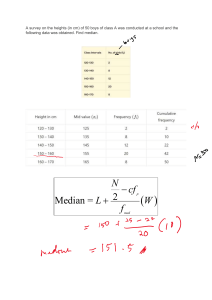
Introduction to Statistics By Ismaila Zango Mohammed Department of Sociology Bayero University, Kano 1. Introduction Statistics is of value because we are constantly exposed to statistics in our every day life. For instance voting polls, results of consumer survey are reported in news papers. In addition to that you may be interested in reading research reports and interpreting them. Quite often we tend to associate our world with numbers such as birth rate, unemployment rate, and divorce rates. Statistics is applicable to a wide variety of academic disciplines from the natural and social sciences to the humanities, government and business. In this chapter attempt is made to define statistics, differentiate descriptive from inferential statistics. Examples of the two classifications are provided with illustrations. The chapter also deals with measures of central tendency and dispersion. Statistics is a mathematical science dealing with the collection, analysis, interpretation or explanation, and presentation of data. In other words, Statistics is a branch of mathematics that deals with the collection, organization, and analysis of numerical data. According to FrankNachmias and Leon-Guerrero (2000) statistics refers to a set of procedures used by social scientists to summarize, organize and communicate information represented in numbers. This type of information is called data. Similarly, Agretis and Franklin (2007) define statistics as the art and science of designing studies and analyzing data that those studies produced. In other words the main aim of statistics is to translate data into knowledge and understanding of the world around us. In addition it also encompasses prediction and forecasting based on data. From the last definition three are things have emerged, which include design, description, and inference. Design means planning how to gather data to answer the questions of interest. Thus, statistics is a reliable means of describing accurately the values of economic, political, social, psychological, biological, and physical data and serves as a tool to correlate and analyze such data. Uses of statistics are no longer confined to gathering and tabulating data, but are chiefly a process of interpreting the information. 1.1 Descriptive Statistics Descriptive statistics are branch of statistics that help researchers to summarize, organize and describe data collected from population or sample. Example of descriptive statistics include frequency, percentage, measures of central tendency and measures of dispersion, which allow the researcher to give a vivid description of events, population and distribution of properties in the population. According Trochim (2001) descriptive statistics are used to describe the basic features of the data in a study. They provide simple summaries about the sample and the 1 measures. Together with simple graphic analysis, they form the basis of virtually every quantitative analysis of data. Descriptive statistics is simply used to describe what is going on in our data. Descriptive Statistics are used to present quantitative descriptions in a manageable form. In a research there are many variables to measure, or may involve lager number of people on a particular measure. For instance in 2007 post election survey in northwest zone in Nigeria a sample 4820 was drawn. We may be interesting in knowing how many of these people have voted, how many of them are males/females and the age distribution of the sample. This can be done by knowing the distribution of the sample by age, sex and voting. In other words the data can be organized according distribution, similarity of certain features for example age (central tendency) of differences (variation or dispersion). There are certain measures, which will be discussed below 1.2 Inferential Statistics Inferential statistics on the other hand are concerned with making prediction or inference about a population from observations and analysis of samples. In others words, from the observation of a sample, inferences can be made about the entire population with regards to the variables the researchers is interest in. With inferential statistics according to Trochim (2001) you are trying to reach conclusions that extend beyond the immediate data alone. For instance, we use inferential statistics to try to infer from the sample data what the population might think. Or, we use inferential statistics to make judgments of the probability that an observed difference between groups is a dependable one or one that might have happened by chance in this study. Thus, we use inferential statistics to make inferences from our data to more general conditions. In other wards inference is a process of making generalization of drawing conclusion about attributes