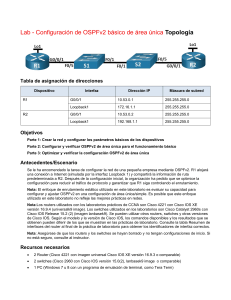
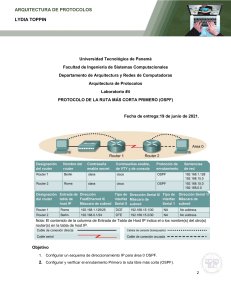
a. Con el esquema de direccionamiento del diagrama, aplique direcciones IP a las interfaces Fast Ethernet en R1, R2 y R3. Cree Loopback1 en R1, Loopback2 en R2 y Loopback3 en R3, y diríjase a ellos de acuerdo con el diagrama. Router 1: Router 2: Router 3: b. Configure las interfaces seriales en R1 y R2 con las direcciones IP que se muestran en el diagrama. Agregue el comando clockrate donde sea necesario. Router 1: Router 2: Paso 2: Adiccionar interfaces físicas a OSPF a. Ingrese el indicador de configuración de OSPF usando el comando router ospf process_number. El número de proceso es un número significativo a nivel local que no afecta el funcionamiento de OSPF. Para esta práctica de laboratorio, utilice el proceso número 1 en todos los enrutadores. b. Agregue interfaces con el comando network address wildcard_mask area area. La dirección es una dirección IP. La máscara es una máscara inversa, similar a la que se usa en una lista de acceso. El área es el área OSPF para poner la interfaz. Para esta práctica de laboratorio, use el área 0, el área de la red troncal, para todas las interfaces. Por ejemplo, el comando network 10.1.200.1 0.0.0.0 area 0 agrega la interfaz con la dirección IP de 10.1.200.1 y su red al proceso OSPF en el área 0. La máscara comodín de 0.0.0.0 significa que los 32 bits del La dirección IP debe coincidir exactamente. Un bit 0 en la máscara comodín significa que parte de la IP de la interfaz debe coincidir con la dirección. Un 1 bit significa que el bit en la interfaz IP no tiene que coincidir con esa parte de la dirección IP. El comando network 10.1.100.0 0.0.0.255 área 0 significa que cualquier interfaz cuya dirección IP coincida con 10.1.100.0 para los primeros 3 octetos coincidirá con el comando y lo agregará al área 0. El último octeto son todos 1, porque en la máscara comodín es 255. Esto significa que una interfaz con una IP de 10.1.100.1, 10.1.100.2 o 10.1.100.250 coincidiría con esta combinación de dirección y comodín y se agregaría a OSPF. En lugar de utilizar máscaras comodín en el comando de red, es posible utilizar máscaras de subred. El enrutador convierte las máscaras de subred al formato comodín automáticamente. Una manera fácil de calcular una máscara comodín de la máscara de subred es restar el valor de octeto para cada octeto de 255. Por ejemplo, una máscara de subred de 255.255.255.252 (/ 30) se convierte en 0.0.0.3 para capturar todas las interfaces en esa subred: 255.255.255.255 −255.255.255.252 = 0 . 0 . 0 . 3 Nota: Otra opción para agregar redes individuales conectadas directamente al proceso OSPF es usar el comando ip ospf process-id area area-id interface que está disponible con Cisco IOS versión 12.3 (11) T y posteriores. c. Ingrese los comandos en R1. Salga al modo EXEC privilegiado y escriba debug ip ospf adj. El comando debug le permite ver a los vecinos OSPF aparecer y ver las relaciones entre vecinos. Evidecias del paso 2: Agregue declaraciones de red a los otros dos enrutadores. Observe la salida de depuración en R1. Cuando haya terminado, desactive la depuración en R1 con el comando undebug all mando. ¿Cuál es la ventaja de agregar redes con una máscara comodín en lugar de usar direcciones de red con clase? La ventaja de usar máscaras comodín para agregar direcciones de red es que estas permiten tener mayor control para determinar cuales interefaces participaran en el proceso de OSPF. Como en OSPF, las interfaces se pueden asignar a diferentes áreas, muchas veces tenemos un enrutador que se encuentra en una red princial, pero diferentes interfaces pertenecen a diferentes áreas. Por lo tanto, se necesita el nivel de control que nos dan las máscaras comodín para asignar las diferentes interfaces a las areas que pertenecen sin