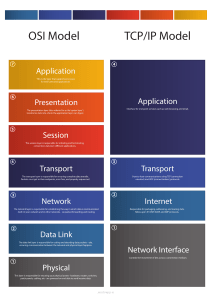
K1 K12 Identifies network failures, setting out the rationale behind the identified task. Q) Define the process of network troubleshooting. Troubleshooting is a form of problem solving, often applied to repair failed products or processes on a machine or a system. It is a logical, systematic search for the source of a problem in order to solve it, and make the product or process operational again. Q) What common troubleshooting commands would you use to diagnose network failures and why? Ipconfig: To check the computer is taking the right IP address. If the IP starts with 169, it is not receiving a valid IP address. Try Ipconfig /release followed by Ipconfig /renew to get rid of your current IP address and request a new one. Ping: Ping cmd Quickly tests the connectivity between network devices by sending the ICMP packets. It will receive the packets when there is connectivity and do not receive the packets in case of connectivity issues. users can quickly identify problems such as high latency, packet loss, and network congestion. Tracert: Use to trace the route the packets are taking. It will show each hop it takes to reach its destination network. Helpful when troubleshooting the network issues. DNS Check: Perform Nslookup to check whether there’s a problem with the server you’re trying to connect to. When troubleshooting network failures, several common commands can help diagnose and identify the underlying issues. These commands provide valuable information about network connectivity, configuration, and performance. Here are some commonly used troubleshooting commands and their purposes: 1. Ping: The ping command is used to test network connectivity between two devices. It sends ICMP Echo Request packets to a specified IP address or hostname and waits for an ICMP Echo Reply. Ping helps determine if a network device is reachable and measures the round-trip time (latency) for packets. 2. Traceroute/Tracert: Traceroute (on Unix-like systems) or Tracert (on Windows systems) is used to trace the route that packets take from the source device to a destination device. It shows the IP addresses of intermediate hops along with their response times. Traceroute helps identify network bottlenecks, high latency points, or routing issues. 3. ipconfig/ifconfig: The ipconfig command (on Windows) or ifconfig command (on Unix-like systems) displays the IP configuration information of network interfaces on a device. It provides details such as IP address, subnet mask, default gateway, and DNS servers. These commands help verify IP settings and ensure proper network configuration. 4. nslookup: The nslookup command (on Windows) or dig command (on Unix-like systems) is used to query DNS (Domain Name System) information. It helps resolve and verify DNS records, such as IP addresses associated with a domain name or reverse DNS lookups. These commands help troubleshoot DNS-related issues, such as name resolution failures. 5. netstat: The netstat command displays network statistics and active network connections on a device. It provides information about open ports, established connections, routing tables, and network interface statistics. Netstat helps identify network services or processes causing issues, check for port conflicts, and view active connections. 6. arp: The arp command (Address Resolution Protocol) displays and manipulates the ARP cache, which maps IP addresses to MAC addresses on a local network. It helps troubleshoot issues related to incorrect or stale ARP entries, such as MAC address conflicts or IP address conflicts. These commands are just a few examples of the many troubleshooting commands available. They provide valuable insights into network connectivity, configuration, and performance, allowing network administrators to identify and resolve common network failures efficiently. It's important to consult the documentation and appropriate resources for the specific operating system or networking equipment being used to fully utilise the available troubleshooting commands. Q) How would a Network Engineer use Ping Utility? By using the ping utility, network administrators and users can quickly identify problems such as high latency, packet loss, and network congestion. The results of the ping test can also be used to determine whether a website or network device is down or experiencing connectivity issues. Q) What types of network diagnosis tools could be used to diagnose network failures? Network diagnosis tools are crucial for identifying and resolving network failures. They provide comprehensive analysis and insights into network performance, connectivity, and configuration. Here are some common types of network diagnosis tools: 1. Network Analyzers: Network analyzers, such as Wireshark, tcpdump, or Microsoft Network Monitor, capture and analyse network traffic at a packet level. They help monitor and troubleshoot network issues by capturing and analysing packets, identifying anomalies, and diagnosing network performance problems. 2. Ping and Traceroute Utilities: Ping and traceroute are built-in diagnostic utilities available on most operating systems. They help verify network connectivity, measure round-trip time (latency), and trace the path packets take from source to destination. 3. 4. 5. 6. 7. 8. These tools are useful for troubleshooting network connectivity issues and identifying routing problems. Network Performance Monitoring (NPM) Tools: NPM tools, such as SolarWinds Network Performance Monitor, PRTG Network Monitor, or Nagios, provide real-time monitoring and performance analysis of network devices and services. They collect data on bandwidth utilization, latency, packet loss, and other performance metrics to identify bottlenecks, network congestion, or service disruptions. SNMP Monitoring Tools: Simple Network Management Protocol (SNMP) monitoring tools, like Cacti, Zabbix, or PRTG Network Monitor, monitor network devices and gather information about their status, performance, and configuration. These tools help identify and troubleshoot issues related to network devices, such as routers, switches, and servers. Network Configuration Management Tools: Network configuration management tools, such as SolarWinds Network Configuration Manager or Cisco Prime Infrastructure, help monitor and manage network device configurations. They track changes, ensure compliance with network standards, and provide backup and restore capabilities. These tools assist in diagnosing configuration-related issues and ensuring consistent network configurations. IP Scanners and Port Scanners: IP scanners, such as Angry IP Scanner, and port scanners, like Nmap, are used to discover and analyze active hosts and open ports on a network. They help identify network devices, detect unauthorized devices or open ports, and assess network security vulnerabilities. Network Traffic Analysis Tools: Network traffic analysis tools, such as NetFlow Analyzer, ntop, or Splunk, collect and analyze flow data, log files, and other network traffic information. They help monitor network usage, identify bandwidth hogs, analyze application traffic patterns, and detect security threats. Diagnostic Command-Line Tools: Command-line tools, such as ipconfig/ifconfig, nslookup/dig, netstat, arp, and others, provide basic network diagnosis and troubleshooting capabilities. These tools are available on most operating systems and help diagnose network configuration issues, DNS problems, IP conflicts, and connectivity problems. These tools collectively provide network administrators with the means to monitor, diagnose, and troubleshoot various network failures and performance issues. The specific tools chosen will depend on the organization's requirements, network infrastructure, and the nature of the network failures being addressed. Install and Manage Network Architecture K2 S2 Plans and carries out their installation and configuration activity to show the stages of activity required and explains the choice and use of hardware and or software to manage and maintain a secure network Q) What are the key differences between a Hub, a Switch, and a Router? Hubs, switches, and routers are networking devices used to connect devices within a network, but they differ in terms of their functionality and the way they handle network traffic. Here are the key differences between a hub, a switch, and a router: 1. Hub: ● Operates at the Physical Layer (Layer 1) of the OSI model. Acts as a central connection point for network devices, allowing them to communicate with each other. ● Broadcasts incoming data packets to all connected devices on the network. ● Does not perform any packet filtering or addressing. ● Provides no intelligence or management capabilities. ● Prone to collisions and performance degradation in high-traffic environments. ● Rarely used in modern networks as switches have replaced their functionality. 2. Switch: ● Operates at the Data Link Layer (Layer 2) of the OSI model. ● Provides multiple ports to connect network devices. ● Learns and stores the MAC addresses of connected devices in its MAC address table. ● Uses the MAC addresses to forward data packets only to the intended destination device, improving network efficiency. ● Provides full-duplex communication, allowing simultaneous transmission and reception of data. ● Supports advanced features like VLANs (Virtual Local Area Networks) for network segmentation and enhanced security. ● Offers better performance and scalability compared to hubs. ● Switches can be managed or unmanaged, with managed switches providing additional features like configuration options, monitoring, and troubleshooting capabilities. 3. Router: ● Operates at the Network Layer (Layer 3) of the OSI model. ● Connects multiple networks and forwards data packets between them. ● Uses IP addresses to identify and route packets to their destinations across different networks. ● Performs routing decisions based on routing tables, which store information about network topology and the best paths for forwarding packets. ● Provides network segmentation and supports the creation of subnets. ● Offers network address translation (NAT) for translating private IP addresses to public IP addresses. ● Provides firewall functionality by filtering network traffic based on rules and access control lists (ACLs). ● Enables interconnectivity between different types of networks, such as Ethernet and Wi-Fi or Ethernet and WAN (Wide Area Network) connections. ● In summary, a hub simply broadcasts all incoming traffic to all connected devices, a switch intelligently forwards traffic to the intended recipient based on MAC addresses, and a router routes data packets between different networks based on IP addresses. Switches and routers offer more advanced features and better performance compared to hubs, and they play crucial roles in modern networking infrastructure. Q) What considerations could be made when implementing fault-tolerance into the network architecture? Fault tolerance refers to the ability of a system (computer, network, cloud cluster, etc.) to continue operating without interruption when one or more of its components fail. The objective of creating a fault-tolerant system is to prevent disruptions arising from a single point of failure, ensuring the high availability and business continuity of mission-critical applications or systems. Key Considerations: ● ● ● Downtime – A highly available system has a minimal allowed level of service interruption. For example, a system with “five nines” availability is down for approximately 5 minutes per year. A fault-tolerant system is expected to work continuously with no acceptable service interruption. Scope – High availability builds on a shared set of resources that are used jointly to manage failures and minimize downtime. Fault tolerance relies on power supply backups, as well as hardware or software that can detect failures and instantly switch to redundant components. Cost – A fault tolerant system can be costly, as it requires the continuous operation and maintenance of additional, redundant components. High availability typically comes as part of an overall package through a service provider (e.g., load balancer provider). Q) What are different ways of securing a network? ● Install Anti Virus and Malware protection: Malware protection, including antivirus software, is a key component of network security practices. Antivirus software will check downloaded applications or data that are new to the network to check that there is no malware. Antivirus software needs to be updated to recognize evidence of new cybercrimes. Unexpected malware threats are detected by antivirus software, along with websites and emails attempting to phish an employee. ● ● ● ● ● ● ● ● Apply encryption to the data: End-To-End Encryption (E2EE) ensures that data shared through a network is secure and authorised to workers who can access the data. Get a VPN: A virtual private network encrypts Wi-Fi, internet connections, and data transfers in a company’s network. Most VPNs have a built-in kill switch to disconnect hardware in the network if a protected connection is lost. Use IDS/IPS Use a network firewall: A firewall is a popular way to protect a company’s network. It filters both incoming and outgoing network traffic based on a company’s security policies and rules. Have a control on Ports Be consistent with network monitoring: Whether traffic errors or vulnerabilities, watching the network is the difference between being unaware of cyberattacks and seeing potential attacks before they happen. Keeping the system up to date: Set Up Two-Factor Authentication (2FA): Two-factor authentication is a vital step in network security. 2FA is anything from answering a personal question, sending a code to an employee’s phone or email address, and fingerprints. ● Change the default username and password of your router or access point. Q) What are proxy servers and how do they protect networks? To diagnose network failures and troubleshoot network issues, several network diagnosis tools can be used. These tools provide insights into network performance, identify potential problems, and assist in resolving issues. Here are some commonly used network diagnosis tools: 1. Ping: Ping is a basic network troubleshooting tool that tests connectivity between devices. It sends ICMP Echo Request packets to a target device and measures the response time. Ping can help determine if a device is reachable and assess network latency. 