of a population from evidence from the sample According to Knoke, Bohrnstedt and Mee (2002) there are number of statistical significant test that allow for making inference that conclusion drawn from a sample are true for the population from which the sample was drawn. The similarity of the sample based observation and the population to a large extent depends on random selection of sample. Random selection of sample ensures that every element in the population has an equal chance of being part of the sample. Examples of inferential statistics include t test, Z test, correlation, regression etc. 2. Types and Sources of Statistical Data Data according to Marshal (1998) are records of observation, which can take many forms such as scores in IQ tests, interview records, field diaries. In other words, data are information, often in the form of facts or figures obtained from experiments or surveys, used as a basis for making calculations or drawing conclusions. Statistical data can be classified into primary and secondary. Data in general could also be categorized into quantitative and qualitative. Quantitative data is any information represented by numbers that can be subjected to statistical 2 analysis, while qualitative data are facts collected which may not necessarily be converted into numbers. According to Sambo (2008) qualitative data consist of transcripts of individual interviews, focus group discussion, field notes, schemes of work, photographs etc. Both qualitative and quantitative could classified as either primary or secondary Primary data are collected by the researcher directly from the subjects using questionnaire or structured interview. Secondary data exist, usually generated for reasons other than reasons of the current researcher. For example a researcher interested in the quality of housing in Nigeria can use data from 2006 census. Secondary data can be qualitative or quantitative. However, for this chapter we are concerned with quantitative data, the decision to use secondary data depends on whether the existed data is of good quality. Sometimes the existing data may even be of superior quality. Secondary data are obtainable in Nigeria from government agencies such as National Population Commission. National Bureau of Statistics, National Planning Commission, Central Bank of Nigeria etc. There are also other databases such Uniform Crime Reports, reports from school enrollment, data on marriage and divorce, vital statistics (record of births and deaths). There are also international databases produced by United Nations agencies such as United Nation Development Programme (UNDP), United Nations International Children Education Fund (UNICEF), World Bank etc. 3. Discussion 3.1 Distribution. This is the way and manner particular characteristics researchers are interested in shared across the sample. For instance how many people in the sample are males or females? This information can be presented in terms of the number of occurrence in the sample (frequency). This can be presented in frequency table as follows. Distributions of discrete variable classify persons, objects or events according to quality of their attributes for instance level of education, while continuous variable classify them according their quantities. Frequency distribution is a table of outcome or response category of variable and the number of time each outcome is observed. Distribution according to Nachmias and Nachmias (1987) is the first step in data analysis and makes sense in relation to other frequencies. Frequencies expressed in comparable number are called proportion or percentages and are usually expressed as: Proportion = fi/N Percentage =fi/N x 100 For instance using data in Table 1 the proportion of male to female is fi/N = 3032/4820 = 0.629 and the percentage is fi/N x 100 = 3032/4820 x 100 =0.629 x 100 = 62.9 Table 1 below is an example of frequency distribution table. The information can also be presented in charts; the data in table1 is presented in pie chart. 3 Table 1 Sex distribution of Respondents Sex Male Female Total Frequency 3032 1788 4820 Proportion 0.629 0.371 1.00 Percent 62.9 37.1 100 Source: Centre for Democratic Research and Training (2007) Chart 1 Sex Distribution of Respondents Percent 37.1 Male 62.9 Female The frequency counts could be transformed into relative frequency of proportion by dividing the number of cases in each outcome by the total number of cases. To determine the proportion of male in table 1 we simple divide number of male by the total number of cases 3032/4820 = 0.629 the proportion is presented in column 3 in table 1. This allows us to compare the number males to female in the sample. The proportion could be transformed into percentages by multiplying the proportion by 100. For example the percentage of females is 0.371 