restringir la red principal completa para que este en un área. Paso 3: Usar los comandos show(mostrar) de OSPF a. El comando show ip Protocolos muestra información básica del protocolo de enrutamiento de alto nivel. La salida enumera cada proceso OSPF, la ID del enrutador y las redes para las que OSPF está enrutando en cada área. Esta información puede ser útil para depurar operaciones de enrutamiento. b. El comando show ip ospf muestra el ID del proceso OSPF y el ID del enrutador. Observe la ID del enrutador que aparece en la salida. El ID de R1 es 10.1.1.1, aunque no haya agregado este bucle de retorno al proceso OSPF. El enrutador elige la ID del enrutador utilizando la IP más alta en una interfaz de bucle invertido cuando OSPF está configurado. Si se agrega una interfaz de bucle invertido adicional con una dirección IP más alta después de encender OSPF, no se convierte en la ID del enrutador a menos que se vuelva a cargar el enrutador, se elimine la configuración de OSPF y se vuelva a ingresar, o se use el comando de nivel OSPF enrutador-id para modificar el RID manualmente y posteriormente se ingresa el comando clear ip ospf process. Si no hay interfaces de bucle invertido en el enrutador, el enrutador selecciona la dirección IP más alta disponible entre las interfaces que se activan mediante el comando no shutdown. Si no se asignan direcciones IP a las interfaces, el proceso OSPF no se inicia. c. El comando show ip ospf Neighbor muestra el estado de vecino importante, incluido el estado de adyacencia, la dirección, la identificación del enrutador y la interfaz conectada. Si necesita más detalles que los resúmenes estándar de una línea de vecinos, use el comando show ip ospf Neighbor Detail. Sin embargo, generalmente, el comando regular le brinda todo lo que necesita. d. El comando show ip ospf interface interface_type number muestra los temporizadores de interfaz y los tipos de red. e. Una variación del comando anterior es el comando show ip ospf interface brief, que muestra cada interfaz que participa en el proceso OSPF en el enrutador, el área en la que se encuentra, su dirección IP, costo, estado y número de vecinos. f. El comando show ip ospf database muestra las distintas LSA en la base de datos OSPF, organizadas por área y tipo. Paso 4: Adiccionar interfaces loopback a OSPF. a. Los tres enrutadores tienen interfaces de loopback, pero aún no se anuncian en el proceso de enrutamiento. Puede verificar esto con el comando show ip route en los tres routers. b. Para cada enrutador, la única dirección de bucle de retorno que se muestra es la conectada localmente. Agregue los bucles de retorno al proceso de enrutamiento para cada enrutador utilizando el mismo comando de red que se usó anteriormente para agregar las interfaces físicas. c. Verifique que estas redes se hayan agregado a la tabla de enrutamiento mediante el comando show ip route. Ahora puede ver los loopback de los otros enrutadores, pero su máscara de subred es incorrecta, porque el tipo de red predeterminado en las loopback de retorno los anuncia como rutas / 32 (host). Como puede ver en el resultado del comando show ip ospf interface Lo1, el tipo de red OSPF predeterminado para una interfaz loopback es LOOPBACK, lo que hace que OSPF anuncie rutas de host en lugar de máscaras de red reales. Nota: El tipo de red OSPF de LOOPBACK es una extensión propiedad de Cisco que no se puede configurar pero que está presente en las interfaces de loopback de forma predeterminada. En algunas aplicaciones como MPLS, la posible discrepancia entre la máscara de interfaz de bucle invertido real y la dirección / máscara anunciada puede provocar problemas de accesibilidad o funcionalidad, y se debe tener cuidado de usar la máscara / 32 en bucles de retorno o siempre que se utilice una máscara diferente. utilizado, el