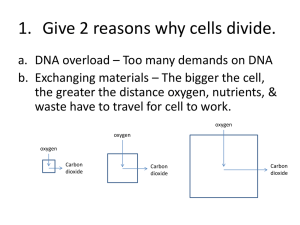
UNIT 7:
CHAPTERS 9-10
DNA Replication
and
Protein Synthesis
Chapter 9
DNA:
The Genetic Material
Section 1
The Structure of DNA
Experiments with Bacteria
In 1928, bacteriologist Frederick Griffith was trying to
prepare a vaccine against pneumonia.
A vaccine is a substance that is prepared from killed or
weakened disease-causing agents, including certain
bacteria, that can be introduced into the body to protect the
body against future infections.
Griffith worked with two types, or strains, of Streptococcus
pneumonia. One strain was enclosed in a polysaccharide
capsule that protected the bacterium from the body’s
defense systems.
This helped make the microorganism virulent, which
means it was able to cause disease.
Experiments with Bacteria
During his experiments, Griffith found that
harmless bacteria had changed and become
virulent, but he did not understand what caused
this change.
Griffith had discovered what is now is called
transformation.
Transformation is a change in the genotype
caused when cells take up foreign genetic
material. The cause of the transformation was
now known at the time.
Experiments with Bacteria
In 1944, Oswald Avery and his co-workers at
the Rockefeller Institute in New York City
demonstrated that DNA was the material
responsible for transformation.
In 1952, experiments performed by Alfred
Hershey and Martha Chase concluded that
DNA injected into bacterial cells by viruses
caused the hereditary changes in the
bacteria.
Experiments with Bacteria
A bacteriophage, or phage, is a
virus that infects bacteria and cause
the bacteria to produce more viruses.
These important experiments have
shown that DNA is the molecule that
stores genetic information in living
cells.
What is DNA?
DNA, or deoxyribonucleic acid, is the double helix, or
double-stranded, nucleic acid that stores genetic information.
DNA also contains the instructions for cellular activity and
protein production.
In eukaryotic cells, DNA is located in the
nucleus of cells where it is coiled into
structures called chromosomes.
In prokaryotic cells, DNA is either
attached to the cell membrane or floats
freely in the cytoplasm.
The Endosymbiotic Theory
Prokaryotic cells lack organelles bound by
membranes.
Mitochondria and chloroplasts have their own
DNA. The DNA in the nucleus does not instruct
the cell to make mitochondria or chloroplasts.
The endosymbiosis theory proposes that
some early prokaryotes evolved internal cell
membranes which eventually led to the
development of primitive eukaryotic cells.
The Endosymbiotic Theory
The theory goes on to say that other
prokaryotic organisms then entered the
primitive eukaryotic cell and lived
inside.
The eukaryotic cell formed a mutualistic
relationship with the prokaryotes, one
in which each organism benefits from
the other.
Over time, those
prokaryotes
evolved into the
cell organelles
of the modern
eukaryotic cell.
It is believed to
be the means by
which such
organelles as
mitochondria
and chloroplasts
arose within
eukaryotic cells.
The Structure of DNA
In the 1950s, researchers James Watson and Francis Crick of
Cambridge University pieced together a model of the
structure
of DNA.
8.2
Structure
of DNA
Watson and Crick determined the three-dimensional
structure of DNA by building models.
• They realized that DNA is
a double helix that is
made up of a sugarphosphate backbone on
the outside with bases on
the inside.
DNA is composed
of four
types ofwithin
nucleotides.
Nucleotides
are the
subunits
DNA.
• DNA is made up of a long chain of nucleotides.
• Each nucleotide has three parts.
– a phosphate group
IMPORTANT!!
– a deoxyribose sugar
– a nitrogen-containing base
phosphate group
deoxyribose (sugar)
nitrogen-containing
base
Nitrogen Bases
The nitrogen bases found in DNA are classified
into two groups called pyrimidines or purines.
Pyrimidines are the single-ringed nitrogen
bases that make up part of a DNA nucleotide,
and include the bases thymine and cytosine.
Purines are the double-ringed nitrogen bases
that make up part of a DNA nucleotide, and
include the bases adenine and guanine.
Base-Pairing Rules of DNA
8.2 Structure of DNA
Nucleotides always pair in the same way.