x 100 = 37.1. The percentage is standardize for sample and are usually presented in the nearest tenth because it will make sense to talk of one tenth of a person. Values of 0.1- 0.4 are rounded down while numbers from 0.5- 0.9 are rounded upward (Knoke, Bohrnstedt and Mee 2002) In statistical language notations and shorthand are often used represent things. For instance N refer to the total number of cases, f denoting frequency associated th outcome (category) of variable. The subscript can take from 1 to the numbers of categories K. In this case our K is 2 that is the number of categories. The distribution of the sample can be presented in tabula or graphic form such as chart. i i i 4 3.2 Measure of Central Tendency In addition to the distribution of the sample, data often exhibit a cluster or central point, this number is called a measure of central tend we may be interested in a having single figure that summarizes the information about our sample that is the central tendency, or average value of set of scores. It is important to however, note that the central tendency is only meaningful at the interval level of measurement. The measures of central tendency include the mode, median and mean. i. The mode (MO) is the most frequent number in the distribution and thus it is easy to determine. For instance thirty students gave their age as follows 15, 15, 17, 17, 18, 18, 19, 20, 20, 21, 22, 22, 23, 23, 23, 24, 24, 27, 28, 29, 29, 30, 30, 31, 32, 35, 36, 36, 37, 38. In this age distribution our mode is 23, which appeared more than any figure in the distribution. It is important to however note that some distribution could have more than one mode. Such distributions are known as bimodal distribution. In the case of grouped data the category that has the highest frequency is the model category. If the data above is grouped as indicated below. The model category is age group 20-24, which has the highest frequency For grouped data the mode is the mid-point of the category that has the largest number of cases for example the mode in Table 2 is located in age category of 20-24 years, which has the largest frequency. To find the mid point we simply add lower and upper limit of the response category, which in this case is 20+24/2= 22. The mid point is 22, thus the mode in this case is easy to determine. Table 2 Age Distribution Age category 15-19 20-24 25-29 30-34 35-39 Total Freq 7 10 4 4 5 30 Percent 23 33 13 13 17 99 ii. The Median (Mdn) is applicable to variable with categories that can be arranged in a sequence from lowest to highest. In other words to find the median the cases have to be arranged from the lowest to the highest or from highest to lowest. The median is the outcome that divides the distribution exactly into half. That is half of the cases will be below the median and the other half will be above the median. For the above data on age the median is 23.5. The existence of the median depends on whether the distribution is even or odd. In the case of odd distribution, there is one middle number below, which half of the cases are found and over which the other half are found. For example consider these two age distributions. Distribution A: 15, 15, 17, 17, 18, 18, 19, 20, 20 5 Distribution B: 15, 15, 17, 17, 18, 18, 19, 20, 20, 21, 22, 23 Distribution A has an odd number of cases (nine). Thus, its median score is the fifth observation or 18. Distribution B has even number of cases (twelve) so it median falls half between the sixth and the seventh cases; therefore its value is the average of the two cases (18+19)/2 = 18.5. In other words, the median is the middle case for odd number distribution of the average scores for the two middle cases for even number distribution. For grouped data however, the median is value of that category at which the cumulative percentage reaches 50.0% (Knoke, Bohrnstedt and Mee 2002) The median for the grouped data is computed with assumption that cases in the category containing the median are evenly distributed throughout the interval. The formula for computing the median for grouped data is L + 1/2N-F W f mdn Where: L = lower true limit of the category containing the median/lower class limit of the median class N= Total number of cases F=Cumulative frequency up to but not including the frequency of the median interval f = The frequency of the median class W = Width of interval containing the median or size of the median class mdn To obtain the true limit we divide the difference between adjacent limits by 2. To obtain the true limit In case of table 4, 30-29 = 1/2 =0.5. Subtract this from lower limits and add it to the upper limits to get the true limit. Table 4 Computation of the Median for Grouped Data Stated Limit True Limit f F 20-29 19.5-29.5 7 7 30-39 29.5-39.5 3 10 40-49 39.5-49.5 9 19 50-59 49.5-59.5 4 23 60-69 