2. Traceroute: Traceroute (or traceroute6 for IPv6) traces the network path taken by packets from a source device to a destination device. It shows the intermediate devices (routers) the packets pass through, helping identify network hops with delays or failures. 3. Network Analyzers: Network analyzers, also known as packet analyzers or sniffers, capture and analyse network traffic at the packet level. They provide detailed information about protocols, packet headers, and payload contents. Network analyzers help diagnose network performance issues, identify abnormal traffic patterns, and troubleshoot protocol-level problems. 4. Wireshark: Wireshark is a popular network analyzer tool that allows capturing and analysing network traffic. It provides a graphical interface to inspect and dissect captured packets, making it useful for troubleshooting network issues, security analysis, and protocol debugging. 5. NetFlow Analyzers: NetFlow analyzers monitor and analyse network traffic flows. They collect and analyse NetFlow data exported by routers and switches, providing insights into traffic patterns, bandwidth utilisation, and identifying potential bottlenecks or anomalies. 6. SNMP Monitoring Tools: Simple Network Management Protocol (SNMP) monitoring tools gather data from network devices that support SNMP. These tools can monitor device performance metrics, interface status, CPU utilisation, and other important parameters. They help detect and diagnose issues related to device health and performance. 7. Cable Testers: Cable testers are hardware tools used to diagnose issues with network cables, such as continuity problems, open circuits, or shorts. They help identify faulty cables or connectors that may cause network connectivity problems. 8. Spectrum Analyzers: Spectrum analyzers analyse the radio frequency spectrum to identify and diagnose issues in wireless networks. They can detect interference sources, signal strength, and channel utilisation, helping troubleshoot Wi-Fi or other wireless network problems. These are just a few examples of network diagnosis tools commonly used by network administrators and engineers. The selection of the appropriate tool depends on the specific nature of the network issue being investigated. A proxy server is a system that acts as a link between users and the internet. It works by facilitating web requests and responses between a user and web server. How? Proxy servers use a different IP address on behalf of the user, concealing the user's real address from web servers. It can help protect networks by preventing cyber attackers from entering a private network or hiding the user’s IP address. Types: ● ● ● ● Forward Proxy Server Reverse Proxy Server Anonymous Proxy Server Protocol Proxy Server HTTPS DNS DHCP FTP SMTP URL: https://www.upguard.com/blog/proxy-server Proxy servers are intermediary servers that sit between client devices and the internet. They act as a gateway between clients and the websites or services they want to access. When a client makes a request to access a website, the request is first sent to the proxy server, which then forwards the request on behalf of the client to the destination server. The response from the destination server is then relayed back to the client through the proxy server. Proxy servers can provide several benefits for network protection: 1. Anonymity and Privacy: By acting as an intermediary, proxy servers can hide the client's IP address and identity from the destination server. This provides a certain level of anonymity and privacy for the client, as the destination server only sees the IP address of the proxy server. 2. Content Filtering and Access Control: Proxy servers can implement content filtering mechanisms to block or allow access to specific websites or types of content. This helps organizations enforce internet usage policies, restrict access to inappropriate or malicious websites, and prevent employees from accessing unauthorized resources. 3. Caching: Proxy servers can cache frequently accessed web content. When a client requests a web page or resource that has been previously accessed and cached by the proxy server, the server can deliver the cached content instead of retrieving it from the internet. This reduces bandwidth usage, improves response times, and relieves the load on the network and destination servers. 4. Load Balancing: Proxy servers can distribute incoming client requests across multiple servers to balance the load and ensure optimal resource utilisation. This helps prevent server overload and improves overall network performance. 5. Security and Filtering: Proxy servers can act as a buffer between clients and the internet, inspecting and filtering incoming and outgoing network traffic. They can provide protection against malicious content, block suspicious websites, and detect and prevent certain types of attacks, such as Distributed Denial of Service (DDoS) attacks or intrusion attempts. 6. Bandwidth Management: Proxy servers can monitor and control bandwidth usage by implementing traffic shaping and prioritization policies. This allows organizations to allocate bandwidth resources effectively, prioritize critical applications or users, and manage network congestion. By serving as an intermediary and implementing various security and control mechanisms, proxy servers help protect networks by enhancing privacy, filtering unwanted content, improving performance, and enforcing security policies. They are commonly used in corporate environments, educational institutions, and other settings where network protection and control are essential. Improving Network Performance K3 Identifies network performance issues within specified parameters URL: https://obkio.com/blog/how-to-measure-network-performance-metrics/#what-is-network-monito ring Q) How would you describe network performance? Network performance is the analysis and review of collective network statistics, to define the quality of services offered by the underlying computer network. More simply, network performance refers to the analysis and review of network performance as seen by end-users. Q) How do you monitor/measure network performance? Monitor: Using Network monitoring tools. It can monitor various network metrics, such as bandwidth utilisation, packet loss, latency, and other key performance indicators (KPIs). These tools can also generate alerts when network issues are detected, allowing network administrators to take prompt action to resolve the issue before it becomes a more significant problem. Network monitoring can be done using different types of tools, including software-based solutions that run on a network device or a server, hardware-based monitoring appliances, and cloud-based monitoring services. These tools provide network administrators with a comprehensive view of network performance and help them to identify and address potential issues proactively. Overall, network monitoring is a critical function in maintaining a healthy and efficient computer network, and it plays a vital role in ensuring that network users have access to reliable and high-quality network services. Measure: ● ● ● Deploy a Performance Network Monitoring Software Measure Network metrics Q) What is a network performance baseline? A network performance baseline is a set of metrics used in network performance monitoring to define the normal working conditions of an enterprise network infrastructure. We can use it to catch changes in traffic that could indicate a problem. Importance: ● Knowing how your network typically performs ● Comparing real-time and historic network data ● Finding small changes in network performance ● Continuously updating performance baselines as a network grows Q) What is QoS? Quality of service (QoS) is the use of mechanisms or technologies that work on a network to control traffic and ensure the performance of critical applications with limited network capacity. It enables organisations to adjust their overall network traffic by prioritising specific high-performance applications. It is typically used in video gaming, online streaming, video conferencing and Voice over IP (VoIP). How: QoS networking technology works by marking packets to identify service types, then configuring routers to create separate virtual queues for each application, based on their priority. As a result, bandwidth is reserved for critical applications or websites that have been assigned priority access. QoS technologies provide capacity and handling allocation to specific flows in network traffic. This enables the network administrator to assign the order in which packets are handled and provide the appropriate amount of bandwidth to each application or traffic flow. ● ● ● ● Bandwidth Delay Loss Jitter K4 Demonstrates a working solution to resolve performance issues showing a response in real-time Q) What are the key network metrics that need to be considered? When troubleshooting network performance issues, several key network metrics should be considered to identify and resolve the problems. These metrics help provide insights into different aspects of network performance. Here are some important network metrics to consider: 1. Latency: Latency refers to the time it takes for data packets to travel from the source to the destination. High latency can cause delays in data transmission and result in slow network performance. Monitoring latency helps identify network congestion, connectivity issues, or delays in data processing. 2. Packet Loss: Packet loss occurs when data packets do not reach their intended destination. It can be caused by network congestion, hardware issues, or improper network configurations. High packet loss rates can lead to degraded performance and impact data integrity and application responsiveness. 3. Bandwidth Utilization: Bandwidth utilization measures the percentage of available network capacity being used. Monitoring bandwidth utilization helps identify if network resources are being overloaded, causing performance bottlenecks. It can also indicate whether sufficient bandwidth is allocated to critical applications or services. 4. Throughput: Throughput measures the amount of data transmitted over a network within a given timeframe. It reflects the network's capacity to handle data transfer efficiently. Monitoring throughput helps identify if the network is reaching its maximum capacity, affecting overall performance. 5. Error Rates: Error rates indicate the number of data packets that encounter errors during transmission. High error rates can be caused by network issues, faulty hardware, or configuration problems. Monitoring error rates helps identify potential sources of network performance degradation. 6. Jitter: Jitter refers to the variation in packet delay. It can cause inconsistencies in data transmission and affect real-time applications, such as voice or video communication. Monitoring jitter helps identify fluctuations in network performance that may impact the quality of these applications. 7. Response Time: Response time measures the time taken for a request to be sent from a source to a destination and for a response to be received. Monitoring response time helps assess the overall responsiveness of applications and services. High response times may indicate performance issues that need to be addressed. 8. Network Availability: Network availability measures the percentage of time a network is operational and accessible to users. Monitoring network availability helps identify periods of downtime or interruptions in service. It is crucial for maintaining consistent network performance and ensuring uninterrupted access to critical services. Q) Identify and define a key network monitoring protocol. SNMP (Simple Network Management Protocol) is a key network monitoring protocol widely used for monitoring and managing network devices. It is an application-layer protocol that allows network administrators to collect and organise information about network devices, monitor their performance, and manage their configurations remotely. Here's a brief definition and overview of SNMP: Definition: SNMP is an industry-standard protocol used for network management and monitoring. It facilitates the exchange of management information between network devices and a central management system, known as the Network Management System (NMS). Key Components of SNMP: 1. Managed Devices: These are network devices, such as routers, switches, servers, printers, or network interfaces, that are SNMP-enabled. Managed devices have SNMP agents running on them to provide information to the NMS. 2. SNMP Agents: SNMP agents are software modules running on managed devices. They collect and store information about the device's performance, status, and configuration. SNMP agents respond to requests from the NMS and send periodic updates, known as SNMP traps, to notify the NMS about specific events or conditions. 3. Network Management System (NMS): The NMS is the central monitoring and management platform responsible for collecting and processing SNMP data. 4. It provides a graphical user interface (GUI) or command-line interface (CLI) for administrators to view and analyse the network information gathered by SNMP agents. The NMS can send SNMP queries to request specific information from SNMP agents and receive SNMP traps for proactive monitoring. 5. Management Information Base (MIB): MIB is a hierarchical database that defines the structure and organisation of managed objects in a network. It contains a collection of SNMP variables that represent various aspects of network devices, such as performance statistics, configuration settings, and error counters. MIBs are used by SNMP agents to provide information to the NMS. SNMP Operations: SNMP operates using a client-server model. The NMS acts as the SNMP manager, while the managed devices function as SNMP agents. The following are the primary SNMP operations: 1. Get: The NMS sends a GET request to an SNMP agent to retrieve the value of a specific SNMP variable from the device's MIB. 2. Set: The NMS can send a SET request to an SNMP agent to modify the value of a specific SNMP variable in the device's MIB, allowing remote configuration of network devices. 