Cavity
advertisement

Parallel Programming
with
Object Assemblies
Swarat Chaudhuri
Penn State
Roberto Lublinerman
Pavol Cerny
Penn State
IST Austria
Taming parallelism
Task-parallelism
Message-passing
Data parallelism:
- Highly coarse-grained
(MapReduce)
- Highly fine-grained
(numeric computations
on dense arrays)
-Problem-specific methods
Taming parallelism
Our target:
Data-parallel computations
over large, unstructured,
shared-memory graphs
Unknown granularity
High-level correctness as well
as efficiency.
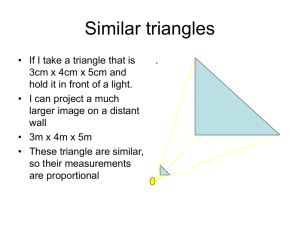
Delaunay mesh refinement
• Triangulate a given set of points.
• Delaunay property:
No point is contained within
the circumcircle of a triangle.
• Quality property:
No bad triangles—i.e.,
triangles with an angle > 120o.
• Mesh refinement:
Fix bad triangles through an
iterative algorithm.
Retriangulation
Cavity: all triangles whose circumcircle contains new point.
Quality constraint may not hold for all new triangles.
Sequential mesh refinement
Mesh m = /* read input mesh */
Worklist wl = new Worklist(m.getBad());
foreach triangle t in wl {
Cavity c = new Cavity(t);
c.expand();
c.retriangulate();
m.updateMesh(c);
wl.add(c.getBad());
}
• Cavities are contiguous “regions” in the mesh.
• Worst-case cavities can encompass the whole mesh.
Parallelization
• Computation over complex, unstructured graphs
Mesh = Heap-allocated graph. Nodes = triangles.
Edges = adjacency
• Atomicity: Cavities must be retriangulated atomically.
• Non-overlapping cavities can be processed in parallel.
• Seems impossible to handle with static analysis:
– Shape of data structure changes greatly over time.
– Shape of data structure is highly input-dependent.
– Without deep algorithmic knowledge, impossible to say if
statically if cavities will overlap.
• Lots of recent work, notably by Pingali et al.
List of similar applications
•
•
•
•
•
•
Delaunay mesh refinement, Delaunay triangulation
Agglomerative clustering, ray tracing
Social network maintenance
Minimum spanning tree, Maximum flow
N-body simulation, epidemiological simulation
Sparse matrix-vector multiplication, sparse Cholesky
factorization
• Belief propagation, survey propagation in Bayesian
inference
• Iterative dataflow analysis, Petri net simulation
• Finite-difference PDE solution
Locality of updates in Chorus
Cavity
•
•
•
On a mesh of ~100,000 triangles from Lonestar
benchmarks: Average cavity size = 3.75 triangles.
Maximum cavity size = 12 triangles
Average-case locality the essence of parallelism.
Chorus: parallel computation driven by
“neighborhoods” in heaps.
Heaps, regions, assemblies
• Heap = directed graph
Nodes = objects
Labeled edges = pointers
• Region = induced subgraph
• Assembly =
region + thread
of control
Typically speculative
and shortlived.
Programs, assembly classes
• Assembly class = set of local variables +
set of guarded updates + constructor + public
variables.
• Program = set of classes
• Synchronization happens in guard evaluation.
busy
executing
update
terminated
ready
to be
:: Guard: Update
preempted
or execute next
update
Guards can merge assemblies
u
f
:: merge (u.f): S
:: merge (u.f)
when g: S
• g is a condition on the
local variables and owned
objects of
•
gets a bigger region,
keeps local state
•
dies.
•
must be in ready state
while merge happens
Updates can split an assembly
split(T)
• Split into assemblies of
class T.
• Other assemblies not
affected.
• Not a synchronization
construct.