59.5-69.5 2 25 To obtain our median, we need to locate the median interval. The median interval will be the one with the middle number. If the data is ungrouped, we will simply rank the 25 cases and pick the middle case. However, we cannot do this for grouped data. In this case we should locate the interval that contains the middle case. Since N is 25, the middle case is N/2 = 12.5. Thus we are looking for the interval that contains twelfth and thirteenth cases. If we look at our cumulative frequencies, we will notice that the interval containing 6 the twelfth and the thirteenth cases is 39.5-49.5. This is our median interval. The l be the lower of this interval. Using our formula we will have mdn will 39.5+ 25/2-10 x 10 9 = 39.5+ 12.5-10 x10 9 = 39.5+ 2.5 x 10 9 = 39.5+2.8 = 42.3 Our median for this grouped data is 42.3 marks. iii. The Mean the Arithmetic Mean (AM) and often referred as the average, is the commonest measure of central tendency. The mean is calculated for continuous distributions and interval variables. The mean is arrived at by adding all the numbers of observations and dividing by total number of cases. The A M is obtained for data not in frequency table, which is simply the average of a given number of data The mean is obtained using the following formula = ∑X N Where ∑ = Summation X = observation N = Number of case The formula requires us to add all the observations from the first case to the last and then divide by the number of cases. In order to illustrate the computation of the mean, apply the formula to the data of the thirty students presented below: A.M = (15+ 15+ 17+ 17+ 18+ 18+ 19+ 20+ 20+ 21+ 22+ 22+ 23+ 23+ 23+ 24+ 24+ 27+ 28+ 29+ 29+ 30+ 30+ 31+ 32+ 35+ 36+ 36+ 37+ 38)/30 = 759/30 = 25.3 The arithmetic mean age for this distribution is 25.3. For data in a frequency distribution the mean is calculated using the following formula = ∑fx ∑f 7 Where ∑ = summation f = frequency x= observation With grouped data the formula for calculating the mean is different and slightly more complex as presented below: = ∑fi mi ∑fi Where ∑ = Summation f = frequency of interval m = mid point of the interval i i Table 5 Computation of the Mean for Grouped Data Stated Limit True Limit Mi fi 20-29 19.5-29.5 24.5 7 30-39 29.5-39.5 34.5 3 40-49 39.5-49.5 44.5 9 50-59 49.5-59.5 54.5 4 60-69 59.5-69.5 64.5 2 Total 25 fi mi 171.5 103.5 400.5 218.0 129.0 1022.5 Note 1: The mid point is obtained by adding the lower and upper limits (either of stated or true limit) of each interval and dividing the sum by 2. For instance for the first interval in table 5 the mid point will be : 20+29/2 = 49/2 = 24.5 Note 2: The fi mi is obtained by multiplying the mid point by the frequency of the interval for example to obtain the fi mi for the second interval see illustration below: 34.5 x 3 = 103.5 To obtain the we simply divide the sum of fi mi by the sum of fi which is illustrated below = ∑ fi mi = 1022.5/25 = 40.9 ∑ fi 8 3. 3 Measure of Dispersion/Variability Researchers are frequently concerned with the variability of the distribution, that is, whether the measurements are clustered tightly around the mean or spread over the range. Measures of dispersion include range, mean deviation, variance and standard deviation. i. The range is the simplest measure of dispersion or variability. A distribution range is defined as the difference between the largest and the smallest score. The range of age in our earlier example is 15 to 38 years or 38-15 = 23. The range is 23 that is the difference between least age and the highest age in the distribution. ii. Percentile is score below which a specific percentage of the distribution falls. Percentile are used to evaluate relative performance on standardize test such University Matriculation Examination (UME). The nth percentile is a score below which n percent of the distribution falls. For instance, the 75 percentile is a score that divide the distribution so that 75 percent of the cases are below and 25 percent are above it. The median is usually the 50 percentile, which is a score that divide the distribution is such a way that 50 percent (or half) of the cases fall below it. Percentiles are meaningful for data that is at ordinal or higher level of measurement. Percentiles are easy to identify if the data are arranged in a frequency distribution One measure of this variability is the difference between two percentiles, usually the 25 low values and the 75 percentiles (high values). th th th th iii. The Mean Absolute Deviation (MAD): This is simply the sum of the difference between the each of the score and the mean divide by the number of cases. It is important to note that absolute value of the number is the value of x without the negative sign and is written as ( / x /) for instance /-2/ = 2 In summing the differences the