3323_11_Milan_Micic_DBSCAN

DBSCAN
Data Mining algorithm
Professor
Dr Veljko Milutinović
Student
Milan Micić
2011/3323 milan.z.micic@gmail.com
School of Electrical Engineering, University of Belgrade
Department of Computer Engineering
Content
•
•
•
•
•
•
•
• Introduction
The DBSCAN basic idea
Algorithm
DBSCAN on R
Example
Advantages
Disadvantages
References
2/13
Introduction
•
•
•
Data clustering algorithms
Using in machine learning, pattern recognition, image analyses, information retrieval, and bioinformatics
Hierarchical, centroid-based, distribution-based, density-based, etc
3/13
DBSCAN basic idea
•
•
•
Density-Based Spatial Clustering of Applications with Noise
•
• Munich,1996
Derived from a human natural clustering approach
•
•
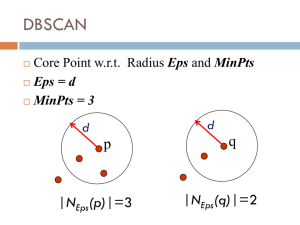
Input parameters
The size of epsilon neighborhood – ε
Minimum points in cluster – MinPts
Neighborhood of a given radius ε has to contain at least a minimum number of points MinPts
4/13
DBSCAN basic idea
•
•
•
•
Directly density-reachable, p
1 p
1 from p belongs to the ε neighborhood of p
2
2 p
2
's neighborhood size is greater than a given parameter MinPts
•
Density-reachable, p
0 from p n
Exists a chain of points p
1
,..., p n-1
, where p i+1 is directly density-reachable from p i
• Core, border and noise point
5/13
Algorithm
DBSCAN(D, eps, MinPts)
C = 0 for each unvisited point P in dataset D mark P as visited
N = regionQuery(P, eps) if sizeof(N) < MinPts mark P as NOISE else
C = next cluster expandCluster(P,N,C,eps,MinPts) add P to cluster C for each point P' in N if P' is not visited mark P' as visited
N' = regionQuery(P', eps) if sizeof(N') >= MinPts
N = N joined with N' if P' is not yet member of any cluster eps, MinPts)
• Complexity with indexing structure: O(n*log(n))
6/13
DBSCAN on R
•
•
•
•
•
FPC - Flexible Procedures for Clustering
GNU General Public License
Various methods for clustering and cluster validation
Interface functions for many methods implemented in language R
DBSCAN: O(n 2 )
•
• dbscan(x,0.2,showplot=2) dbscan Pts=600 MinPts=5 eps=0.2
0 1 2 3 4 5 6 7 8 9 10 11 seed 0 50 53 51 52 51 54 54 54 53 51 1 border 28 4 4 8 5 3 3 4 3 4 6 4 total 28 54 57 59 57 54 57 58 57 57 57 5
7/13
Example
• Astronomy task
• Identifying celestial objects by capturing the radiation they emit
• Captured noise (by sensors, diffuse emission from atmosphere and space itself)
•
• Eliminating method – to constrain the relevant intensity by a known threshold
In this case – only pixels whose intensity are less than 50
(and consequently darker) are being considered
8/13
Example
•
•
•
DBSCAN algorithm applied on individual pixels
Linking together a complete emission area
•
Each of the generated cluster will define a celestial entity
ε = 5, MinPts = 5, 64 clusters and 224 outliers found
9/13
Disadvantages
•
•
•
•
Appropriate parameters ε and MinPts
Numerous experiments indicates best MinPts = 4
•
Clustering datasets with large difference in densities
“Curse of dimensionality”
In every algorithm based on the Euclidean distance for high-dimensional data sets
10/13
Advantages
•
•
•
•
•
Does not require number of clusters in the data a priori
Can find arbitrarily shaped clusters
• Even clusters completely surrounded by a different cluster
Mostly insensitive to the ordering of the points in the database
• Only border points might swap cluster membership
Has a notion of noise
Requires just two parameters
11/13
References
•
•
•
•
Martin Ester, Hans-Peter Kriegel, Joerg Sander, Xiaowei Xu:
“ A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise” ,
Institute for Computer Science, University of Munich,
1996;
Mehmed Kantardzic:
“ Data Mining: Concepts, Models, Methods, and Algorithms ”,
2011;
Wikibooks: http://en.wikibooks.org/wiki/Data_Mining_Algorithms_In_R/Clustering/
Density-Based_Clustering ;
Wiki: http://en.wikipedia.org/wiki/DBSCAN
12/13
Thank you for your attention!
Questions
Milan Micić milan.z.micic@gmail.com
13/13