• The base-pairing rules show
how nucleotides always pair
up in DNA.
– A pairs with T
– C pairs with G
• Because a pyrimidine
(single ring) pairs with a
purine (double ring), the
helix has a uniform width.
G
C
A T
mRNA vs DNA: Key Differences
Like DNA, RNA, or ribonucleic acid, is a nucleic acid
made of nucleotides linked together.
RNA differs from DNA in three main ways.
DNA
double stranded
deoxyribose sugar
Bases: T-A, G-C
mRNA
single stranded
ribose sugar
Bases: U-A, G-C
Comparing RNA and DNA
Image courtesy of Wikimedia Commons
Chromosome Structure
Histones
Histones are the chief protein
components of chromatin, and act
as spools around which DNA winds.
Histones play a role in gene
regulation.
Without histones, the unwound
DNA in chromosomes would be
very long.
Each human cell has
about 1.8 meters of DNA.
But, wound on the
histones, it has about 90
millimeters of chromatin.
There are 22 pair of autosomes and 1 pair
of sex chromosomes.
a human karyotype
The Nobel Prize
Alfred Nobel, the Swedish inventor of
dynamite, provided a $9 million
endowment in his will to be awarded to
people whose work showed ingenuity
and most benefited humanity.
James Watson, Francis Crick, and
Maurice Wilkins received the Nobel Prize
in 1962 for their work in explaining the
structure of DNA.
The Nobel Prize
The work of Watson and Crick expanded on the previous work
of other scientists such as Erwin Chargaff of Columbia
University in New York City and Maurice Wilkins and Rosalind
Franklin of King’s College in London.
The Nobel Prize is only awarded to living individuals, so
Rosalind Franklin did not receive it.
She had died of cancer in 1958 at the age 37.
Her work involved using X-rays to study the structure of DNA,
and probably contributed to her death.
The X-ray photographs taken by Rosalind Franklin allowed
Watson and Crick to determine the structure of DNA.
Bonding in DNA
DNA resembles a ladder twisted like a spiral staircase.
The sugar-phosphate backbones (the outer circles and
pentagons) are similar to the side rails of a ladder. The
paired nitrogen bases are similar to the rungs of the
ladder.
A weak hydrogen bond is found between the pairs of
nitrogen bases, and holds together the double helix
shape of the DNA molecule.
A covalent bond holds the sugar and phosphates
together.
hydrogen bond
covalent bond
Section 2
DNA Replication
DNA Replication
Before a cell divides, it must first
replicate its DNA. DNA makes a
copy of itself by a process called
DNA replication.
The DNA replicates before a cell
divides so that each new cell receives
an identical copy of the genetic
material contained in the parent cell.
Initiator proteins are proteins that
recruit other proteins to separate the
DNA strands at the origin, forming a
bubble.
DNA Replication
DNA replication is the process of making a copy
of DNA, and takes place during the Synthesis (S)
phase of interphase.
A single strand of DNA serves as a template, or
pattern, for a new strand.
The rules of base-pairing direct replication –
thymine pairs with adenine, and guanine pairs with
cytosine.
Each body cell will receive a complete set of
identical DNA.
DNA Replication
Before replication can occur, the length of the DNA
double helix about to be copied must be unwound.
In addition, the two strands must be separated,
much like the two sides of a zipper, by breaking the
weak hydrogen bonds that link the paired bases.
Once the DNA strands have been unwound, they
must be held apart to expose the bases so that
new nucleotide partners can hydrogen-bond to
them.
DNA Replication -- Step 1:
Enzymes called DNA helicases cause the double
helix to unwind by breaking the hydrogen bonds
that link the complementary nitrogen bases
between the two strands.
The areas where the double helix separates are
called replication forks because of their Y
shape.
DNA Replication -- Step 2:
At the replication
forks, enzymes known as DNA polymerases then move along
the exposed DNA strand, joining newly arrived nucleotides into a
new DNA strand that is complementary to the template.
DNA polymerases add nucleotides to the exposed nitrogen bases
according to the base pairing rules.
As the DNA polymerases move along in opposite directions, two
new double helixes are formed.
Multiple Replication Forks
Because chromosomes are
so large (billions of base
pairs), multiple replication
forks, or bubbles, work
simultaneously.