signs are ignored the formula is MAD = ∑/X-/ N In order to calculate the MAD we need to obtain the mean. The mean for the data below is = ∑X = 95+61+71+50+90+77+81/7 = 525/7 = 75 N Table 6 Computation of the Mean Absolute Deviation State X X- /X-/ JG 95 20 20 KN 61 -14 14 KT 71 -4 4 KD 50 -25 25 KB 90 15 15 SK 77 2 2 ZM 81 6 6 Total 525 0 86 9 To obtain the MAD (∑/X-/ /N) using the formula is simply to subtract the mean from the X value for instance in case the first entry in Table 6, 95-75 = 20. The sum of /X-/ divide N. MAD = ∑/X-/ = 86/7 = 12.3 N iv. The Variance is the square of the standard deviation. It is a measure of variation for interval-ratio variables and is the average of squired deviations from the mean. For example we may be interested in determining the variation of poverty across the seven states in the northwest zone. To calculate the variance we need to find the mean, calculate the difference of each of the scores to the mean and the squired sum of the difference. The formula for raw date is presented below: Ѕ = ∑(x-) N 2 Whereas ∑= summation sign X= Scores = Mean N= number of observation Table 7 Showing the Poverty Rate in Northwest Zone State X X- (X-) JG 95 20 400 KN 61 -14 196 KT 71 -4 16 KD 50 -25 625 KB 90 15 225 SK 77 2 4 ZM 81 6 36 Total 525 0 1502 Source: Ogwumike (2006) 2 =527/7 =75 The formula for calculating variance for grouped data is presented below: Ѕ = ∑(fi x ) 2 N 10 Table 5 Computation of the Variance for Grouped Data Age category fi mi fi mi x= mi- 15-19 7 17 119 -8 20-24 10 22 220 -3 25-29 4 27 108 2 30-34 4 32 64 7 35-39 5 37 185 12 Total 30 696 The mean for the data is 25.3 approximated to 25 x 64 9 4 49 144 2 /fi xi/ 56 30 8 28 60 182 fi x 448 90 16 196 720 642 2 For grouped data some adjustments have to be made to obtain the variance. The average deviation from the mean becomes ∑/fi x//N. Where fi is interval frequency and Xi= mi - or each interval mid point minus the mean. Thus our variance for the data in Table 5 is: ∑(fi x ) = 642/30 = 21.4 2 N v. The Standard Deviation (SD) is a measure of variability that is more scientific than mean deviation for further investigation and analysis of statistical data. The SD is defined as the square root of the variance. The formula for raw data is presented below ___________ SD= √∑(x-) /N 2 In the previous example the SD; SD = √1502/7 = √214.57 = 14.65 3.4 Skewness The distribution of the data can be described by the shape of the general distribution, which can be visually presented in a curve. A distribution according to Frank-Nachmias and Leon-Guerrero (2000) can either be symmetrical or skewed depending on whether there are a few extreme values at one end of the distribution. A distribution is said to be symmetrical if the frequencies at the right and left tails are identical. In other words, if the distribution is divided into two halves, each will be a mirror image of the other. Example of symmetrical distribution is presented in Table 6. Symmetry or lack of it in a distribution is determined using coefficient of skewness. The coefficient of skewness is defined as: 11 Coefficient of Skewness = mean- mode or SD Or 3(maen – median) SD SD = Standard Deviation Table 6 Hypothetical Income Distribution (Symmetrical) Income (X) Frequency FX 1 N 1,000 N 1,000 ☺ 2 N 4,000 N 2,000 ☺ ☺ 4 N 12,000 N 3,000 ☺ ☺☺☺ 2 N 8,000 N 4,000 ☺ ☺ 1 N 5,000 N 5,000 ☺ Total 10 N 30,000 The mean income for this distribution is = ∑fx/∑f = 30,000/10 = N 3,000. The median is also N 3,000. The distribution clusters around the mean However in a skewed distribution there are few extreme values on one side of the distribution. A distribution with extreme low values is said to be negatively skewed, while a distribution with few extreme high values is referred to as positively skew. In a skewed distribution the mean is pulled in the direction of the extreme values (either extreme low or extreme high scores). Example of skewed distribution is presented in Table7. Table 7 Hypothetical Income Distribution (Positively Skewed) Income (X) Frequency FX 1 N 1,000 N 1,000 ☺ 2 N 4,000 N 2,000 ☺ ☺ 4 N 12,000 N 3,000 ☺ ☺☺☺ 2 N 8,000 N 4,000 ☺ ☺ N 50,000 ☺ Total 1 N 50,000 N 75,000 10 The mean income for this distribution is = ∑fx/∑f = 75,000/10 = N 7,500. The median is N3,000 and the mode is also N3,000. In this distribution the mean is affected by the extreme high value, thus the mean is N6,000 while the median is still N 3,000. The value of the mean is twice the value of the median and the mode in this case. In order to determine the degree of skewness in distribution in table we need to calculate the SD, which is 5.18. To calculate the coefficient of skewness we will the following: Mean = Mode = N 6,000 N 3,000 12 SD = 5.18 Coefficient of Skewness = mean- mode = 6000-3000 = 3000 = 579.2 SD 5.18 5.18 The coefficient of skewness can either be a positive or negative value, which indicates the nature of the skewness. Higher the value of the coefficient indicates the magnitude of the skewness. In our example the value is 579.2, which shows that the data is positively skewed. 