3. Trap: SNMP agents send SNMP traps to the NMS when predefined events or conditions occur, such as interface status changes, device reboots, or critical errors. Traps are used for proactive monitoring and alerting. Benefits of SNMP: ● Centralised monitoring and management of network devices from a single location. ● Real-time visibility into network performance, availability, and resource utilisation. ● Proactive monitoring and alerting through SNMP traps. ● Simplified network troubleshooting and fault management. ● Efficient utilisation of network resources through performance optimization and capacity planning. ● Interoperability with a wide range of network devices from different vendors. SNMP is an integral protocol for network monitoring and plays a crucial role in maintaining network performance, identifying issues, and ensuring efficient network management. Q) How do you know if your solution has taken effect and is working successfully? To determine if your solution has taken effect and is working successfully during network performance issues, you can follow these steps: 1. Monitor Performance Metrics: Continuously monitor the relevant network performance metrics after implementing the solution. Compare the metrics before and after the solution implementation to identify any improvements or changes. 2. Analyze Trend and Patterns: Look for trends and patterns in the performance metrics over time. If the solution is effective, you should observe a positive change in the metrics, such as reduced latency, lower packet loss, increased throughput, or improved response times. 3. User Feedback: Gather feedback from end-users or stakeholders who are directly impacted by the network performance issues. Assess whether they have noticed any improvements or if they are experiencing smoother operations, faster response times, or fewer disruptions. 4. Test Scenarios: Conduct targeted tests or simulations to evaluate the impact of the solution on specific scenarios or use cases. For example, if the performance issue was related to a particular application, test its performance after implementing the solution to verify if the issue is resolved. 5. Comparative Analysis: Compare the current performance with the baseline or expected performance levels. If the current performance aligns with the desired or expected benchmarks, it indicates that the solution is effective. 6. Incident and Ticket Logs: Review incident and ticket logs to determine if there has been a reduction in reported performance-related incidents or requests for support. A decrease in the number of incidents suggests that the solution is addressing the underlying performance issues. 7. Network Monitoring Alerts: Monitor network monitoring tools and alerting systems to ensure that they are not generating alerts related to the previously identified performance issues. If the alerts decrease or cease altogether, it indicates that the solution has effectively resolved the issues. 8. Feedback from IT Team: Seek feedback from the IT team members responsible for managing and maintaining the network infrastructure. Q) What are the hardware requirements to deploy a performance monitoring solution? The hardware requirements for deploying a performance monitoring solution can vary depending on the specific solution, scale of the network, and the desired level of monitoring granularity. Here are some general hardware requirements to consider: 1. Server or Host Machine: You will need a dedicated server or host machine to run the performance monitoring software or platform. The server should have sufficient processing power, memory, and storage capacity to handle the monitoring workload. 2. Network Monitoring Tools: Depending on the complexity of your network and the depth of monitoring required, you may need specialised hardware devices such as network probes or traffic analyzers. These devices capture network traffic data for analysis and monitoring purposes. 3. Network Interfaces or Network TAPs: To capture network traffic, you may need additional network interfaces or Network Test Access Points (TAPs) that can tap into network links and mirror or forward traffic to the monitoring devices. 4. Storage Solution: Consider the storage requirements for storing the monitoring data. Depending on the volume and retention period of the data, you may need a dedicated storage solution such as a Network Attached Storage (NAS) or Storage Area Network (SAN). 5. Redundancy and High Availability: For critical monitoring environments, redundancy and high availability may be necessary to ensure continuous K5 Uses organizational procedures to deal with recording information effectively and in line with protocols Q) What are the key organisational procedures that must be considered when recording information. When recording information in an organisation, there are several key organisational procedures that should be considered to ensure accuracy, confidentiality, and accessibility of the recorded information. Here are some important procedures to keep in mind: 1. Data Classification: Determine the sensitivity and importance of the information being recorded and classify it accordingly. This classification helps in establishing appropriate handling procedures, access controls, and retention policies. 2. Data Entry Standards: Define clear guidelines and standards for data entry to ensure consistency and accuracy. This includes specifying the format, structure, and required fields for recording information. 3. Quality Assurance: Implement processes to review and verify the accuracy and completeness of recorded information. This can involve regular audits, checks, and validation procedures to identify and rectify any errors or inconsistencies. 4. Security and Access Control: Establish measures to protect the recorded information from unauthorised access, modification, or disclosure. This may include password protection, encryption, user authentication, and role-based access controls. 5. Version Control: Maintain a system to track and manage different versions of recorded information, especially when multiple updates or revisions are made. This helps ensure the integrity of the data and allows for proper tracking and auditing. 6. Retention and Disposal: Establish policies and procedures for the retention and disposal of recorded information. This ensures compliance with legal and regulatory requirements while also minimising data storage costs and risks associated with unnecessary data retention. 7. Backup and Disaster Recovery: Implement regular data backup procedures to protect against data loss or system failures. Additionally, develop and test disaster recovery plans to ensure the continuity of recorded information in the event of a catastrophic event. 8. Documentation and Metadata: Maintain accurate and up-to-date documentation about the recorded information, including relevant metadata such as creation date, author, source, and context. This helps in understanding and interpreting the information effectively. 9. Privacy and Data Protection: Ensure compliance with applicable privacy laws and regulations when recording personal or sensitive information. Obtain necessary consents, handle data securely, and provide individuals with rights regarding their personal data. 10. Training and Awareness: Provide training and awareness programs to employees involved in recording information. This helps ensure that they understand the procedures, responsibilities, and best practices for recording information accurately and securely. Q) How can protocols influence recording technical information Protocols play a crucial role in recording technical information during network monitoring and performance analysis. Here's how protocols can influence the recording of technical information: 1. Data Format: Protocols define the structure and format of the data exchanged between network devices. They specify how information is packaged, organised, and transmitted. By adhering to a specific protocol, monitoring tools can interpret and record data accurately. For example, protocols like SNMP, NetFlow, or sFlow provide standardised formats for capturing and recording network performance data. 2. Data Collection: Monitoring protocols enable the collection of technical information from network devices. For instance, SNMP allows monitoring tools to retrieve information such as device status, interface statistics, and performance metrics from SNMP-enabled devices. Similarly, flow-based protocols like NetFlow or IPFIX capture network flow data, providing insights into traffic patterns, source-destination relationships, and application-level details. 3. Real-Time Monitoring: Protocols that support real-time streaming of data, such as streaming telemetry protocols (e.g., gRPC, OpenConfig, or NETCONF), enable continuous monitoring and recording of technical information. These protocols allow network devices to send updates or notifications in real-time, facilitating immediate data recording and analysis. 4. Metadata and Headers: Protocols often include metadata or headers that provide additional contextual information about the recorded data. These metadata elements can include timestamps, source and destination IP addresses, port numbers, protocol identifiers, packet sequence numbers, and other relevant details. Monitoring tools leverage this information for accurate data analysis and correlation. 5. Compatibility and Interoperability: Standardised protocols ensure compatibility and interoperability between different network devices and monitoring tools. By adhering to common protocols, monitoring solutions can collect technical information from a wide range of devices, regardless of the vendor or platform. This allows for a comprehensive and unified view of the network. 6. Security Considerations: Protocols may incorporate security features that influence the recording of technical information. For example, encrypted protocols like HTTPS or SSH provide secure communication channels for transmitting sensitive data. Monitoring tools must be capable of decrypting and recording the relevant information while maintaining the necessary security measures. 7. Protocol-Specific Analysis: Different protocols offer unique insights into network performance and behaviour. For instance, protocols like ICMP (Internet Control Message Protocol) can be used to measure network latency and packet loss, while protocols like DNS (Domain Name System) can provide information about domain resolution times. By recording and analysing protocol-specific information, network administrators can diagnose and troubleshoot performance issues effectively. K6 Service Level Agreements (SLAs) and their application to delivering network engineering activities in line with contractual obligations and customer service Service Level Agreements (SLAs) are contractual agreements between a service provider and its customers that define the level of service expected and the performance metrics that will be measured. When it comes to delivering network engineering activities, SLAs play a crucial role in ensuring that contractual obligations and customer service expectations are met. Here's how SLAs are applied in this context: 1. Performance Metrics: SLAs for network engineering activities outline specific performance metrics that must be met. These metrics can include network uptime, response time for issue resolution, bandwidth availability, and network latency. The SLA sets the expectations for these metrics and holds the service provider accountable for meeting them. 2. Availability and Reliability: SLAs define the expected availability and reliability of the network services provided. This includes specifying the minimum acceptable uptime percentage and the response time for addressing any network failures or disruptions. The SLA ensures that the service provider maintains a reliable network infrastructure and promptly resolves any issues that may arise. 3. Response and Resolution Times: SLAs typically include response and resolution time targets for network engineering activities. For example, the SLA may specify that the service provider must acknowledge a reported network issue within a certain timeframe (e.g., 1 hour) and resolve it within another defined timeframe (e.g., 4 hours). These targets ensure timely response and efficient problem resolution. 4. Service Credits and Penalties: SLAs often include provisions for service credits or penalties in case the service provider fails to meet the agreed-upon performance metrics. Service credits can be monetary or in the form of extended service periods provided to the customer as compensation for service level breaches. Conversely, penalties can be imposed on the service provider if they consistently fail to meet the SLA requirements. 5. Reporting and Monitoring: SLAs establish reporting and monitoring mechanisms to track the performance of network engineering activities. This includes regular reporting of performance metrics, service level achievements, and any incidents or outages. The SLA ensures transparency and accountability by providing customers with visibility into the service provider's performance. 6. Escalation Procedures: SLAs may outline escalation procedures to be followed in case of unresolved issues or disputes. This ensures that there is a clear process for addressing any problems that arise during the delivery of network engineering activities and that appropriate actions are taken to resolve them promptly. 