Data Mining and Machine Learning with EM
advertisement

Machine Learning with EM
闫宏飞
北京大学信息科学技术学院
7/24/2012
http://net.pku.edu.cn/~course/cs402/2012
Jimmy Lin
University of Maryland
SEWMGroup
This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States
See http://creativecommons.org/licenses/by-nc-sa/3.0/us/ for details
Today’s Agenda
• Introduction to statistical models
• Expectation maximization
• Apache Mahout
Introduction to statistical models
• Until the 1990s, text processing relied on rulebased systems
• Advantages
– More predictable
– Easy to understand
– Easy to identify errors and fix them
• Disadvantages
– Extremely labor-intensive to create
– Not robust to out of domain input
– No partial output or analysis when failure occurs
Introduction to statistical models
• A better strategy is to use data-driven methods
• Basic idea: learn from a large corpus of examples of what
we wish to model (Training Data)
• Advantages
– More robust to the complexities of real-world input
– Creating training data is usually cheaper than creating rules
• Even easier today thanks to Amazon Mechanical Turk
• Data may already exist for independent reasons
• Disadvantages
– Systems often behave differently compared to expectations
– Hard to understand the reasons for errors or debug errors
Introduction to statistical models
• Learning from training data usually means estimating the
parameters of the statistical model
• Estimation usually carried out via machine learning
• Two kinds of machine learning algorithms
• Supervised learning
– Training data consists of the inputs and respective outputs
(labels)
– Labels are usually created via expert annotation (expensive)
– Difficult to annotate when predicting more complex outputs
• Unsupervised learning
– Training data just consists of inputs. No labels.
– One example of such an algorithm: Expectation
Maximization
EM-Algorithm
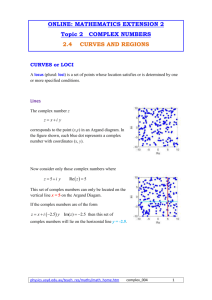
What is MLE?
• Given
– A sample X={X1, …, Xn}
– A vector of parameters θ
• We define
– Likelihood of the data: P(X | θ)
– Log-likelihood of the data: L(θ)=log P(X|θ)
• Given X, find
ML arg max L()
MLE (cont)
• Often we assume that Xis are independently identically
distributed (i.i.d.)
ML arg max L()
arg max log P( X | )
arg max log P( X 1 ,..., X n | )
arg max log P( X i | )
i
arg max logP( X i | )
i
• Depending on the form of p(x|θ), solving optimization
problem can be easy or hard.
An easy case
• Assuming
– A coin has a probability p of being heads, 1-p of
being tails.
– Observation: We toss a coin N times, and the
result is a set of Hs and Ts, and there are m Hs.
• What is the value of p based on MLE, given
the observation?
An easy case (cont)
L() log P( X | ) log p m (1 p) N m
m log p ( N m) log(1 p)
dL() d (m log p ( N m) log(1 p)) m N m
0
dp
dp
p 1 p
p= m/N
EM: basic concepts
Basic setting in EM
• X is a set of data points: observed data
• Θ is a parameter vector.
• EM is a method to find θML where
ML arg max L()
arg max log P( X | )
• Calculating P(X | θ) directly is hard.
• Calculating P(X,Y|θ) is much simpler, where Y is
“hidden” data (or “missing” data).
The basic EM strategy
• Z = (X, Y)
– Z: complete data (“augmented data”)
– X: observed data (“incomplete” data)
– Y: hidden data (“missing” data)
The log-likelihood function
• L is a function of θ, while holding X constant:
L( | X ) L( ) P( X | )
l ( ) log L( ) log P ( X | )
n
log P ( xi | )
i 1
n
logP ( xi | )
i 1
n
log P ( xi , y | )
i 1
y
The iterative approach for MLE
ML arg max L()
arg max l ()
n
arg max log p( xi , y | )
i 1
y
In many cases, we cannot find the solution directly.
An alternative is to find a sequence:
s.t.
0 , 1 ,..., t ,....
l ( ) l ( ) ... l ( ) ....
