Connection Machine - University of Virginia
advertisement

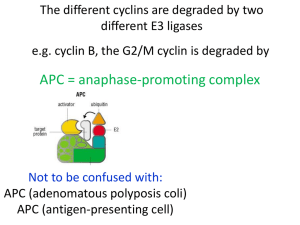
Connection Machine Architecture Greg Faust, Mike Gibson, Sal Valente CS-6354 Computer Architecture Fall 2009 1 Historic Timeline • • • • • • • • • 1981: MIT AI-Lab Technical Memo on CM 1982: Thinking Machines Inc. Founded 1985: Danny Hillis wins ACM “Best PhD” Award 1986: CM-1 Ships 1987: CM-2 Ships 1991: CM-5 Announced 1991: CM-5 Ships 1994: TMI Chapter 11 – Sun/Oracle pick bones Heavily DARPA funded/backed $16M+ Direct Contracts plus subsidized CM sales 2 Involved Notables • • • • • • • • • Danny Hillis – CM inventor and TMI Founder Charles Leiserson – Fat tree inventor Richard Feynman – Noble Prize winning Physicist Marvin Minsky – MIT AI Lab “Visionary” Guy Steele – Common Lisp, Grace Hopper Award Stephen Wolfram – Mathematica inventor Doug Lenat – Mind/Body problem philosopher Greg Papadopoulos – MIT Media lab, Sun CTO various others 3 CM-1 and CM-2 Architecture • • • • • Original design goal to support neuron like simulations Up to 64K single bit processors (actually 3 bits in and 2 out) 16 Processors/chip, 32chips/PCB, 16 PCBs/cube, 8cubes/hypercube Hypercube architecture – Each 16-Proc chip a hyper-node Each proc has 4K bits of bit addressable RAM – Distributed Physical Memory – Global Memory Addresses • • • • • Up to 4 front-end computers talk to sequencers via 4x4 crossbar “Sequencers” issue SIMD instructions over a Broadcast Network Bit procs communicate via 2D local HW grid connections (“NEWS”) Bit procs communicate via hypercube network using MSG passing Lots of Twinkling Lights!! 4 CM-1 CM-2 Architecture 5 CM-1 and CM-2 Programming • ISA supports: – Bit-oriented operations – Arbitrary precision multi-bit scalar Ops using bit-serial implementation on bit procs – Full Multi-Dimensional Vector Ops • “Virtual Processor” idea similar to CUDA threads but they are statically allocated • OS and Programming Tools run on front-ends • *Lisp as the initial programming language • Later C* and CM-Fortran 6 CM-2 Improvements • • • • 1 Weitek IEEE FP coprocessor per 32 1-bit procs Up to 256K bits of memory per processor Added ECC to Memory Implemented the IO subsystem – Up to 80 GByte RAID array called “Data Vault” uses 39 Striped Disks and ECC, plus spare disks on standby – High Speed Graphics Output • En-route MSG combining in H-Cube router • New implementation of Multi-Dimensional NEWS on top of H-Cube (special addressing mode) 7 CM-1 Photo 8 CM-5 vs CM-1 and CM-2 • • • • Significant departure from CM-1 and CM-2 Targeted at more scientific and business applications More Commercial Off-The-Shelf components (“COTS”) Large Array of SPARC Processing Nodes – 1-bit processors are abandoned • Abandoned “NEWS” Grid and Hyper-Cube Networks • Delivered 1024 node machine, with claims 16K nodes possible • Even More Twinkling Lights! 9 CM-5 Photo – Watch it Blink 10 CM-5 Overall Architecture • "Coordinated Homogeneous Array of RISC Processors“ or “CHARM” • Asymmetric CoProcessors Model – Large Array of Processor Nodes – Small Collection of Control Nodes • 2 Separate scalable networks – One for data – One for control and synchronization • Still uses striped RAID for high disk BandWidth 11 Division of Labor • Processor Nodes can be assigned to a “Partition” • One Control Node per Partition • Control Node runs scalar code, then broadcasts parallel work to Processor Nodes • Processor Nodes receive a program, not an instruction stream, have own Program Counter • Processor nodes can access other node's memory by reading or writing a global memory address • Processor Nodes also communicate via MSG passing • Processor Nodes cannot issue system calls 12 Control Nodes • • • • • • Full Sun Workstations Running UNIX Connected to the “Outside World” Handles Partition Time Sharing Connected to both data and control networks Performs System Diagnostics 13 Processor Nodes • Nodes are a 5-chip microprocessor – Off the Shelf SPARC processor @ 40 MHz – 32MBytes local node memory – Multi-port memory controller for added BW – “Caching techniques do not perform as well on large parallel machines” – Proprietary 4-FPU Vector coprocessor – Proprietary network controller 14 CM-5 Processor Node Diagram 15 Data Network Architecture • Point to Point Inter-node communication and I/O • Implemented as a Fat Tree – Fat Trees invented by TMI employee Charles Leiserson • • • • Claim: Onsite BandWidth Expandable Delivering 5GB/sec Bisection BW on 1024 node machine Data router chip is a 8x8 crossbar switch Faulty nodes are mapped out of network – Programs can not assume a network topology • Network can be flushed when Time Share swaps occur • Network, not processors, guarantee end to end delivery 16 Fat Tree Structure 17 Separate Control Network • • • • • • Synchronization & control network Complete Binary Tree organization Provides broadcast capability Implements barrier operations Implements interrupts for timesharing Performs reduction operators (Sum, Max, AND, OR, Count, etc) 18 CM-5 Programming • Supports multiple Parallel High Level Languages and Programming Styles – Including Data Parallel Model from CM-1 and CM-2 • Goal: Hide many decisions from programmers – CM-1, CM-2 vs CM-5 ISA changes – Use of Processor Node CPU vs Vector CoProcessors – Partition Wide Synchronizations generate by Compiler • Is it MIMD, SPMD, SIMD? – “Globally Synchronized MIMD” 19 Sample CM Apps • Machine Learning – Neural Nets, concept clustering, genetic algorithms • • • • • • • • VLSI Design Geophysics (Oil Exploration), Plate Tectonics Particle Simulation Fluid Flow Simulation Computer Vision Computer Graphics , Animation Protein Sequence Matching Global Climate Model Simulation 20 References • • • • • • Danny Hillis PhD: The Connection Machine Inc: The Rise and Fall of Thinking Machines Wiki: Connection Machine ACM: The CM-5 Connection Machine ACM: The Network Architecture of the CM-5 IEEE: Architecture and Applications of the Connection Machine • IEEE: Fat-trees: universal networks for hardware-efficient supercomputing • Encyclopedia of Computer Science and Technology 21