7. Continuous Improvement: SLAs can also include provisions for continuous improvement, where the service provider commits to ongoing enhancements and optimizations of the network infrastructure and services. This ensures that the network engineering activities evolve over time to meet changing customer needs and technological advancements. K7 Their role in Business Continuity and Disaster Recovery Business Continuity (BC) and Disaster Recovery (DR) are two closely related concepts that aim to ensure the resilience and continuity of business operations in the face of disruptive events. While they are related, they have distinct focuses: Business Continuity (BC): 1. Business Continuity refers to the processes, strategies, and plans an organisation puts in place to ensure it can continue operating during and after a disruptive event. The primary goal of BC is to minimise downtime, maintain essential business functions, and provide uninterrupted services to customers. BC encompasses a broad range of activities, including: ● Risk assessment and business impact analysis: Identifying potential risks and assessing their potential impact on critical business functions. ● Business continuity planning: Developing plans and procedures to address identified risks and ensure the continuity of essential operations. ● Redundancy and backup systems: Implementing backup systems, redundant infrastructure, and alternate work arrangements to ensure continuous availability of critical resources. ● Data backup and recovery: Establishing data backup strategies and recovery mechanisms to protect critical data and facilitate its restoration in the event of a disaster. ● Testing and training: Regularly testing business continuity plans and conducting training exercises to ensure preparedness and identify areas for improvement. ● Crisis communication: Establishing communication protocols to keep stakeholders, employees, and customers informed during a disruptive event. ● Continuous improvement: Regularly reviewing and updating business continuity plans to incorporate lessons learned and evolving risks. Disaster Recovery (DR): 2. Disaster Recovery focuses specifically on the technology and IT infrastructure aspects of business continuity. It involves the processes and procedures to restore and recover IT systems, data, and technology infrastructure following a disruption. Key elements of DR include: ● Data backup and replication: Regularly backing up critical data and replicating it to offsite or remote locations for redundancy and data protection. ● Recovery Point Objective (RPO) and Recovery Time Objective (RTO): Establishing targets for the maximum acceptable data loss (RPO) and the time required to restore systems (RTO) after a disruption. ● Backup and recovery systems: Implementing backup solutions, data storage devices, and recovery mechanisms to facilitate the restoration of systems and data. ● Infrastructure redundancy: Deploying redundant hardware, failover systems, and alternative connectivity options to ensure the availability of critical infrastructure. ● System and application recovery: Developing recovery plans and procedures for restoring systems, applications, and databases to their normal operating state. ● Testing and validation: Regularly testing and validating the DR plans, including mock disaster scenarios, to ensure the effectiveness of recovery procedures and identify any gaps or shortcomings. ● Documentation and maintenance: Documenting DR procedures and maintaining up-to-date inventories of hardware, software, and infrastructure components. While BC focuses on maintaining overall business operations, DR specifically addresses the recovery of IT systems and data to minimise downtime and ensure timely restoration of critical technology infrastructure. Both BC and DR are crucial for organisations to ensure the resilience and continuity of their operations. They involve comprehensive planning, risk assessment, redundancy measures, and testing to mitigate the impact of disruptions and facilitate timely recovery. Implementing effective BC and DR strategies helps organisations minimise financial losses, maintain customer trust, and continue providing services even during challenging circumstances. Define Network Tasks K8 Explains the purposes and uses of ports and protocols in Network Engineering activities Q) Identify common ports and explain their functionality Ports are endpoints within a computer network that allow for communication between different applications or services. Each port is assigned a unique number, known as a port number, to facilitate the identification and routing of data packets. Here are some common ports and their functionalities: 1. Port 80 (HTTP): This port is used for Hypertext Transfer Protocol (HTTP) communication. It is the default port for web browsing and allows for the transfer of web pages, images, and other resources between web servers and clients. 2. Port 443 (HTTPS): This port is used for secure HTTP (HTTPS) communication. It encrypts the data exchanged between web servers and clients using Secure Sockets Layer (SSL) or Transport Layer Security (TLS) protocols. It is commonly used for secure online transactions, login pages, and sensitive data transfers. 3. Port 25 (SMTP): Simple Mail Transfer Protocol (SMTP) uses port 25 to send outgoing mail from email clients or servers to the destination mail servers. It is responsible for the reliable transmission of email messages over the internet. 4. Port 110 (POP3): Post Office Protocol version 3 (POP3) uses port 110 for retrieving emails from a remote mail server. Email clients connect to the mail server through this port to download messages and manage the mailbox. 5. Port 143 (IMAP): Internet Message Access Protocol (IMAP) uses port 143 for accessing and managing email messages on a remote mail server. It allows users to view, organise, and synchronise their email across multiple devices while keeping the messages stored on the server. 6. Port 22 (SSH): Secure Shell (SSH) uses port 22 for secure remote administration and secure file transfer. It provides encrypted communication channels for accessing and managing remote servers and devices. 7. Port 21 (FTP): File Transfer Protocol (FTP) uses port 21 for transferring files between a client and a server over a network. It allows users to upload, download, and manage files on a remote server. 8. Port 53 (DNS): Domain Name System (DNS) uses port 53 for resolving domain names into IP addresses and vice versa. It translates human-readable domain names (e.g., example.com) into the numerical IP addresses used by computers to locate resources on the internet. 9. Port 443 (TLS/SSL): This port is commonly used for secure connections using TLS/SSL protocols, such as HTTPS, SMTPS (secure SMTP), and FTPS (secure FTP). It provides encryption and authentication for various applications. 10. Port 3389 (RDP): Remote Desktop Protocol (RDP) uses port 3389 for remote desktop connections to Windows-based systems. It allows users to access and control a remote computer or server over a network. Q) What are the key differences between TCP and UDP? TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are two transport layer protocols that provide different approaches to data transmission. Here are the key differences between TCP and UDP: 1. Connection-Oriented vs. Connectionless: TCP is a connection-oriented protocol, which means it establishes a reliable, virtual connection between the sender and receiver before data transmission. UDP, on the other hand, is connectionless and does not establish a dedicated connection before sending data. 2. Reliability: TCP provides reliable data delivery. It ensures that data is transmitted in the correct order and without loss or duplication. TCP uses acknowledgments, sequence numbers, and retransmission mechanisms to guarantee reliable data transfer. UDP, on the other hand, does not guarantee reliability. It does not perform error checking, retransmissions, or packet ordering, making it faster but less reliable than TCP. 3. Ordering: TCP guarantees in-order delivery of data packets. It ensures that packets are received and assembled in the same order as they were sent. UDP does not enforce packet ordering, and packets may arrive out of order or get dropped if the network is congested. 4. Flow Control: TCP performs flow control to regulate the amount of data transmitted between sender and receiver. It uses a sliding window mechanism to manage the flow of packets and prevent overwhelming the receiver. UDP does not have built-in flow control mechanisms, so it can potentially overwhelm the receiver with a large volume of data. 5. Error Checking: TCP performs extensive error checking by using checksums to verify the integrity of data packets. If errors are detected, TCP requests retransmission of the corrupted packets. UDP includes a simple checksum mechanism for error detection, but it does not request retransmission of corrupted packets. 6. Overhead: TCP has higher overhead compared to UDP due to its reliability mechanisms, connection establishment, and flow control mechanisms. This additional overhead contributes to increased latency and slower transmission speeds. UDP has lower overhead Q) Describe the purpose and operation of ports in Network engineering. In network engineering, ports serve as endpoints for communication within a computer network. They enable different applications and services to send and receive data packets across the network. Ports are identified by unique numbers, called port numbers, which allow for the proper routing of data to the intended application or service. Here is an overview of the purpose and operation of ports in network engineering: 1. Endpoint Identification: Ports provide a way to identify specific applications or services running on devices within a network. Each application or service listens on a specific port number, allowing network devices to direct incoming data packets to the appropriate destination. 2. Protocol Differentiation: Ports are used to differentiate between different network protocols and their associated services. Each protocol typically uses a specific port number to ensure that data is correctly routed and processed by the intended protocol handler. For example, port 80 is associated with the HTTP protocol used for web browsing, while port 25 is used for SMTP protocol handling email communication. 3. Communication Channels: Ports enable multiple simultaneous communication channels on a single device. By assigning different port numbers to different applications or services, devices can handle multiple network connections concurrently. This allows for parallel communication between different applications or services running on the same device. 4. Incoming and Outgoing Traffic: Ports distinguish between incoming and outgoing network traffic. For instance, a web server listens on port 80 to receive incoming HTTP requests from clients, while a client device uses an ephemeral port for outgoing connections to remote servers. Ephemeral ports are dynamically assigned by the operating system for temporary use during the communication session. 5. Port Numbers: Port numbers are 16-bit unsigned integers, ranging from 0 to 65535. They are divided into three ranges: well-known ports (0-1023), registered ports (1024-49151), and dynamic or private ports (49152-65535). Well-known ports are reserved for specific protocols and services, while registered ports are assigned by the Internet Assigned Numbers Authority (IANA) for specific applications. Dynamic or private ports are used for temporary connections and are not specifically assigned to any application or service. 6. Port Forwarding: In network engineering, port forwarding allows incoming traffic on a specific port to be redirected to a different device or port within a local network. This enables services running on devices behind a router or firewall to be accessible from the outside network. 7. Security and Access Control: Ports play a crucial role in network security and access control. Firewalls and network security devices can monitor and control network traffic based on the source or destination port numbers. This allows administrators to define rules and policies to permit or block specific types of traffic based on port numbers. Q) Describe the purpose and operation of protocols in Network engineering. In network engineering, protocols play a critical role in facilitating communication and data transfer between devices within a computer network. A protocol defines a set of rules, standards, and procedures that govern the format, sequencing, timing, and error control of data exchanged between network devices. Here is an overview of the purpose and operation of protocols in network engineering: 1. Communication Standardisation: Protocols provide a standardised framework for devices to communicate and exchange information. They ensure that devices from different manufacturers and running different software can interoperate and understand each other's data. 2. Data Formatting and Structure: Protocols define the format and structure of data exchanged between devices. They specify the organisation and representation of data, including headers, payloads, and control information. This ensures consistency and compatibility in data transmission. 3. Addressing and Identification: Protocols provide mechanisms for addressing and identifying devices within a network. They define unique identifiers, such as IP addresses and MAC addresses, that allow devices to locate and communicate with each other. 4. Data Routing and Forwarding: Protocols determine how data is routed and forwarded within a network. They establish rules and algorithms for determining the best path for data transmission from the source device to the destination device. Routing protocols, such as OSPF (Open Shortest Path First) and BGP (Border Gateway Protocol), play a crucial role in managing network traffic and ensuring efficient data delivery. 5. Error Detection and Correction: Protocols incorporate error detection and correction mechanisms to ensure data integrity. They employ techniques such as checksums, cyclic redundancy checks (CRC), and acknowledgment mechanisms to detect and recover from transmission errors. 