0
1
t
l ( ) l ( t ) log P ( X | ) log P ( X | t )
n
n
log P ( x i , y | ) log P ( x i , y | t )
i 1
n
log
i 1
i 1
y
y
P( x , y | )
i
y
P( x , y |
i
t
)
y
n
log
i 1
y
P ( xi , y | )
P( x i , y '| t )
y'
P ( xi , y | )
P ( xi , y | t )
log
t
P ( xi , y | t )
i 1
y P( x i , y '| )
n
y'
P ( xi , y | t )
P ( xi , y | )
log
t
P ( xi , y | t )
i 1
y P( x i , y '| )
n
y'
n
log P ( y | xi , t )
i 1
y
n
log E P ( y| x , t ) [
i
i 1
n
E P ( y| x , t ) [log
i 1
i
P ( xi , y | )
P ( xi , y | t )
P ( xi , y | )
]
P ( xi , y | t )
P ( xi , y | )
]
t
P ( xi , y | )
Jensen’s inequality
Jensen’s inequality
if f is convex, then E[ f ( g ( x)] f ( E[ g ( x])
if f is concave, then E[ f ( g ( x)] f ( E[ g ( x])
log is a concave function
E[log( p( x)] log(E[ p( x)])
Maximizing the lower bound
( t 1)
p( xi , y | )
arg max EP ( y| x , t ) [log
]
t
i
p( xi , y | )
i 1
n
P( xi , y | )
arg max P( y | xi , ) log
t
P
(
x
,
y
|
)
i 1 y
i
n
t
n
arg max P( y | xi , ) log P( xi , y | )
t
i 1
y
n
arg max EP ( y| x , t ) [log P( xi , y | )]
i 1
i
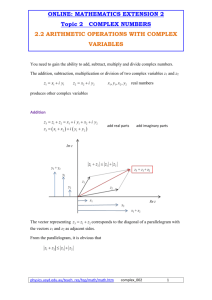
The Q function
The Q-function
• Define the Q-function (a function of θ):
Q( , t ) E[log P( X , Y | ) | X , t ] E P (Y | X , t ) [log P( X , Y | )]
n
P(Y | X , ) log P( X , Y | ) E P ( y| x , t ) [log P( xi , y | )]
t
i 1
Y
i
n
P( y | xi , t ) log P( xi , y | )
i 1
–
–
–
–
y
Y is a random vector.
X=(x1, x2, …, xn) is a constant (vector).
Θt is the current parameter estimate and is a constant (vector).
Θ is the normal variable (vector) that we wish to adjust.
• The Q-function is the expected value of the complete data log-likelihood
P(X,Y|θ) with respect to Y given X and θt.
The inner loop of the
EM algorithm
• E-step: calculate
n
Q( , t ) P( y | xi , t ) log P( xi , y | )
i 1
y
• M-step: find
( t 1)
arg maxQ( , )
t
L(θ) is non-decreasing
at each iteration
• The EM algorithm will produce a sequence
, ,..., ,....
0
1
t
• It can be proved that
l ( ) l ( ) ... l ( ) ....
0
1
t
The inner loop of the
Generalized EM algorithm (GEM)
• E-step: calculate
n
Q( , t ) P( y | xi , t ) log P( xi , y | )
i 1
y
• M-step: find
( t 1)
Q(
arg maxQ( , )
t
t 1
, ) Q( , )
t
t
t
Recap of the EM algorithm
Idea #1: find θ that maximizes the
likelihood of training data
ML arg max L()
arg max log P( X | )
Idea #2: find the θt sequence
No analytical solution iterative approach, find
, ,..., ,....
0
1
t
s.t.
l ( ) l ( ) ... l ( ) ....
0
1
t
Idea #3: find θt+1 that maximizes a tight
lower bound of
l ( ) l ( t )
P ( xi , y | )
l ( ) l ( ) E P ( y| x , t ) [log
]
t
i
P ( xi , y | )
i 1
n
t
a tight lower bound
Idea #4: find θt+1 that maximizes
the Q function
Lower bound of
( t 1)
l ( ) l ( )
t
p ( xi , y | )
arg max E P ( y| x , t ) [log
]
t
i
p ( xi , y | )
i 1
n
n
arg max E P ( y| x , t ) [log P( xi , y | )]
i 1
i
The Q function
The EM algorithm
• Start with initial estimate, θ0
• Repeat until convergence
– E-step: calculate
n
Q( , ) P( y | xi , t ) log P( xi , y | )
t
i 1
y
– M-step: find
(t 1) arg maxQ( , t )
An EM Example
E-step
M-step
Apache Mahout
Industrial Strength Machine Learning
May 2008
Current Situation
• Large volumes of data are now available
• Platforms now exist to run computations over
large datasets (Hadoop, HBase)
• Sophisticated analytics are needed to turn data
into information people can use
• Active research community and proprietary
implementations of “machine learning”
algorithms
• The world needs scalable implementations of ML
under open license - ASF
History of Mahout
• Summer 2007
– Developers needed scalable ML
– Mailing list formed
• Community formed
– Apache contributors
– Academia & industry
– Lots of initial interest
• Project formed under Apache Lucene
– January 25, 2008
Current Code Base
• Matrix & Vector library
– Memory resident sparse & dense implementations
• Clustering
– Canopy
– K-Means
– Mean Shift
• Collaborative Filtering
– Taste
• Utilities
– Distance Measures
– Parameters
Under Development
•
•
•
•
•
•
•
Naïve Bayes
Perceptron
PLSI/EM
Genetic Programming
Dirichlet Process Clustering
Clustering Examples
Hama (Incubator) for very large arrays
Appendix
• Sean Owen, Robin Anil, Ted Dunning and Ellen
Friedman,Mahout in action,Manning
Publications; Pap/Psc edition (October 14,
2011)
• From Mahout Hands on, by Ted Dunning and
Robin Anil, OSCON 2011, Portland
Step 1 – Convert dataset into a
Hadoop Sequence File
• http://www.daviddlewis.com/resources/testcolle
ctions/reuters21578/reuters21578.tar.gz
• Download (8.2 MB) and extract the SGML files.