tipo de red OSPF debe cambiarse a punto a punto. d. Para cambiar este comportamiento predeterminado, use el comando ip ospf network punto a punto en el modo de configuración de interfaz para cada loopback. Una vez que las rutas se propagan, verá las máscaras de subred correctas asociadas con esas interfaces de bucle invertido. e. Utilice el siguiente script Tcl para verificar la conectividad a todas las direcciones en la topología. Step 5: Modificar los costos de los enlaces OSPF Cuando usa el comando show ip route en el R1, verá que la ruta más directa al loopback del R2 es a través de su conexión Ethernet. Junto a esta ruta hay un par con el formato [distancia administrativa / métrica]. La distancia administrativa predeterminada de OSPF en los routers Cisco es 110. La métrica depende del tipo de enlace. OSPF siempre elige la ruta con la métrica más baja, que es la suma de todos los costos del enlace. Puede modificar el costo de un solo enlace mediante el comando de interfaz ip ospf cost cost. Utilice este comando en ambos extremos del enlace. En los siguientes comandos, el costo de enlace de la conexión Fast Ethernet entre los tres enrutadores se cambia a un costo de 50. Observe el cambio en las métricas en la tabla de enrutamiento. Como referencia, aquí hay algunos costos de enlace predeterminados (tomados de Cisco.com): • Enlace en serie de 64 kb / s: 1562 • T1 (enlace en serie de 1,544 Mb / s): 64 • E1 (enlace en serie de 2.048 Mb / s): 48 Manual de laboratorio CCNP ROUTE 119 • Ethernet: 10 • Fast Ethernet: 1 • FDDI: 1 • X25: 5208 • ATM: 1 OSPF usa un ancho de banda de referencia de 100 Mb / s para el cálculo de costos. La fórmula para calcular el costo es el ancho de banda de referencia dividido por el ancho de banda de la interfaz. Por ejemplo, en el caso de Ethernet, el costo es: 100 Mb / s / 10 Mb / s = 10. Los costos de enlace anteriores no incluyen Gigabit Ethernet, que es significativamente más rápido que Fast Ethernet, pero aún tendría un costo de 1 usando el ancho de banda de referencia predeterminado de 100 Mb / s. El cálculo del costo se puede ajustar para tener en cuenta los enlaces de red que son más rápidos que 100 Mb / s utilizando el comando auto-cost reference-bandwidth para cambiar el ancho de banda de referencia. Por ejemplo, para cambiar el ancho de banda de referencia a 1000 Mb / s (Gigabit Ethernet), use los siguientes comandos. Nota: Si se usa el comando ip ospf cost cost en la interfaz, como es el caso aquí, anula este costo formulado. Nota: El ejemplo anterior es solo para referencia y no debe ingresarse en R1 Paso 6: Modificar las prioridades de la interfaz para controlar la elección de DR y BDR. Si usa el comando show ip ospf Neighbor Detail en cualquiera de los enrutadores, verá que para la red Ethernet, R3 es el DR (enrutador designado) y R2 es el BDR (enrutador designado de respaldo). Estas designaciones están determinadas por la prioridad de la interfaz para todos los enrutadores en esa red, que se ve en el resultado del programa. La prioridad predeterminada es 1. Si todas las prioridades son las mismas (lo que ocurre de manera predeterminada), la elección de DR se basa en las ID del enrutador. El enrutador con ID de enrutador más alto se convierte en el DR, y el segundo más alto se convierte en el BDR. Todos los demás enrutadores se convierten en DROTHER. Nota: Si sus enrutadores no tienen este comportamiento exacto, podría deberse al orden en el que aparecieron. A veces, un enrutador no abandona la posición DR a menos que su interfaz se caiga y otro enrutador se haga cargo. Es posible que sus enrutadores no se comporten exactamente como en el ejemplo. Utilice el comando ip ospf priority number interface para cambiar las prioridades de OSPF en R1 y R2 para hacer que R1 sea el DR y R2 el BDR. Después de cambiar la prioridad en