6. Flow Control and Congestion Management: Protocols include mechanisms for managing the flow of data and preventing network congestion. They regulate the rate of data transmission between devices to ensure that the receiving device can handle the incoming data and prevent data loss or network congestion. K9 Describes features and factors that play a role in deployment of devices, applications, protocols and services at their appropriate OSI and/or TCP/IP layers. Q) Explain the different layers of the OSI model. The OSI (Open Systems Interconnection) model is a conceptual framework that standardises the functions of a communication system into seven distinct layers. Each layer has a specific role and interacts with the layers above and below it. Here's a brief explanation of the different layers of the OSI model: Physical Layer: 1. The Physical Layer is the lowest layer of the OSI model. It deals with the transmission and reception of raw data bits over physical media, such as copper wires, fibre optic cables, or wireless signals. It defines electrical, mechanical, and procedural specifications for establishing and maintaining physical connections. Data Link Layer: 2. The Data Link Layer provides reliable and error-free transmission of data frames between adjacent network nodes over a shared physical medium. It performs tasks like framing, error detection, flow control, and media access control. Ethernet switches operate at this layer. Network Layer: 3. The Network Layer is responsible for establishing logical connections between different networks. It deals with routing, addressing, and forwarding of data packets across multiple network nodes. Routers operate at this layer and make decisions about the optimal path for data transmission. Transport Layer: 4. The Transport Layer ensures reliable end-to-end delivery of data across a network. It segments data received from the upper layers into smaller units (segments), handles error detection and recovery, and provides flow control and congestion management. TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) operate at this layer. Session Layer: 5. The Session Layer establishes, manages, and terminates communication sessions between applications on different network devices. It provides mechanisms for session establishment, synchronisation, checkpointing, and recovery. It also handles security and authentication aspects of a session. Presentation Layer: 6. The Presentation Layer is responsible for data representation, encryption, compression, and formatting. It ensures that data exchanged between applications is in a format that can be understood by the receiving system. It handles tasks like data translation, encryption/decryption, and data compression. Application Layer: 7. The Application Layer is the highest layer of the OSI model. It provides a user interface for network services and enables communication between network applications and end-users. This layer includes protocols and services like HTTP (Hypertext Transfer Protocol), FTP (File Transfer Protocol), SMTP (Simple Mail Transfer Protocol), and DNS (Domain Name System). Each layer in the OSI model performs specific functions and relies on the services provided by the layers below it. The model enables interoperability between different network devices and facilitates the standardised development of networking protocols and technologies. Q) Using devices, applications, protocols, or services, describe the function of the Transport Layer of the OSI and TCP/IP model. The Transport Layer, present in both the OSI and TCP/IP models, is responsible for reliable end-to-end delivery of data between applications running on different network devices. It ensures that data is transmitted accurately, efficiently, and in the correct order. Here are some devices, applications, protocols, and services associated with the Transport Layer and their functions: 1. Devices: ● Transport-layer devices include routers and firewalls that operate at higher layers but inspect and manage transport-layer protocols to facilitate communication between networks. 2. Applications: ● Applications that utilise the Transport Layer protocols for communication include web browsers, email clients, file transfer applications, video conferencing software, and online gaming applications. These applications rely on the Transport Layer to establish and maintain connections with remote hosts. 3. Protocols: ● Transmission Control Protocol (TCP) is the primary transport protocol used in the TCP/IP suite. It provides reliable, connection-oriented, and error-checked data transmission. TCP breaks data into segments, assigns sequence numbers to them, ensures their reliable delivery, and handles congestion control and flow control mechanisms. ● User Datagram Protocol (UDP) is another transport protocol in the TCP/IP suite. It is connectionless and provides a lightweight and faster transmission mechanism without the reliability guarantees of TCP. UDP is often used for real-time applications like streaming media, voice over IP (VoIP), and online gaming, where small delays are acceptable, and reliability can be managed by the application layer. 4. Services: ● Reliable Data Delivery: The Transport Layer ensures that data sent by the sending application is received accurately and completely by the receiving application. It performs error detection and correction using mechanisms such as checksums and acknowledgments. ● Flow Control: The Transport Layer regulates the rate of data transmission between the sender and receiver to prevent overwhelming the receiving system. It manages the amount of data sent based on the receiver's ability to handle it. ● Congestion Control: The Transport Layer monitors the network for congestion and adjusts the rate of data transmission accordingly. It prevents network congestion by reducing the transmission rate when necessary to maintain the stability and efficiency of the network. ● Port Multiplexing: The Transport Layer uses port numbers to multiplex multiple application-level connections over a single network connection. This allows multiple applications running on a device to establish concurrent connections with different services on remote devices. The Transport Layer acts as an intermediary between the Application Layer and the lower network layers, ensuring reliable and efficient data transmission. It provides the necessary mechanisms to deliver data accurately, manage the flow of data, and adapt to network conditions to maintain optimal performance. Q) What is the TCP/IP Model? Explain the different Layers of TCP/IP Model. The TCP/IP (Transmission Control Protocol/Internet Protocol) model is a conceptual framework for the design and implementation of computer network protocols. It is the foundation of the modern internet and is widely used for communication between devices on the internet. The TCP/IP model consists of four layers, which are: Network Interface Layer (also known as Link Layer or Network Access Layer): 1. The Network Interface Layer is responsible for the transmission of data packets over the physical network medium. It defines the protocols and standards for connecting devices to the local network, such as Ethernet, Wi-Fi, or DSL. This layer deals with hardware-specific issues like addressing, data framing, and error detection. Internet Layer: 2. The Internet Layer is responsible for addressing, routing, and fragmenting data packets across different networks. It uses the IP (Internet Protocol) to assign unique IP addresses to devices, enabling them to be identified and located on the internet. The Internet Layer handles packet forwarding, network congestion control, and the fragmentation and reassembly of data packets. Transport Layer: 3. The Transport Layer is responsible for the reliable delivery of data between devices. It provides services such as segmentation, flow control, error recovery, and multiplexing of multiple application-level connections over a single network connection. The two main protocols at this layer are TCP (Transmission Control Protocol) and UDP (User Datagram Protocol). Application Layer: 4. The Application Layer is the topmost layer in the TCP/IP model. It provides services and protocols that enable applications to communicate with each other over the internet. Examples of protocols at this layer include HTTP (Hypertext Transfer Protocol) for web browsing, SMTP (Simple Mail Transfer Protocol) for email, FTP (File Transfer Protocol) for file transfer, and DNS (Domain Name System) for translating domain names into IP addresses. Compared to the OSI model, the TCP/IP model combines the functionalities of the Session, Presentation, and Application Layers of the OSI model into a single Application Layer. The TCP/IP model is widely used in networking and is the basis for the communication protocols that power the internet. K10 Explains the concepts and characteristics of routing and switching in Network Engineering activities Q) Explain the relevance of layer 2 and 3 of the OSI model whilst considering routing and switching? Layer 2 (Data Link Layer) and Layer 3 (Network Layer) of the OSI model play crucial roles in routing and switching within a network. Here's an explanation of their relevance in these contexts: Layer 2 (Data Link Layer): The Data Link Layer is responsible for the reliable transmission of data frames between adjacent network nodes over a shared physical medium. It ensures error-free delivery and provides mechanisms for flow control, error detection, and media access control. In the context of switching, Layer 2 is particularly relevant. Switches operate at this layer, making forwarding decisions based on the destination MAC (Media Access Control) addresses in Ethernet frames. Switches use MAC address tables (also known as forwarding tables) to determine the destination port for incoming frames. When a frame arrives at a switch, it examines the destination MAC address and compares it with the entries in the MAC address table. Based on the table's information, the switch determines the outgoing port(s) through which the frame should be forwarded. This process is known as MAC address learning and allows switches to forward frames within a local network (LAN) based on Layer 2 information. Layer 2 switching is efficient and provides fast forwarding within a LAN. Layer 3 (Network Layer): The Network Layer is responsible for establishing logical connections between different networks and performing routing functions. It handles addressing, routing, and forwarding of data packets across multiple network nodes. Routers operate at Layer 3 and make decisions about the optimal path for data transmission between networks. In the context of routing, Layer 3 is crucial. Routers use IP (Internet Protocol) addresses to identify and route data packets between different networks. They maintain routing tables that contain information about available network paths and use routing algorithms to determine the best path for forwarding packets. Layer 3 routing enables inter-network communication by directing packets across multiple routers until they reach the destination network. This process involves examining the IP addresses in the packet headers and making forwarding decisions based on the routing table's information. Layer 3 routing allows for the connection of networks that are geographically dispersed, enabling communication between devices on different networks. It involves protocols such as IP, ICMP (Internet Control Message Protocol), and routing protocols like OSPF (Open Shortest Path First) or BGP (Border Gateway Protocol). Layer 3 is essential for the internet's functioning, as it enables global connectivity and inter-network communication. In summary, Layer 2 (Data Link Layer) is relevant to switching within a local network, where switches use MAC addresses to forward frames within a LAN. Layer 3 (Network Layer) is relevant to routing between networks, where routers use IP addresses to forward packets across multiple networks. Both layers are essential for efficient and reliable communication within and between networks. Q) What is the key difference between routing and switching? The key difference between routing and switching lies in their functionality and the scope of their operations within a network. Here are the main distinctions: 1. Function: ● Routing: Routing involves the process of selecting the best path for data packets to reach their destination across different networks. Routers analyze the destination IP address in a packet header and make decisions on how to forward the packet based on routing tables and algorithms. Routing occurs at Layer 3 (Network Layer) of the OSI model. ● Switching: Switching involves the process of forwarding data frames within a local network (LAN) based on the destination MAC address in the Ethernet frame. Switches maintain MAC address tables and use them to determine the outgoing port for a received frame. Switching occurs at Layer 2 (Data Link Layer) of the OSI model. 2. Scope: ● Routing: Routing takes place at the network level and involves making decisions on how to forward packets between different networks. It enables communication between devices on different networks and facilitates inter-network connectivity. ● Switching: Switching operates at the local network level (LAN) and focuses on forwarding frames within a single network. It connects devices within the same network, allowing for efficient communication and data exchange. 3. Addressing: ● Routing: Routers use IP (Internet Protocol) addresses to identify and route packets across networks. They analyse the destination IP address in a packet header to determine the appropriate path for forwarding. ● Switching: Switches use MAC (Media Access Control) addresses to identify devices within a local network. They examine the destination MAC address in an Ethernet frame to decide the appropriate outgoing port for forwarding. 4. Traffic Control: ● Routing: Routers handle traffic control by making decisions on the best path for packets based on factors like network congestion, available bandwidth, and routing metrics. They can apply congestion control mechanisms to prevent network congestion and ensure efficient packet delivery. ● Switching: Switches handle traffic control within a local network by forwarding frames based on MAC addresses. They do not perform congestion control as their main focus is on local data transmission. In summary, routing is responsible for forwarding packets between networks based on IP addresses, enabling inter-network communication. Switching, on the other hand, involves forwarding frames within a local network based on MAC addresses, facilitating efficient data transmission within the same network. Routing operates at the network level, while switching operates at the local network level. Implement Solutions K11 Identifies the characteristics of network topologies, types, and technologies Q) What is Network Topology? Give examples and describe their characteristics. Network topology refers to the physical or logical layout of a computer network. It defines how devices are connected and the structure of the network. There are several types of network topologies, each with its own characteristics. Here are some examples: 1. Bus Topology: ● In a bus topology, all devices are connected to a single communication medium, often referred to as a bus or backbone. Devices are connected in a linear manner, with each device linked to the main cable. ● Characteristics: ● Simple and inexpensive to implement. ● Easy to add or remove devices. ● However, if the main cable fails, the entire network can be affected, and the network performance may degrade as the number of devices increases. 2. Star Topology: ● In a star topology, all devices are connected to a central device, such as a switch or hub. Each device has a dedicated connection to the central device. ● Characteristics: ● Easy to install and manage. ● Failure of one device does not affect the rest of the network. ● However, the central device becomes a single point of failure. If it fails, the entire network connected to it may become inaccessible. 3. Ring Topology: ● In a ring topology, devices are connected in a circular manner, forming a closed loop. Each device is connected to two neighbouring devices, creating a ring-like structure. ● Characteristics: ● Data travels in a unidirectional manner, passing through each device in the ring. ● Failure of a single device can disrupt the entire network. ● Requires a token-passing mechanism to control data transmission and avoid collisions. 