An entire human chromosome
can be replicated in about
8-9 hours.
Multiple Replication Forks
Eventually these areas run together to form
a complete chain.
In humans, DNA is copied at about 50 base
pairs per second.
The process would take a month (rather
than the hour it actually does) without
these multiple places on the chromosome
where replication can begin.
DNA strands have a directionality. The different
ends of a single strand are called the 3’ (threeprime) end and the 5’ (five-prime) end.
The 3’ end of one DNA strand always pairs with
the 5’ end of the complementary strand, and the
5’ end will always pair with the complementary
3’ end of the DNA strand.
In addition to being complementary, the two
strands of DNA are orientated in opposite
directions.
Antiparallel is a term describing the two side
rails of the ladder-like structure of a doublestranded DNA molecule and how they are
oriented in opposite directions.
Checking For Errors
DNA polymerases are a family of enzymes (a
type of protein) that carry out all forms of DNA
replication.
DNA polymerases are generally extremely accurate,
making less than one error for every 107
nucleotides added.
Even so, some DNA polymerases also have
proofreading ability. They can remove
nucleotides from the end of a strand in order to
correct mismatched bases.
DNA REPLICATION
Step 3:
The process continues until all
of the DNA has been copied
and the polymerases are
signalled to detach.
DNA replication produces two
DNA molecules, each
composed of a new and an
original strand.
The nucleotide sequences in
both of these DNA molecules
are identical to each other and
to the original DNA molecule.
Gene Expression
The main function of genes is to control the
production of proteins.
An organism’s traits depend on the kind and number
of proteins it makes, based on the information in its
genes.
Gene expression is the process by which the
information carried in genes is transferred into
proteins.
A particular cell expresses only the genes that code
for the proteins its needs for its functions.
Chapter 10
Section 3
Protein Synthesis:
How Proteins Are Made
The Genetic Code
The traits an organism inherits are
carried in the DNA it receives from its
parents.
These traits are determined by proteins.
Cells follow instructions in the DNA to
make those proteins.
Protein Synthesis
Proteins are not made directly by DNA.
RNA copies information from the DNA molecule.
The RNA carries the information to the ribosomes,
where proteins are made.
These two processes are called transcription (copying
the code) and translation (reading and translating the
code).
Together, translation and transcription are known as
protein synthesis – the making of proteins.
From Genes To Proteins
DNA
Replication
RNA
Transcription
Protein Translation
mRNA vs DNA: Key Differences
Like DNA, RNA, or ribonucleic acid, is a nucleic acid
made of nucleotides linked together.
RNA differs from DNA in three main ways.
DNA
double stranded
deoxyribose sugar
Bases: T-A, G-C
mRNA
single stranded
ribose sugar
Bases: U-A, G-C
Comparing RNA and DNA
Image courtesy of Wikimedia Commons
Transcription and Translation
The instructions for making a protein are transcribed, or
transferred, from a gene to a RNA molecule in a process
called transcription.
Cells then use two different types of RNA to read and
translate the instructions from a gene to an RNA molecule in a
process called translation.
Gene expression is the name of the entire process by which
proteins are made using the information coded in DNA.
Transcription
Transcription is a process that occurs in the
nucleus where the DNA is located, and uses DNA as a
template to make a complementary strand of RNA.
The instructions in DNA are in a code that depends on
the arrangement of nucleotide bases.
The nucleotides of DNA are arranged in triplets, or
groups of three. There are 64 possible triplets.
The code for making proteins is passed from the DNA
to an RNA molecule during transcription.
Transcription
Transcription is similar to DNA replication, with
one major exception: Transcription produces only
one strand of nucleotides.
DNA consists of the two linked strands of
nucleotides bases.
To begin protein synthesis, the strands must
separate.
Complementary nucleotides of RNA are added to a
DNA strand to make a strand of RNA instead.
Transcription
The RNA that carries the instructions from DNA
in the nucleus to where they will be translated
into a protein molecule is called messenger
RNA, or mRNA.
The instructions in mRNA are arranged in sets
called codons which complement the DNA
triplet.
A codon is a group of three nitrogenous bases
on mRNA that codes for a specific amino acid.
Transcription
Codons are universal, and each corresponds to a
different amino acid.