ambas interfaces, observe el resultado del comando show ip ospf Neighbor Detail. También puede ver el cambio con el comando show ip ospf Neighbor, pero requiere más interpretación porque genera estados por vecino, en lugar de indicar el DR y BDR en una red de adyacencia de vecinos. Nota: Para hacer que un enrutador asuma el control como DR, use el comando clear ip ospf process en todos los enrutadores después de cambiar las prioridades. Otro método para demostrar el proceso de elección y las prioridades es apagar y reactivar todos los puertos del conmutador simultáneamente. El conmutador se puede configurar con el puerto de árbol de expansión predeterminado y todos los puertos se pueden apagar y reactivar mediante los siguientes comandos. interface range fa0/1 - 24 shutdown no shutdown ¿Cuál es el propósito del DR en OSPF? El DR tiene como función presentar el segmento de acceso multiple generando el LSA de tipo 2 en nombre de ese segmento. Sin el LSA de tipo 2 que se forma por el DR, en un segmento de acceso multiple que tenga una determina cantidad enrutadores x, cada router debería poder generar su propio LSA tipo 1 con x-1 enlaces (entradas), una para cada vecino, para indicar una completo acceso. La base de datos de estado de enlace en cada enrutador tendría un cantidad de n*(n-1) enlaces que son recopilados del LSA tipo 1 que son originados por n enrutadores en ese segmento. Con el LSA tipo 2 que representa el segmento de acceso múltiple, cada uno de los x enrutadores conectados al segmento inserta solo una entrada en sus LSA tipo 1, lo que describe una conexión al segmento de acceso múltiple representado por el LSA de tipo 2 . El DR, además de su propio LSA Tipo 1, generará un LSA Tipo 2 que contiene x entradas, lo que indica una conexión desde el segmento de acceso múltiple a cada enrutador conectado. Esencialmente, el segmento de acceso múltiple se describirá como cada enrutador que tiene un enlace al segmento y el segmento a su vez tiene un enlace a cada enrutador. La base de datos de estado de enlace en cada enrutador ahora contendrá solo x + 1 enlaces que es, para x grandes, significativamente más bajo que el anterior recuento x (x-1). ¿Cuál es el propósito de un BDR en OSPF? EL BDR es un enrutador designado de respaldo y tiene como propósito es asumir el cargo de DR en caso tal que el DR actual se caiga. Cuando el BDR se convierte en RD, se lleva a cabo una nueva elección de BDR para el próximo BDR. Desafío: cambio de topología OSPF, como muchos protocolos de enrutamiento de estado de enlace, es razonablemente rápido cuando se trata de convergencia. Para probar esto, haga que R3 envíe una gran cantidad de pings al loopback de R1. De forma predeterminada, los pings toman la ruta de R3 a R1 a través de Fast Ethernet porque tiene el costo de ruta total más bajo. a. Verifique la ruta de R3 a R1 realizando una ruta de rastreo en R3 al loopback de R1 b. Inicie un ping desde R3 al loopback de R1 con un número de repetición alto usando el comando ping ip repeat number. Mientras se realiza este ping, apague la interfaz R1 Fa0 / 0. ¿Notó que se descartaron algunos paquetes, pero luego los pings comenzaron a regresar nuevamente? Si se notó que se descargaron unos paquetes cuando se apago la interfaz F0/0 del router 1, esto es debido al tiempo que se demoró la ayacencia OSPF en agotar el tiempo de espera, también por la topología de la red en volver a converger. ¿Cómo cree que se compara la convergencia OSPF con otros protocolos de enrutamiento, como RIP? ¿Qué pasa con EIGRP? Es probable que OSPF sea mejor que RIP en esta condición por su tiempo muerto que es mucho más corto. EIGRP funcionaría mejor que OSPF si este ultimo esta en la configuración predeterminada, aunque los intervalos de saludo, y tiempo muerto pueden ajustarse para hacer una comparación más justa.