4. Mesh Topology: ● In a mesh topology, every device is connected to every other device in the network. It provides a direct point-to-point connection between devices. ● Characteristics: ● Offers high redundancy and fault tolerance as there are multiple paths for data to travel. ● Can be expensive to implement, especially for large networks. ● Provides high scalability and flexibility. 5. Hybrid Topology: ● A hybrid topology combines two or more different types of topologies. For example, a network might have a combination of star and bus topologies or a mixture of ring and mesh topologies. ● Characteristics: ● Allows for customization and optimization based on specific network requirements. ● Offers a balance between different topology characteristics. These are just a few examples of network topologies, and there are variations and combinations beyond these. The choice of topology depends on factors such as the network size, cost, scalability, fault tolerance requirements, and expected network traffic patterns. Q) What network topologies have you encountered during your role as a network engineer? Q) What are the different network types? There are several different network types based on their geographical scope, architecture, and purpose. Here are some of the common network types: Local Area Network (LAN): 1. A Local Area Network is a network that covers a small geographic area, typically within a building or a campus. It connects computers, devices, and resources in a limited area, allowing for local communication and data sharing. LANs are commonly used in homes, offices, schools, and small businesses. Wide Area Network (WAN): 2. A Wide Area Network spans a large geographical area, typically connecting multiple LANs or sites across different cities, countries, or even continents. WANs are used to establish long-distance communication and connect geographically dispersed locations. The internet is a prime example of a global WAN. Metropolitan Area Network (MAN): 3. A Metropolitan Area Network covers a larger area than a LAN but smaller than a WAN, typically serving a city or a metropolitan region. MANs connect multiple LANs within a specific geographic area, facilitating communication and resource sharing among different organisations or institutions. Wireless Network: 4. A Wireless Network allows devices to connect and communicate without the need for physical wired connections. Wi-Fi networks are the most common type of wireless networks, providing wireless access to LANs or the internet. Wireless networks are widely used in homes, offices, public spaces, and mobile devices. Virtual Private Network (VPN): 5. A Virtual Private Network is a secure and private network connection established over a public network, such as the internet. VPNs enable users to access a private network remotely, providing secure communication and extending the reach of a private network across different locations. Client-Server Network: 6. In a Client-Server network, multiple client devices connect to and communicate with a central server. The server provides resources, services, and data storage, while the clients request and utilise these resources. Client-Server networks are commonly used in enterprise environments and web-based applications. Peer-to-Peer Network (P2P): 7. In a Peer-to-Peer network, devices are connected directly to each other without a central server. Each device can act as both a client and a server, allowing for decentralised communication and resource sharing. P2P networks are often used for file sharing, collaborative applications, and decentralised systems. Cloud Network: 8. A Cloud Network refers to the infrastructure and network services provided by cloud computing platforms. It allows users to access and utilise computing resources, applications, and data stored in remote data centres over the internet. Cloud networks enable scalability, flexibility, and on-demand access to resources. These are some of the different network types, each serving specific purposes and catering to different communication needs. Organisations and individuals choose the appropriate network type based on factors such as the scale of the network, geographic requirements, security considerations, and desired functionalities. K12 Wireless technologies and configurations Wireless technologies and configurations refer to the different methods and setups used for wireless communication and networking. Here are some commonly used wireless technologies and configurations: Wi-Fi (Wireless Fidelity): 1. Wi-Fi is a wireless networking technology that allows devices to connect to a local area network (LAN) or the internet wirelessly. It uses radio waves to transmit data between devices. Wi-Fi operates on different frequency bands, including 2.4 GHz and 5 GHz, and supports various standards such as 802.11a, 802.11b, 802.11g, 802.11n, 802.11ac, and 802.11ax (Wi-Fi 6). Wi-Fi configurations include: ● Infrastructure Mode: In infrastructure mode, devices connect to a central wireless access point (AP) that acts as a hub for communication. The AP is connected to a wired network, allowing wireless devices to access resources and the internet. ● Ad-hoc Mode: Ad-hoc mode, also known as peer-to-peer mode, allows wireless devices to connect directly to each other without the need for a central AP or infrastructure. Ad-hoc networks are formed temporarily for specific purposes, such as file sharing or multiplayer gaming, without requiring an existing network infrastructure. Bluetooth: 2. Bluetooth is a wireless technology used for short-range communication between devices. It is commonly used for connecting peripherals such as keyboards, mice, speakers, and headphones to computers, smartphones, and other devices. Bluetooth operates in the 2.4 GHz frequency band and supports multiple profiles for different types of communication. Zigbee: 3. Zigbee is a low-power wireless technology designed for low-data-rate communication in applications such as home automation, industrial control, and sensor networks. It operates in the 2.4 GHz or 900 MHz frequency bands and provides low-power consumption and long battery life for connected devices. Zigbee networks are typically organised in a mesh topology, where multiple devices can act as routers and extend the network's coverage. Cellular Networks: 4. Cellular networks provide wireless communication over a wide area, enabling mobile telephony, data services, and internet connectivity. They use licensed frequency bands and require cellular infrastructure, including base stations and mobile network operators, to provide coverage. Cellular networks include technologies such as 2G (GSM), 3G (UMTS/HSPA), 4G LTE, and 5G. Near Field Communication (NFC): 5. NFC is a short-range wireless technology that enables communication between devices in close proximity (typically a few centimetres). NFC is often used for contactless payments, ticketing, access control, and data transfer between devices by simply bringing them close together. Wireless Sensor Networks (WSN): 6. Wireless Sensor Networks consist of numerous autonomous sensor nodes that communicate wirelessly to monitor and collect data from the environment. WSNs are used in various applications such as environmental monitoring, industrial automation, agriculture, and healthcare. The nodes in a WSN typically form a self-organising network with limited power and processing capabilities. These are some of the commonly used wireless technologies and configurations. The choice of wireless technology depends on factors such as range requirements, data rate, power consumption, security considerations, and the specific application or use case. Different wireless technologies and configurations are selected based on the requirements and objectives of the wireless communication needs. Protocols: Wi-Fi (IEEE 802.11): 1. Wi-Fi protocols are used for wireless local area network (WLAN) communication. The IEEE 802.11 family of protocols defines different standards for Wi-Fi networks, including: ● 802.11a: Operates in the 5 GHz frequency band, providing higher data rates but shorter range compared to 802.11b/g. ● 802.11b/g: Operate in the 2.4 GHz frequency band, offering slower data rates but longer range compared to 802.11a. ● 802.11n: Provides higher data rates and improved range using multiple-input multiple-output (MIMO) technology in both 2.4 GHz and 5 GHz bands. ● 802.11ac: Also known as Wi-Fi 5, it operates in the 5 GHz band and offers higher data rates and improved performance compared to 802.11n. ● 802.11ax: Also known as Wi-Fi 6, it operates in both 2.4 GHz and 5 GHz bands and introduces advanced features to enhance capacity, efficiency, and performance in high-density environments. Bluetooth: 2. Bluetooth technology uses various protocols for wireless communication between devices. The Bluetooth protocol stack includes: ● Bluetooth Classic: The original Bluetooth protocol designed for point-to-point communication and connecting devices such as headsets, keyboards, and speakers. ● Bluetooth Low Energy (LE): Designed for low-power, energy-efficient communication with devices like fitness trackers, smartwatches, and IoT devices. Physical Layer Protocol: In the context of wired connections, Ethernet is the most commonly used protocol at the physical layer (Layer 1) of the OSI model. Ethernet defines the physical medium and the means by which devices communicate over wired networks. Ethernet uses various physical layer protocols to transmit data over different types of physical media, such as twisted-pair copper cables, coaxial cables, or fibre optic cables. The specific physical layer protocol used depends on the type of Ethernet implementation being used. For example, some commonly used Ethernet physical layer protocols include: 1. 10BASE-T: This protocol defines the physical layer for Ethernet over twisted-pair copper cables, specifically using Category 3, 4, or 5 cables. It supports a maximum data rate of 10 Mbps. 2. 100BASE-TX: This protocol is used for Ethernet over twisted-pair copper cables, typically using Category 5 or higher cables. It supports a maximum data rate of 100 Mbps. 3. 1000BASE-T: Also known as Gigabit Ethernet, this protocol is used for Ethernet over twisted-pair copper cables, generally using Category 5e or 6 cables. It supports a maximum data rate of 1 Gbps. 4. 10GBASE-T: This protocol enables 10 Gigabit Ethernet over twisted-pair copper cables, usually using Category 6a or 7 cables. It supports a maximum data rate of 10 Gbps. 5. 1000BASE-SX/LX: These protocols are used for Ethernet over fibre optic cables. 1000BASE-SX supports shorter distances (up to a few hundred metres) using multi-mode fibres, while 1000BASE-LX supports longer distances (up to several kilometres) using single-mode fibres. These are just a few examples of Ethernet physical layer protocols used in wired connections. Ethernet provides a flexible and scalable solution for wired network communication, and the choice of the specific protocol depends on factors such as data rate requirements, distance, and the type of physical medium being used. K13 Explains cloud concepts and their purposes within the network engineering environment. Q) What are the advantages of Cloud Computing in a network engineering environment? Cloud computing offers several advantages in a network engineering environment. Here are some key advantages: 1. Scalability: Cloud computing provides scalable resources that can be easily adjusted to meet the changing needs of a network engineering environment. Network engineers can quickly scale up or down their computing resources, such as virtual machines, storage, and networking components, to accommodate varying workloads and demand. 2. Flexibility and Agility: Cloud computing enables network engineers to deploy and manage network resources quickly and efficiently. They can spin up virtual machines, provision storage, and configure networking components on-demand, reducing the time and effort required for traditional hardware-based deployments. This flexibility and agility facilitate faster experimentation, testing, and deployment of network configurations and services. 3. Cost Efficiency: Cloud computing offers cost advantages in terms of reduced capital expenditures and increased operational efficiency. Network engineers can leverage cloud providers' infrastructure and pay for resources on a usage basis, avoiding the upfront costs associated with procuring and maintaining physical hardware. Additionally, cloud computing allows for better resource utilisation, as resources can be dynamically allocated and de-allocated as needed, minimising wasted capacity. 4. Global Reach and Availability: Cloud computing provides a global infrastructure with data centres located in various regions around the world. This enables network engineers to deploy network services and applications closer to their end-users, reducing latency and improving the user experience. Furthermore, cloud providers often offer high availability and redundancy, ensuring that network services are accessible and resilient even in the event of hardware or network failures. 5. Collaboration and Remote Access: Cloud computing facilitates collaboration among network engineers, allowing them to work together on network designs, configurations, and troubleshooting tasks. Cloud-based collaboration tools and shared access to network resources enable remote teams to collaborate effectively, regardless of their physical locations. 6. Disaster Recovery and Business Continuity: Cloud computing offers robust disaster recovery and business continuity capabilities. Network engineers can replicate and backup network configurations, data, and services in the cloud, ensuring that critical network resources can be quickly restored in the event of a disaster or outage. Cloud providers often have redundant infrastructure, backups, and disaster recovery plans in place to minimise downtime and data loss. 7. Automation and Orchestration: Cloud computing platforms provide automation and orchestration capabilities, allowing network engineers to automate routine tasks, configurations, and deployments. This automation streamlines network management, reduces human error, and improves overall operational efficiency. 