Natural Language Processing COMPSCI 423/723
advertisement

Natural Language Processing
COMPSCI 423/723
Rohit Kate
1
Probability Theory
Language Models
2
Probability Theory
3
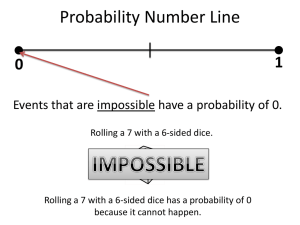
What is Probability?
• In ordinary language, probability is the degree of
certainty of an event: It is very probable that it
will rain today.
• Probability theory gives a formal mathematical
framework to work with numerical estimates of
certainty of events, using this one can:
– Predict likelihood of combinations of events
– Predict most likely outcome
– Predict something given that something else
4
Why is Probability Theory
Important for NLP?
• To obtain estimates for various outcomes of an ambiguity,
for example:
• Predict most likely parse or an interpretation of an
ambiguous sentence given the context or background
knowledge
– Time flies like an arrow.
•
•
•
•
Time goes by fast: 0.9
A particular type of flies “time flies” like an arrow: 0.05
Measure speed of flies like you will measure speed of an arrow: 0.03
…
• Instead of using some ad hoc arithmetic to encode
estimates of certainty, probability theory is preferable
because it has sound mathematics behind it, for example
rules for combining probabilities
5
Definitions
• Sample Space (Ω): Space of possible outcomes
– Outcomes of throwing a dice: {1,2,3,4,5,6}
• Event: Subset of a sample space
– An even number will show up: {2,4,6}
– Number 2 will show up: {2}
• Probability function (or probability distribution):
Mapping from events to a real number in [0,1],
such that:
P(Ω) = 1
For any events α and β if α П β = ø (disjoint) then
P(α U β) = P(α) + P(β)
6
An Example
• For throwing a dice
P({1,2,3,4,5,6}) = 1 (some outcome shows up)
• Suppose each basic outcome is equally likely, since
they are all disjoint and add up to 1, we will have
P({1}) = 1/6, P({2})=1/6, P({3})=1/6…
• P(an even number shows up) = P({2,4,6}) = P({2}) +
P({4}) + P({6}) = 1/6 + 1/6 + 1/6 = 1/2
• P(an even number or 3 shows up) = 1/2 + 1/6= 2/3
• P(an even number or 6 shows up) ≠ 1/2 + 1/6 why?
P({2,4,6}) = 1/2
7
Interpretation of Probability
• Frequentist interpretation:
P({3})=1/6: If a dice is thrown multiple times then
1/6th of the times 3 will show up
P(It will rain tomorrow) = 1/2 ??
• Subjective interpretation: One’s degree of
belief that the event will happen
The mathematical rules should hold for both
interpretations.
8
Estimating Probabilities
• For well defined sample spaces and events, they
can be analytically estimated:
P({3}) = 1/6 (assuming fair dice)
• For many other sample spaces it is not possible to
analytically estimate, for example P(A teenager
will drink and drive).
• For these cases they can be empirically estimated
from a good sample,
P(A teenager will drink and drive) = # of
Teenagers who drink and drive/# of teenagers
9
Conditional Probability
• Updated probability of an event given that
some event happened
P({2}) = 1/6
P({2} given an even number showed up) = ?
Represented as: P({2}|{2,4,6}) or P(A|B)
P(A|B) = P(AПB)/P(B) (for P(B) > 0)
P({2}|{2,4,6}) = P({2})/P({2,4,6}) = 1/6/(1/2) = 1/3
10
Multiplicative and Chain Rules
• Multiplicative rule:
P(AПB) = P(B)P(A|B) = P(A)P(B|A)
• Generalization of the rule, chain rule:
P(A1ПA2П…ПAn) =
P(A1)P(A2|A1)P(A3|A1ПA2)…P(An|A1П..ПAn-1)
Or in any order of As
11
Independence
• Two events A and B are independent of each other if
P(AПB) = P(A)P(B) or equivalently P(A)=P(A|B) or
P(B)=P(B|A), i.e. happening of an event B does not change
the probability of A or vice versa. Otherwise the events are
dependent.
Example:
• P({1,2}) = 1/3 P(Even) = 1/2
• P({1,2} П Even) = P({2}) = 1/6 = P({1,2})*P(Even)
• P({1,2}|Even) = P({1,2}ПEven)/P(Even) = 1/6/(1/2) = 1/3
Hence , P({1,2}|Even)=P({1,2})
– Given that an even number showed up does not change the
probability of whether one or two showed up. Hence these are
independent events.
