The Trie Data Structure
advertisement

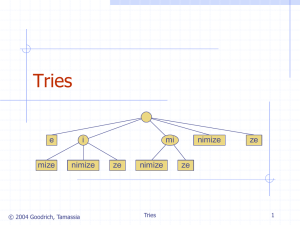
The Trie Data Structure • Basic definition: a recursive tree structure that uses the digital decomposition of strings to represent a set of strings for searching. • Example • One of the advantages of the trie data structure is that its tree depth depends on the amount of data stored in it. Each element of data is stored at the highest level of the tree that still allows a unique retrieval. Another Trie Example • Suppose we have a string that can be identified by the number sequence 8376. Assume also that the trie data structure consists of a trie[] array at the top level. If 8376 is the only data element to be stored, it can be stored as trie[8]. Assume now that another string identified as 8453 is added. To make room for the second element, we allocate another 10-element array and have trie[8] point to it. We push 8376 down and now is indexed as trie[8][3], while the new element, 8453 will be stored under trie[8][4]. Patricia (PAT) Trees • Basic definition: A trie with the additional constraint that single-descendant nodes are eliminated. • Example • PAT arrays provide the same functionality as PAT trees with less space requirement. Suffix Trees • Basic definition: A trie data structure (usually a Patricia tree) built over all suffixes of a text • Example • A suffix tree for a text of n characters can be built in O(n) time. • Suffix arrays provide the same functionality as suffix trees with less space requirement. See page 200 of your text for more on suffix arrays. IR using Suffix Trees • Text is view as one long string and each position in the text corresponds to a semi-infinite string. • No keywords or terms are used. Queries are based on substrings of the text. • The text does not need structure, but if there is one, it can be used. • Searches supported: – Proximity searching – Range searching – Regular expression searching