8. Innovation and Access to Services: Cloud computing enables network engineers to access a wide range of innovative services and technologies, such as Software-Defined Networking (SDN) and Network Function Virtualization (NFV). These services provide greater flexibility, agility, and programmability, allowing network engineers to design and deploy more advanced and dynamic network architectures. Overall, cloud computing offers network engineers the advantages of scalability, flexibility, cost efficiency, global reach, collaboration, disaster recovery, and access to innovative services. It empowers network engineers to design, deploy, and manage networks more efficiently and effectively, accelerating the pace of network innovation and supporting evolving business needs. Q) Describe the different cloud service models. Cloud computing offers different service models that cater to varying levels of control and responsibility for users. The three primary cloud service models are: Infrastructure as a Service (IaaS): 1. IaaS provides users with virtualized computing resources over the internet. It offers the fundamental building blocks for cloud infrastructure, including virtual machines, storage, and networking capabilities. With IaaS, users have more control and responsibility over the management and configuration of their operating systems, applications, and data. They can scale resources up or down based on their needs and have greater flexibility in customising their infrastructure. Examples of IaaS providers include Amazon Web Services (AWS) EC2, Microsoft Azure VMs, and Google Compute Engine. Platform as a Service (PaaS): 2. PaaS offers a higher level of abstraction by providing a platform for users to develop, deploy, and manage applications without the need to worry about underlying infrastructure. It includes pre-configured development frameworks, runtime environments, and other tools that simplify application development and deployment. PaaS abstracts away the complexities of infrastructure management, allowing developers to focus on coding and application logic. Users have control over the applications and data they deploy, while the platform handles the underlying infrastructure. Popular PaaS providers include Heroku, Google App Engine, and Microsoft Azure App Service. Software as a Service (SaaS): 3. SaaS is the most user-friendly cloud service model, offering ready-to-use applications that are accessible over the internet. With SaaS, users can access software applications without the need for installation, maintenance, or management of the underlying infrastructure, platform, or software stack. The provider handles all aspects of software delivery, including updates, security, and availability. Users simply access the application through a web browser or a dedicated client. Common examples of SaaS applications include customer relationship management (CRM) software like Salesforce, email services like Gmail, and productivity tools like Google Workspace (formerly G Suite). K14 Describes the functions of network services Q) What are some common network services you have implemented? As an AI language model, I don't have the capability to directly implement network services. However, I can provide you with a list of common network services that are commonly implemented in network environments. These services include: 1. Domain Name System (DNS): DNS resolves domain names to IP addresses, allowing users to access websites and services using human-readable names. 2. Dynamic Host Configuration Protocol (DHCP): DHCP automatically assigns IP addresses and network configuration parameters to devices on a network, simplifying network management and reducing configuration errors. 3. Network Time Protocol (NTP): NTP synchronises the time on network devices, ensuring consistent timekeeping across the network. It is essential for accurate timestamps, logging, and coordination of network events. 4. File Transfer Protocol (FTP): FTP enables the transfer of files between networked devices. It provides a standard set of commands for uploading, downloading, and managing files on remote servers. 5. Simple Network Management Protocol (SNMP): SNMP allows for the monitoring and management of network devices and systems. It provides a standardised framework for collecting and organising network device information and configuring network parameters. 6. Virtual Private Network (VPN): VPN establishes secure, encrypted connections over public networks, enabling remote users to access a private network securely. It is commonly used to provide secure access to corporate networks or to connect geographically distributed networks. 7. Secure Shell (SSH): SSH provides secure remote access to network devices and servers. It encrypts the communication between the client and server, preventing unauthorised access and ensuring data confidentiality. 8. Web Proxy: A web proxy acts as an intermediary between clients and servers, caching and forwarding web requests on behalf of clients. It can enhance security, performance, and content filtering for network users. 9. Email Services: Email services, such as Simple Mail Transfer Protocol (SMTP), Internet Message Access Protocol (IMAP), and Post Office Protocol (POP), enable the sending, receiving, and management of email messages over a network. 10. Remote Desktop Services: Remote Desktop Services, such as Microsoft's Remote Desktop Protocol (RDP), allow users to access and control remote desktops or applications from their local devices, enabling remote administration and support. Q) Explain what is HTTP and which port does it use? K15 S11 Explains how they have undertaken Network maintenance activities Q) What key maintenance activities would a network technician carry out on a system? A network technician is responsible for performing various maintenance activities to ensure the smooth operation and optimal performance of a network system. Some key maintenance activities that a network technician may carry out include: 1. Network Monitoring: Regularly monitoring the network infrastructure, including routers, switches, servers, and other network devices, to identify and address any performance issues, network congestion, or potential failures. This may involve using network monitoring tools to track network traffic, bandwidth utilisation, device health, and security events. 2. Troubleshooting and Issue Resolution: Identifying and troubleshooting network issues, such as connectivity problems, slow performance, or service disruptions. This may involve analysing network logs, conducting network tests, and utilising diagnostic tools to isolate and resolve the root cause of problems. 3. Performance Optimization: Assessing network performance and implementing optimization techniques to improve efficiency and responsiveness. This may include analysing network traffic patterns, adjusting network configurations, optimising Quality of Service (QoS) settings, and optimising network protocols. 4. Firmware/Software Updates: Keeping network devices up to date by installing the latest firmware updates and patches provided by equipment manufacturers. This ensures that devices have the latest features, bug fixes, and security enhancements. 5. Security Auditing and Patching: Conducting security audits to identify vulnerabilities and implementing necessary security patches and updates. This includes maintaining up-to-date antivirus software, enabling firewalls, implementing access controls, and ensuring compliance with security policies. 6. Backup and Disaster Recovery: Implementing regular data backups and disaster recovery plans to protect against data loss and ensure business continuity in the event of a network failure or disaster. This may involve configuring backup systems, testing data recovery procedures, and documenting recovery processes. 7. Capacity Planning: Assessing network capacity and anticipating future growth to ensure the network can handle increasing demands. This may involve monitoring bandwidth utilisation, analysing trends, and recommending upgrades or expansions to accommodate growing network requirements. 8. Documentation and Reporting: Maintaining accurate documentation of network configurations, diagrams, changes, and maintenance activities. This includes documenting network topology, IP addressing schemes, device configurations, and any changes made to the network infrastructure. Regular reporting on network performance, availability, and maintenance activities may also be required. 9. User Support and Training: Assisting end-users with network-related issues, providing technical support, and offering training on network usage and best practices. These maintenance activities help to ensure the reliability, performance, and security of the network system. Regular maintenance by network technicians is essential to prevent potential issues, address problems promptly, and optimise the network infrastructure. Q) What’s the key difference between proactive and reactive network maintenance? The key difference between proactive and reactive network maintenance lies in their approach and timing in addressing network issues. Here's a breakdown of each: Proactive Network Maintenance: 1. Proactive network maintenance involves taking preventive measures and performing regular tasks to identify and address potential issues before they become significant problems. The focus is on anticipating and mitigating risks to maintain the optimal functioning of the network. Key characteristics of proactive maintenance include: ● Monitoring: Continuously monitoring the network infrastructure, including devices, performance metrics, and security logs, to identify any anomalies or potential issues. ● Preventive Maintenance: Conducting routine tasks such as firmware updates, security patching, backups, capacity planning, and performance optimization to prevent issues and ensure network stability. ● Predictive Analysis: Utilising historical data and analytics to predict and anticipate potential failures or performance bottlenecks, allowing for proactive steps to be taken to mitigate risks. ● Regular Inspections: Conducting periodic network inspections, audits, and assessments to identify vulnerabilities, optimise configurations, and ensure compliance with industry standards and best practices. The goal of proactive network maintenance is to minimise downtime, optimise network performance, enhance security, and provide a reliable network experience for users. Reactive Network Maintenance: 2. Reactive network maintenance involves addressing network issues as they occur, responding to incidents and troubleshooting problems that arise. This approach is more focused on resolving immediate problems rather than preventing them. Key characteristics of reactive maintenance include: ● Issue Resolution: Responding to network issues reported by users or detected through monitoring systems and taking actions to troubleshoot and resolve the problems. ● Troubleshooting: Identifying the root cause of network failures or performance degradation, often through diagnostics, log analysis, and testing, and applying appropriate fixes. ● Incident Response: Handling network emergencies, such as service disruptions or security breaches, by following established incident response procedures to minimise the impact and restore normal operations. ● Ad hoc Fixes: Applying temporary solutions or workarounds to restore network functionality while a permanent resolution is pursued. Reactive network maintenance focuses on addressing immediate problems and restoring network services, but it may result in longer downtime, increased service disruptions, and potential negative impacts on user experience. While reactive maintenance is necessary for incident response, proactive maintenance aims to prevent issues from occurring in the first place. A combination of both approaches is often employed in network maintenance to ensure a reliable and well-performing network environment. Proactive measures help minimise potential issues, while reactive measures address incidents that couldn't be prevented. K16 Explains how current legislation relates to network engineering activities Q) What key legislation needs to be considered when maintaining a network? When maintaining a network in the UK, several key legislations and regulations need to be considered to ensure compliance and protect the privacy, security, and legal rights of individuals and organisations. Here are some important legislations that may apply: Data Protection Act 2018 (DPA): 1. The DPA is the UK's primary data protection legislation, which incorporates provisions of the GDPR into UK law. It governs the processing and protection of personal data and establishes rights and obligations for organisations handling personal information. Privacy and Electronic Communications Regulations (PECR): 2. PECR governs electronic communications, including marketing activities such as email marketing, telemarketing, and the use of cookies and similar technologies. It sets rules on consent, privacy, and electronic communications for businesses operating in the UK. Computer Misuse Act 1990: 3. The Computer Misuse Act criminalises unauthorised access to computer systems and networks, as well as activities such as hacking, malware distribution, and denial-of-service attacks. It provides legal protection for network security and safeguards against cybercrimes. Network and Information Systems Regulations 2018 (NIS Regulations): 4. The NIS Regulations implement the EU Directive on Security of Network and Information Systems in the UK. They establish security and incident reporting requirements for operators of essential services and digital service providers to ensure the resilience and security of network and information systems. Regulation of Investigatory Powers Act 2000 (RIPA): 5. RIPA governs the interception of communications and surveillance activities by public authorities in the UK. It regulates the lawful interception of communications and sets out the powers and procedures for conducting surveillance. Copyright, Designs and Patents Act 1988: 6. This legislation protects intellectual property rights, including copyright, patents, and designs. It governs the use and reproduction of copyrighted materials, including software and digital content, and ensures the legal use and distribution of intellectual property. Q) How do you ensure that key legislation is followed correctly? Ensuring that key legislation is followed correctly requires a systematic approach and adherence to established practices. Here are some steps and measures to help ensure compliance with key legislation: 1. Stay Informed: Stay updated on relevant legislation by monitoring official government websites, industry publications, and legal sources. Regularly review any updates or amendments to the legislation that may impact your organisation's operations. 