Local updates
• Attempts to access objects
outside region lead to
exceptions.
x = u.f;
x.f = y;
u
f
Delaunay mesh refinement
• Use two assembly classes: Triangle and
Cavity.
– Cavity = local region in mesh.
• Each triangle:
– Determines if it is bad (local check).
– If so, merges with neighbors to become cavity.
• Each cavity:
– Determines if it is complete (local check).
– If no, merges with a neighbor.
– If yes, retriangulates (locally) and splits.
Delaunay mesh refinement:
sketch
assembly Triangle:: ...
action::
merge (v.f, Cavity) when isBad:
skip
assembly Cavity:: ...
action::
merge (v.f) when (not isComplete):
...
isComplete:
retriangulate();
split(Triangle)
Delaunay mesh refinement:
sketch
assem Triangle:: ...
action::
merge (v.f, Cavity, u) when bad?:
skip
assem Cavity:: ...
What happens on a conflict?
action::
merge (v.f) when (not complete?):
• Cavity i “absorbed” by cavity j.
skip
• Cavity j now has some
complete?:
“unnecessary” triangles.
retriangulate();
• j will later split.
split(Triangle)
Boruvka’s algorithm for minimum
spanning tree
• Assembly = spanning tree
• Initially, each assembly has
one node.
• As algorithm progresses, trees
merge.
Race-freedom
• No aliasing, only
ownership transfer.
•
can merge with only
when is not in the
middle of an update.
Deadlock-freedom
• Classic definition: Process P waits for a resource from Q and
vice versa.
• Deadlock in Chorus:
–
has a locally enabled merge with
–
has a locally enabled merge with
– No other progress is possible.
u
• But one of the merges
can always be carried out.
(An assembly can always
be killed at its ready state.)
JChorus
• Chorus + sequential
Java.
• Assembly classes in
addition to object
classes.
7: assembly Cavity {
8: action {
// expand cavity
9: merge(outgoingedges,
TriangleObject t):
10:
{ outgoingedges.remove(t);
11:
frontier.add(t);
12:
build(); }
13: }
14: Set members; Set border;
15: Queue frontier; // current frontier
16: List outgoingedges;
// outgoing edges on which to merge
17: TriangleObject initial;
...
Division-based implementation
• Division = set of assemblies
mapped to a core.
• Local access:
Merge-actions within a division
Split-actions
Local updates
• Remote access:
Merge-actions issued across
divisions
• Uses assembly-level locks.
Implementation strategies
• Adaptive divisions. Heuristic for reducing
the number of remote merges.
• During a merge, not only the target assembly, but
also assemblies reachable by k pointer indirections,
are migrated.
• Adaptation heuristic does elementary load
balancing.
• Union-find data structure to relate objects
and assemblies that they belong to
• Needed for splits and merges.
• Token-passing for deadlock prevention and
termination detection.
Experiments: Delaunay refinement
from Lonestar benchmarks
• Large dataset from Lonestar benchmarks.
– 100,364 triangles.
– 47,768 initially bad.
• 1 to 8 threads.
• Competing approaches:
– Object-level locking
– DSTM (Software transactions)
Locality: mesh snapshots
The initial mesh and divisions
Mesh after several thousand
retriangulations
Delaunay: Speedup over sequential
Delaunay: Self-relative speedup
Delaunay: Conflicts
Related models
• Threads + explicit locking: Global heap abstraction,
arbitrary aliasing.
• Software transactions: Burden of reasoning passed to
transaction manager. In most implementations, heap is
viewed as global.
• Static data partitioning: Unpredictable nature of the
computation makes static analysis hard.
• Actors: Based on low-level messaging. If sending
references, potential of races. If copying triangles,
inefficient.
• Pingali et al’s Galois: Same problem, but ours is an
alternative.
More information
Parallel programming with object assemblies.
Roberto Lublinerman, Swarat Chaudhuri,
Pavol Cerny.
OOPSLA 2009.
http://www.cse.psu.edu/~swarat/chorus