reject Ho. 6. Conclusion: With a p-value range of 0.025 < p-value < 0.05 and an alpha value of 0.05, we reject Ho and conclude that mean SATM scores for the 2005 PSU incoming freshman class is less than 610. Note: If in either of these two tests the alternative hypothesis (Ha) was “not equal” we would have conducted the analysis in the same way except when calculating the p-value we would have doubled the results. This would have led to a p-value of 0.091 for the first example and a range of 0.05 < p-value < 0.10 for example two. In both cases this would have resulted in us NOT rejecting Ho. Eg 3: PSU wants to determine with 95% confidence what the mean SAT Math (SATM) is for incoming freshman class of 2005. The descriptive statistics are: sample size is 216; sample mean is 599; and the sample standard deviation is 85.3 Step 1: Now the problem states that want to determine or find the mean SATM. That is the university does not have a hypothesized value (i.e. and educated guess) and instead wants to estimate what it might be with a level of confidence of 95%. Step 2: SATM is a quantitative variable plus the question uses the word “mean”. Since we are only interested in one population, SATM scores for the fall 2005 class, the correct procedure to use is an one-mean confidence interval. If we wanted to estimate the difference between SATM scores say for two different years or between incoming freshman males and females then a twomeans confidence interval would be appropriate. Step 3: Perform the steps for calculating a one-sample mean confidence interval 1. The general confidence interval formula: sample statistic ± Multiplier*Standard Error 2. Specific formula for one sample CI: x t multiplier * s n 3 3. Find the t-multiplier. Since interested in 95% level of confidence with degrees of freedom of 215 (again using 100 from the T-table) we go to the T-table and find under Confidence Level the level of 95% and go down this column until we reach the row that matches degrees of freedom (df) of 100. The resulting t-multiplier is 1.984 4. Plug the values into the confidence interval formula: 599 1.984 * 85.3 216 85.3 5. Calculate the interval: The margin of error is 1.984 * = 11.515 making the 216 lower bound of the interval equal to 599 - 11.515 = 587.485 and the upper bound of the interval equal to 599 + 11.515 = 610.515. 6. Interpret the interval: We are 95% confident that the true mean SATM scores for the incoming 2005 freshman class at PSU is between 587.485 and 610.515 Note: If we wanted to use this interval to test Ho: μ = 610 Ha: μ ≠ 610 we would NOT reject Ho since the interval (ever so slightly!) does contain the 610 hypothesized value. 4