There are 64 different codons, but only 20 different
amino acids.
These amino acids combine in a multitude of ways
to form many different proteins.
The ways the amino acids combine determine a
protein’s shape and function.
Base-Pairing in RNA
RNA forms base
pairs with DNA:
G pairs with C
A pairs with U
(Uracil replaces
thymine in RNA.)
A DNA triplet pairs
with an mRNA
codon.
Transcription:
Introns and Exons
After it is initially copied, the mRNA transcript is not yet
complete.
Exons are “splicing” enzymes that recognize coding regions.
Exons are the base sequence that remains after RNA splicing
that can be translated into a protein.
Introns are long segments of nucleotides
that have no coding information. Introns
are non-expressed and non-translated
nucleotides that must be removed by
splicing.
Introns must be removed before the
completed transcript can leave the
nucleus.
Transcription Challenge!
Create an mRNA transcript for the following DNA sequence:
5’
3’
ACG ATA CCC TGA CGA GCG TTA
UGC UAU GGG ACU
3’
GCU CGC
AAU
5’
Hmmmm…
I think I
get it now!
Transcription is Complete.
What’s Next? Translation
How is mRNA “read” to generate
proteins from amino acids?
The mature mRNA transcript leaves
the nucleus through a nuclear pore.
Once in the cytoplasm, it seeks out
a ribosome to begin translation.
Translation is a process that
takes place in the cytoplasm on
ribosomes, and converts the
information in the mRNA into a
sequence of amino acids that
makes up a protein.
TRANSLATION – rRNA
Ribosomes in the cytoplasm are referred to as
ribosomal RNA, or rRNA, and act as the site
for translation.
Translation begins when the mRNA leaves the
nucleus and enters the cytoplasm.
The mRNA, the two ribosomal subunits, and a
tRNA carrying the amino acid methionine (or
AUG, the start codon) together form a
functional ribosome.
TRANSLATION – tRNA
Transfer RNA, or tRNA, are single strands of
RNA that temporarily carry a specific amino
acid on one end.
The tRNA delivers amino acids to the
ribosomes, which are linked together in an
order determined by the code carried by the
mRNA.
In this way, the information is translated from
nucleotides to amino acids.
TRANSLATION – Transfer RNA
In order to translate the
code, mRNA codons
must join with the
correct anticodon on
tRNA.
An anticodon is a set
of three nitrogenous
bases on a tRNA
molecule that is
complementary to the
codon on an mRNA
molecule.
TRANSLATION: Codons and Anticodons
Remember that a three-base sequence on the DNA gene is called a
triplet.
The corresponding three-base sequence on mRNA is called a
codon.
An anticodon is a three-nucleotide sequence on a tRNA that is
complementary to an mRNA codon.
Triplet = three-base sequence on DNA
Codon = three-base sequence on mRNA that complements the DNA
triplet
Anticodon = three-base sequence on tRNA that complements the
mRNA codon
Start Codons and Stop Codons
The mRNA start codon AUG,
signals the beginning of a
protein chain.
A stop codon is one of three
codons (UAG, UAA, UGA) for
which there is no tRNA
molecule with a complementary
anticodon. The stop codon
signals the end of the protein
molecule, and protein synthesis
stops.
The newly made protein is then
released into the cell.
start
codon
stop
codon
DNA Transcription:
mRNA copies the DNA
triplets
DNA Translation
and Protein
Synthesis:
tRNA copies the
mRNA codons
anticodons
codons
The Key to the Code:
Which codons code for which amino acids?
The Key to the Code:
Which codons code for which amino acids?
mRNA: CUCAAGUGCUUC
What is the portion of the protein molecule coded for
by the piece of mRNA given?
Leu – Lys – Cys – Phe
The anticodons for the codons in the mRNA given are –
GAG – UUC – ACG – AAG
The Polypeptide
A polypeptide is made up of a
string of thousands of amino
acids.
Remember that an organism’s
traits depend on the kind and
number of proteins it makes.
Most proteins fold into unique
3-dimensional structures.
The shape of the protein molecule
determines its function.