12
Independence
• P({2}|Even) = P({2}ПEven)/P(Even) =
P({2})/P{2,4,6} = 1/6/(1/2) = 1/3
P({2}) ≠P({2}|Even)
– Given that even number showed up increases the
probability that the number was 2, hence these
are not independent events
• Outcome of second throw of dice is supposed
to be independent of the first throw of dice
P(consecutive {2}) = P({2})*P({2}) = 1/6*1/6 = 1/36
13
Independence
• If A1, A2..An are independent then,
P(A1ПA2П…ПAn) = P(A1)P(A2|A1)P(A3|A1ПA2)…P(An|A1П..ПAn-1)
(chain rule)
= P(A1)P(A2)P(A3)…P(An)
Independence assumption is often used in NLP to simplify
computations of complicated probabilities.
S
For example, probability of a
parse tree is often simplified as the
product of probabilities of
generating individual productions.
NP
VP
Article NN
The
girl
Verb
ate
NP
Article
NN
the
cake
14
Conditional Independence
• Two events A and B are conditionally
independent given C if
P(AПB|C) = P(A|C)P(B|C)
Conditional independence is encountered more
often than unconditional independence.
15
Maximum Likelihood Estimate
• P(A teenager will drink and drive) = # of
Teenagers who drink and drive/# of teenagers
• Suppose out of a sample of 5 teenagers one
drinks and drives
P(A teenager will drink and drive) = 1/5
• Relative frequency estimates can be proven to be
maximum likelihood estimates (MLE) because
they maximize the probability that it will generate
the sampled data
• Any other probability value will explain the data
with less probability
16
Maximum Likelihood Estimates
• If P(TDD) = 1/5 then P(not TDD)=4/5
– Probability of the sampled data making assumption
that each teenager is independent
• P(Data)=1/5*(4/5)4=0.08192
– It will be less for any other value of P(TDD), for
P(TDD)=1/6,
• P(Data) = 1/6*(5/6)4 = 0.0803.
– For P(TDD)=1/4
• P(Data) = 1/4*(3/4)4 = 0.07091
• Whenever possible to compute, simple frequency
counts are not only intuitive but theoretically also
the best probability estimates
17
Bayes’ Theorem
• Lets us calculate P(B|A) in terms of P(A|B)
• For example, using Bayes’ theorem we can
calculate P(Hypothesis|Evidence) in terms of
P(Evidence|Hypothesis) which is usually easier
to estimate.
18
Bayes Theorem
P( E | H ) P( H )
P( H | E )
P( E )
Simple proof from definition of conditional probability:
P( H E )
P( H | E )
P( E )
(Def. cond. prob.)
P( H E )
(Def. cond. prob.)
P( E | H )
P( H )
P( H E) P( E | H ) P( H )
QED: P( H | E )
P( E | H ) P( H )
P( E )
19
Random Variable
• Represents a measurable value associated with
events, for example, the number that showed up
on the dice, sum of the numbers of consecutive
throws of a dice
• Let X represent the number that showed up
P(X=2) is the probability that 2 showed up
• Let Z represent sum of the numbers that showed
up on throwing the dice twice
P(Z > 5) is the probability that the sum was greater than
5
20
Probability Distribution
• Probability distribution: Specification of probabilities
for all the values of a random variable
Example: X represents the number that shows up when a
dice is thrown, a probability distribution (should add to 1)
X
P(X)
1
1/6
2
1/6
3
2/6
4
1/6
5
1/12
6
1/12
Given a probability distribution, probability of any event over
the random variable can be computed, P(X>5), P(X=2 or 3)
21
Joint Probability Distribution
• The joint probability distribution for a set of
random variables, X1,…,Xn gives the probability of
every combination of values: P(X1,…,Xn)
• Given a joint probability distribution, probability
of any event over the random variables can be
computed
• Example:
S: shape (circle, square)
C: color (red, blue)
L: label (positive, negative)
22
Joint Probability Distribution
• Joint distribution of P(S,C,L):
S,C,L
P(S,C,L)
Circle, Red, Positive
0.2
Circle, Red, Negative
0.05
Circle, Blue, Positive
0.02
Circle, Blue, Negative
0.2
Square, Red, Positive
0.02
Square, Red, Negative
0.3
Square, Blue, Positive
0.01
Square, Blue, Negative
0.2
23
Marginal Probability
Distributions
• The probability of all possible conjunctions
(assignments of values to some subset of
variables) can be calculated by summing the
appropriate subset of values from the joint
distribution
P(red circle) 0.20 0.05 0.25
P(red ) 0.20 0.02 0.05 0.3 0.57
• In general, distribution of subset of random
variables, for e.g. P(C) or P(C^S), can be
computed from joint distribution, these are called
marginal probability distributions
24
Conditional Probability
Distributions
• Once marginal probabilities are computed,
conditional probabilities can also be
calculated
P( positive| red circle)
P( positive red circle) 0.20
0.80
P(red circle)
0.25
• In general, distributions of subsets of random
variables with conditions, for e.g. P(L|C^S),
can also be computed, these are called
conditional probability distributions
25
Language Models
Most of these slides have been adapted from
Raymond Mooney’s slides from his NLP course at UT
Austin.