– $ mkdir -p mahout-work/reuters-sgm
– $ cd mahout-work/reuters-sgm && tar
xzf ../reuters21578.tar.gz && cd ..
&& cd ..
• Extract content from SGML to text file
– $ bin/mahout
org.apache.lucene.benchmark.utils.Ex
tractReuters mahout-work/reuters-sgm
mahout-work/reuters-out
Step 1 – Convert dataset into a
Hadoop Sequence File
• Use seqdirectory tool to convert text file into a
Hadoop Sequence File
– $ bin/mahout seqdirectory \
-i mahout-work/reuters-out
\
-o mahout-work/reuters-outseqdir \
-c UTF-8 -chunk 5
Hadoop Sequence File
• Sequence of Records, where each record is a <Key, Value> pair
–
–
–
–
–
–
<Key1, Value1>
<Key2, Value2>
…
…
…
<Keyn, Valuen>
• Key and Value needs to be of class
org.apache.hadoop.io.Text
– Key = Record name or File name or unique identifier
– Value = Content as UTF-8 encoded string
• TIP: Dump data from your database directly into Hadoop Sequence
Files (see next slide)
Writing to Sequence Files
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path("testdata/part00000");
SequenceFile.Writer writer = new
SequenceFile.Writer(
fs, conf, path, Text.class,
Text.class);
for (int i = 0; i < MAX_DOCS; i++)
writer.append(new
Text(documents(i).Id()),
new Text(documents(i).Content()));
}
writer.close();
Generate Vectors from Sequence Files
• Steps
1. Compute Dictionary
2. Assign integers for words
3. Compute feature weights
4. Create vector for each document using word-integer
mapping and feature-weight
Or
• Simply run $ bin/mahout seq2sparse
Generate Vectors from Sequence Files
• $ bin/mahout seq2sparse \
-i mahout-work/reuters-out-seqdir/
\
-o mahout-work/reuters-out-seqdirsparse-kmeans
• Important options
– Ngrams
– Lucene Analyzer for tokenizing
– Feature Pruning
• Min support
• Max Document Frequency
• Min LLR (for ngrams)
– Weighting Method
• TF v/s TFIDF
• lp-Norm
• Log normalize length
Start K-Means clustering
• $ bin/mahout kmeans \
-i mahout-work/reuters-out-seqdirsparse-kmeans/tfidf-vectors/ \
-c mahout-work/reuters-kmeans-clusters
\
-o mahout-work/reuters-kmeans \
-dm
org.apache.mahout.distance.CosineDistanceMeas
ure –cd 0.1 \
-x 10 -k 20 –ow
• Things to watch out for
–
–
–
–
Number of iterations
Convergence delta
Distance Measure
Creating assignments
Inspect clusters
• $ bin/mahout clusterdump \
-s mahout-work/reuterskmeans/clusters-9 \
-d mahout-work/reuters-outseqdir-sparsekmeans/dictionary.file-0 \
-dt sequencefile -b 100 -n
20
Typical output
:VL-21438{n=518 c=[0.56:0.019, 00:0.154, 00.03:0.018, 00.18:0.018, …
Top Terms:
iran
=> 3.1861672217321213
strike
=>
2.567886952727918
iranian
=>
2.133417966282966
union
=>
2.116033937940266
said
=>
2.101773806290277
workers
=>
2.066259451354332
gulf
=> 1.9501374918521601
had
=> 1.6077752463145605
he
=> 1.5355078004962228