DNA Replication and Protein
Synthesis Videos
GO TO START, DOCUMENTS, VIDEOS
(Videos of DNA Replication, mRNA
Splicing, RNA Folding, DNA Transcription,
DNA Translation Animations)
Or, go to website link below from HHMI’s
Biointeractive: DNA Animations/Transcription
(basic), and look under Animations
http://www.hhmi.org/biointeractive/dna/DN
Ai_transcription_vo1.html
Protein Synthesis- Part 2
Translation
From HHMI’s Biointeractive: DNA
Animations/Translation (basic)
http://www.hhmi.org/biointeractive/dna/
DNAi_translation_vo1.html
Types of Proteins
Proteins can be informally divided into three main classes:
globular proteins, fibrous proteins, and membrane proteins.
Almost all globular proteins are soluble, such as
hemoglobin, and many are enzymes.
Fibrous proteins are often called structural proteins,
and include collagen, the major component of
connective tissue, and keratin, the protein component
of hair and nails.
Membrane proteins often serve as receptors or
provide channels for polar or charged molecules to
pass through the cell membrane.
membrane
proteins
catalase, a
globular protein
a collagen
fiber, or
fibrous protein
Amino Acids: The Building
Blocks of Proteins
All amino acids are made up of an amino group, a
carboxyl group, and a R side chain.
The R side chain is different for each amino acid,
making each amino acid unique.
Amino Acids: The Building
Blocks of Proteins
Transcription vs. Translation:
A Comparative Review
Transcription
process by which genetic
information encoded in
DNA is copied onto
messenger RNA
occurs in the nucleus
DNA is transcribed to
mRNA
involves DNA and mRNA
Translation
process by which
information encoded in
mRNA is used to assemble a
protein
occurs on a ribosome (rRNA)
mRNA is translated to tRNA
to make a protein
involves mRNA, tRNA, and
amino acids
Both processes are involved in protein synthesis – the making
of a protein molecule.
Both strands of RNA originated from the original strand of DNA.
SECTION 4
Changes in DNA
and
Their Impacts
Mutations
Mutations are errors in the transcription or
translation process.
Most mutations will have no effect whatsoever on
the organism, but some mutations can be
passed on to offspring of the affected
individual if the mutation occurs in gametes.
In a point mutation, a single nucleotide changes.
In an insertion mutation, a sizable length of DNA
is inserted into a gene.
Mutations
In a deletion mutation, segments of a gene are lost
or deleted.
A frameshift mutation causes a gene to be read in
the wrong three-nucleotide sequence. A frameshift
mutation could be caused by a deletion mutation or an
insertion mutation.
The deletion or insertion totally changes the protein,
and causes major problems. The “frame” of the whole
sequence “shifted” because of the deletion or insertion.
Because the genetic message is read as a series of
triplets nucleotides, insertions and deletions of one or
two nucleotides can upset the triplet groupings.
Using Analogies to
Represent a Strand of DNA
We will be using a sentence as an analogy representing a
strand of DNA.
Our sentence is:
The fat cat ate the wee rat.
If this sentence represents a strand of DNA, what does each
word represent?
a triplet of DNA that codes for one amino acid
What does each letter represent?
a nitrogen base within the amino acid
Mutations?!?
Now we’re going to look at mutations in the
DNA.
When you hear about mutations, you may
think about some teenage turtles or
growing an extra arm, but the word mutate
just means to change.
Let’s look at what happens when we change
the sentence/DNA.
Substitution
The fat cat ate the wee rat.
The fat cat ate the wet rat.
What changed?
The second ‘e’ in wee changed to a ‘t’.
What does this represent?
An amino acid was substituted at that
point.
How would this type of change affect the protein?
It would cause a slight mutation that
probably would not have too much affect
on the protein since it was only one amino
acid.
Deletion
The fat cat ate the wee rat.
The fat cat att hew eer at.
What changed?
The ‘e’ of ate was deleted, which caused all
the triplets to shift to the left. Now the last
triplet is missing an amino acid.
What does this represent?
All the triplets are now changed.
How would this type of change affect the protein?
There would be a significant change in the
protein.
Insertion
The fat cat ate the wee rat.
The fab tca tat eth ewe era t.
What changed?
A ‘b’ was inserted for the ‘t’ of fat. This
caused all the triplets to shift right. Now
the last triplet has only one amino acid.
How would this type of change affect the protein?
There would be a significant change in the
protein.