26
What is a Language Model (LM)?
• Given a sentence how likely is it a sentence of the
language?
The dog bit the man. => very likely or 0.75
Dog man the the bit. => very unlikely or 0.002
The dog bit man. => likely or 0.15
• A probabilistic model is better than a formal
grammar model which will only give a binary
decision
• To specify a correct probability distribution,
the probability of all sentences in a language
must sum to 1
27
What are the Uses of an LM?
• Speech recognition
– “I ate a cherry” is a more likely sentence than “Eye eight
uh Jerry”
• OCR & Handwriting recognition
– More probable sentences are more likely correct readings
• Machine translation
– More likely sentences are probably better translations
• Generation
– More likely sentences are probably better NL generations
• Context sensitive spelling correction
– “Their are problems wit this sentence.”
28
What are the Uses of an LM?
• A language model also supports predicting
the completion of a sentence.
– Please turn off your cell _____
– Your program does not ______
• Predictive text input systems can guess what
you are typing and give choices on how to
complete it.
29
What is the probability of a
sentence?
P(A1ПA2П…ПAn) = P(A1)P(A2|A1)P(A3|A1ПA2)…P(An|A1П..ПAn-1)
(chain rule)
P(Please,turn,off,your,cell,phone) =
P(Please)P(turn|Please)P(off|Please,turn)P(your|Please,t
urn,off)P(cell|Please,turn,off,your)P(phone|Please,turn,o
ff,your,cell)
Estimate the above probabilities from a large corpus
–
–
Too many probabilities (parameters) to estimate
They become sparse, cannot be estimated well.
30
What is the probability of a
sentence?
Approximate the probability by making independence
assumptions
P(Please,turn,off,your,cell,phone) =
P(Please)P(turn|Please)P(off|Please,turn)P(your|Please,turn,off)P(c
ell|Please,turn,off,your)P(phone|Please,turn,off,your,cell)
Bigram approximation:
P(Please,turn,off,your,cell,phone) =P(Please)
P(turn|Please)P(off|turn)P(your|off)P(cell|your)P(phone|cell)
Trigram approximation:
P(Please,turn,off,your,cell,phone) =
P(Please)P(turn|Please)P(off|Please,turn)P(your|turn,off)P(cell|off,
your)P(phone|your,cell)
31
N-Gram Model Formulas
• Word sequences
w1n w1...wn
• Chain rule of probability
n
P( w ) P( w1 ) P( w2 | w1 ) P(w3 | w )...P( wn | w ) P( wk | w1k 1 )
n
1
2
1
• Bigram approximation
n 1
1
k 1
n
P( w ) P( wk | wk 1 )
n
1
k 1
• N-gram approximation
n
P( w ) P( wk | wkk1N 1 )
n
1
k 1
32
Estimating Probabilities
• N-gram conditional probabilities can be estimated
from raw text based on the relative frequency of
word sequences, they are the maximum
likelihood estimates
Bigram:
N-gram:
C ( wn 1wn )
P( wn | wn 1 )
C ( wn 1 )
n 1
n N 1
P(wn | w
C (wnn1N 1wn )
)
C (wnn1N 1 )
• To have a consistent probabilistic model, append
a unique start (<s>) and end (</s>) symbol to
every sentence and treat these as additional
words
33
Generative Model of a Language
• An N-gram model can be seen as a
probabilistic automata for generating
sentences.
Start with an <s> symbol
Until </s> is generated do:
Stochastically pick the next word based on the conditional
probability of each word given the previous N 1 words.
34
Training and Testing a Language Model
• A language model must be trained on a
large corpus of text to estimate good
parameter (probability) values
• Model can be evaluated based on its ability
to predict a high probability for a disjoint
(held-out) test corpus
• Ideally, the training (and test) corpus
should be representative of the actual
application data
35
Unknown Words
• How to handle words in the test corpus
that did not occur in the training data, i.e.
out of vocabulary (OOV) words?
• Train a model that includes an explicit
symbol for an unknown word (<UNK>).
– Choose a vocabulary in advance and replace
other words in the training corpus with <UNK>.
– Replace the first occurrence of each word in
the training data with <UNK>.