4. Summary Conclusion In the chapter some commonly used methods of organizing, summarizing data and finding the centre of ungrouped and grouped data have been treated. The methods include mode, median and mean. Similarly, some measures of dispersion have also been treated such as range, mean average deviation, variance and standard deviation. The distribution helps researchers to summaries, organize and display data. Difference and trends within group can be identified using simple frequency distribution table. The mean in the absence of extreme scores (outliers) is the most recommended. On the other hand, standard deviation is the most scientific measure of dispersion compared to the mean average deviation. Depending on the data the distribution can be symmetrical or skewed. In general, statistics is a useful tool for summarizing, presenting and analysis of data. 13 Exercises 1. Thirty students were asked about their age and the following data were obtained 17, 18, 22, 20, 20, 22, 23, 30, 23, 30, 31, 32, 29, 35, 37, 36, 19, 21, 23, 24, 36, 38, 15, 18, 17, 24, 27, 28, 29 a. Construct frequency table using class interval of 5, taking into account the lower limit of 15. b. Compute the percentage and cumulative percent for each category 2. From the data Table 1 below compute the percentage of those currently married and those ever married Table 1 Marital Status of Respondents Marital Status Frequency Married 710 Single 226 Divorced 35 Separated 06 Widowed 37 Source: Department of Sociology, Bayero University, Kano (2009) 3. From the data in table 2 compute the percentage of those with secondary level of education. 4. Calculate cumulative frequency and percentage. Table 2 Respondents Level of Education Level of Education No Schooling Qur’anic Eduction Adult Literacy Primary Secondary Tertiary Source: Mohammed (2001) 5. Frequency 21 407 71 146 245 269 Using data in table 3 calculate the median age at first married using formula for grouped data 14 Table 3 Age at First Marriage Age at Marriage 15-20 Years 21-25 Years 26-30 Year 31-36 Years Total Source: Mohammed (2001) Frequency 351 429 246 74 1100 6. Using data in table 3 calculate the mean age using formula for grouped data Poverty rate in Southwest of Nigeria Ekiti 42% Ondo 42% Lagos 64% Oyo 24% Osun 32% Ogun 32% Source (Ogwumike, 2006) 7. From the data above what is the range of poverty in southwest of Nigeria 8. From the data above calculate Mean Deviation, Variance and Standard Deviation Table 4 Respondents Desired Total Number of Children Desired Total Number of Children 1-5 6-10 11-15 16-20 21-25 26-30 Source: Mohammed (2001) Frequency 57 53 8 9 6 1 9. Using the data in Table 4 calculate the variance using grouped data formula. 10. Using the data in Table 4 calculate the standard deviation using grouped data formula. 15 References Agretis, A and Franklin, C (2007) Statistics: The Art and Science of Learning From Data. New Jersey: Pearson Prentice Hall Babbie, Earl (2004) The Practice of Social Research (Belmont CA: Wadsworth/Thompson) Centre for Democratic Research and Training (2007) Educating the Electorate: A Survey Report on Voter Education Project and Public Opinion on Nigeria’s 2007 General Election in Northwest Geo-political Zone of Nigeria, Submitted to UNDP, Abuja, Nigeria Department of Sociology, Bayero University, Kano (2009) Strategies For Enhancing Community Security & Conflict Resolution Mechanisms In Katsina State A Report Submitted To Safety And Security Component Manager DfID, 3 Floor, AP Plaza, Adetokunbo Ademola Crescent, Wuse II, Abuja-Nigeria rd Frankfort-Nachmias, C and Leon-Guerrero, A. (2000) Social Statistics for Diverse Society (Thousand Oak CA: Pine Forge Press) Knoke, D. Bohrnstedt, G. W. and Mee, A. P. (2002) Statistics for Social Data Analysis. Belmont: Wadworth and Thompson Marhal, G (1998) Oxford Dictionary of Sociology, Oxford: Oxford University Press Mc Tavish, D and Loether, H, (1999) Social Research. Longman Mohammed, I.Z. (2001) Male Attitudes Toward and Use of Family Techniques in Kano State A PhD Thesis Submitted to the Department of Sociology, Bayero University, Kano. Ogwumike, F (2006) Nigeria Poverty Assessment: Quantitative Aspect. Draft report Submitted to the United Nations Development Programme, Abuja Nachmias, D and Nachmias, C (1987) Research Methods in the Social Sciences (New York: St Martins Press) Trochim, William M K (2001) Research Methods Knowledge Base. Cincinnati, OH : Atomic Dog Publishers., 2001 Sambo, A. A. (2008) Research Methods in Education Lagos: Stirling-Horden Publishers Ltd. 16