Point Mutations vs.
Frameshift Mutations
The substitution example was a point mutation.
The last two examples of a deletion mutation and an insertion
mutation caused frameshift mutations.
What is the difference between a point mutation and a frameshift
mutation?
In a point mutation, a single nucleotide changes – a minor problem.
A frameshift mutation causes a gene to be read in the wrong threenucleotide sequence – it totally changes the protein, and causes
major problems. The “frame” of the whole sequence “shifted.”
Which is worse? Why?
Inversion
The fat cat ate the wee rat.
The fat tar eew eht eta tac.
What changed?
Everything after the word ‘fat’ is inverted.
How would this type of change affect the
protein?
The protein would be totally changed in
structure.
Chromosomal Mutations
What changed?
How would this type
of change affect the
protein?
SAMPLE BIOLOGY
EOC QUESTION:
normal
p arm
q arm
Cri-du-Chat is a serious
genetic disorder resulting in
small birth weight, respiratory
problems, and a poorly
developed larynx which causes
a catlike cry in infants.
Analyzing the chromosomes in
the diagram to the left indicates
that Cri-du-Chat is caused by—
F. addition of extra nucleotides on
the p arm of chromosome 5
G. exchange of genes from the
crossing over of chromosome 5
p arms
H. loss of several genes on the
p arm of chromosome 5
J. loss of genes on the q arm of
chromosome 5
Non-disjunction
Example: Trisomy 21 or Down Syndrome
Sometimes there
is an error in
meiosis when egg
or sperm cells
divide resulting in
too many or too
few chromosomes.
How do you think
this type of change
would impact
protein synthesis?
Down syndrome, or trisomy 21,
results when an individual has an extra
copy of chromosome 21.
What events can cause an individual to
have an extra copy of a chromosome?
Disjunction is an event that occurs
when sperm and egg cells form, and
each chromosome and its homologue
pair separate.
TRISOMY 21
Nondisjunction occurs if one or more
chromosomes fail to separate properly,
and one new gamete ends up receiving
both chromosomes, while the other
gamete receives none.
Trisomy occurs when the gamete with
both chromosomes fuses with a normal
gamete during fertilization, resulting in
offspring with three copies of that
chromosome instead of two.
Mutation Impact
The impact of a mutation on an individual
also depends on where and when it occurs.
If there was a mutation in the DNA of a
zygote, how would that impact the
individual?
How might a mutation in a skin cell affect an
individual?
Mutations
What types of mutations are these?
1. THE CAT ATE transcribed as THE ATA TE
DELETION MUTATION – the ‘C’ was deleted
2. THE CAT ATE transcribed as THE CAR ATE
POINT MUTATION – a single nucleotide ( the R ) changed
3. THE CAT ATE transcribed as THE ATE CAT
FRAMESHIFT MUTATION – wrong three-nucleotide
sequence
4. THE CAT ATE transcribed as THE CAT ATE THE CAT
INSERTION MUTATION -- extra DNA inserted
Unit 5 Chapters 9-10 Test Review
Know all the vocabulary for this Unit!
Be able to identify and describe a purine and a pyrimidine,
and the individual nitrogen bases that fall under these
classifications.
Know the differences between a DNA strand, mRNA strand,
and a tRNA strand.
Be able to correctly pair nitrogen bases in a DNA strand,
mRNA strand, or tRNA strand.
Know the function of rRNA and where it is found.
Be able to describe and contrast the processes of
translation and transcription -- define and describe the
process, know where each process occurs, know what
each process produces or accomplishes as an end result.
Be able to identify the codons that act as stop codons and
start codons.
Unit 5 Chapters 9-10 Test Review
Be able to identify and describe a triplet, codon, and
anticodon.
Know the definitions of an insertion mutation, frameshift
mutation, deletion mutation, and point mutation, and be
able to recognize and identify an illustration or example of
each type of mutation.
Know the function, a description, and location of DNA
polymerases, DNA helicases, and histones.
Be able to label the parts of a DNA molecule.
Be able to identify and describe a replication fork, a
polypeptide, and the parts of an amino acid.
Be able to identify and describe introns and exons and
where they are located.
Be able to identify and describe the antiparallel
directionality of the 3’ and 5’ ends of a DNA strand.