36
Evaluation of an LM
• Ideally, evaluate use of model in end application
(extrinsic)
– Realistic
– Expensive
• Evaluate on ability to model test corpus (intrinsic)
– Less realistic
– Cheaper
37
Perplexity
• Measure of how well a model “fits” the test data
• Uses the probability that the model assigns to the
test corpus
• Normalizes for the number of words in the test
corpus and takes the inverse
PP (W ) N
1
P ( w1w2 ...wN )
• Measures the weighted average branching factor
in predicting the next word (lower is better)
38
Sample Perplexity Evaluation
• Models trained on 38 million words from
the Wall Street Journal (WSJ) using a
19,979 word vocabulary.
• Evaluate on a disjoint set of 1.5 million WSJ
words.
Unigram
Perplexity
962
Bigram
170
Trigram
109
39
Smoothing
• Since there are a combinatorial number of
possible word sequences, many rare (but not
impossible) combinations never occur in training,
so MLE incorrectly assigns zero to many
parameters (also know as sparse data problem).
• If a new combination occurs during testing, it is
given a probability of zero and the entire
sequence gets a probability of zero
• In practice, parameters are smoothed (also know
as regularized) to reassign some probability mass
to unseen events.
– Adding probability mass to unseen events requires
removing it from seen ones (discounting) in order to
maintain a joint distribution that sums to 1.
40
Laplace (Add-0ne) Smoothing
• “Hallucinate” additional training data in which each
word occurs exactly once in every possible (N1)gram context and adjust estimates accordingly.
C ( wn1wn ) 1
C ( wn1 ) V
Bigram:
P( wn | wn1 )
N-gram:
n 1
C
(
w
n N 1wn ) 1
P(wn | wnn1N 1 )
C (wnn1N 1 ) V
where V is the total number of possible words (i.e.
the vocabulary size)
• Tends to reassign too much mass to unseen events,
so can be adjusted to add 0<<1 (normalized by V
instead of V)
• More advanced smoothing techniques have also
41
been developed
Model Combination
• As N increases, the power (expressiveness)
of an N-gram model increases, but the
ability to estimate accurate parameters
from sparse data decreases (i.e. the
smoothing problem gets worse).
• A general approach is to combine the
results of multiple N-gram models of
increasing complexity (i.e. increasing N).
42
Interpolation
• Linearly combine estimates of N-gram
models of increasing order
Interpolated Trigram Model:
Pˆ (wn | wn2, wn1 ) 1P(wn | wn2, wn1 ) 2 P(wn | wn1 ) 3 P(wn )
Where:
i
1
i
• Learn proper values for i by training to
(approximately) maximize the likelihood of
an independent development (also known as
tuning) corpus
43
Backoff
• Only use lower-order model when data for higher-order
model is unavailable (i.e. count is zero).
• Recursively back-off to weaker models until data is
available.
n 1
n 1
P
*
(
w
|
w
)
if
C
(
w
n 1
n
n N 1
n N 1 ) 1
Pkatz ( wn | wn N 1 )
n 1
n 1
(
w
)
P
(
w
|
w
otherwise
n N 1
katz
n
n N 2 )
Where P* is a discounted probability estimate to reserve
mass for unseen events and ’s are back-off weights
44
A Problem for N-Grams LMs:
Long Distance Dependencies
• Many times local context does not provide the
most useful predictive clues, which instead are
provided by long-distance dependencies
– Syntactic dependencies
• “The man next to the large oak tree near the grocery store on
the corner is tall.”
• “The men next to the large oak tree near the grocery store on
the corner are tall.”
– Semantic dependencies
• “The bird next to the large oak tree near the grocery store on
the corner flies rapidly.”
• “The man next to the large oak tree near the grocery store on
the corner talks rapidly.”
• More complex models of language that use syntax
and semantics are needed to handle such
dependencies
45
Domain-specific LMs
• Using a domain-specific corpus one can
build a domain-specific language model
• For example, train a language model for
each difficulty level (grades 1 to 12)
• Then automatically predict difficulty level
of a new document and recommend for the
grade level
46
A Large LM
• Google had released a 5-gram LM trained on one
trillion words in 2006
• Available through Linguistic Data Consortium
(LDC) (not free)
http://www.ldc.upenn.edu/Catalog/CatalogEntry.jsp?catalogId=LDC2006T13
• Data Sizes
•
•
•
•
•
•
•
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams:
13,588,391
Number of bigrams:
314,843,401
Number of trigrams:
977,069,902
Number of fourgrams: 1,313,818,354
•
Number of fivegrams:
1,176,470,663
47
Homework 1, Due next week in class
Find marginal distributions for P(C^S) and
P(C) from the joint distribution shown in
slide #23. Compute the conditional
distribution P(S|C) from this.
48