2. Conduct Compliance Assessments: Conduct periodic assessments to evaluate your organisation's compliance with key legislation. This involves reviewing policies, procedures, and practices to identify any gaps or areas that require improvement. 3. Develop Policies and Procedures: Establish clear policies and procedures that outline the requirements of the key legislation and how they should be implemented within your organisation. Ensure these policies are communicated to employees and regularly reviewed and updated as needed. 4. Provide Training and Awareness: Conduct training sessions to educate employees about their responsibilities and obligations under the relevant legislation. Raise awareness of the importance of compliance and provide guidance on how to adhere to the requirements. 5. Implement Internal Controls: Put in place internal controls and mechanisms to monitor and enforce compliance. This may include access controls, data protection measures, security protocols, and regular audits or assessments to identify any non-compliance issues. 6. Data Protection and Privacy Measures: Implement appropriate measures to protect personal data and ensure compliance with data protection regulations. This may involve implementing data protection policies, conducting privacy impact assessments, and establishing procedures for data breach notification and handling. 7. Engage Legal Counsel: Seek legal advice from professionals specialising in the relevant legislation to ensure your organisation's activities are compliant. They can provide guidance on interpreting the legislation, addressing specific compliance issues, and managing any legal risks. 8. Document and Maintain Records: Keep comprehensive records of compliance efforts, including policies, procedures, training materials, and audit reports. Document any steps taken to address non-compliance and maintain records to demonstrate compliance in case of audits or legal inquiries. 9. Monitor and Review: Regularly monitor compliance with key legislation through ongoing assessments, internal audits, and reviews. Stay vigilant and address any identified compliance gaps promptly. K17 Troubleshooting methodologies for network and IT infrastructure K18 Describes the integration of a server into a network and explains how they have maintained system performance and integrity. Q) How do you ensure that performance and integrity have been maintained when integrating a server into the network? To ensure that performance and integrity are maintained when integrating a server into a network, you can follow these best practices: 1. Network Planning and Design: Before integrating a server, ensure that the network infrastructure is properly planned and designed to accommodate the server's requirements. Consider factors such as network bandwidth, latency, security, and scalability. 2. Compatibility and Interoperability: Verify that the server hardware, operating system, and software applications are compatible with the existing network infrastructure. Ensure that any necessary drivers, patches, or updates are applied to ensure smooth integration and interoperability. 3. Configuration and Optimization: Properly configure the server's network settings, including IP addressing, subnet masks, gateway, and DNS settings. Optimize network parameters such as MTU (Maximum Transmission Unit), TCP window size, and network congestion control algorithms to ensure optimal performance and reliability. 4. Security Measures: Implement appropriate security measures to protect the server and the network. This includes configuring firewall rules, access controls, intrusion detection/prevention systems, and keeping the server's operating system and applications up to date with security patches. 5. Load Testing and Performance Tuning: Perform load testing to assess the server's performance under expected workloads. Identify any bottlenecks or performance issues and optimize server settings, such as adjusting resource allocation, tuning server parameters, and optimizing database configurations. 6. Monitoring and Performance Metrics: Implement monitoring tools and establish performance metrics to continuously monitor the server's performance. Monitor factors such as CPU and memory usage, disk I/O, network traffic, and response times. Set up alerts to notify administrators of any performance degradation or anomalies. 7. Backup and Disaster Recovery: Establish a robust backup and disaster recovery plan for the server and its data. Regularly backup server configurations, applications, and data to ensure data integrity and facilitate quick recovery in case of failures or disasters. 8. Documentation and Change Management: Maintain thorough documentation of the server's configuration, network integration steps, and any changes made during the process. Implement a change management process to track and manage any modifications or updates to the server and network settings. 9. Ongoing Monitoring and Maintenance: Continuously monitor and maintain the server's performance and integrity through regular maintenance activities. This includes applying security patches and updates, reviewing performance metrics, optimizing configurations as needed, and addressing any identified issues promptly. By following these practices, you can ensure that the server integration into the network is done with attention to performance, reliability, and security, thereby maintaining the overall performance and integrity of the network environment. Q) What technologies could be used to minimise downtime when integrating a new server into the network? To minimize downtime when integrating a new server into a network, several technologies and techniques can be employed. Here are some commonly used technologies: 1. Load Balancers: Load balancers distribute incoming network traffic across multiple servers, ensuring that the workload is balanced and no single server is overwhelmed. By implementing load balancers, you can achieve high availability and redundancy, minimizing downtime during server integration or maintenance. 2. Virtualization: Virtualization technologies, such as server virtualization or containerization, allow for the creation of virtual instances of servers or applications. Virtualization enables seamless migration of workloads between physical servers, facilitating server integration without disrupting ongoing services. 3. Redundant Networking Components: Implementing redundant networking components, such as switches, routers, and network links, ensures network availability in case of failures. Technologies like Spanning Tree Protocol (STP) or Virtual Router Redundancy Protocol (VRRP) provide failover capabilities and maintain network connectivity during server integration or maintenance. 4. High Availability Clustering: Utilizing high availability clustering technologies, such as Windows Failover Clustering or Linux High Availability (HA) clustering, enables server redundancy and failover capabilities. Clusters consist of multiple servers working together, ensuring that if one server fails, another server in the cluster can take over without downtime. 5. Disaster Recovery Solutions: Implementing disaster recovery solutions, such as backup and replication technologies, enables quick recovery and minimal downtime in case of server or network failures. Backup systems and replication mechanisms ensure that critical data and services can be restored rapidly. 6. Zero-Downtime Deployment Techniques: Employing deployment techniques that minimize or eliminate downtime during server integration. This includes strategies like blue-green deployments, canary releases, or rolling deployments, where new server instances are gradually introduced into the production environment without interrupting ongoing services. 7. Network Virtualization: Network virtualization technologies, such as software-defined networking (SDN) or virtual LANs (VLANs), allow for the creation of virtual network segments or overlays. These technologies enable the isolation and flexibility of network configurations, making it easier to integrate new servers without impacting the entire network. 8. Automated Configuration Management: Leveraging automation and configuration management tools, such as Ansible, Puppet, or Chef, to streamline the process of deploying and configuring new servers. Automation reduces human error, accelerates deployment, and minimizes downtime associated with manual configurations. By implementing these technologies and techniques, organizations can minimize downtime during server integration, maintain network availability, and ensure a seamless transition to new server environments. It is important to carefully plan and test these technologies before implementing them in production environments to guarantee their effectiveness and minimize potential disruptions. Maintain Security K19 Explains the types of current security threats to networks and describes Q) What is the difference between Vulnerability, Threat and Risk? Vulnerabilities are flaws in the security of a system that makes it more vulnerable to attack by an exploit. It is a weakness, flaw or other shortcoming in a system (infrastructure, database or software), but it can also exist in a process, a set of controls, or simply just the way that something has been implemented or deployed. Threats are the actual occurrences of a risk that could cause harm to a system or its users. It is anything that could exploit a vulnerability, which could affect the confidentiality, integrity or availability of your systems, data, people and more. Risk is the likelihood of a threat or vulnerability occurring. It is the probability of a negative (harmful) event occurring as well as the potential scale of that harm. Your organisational risk fluctuates over time, sometimes even on a daily basis, due to both internal and external factors. Q) What is the CIA triad The CIA triad is a widely used information security model that can guide an organisation's efforts and policies aimed at keeping its data secure. ● ● ● Confidentiality: Only authorised users and processes should be able to access or modify data Integrity: Data should be maintained in a correct state and nobody should be able to improperly modify it, either accidentally or maliciously Availability: Authorised users should be able to access data whenever they need to do so. Q) Describe common security threats to networks. ● ● ● ● Man in the Middle Malware attacks Denial of Services Phishing ● Malware: Malicious software, such as viruses, worms, Trojans, ransomware, and spyware, can infect network systems and compromise their security. Malware can spread across networks, steal sensitive information, disrupt operations, or give unauthorized access to attackers. ● Phishing and Social Engineering: Phishing attacks involve fraudulent emails, messages, or websites that trick users into revealing sensitive information, such as usernames, passwords, or financial details. Social engineering techniques exploit human psychology to manipulate individuals into disclosing confidential information or performing malicious actions. ● Denial-of-Service (DoS) and Distributed Denial-of-Service (DDoS) Attacks: DoS and DDoS attacks aim to overwhelm network resources, such as servers or bandwidth, rendering them inaccessible to legitimate users. Attackers flood the network with excessive traffic or exploit vulnerabilities to disrupt network services and cause downtime. ● Insider Threats: Insider threats refer to malicious or negligent actions by individuals within an organization who have authorized access to the network. These can include unauthorized data access, data theft, sabotage, or intentional damage to network infrastructure. ● Network Intrusions and Unauthorized Access: Unauthorized individuals or hackers may attempt to gain unauthorized access to network systems or data. This can involve exploiting vulnerabilities, weak passwords, or misconfigured access controls to breach the network's security defenses. ● Data Breaches: Data breaches occur when unauthorized individuals gain access to sensitive or confidential data. This can happen through network vulnerabilities, stolen credentials, weak authentication mechanisms, or insecure data storage and transmission practices. ● Man-in-the-Middle (MitM) Attacks: In MitM attacks, attackers intercept and modify communication between two parties without their knowledge. This allows them to eavesdrop on sensitive data, inject malicious code, or alter the contents of the communication. K20 S8 Explains how they have upgraded, applied and tested components to systems configurations ensuring that the system meets the organisation’s requirements and minimises downtime. This should include backup processes and an understanding of the use of automated tools Q) What are the different types of storage methods that could be used when backing up network data? There are several different types of storage methods that can be used when backing up network data. Each method has its own advantages and considerations. Here are some common types: 1. Local Disk Storage: Backing up data to local disk storage involves using external hard drives, network-attached storage (NAS) devices, or storage area network (SAN) devices. This method provides fast backup and recovery times, and the backup data remains readily accessible on-site. However, local disk storage may be susceptible to physical damage, theft, or data loss in the event of disasters affecting the backup location. 2. Tape Storage: Tape storage involves using magnetic tapes to store backup data. It offers a cost-effective solution for long-term data retention and is suitable for large-scale backups. Tape storage provides offline and offline access to backup data, protecting against cyber threats. However, tape backups may have slower backup and recovery times compared to disk-based solutions. 3. Cloud Storage: Cloud storage involves backing up data to remote servers hosted by a third-party cloud service provider. It offers scalability, off-site storage, and the ability to access data from anywhere with an internet connection. Cloud storage provides data redundancy, encryption, and automated backup processes. However, it requires a reliable internet connection, and the cost can increase as the amount of data stored grows. 4. Network-Attached Storage (NAS): NAS is a dedicated storage device connected to the network that allows for file-level backups. It provides centralized storage accessible to multiple devices and offers features like RAID (Redundant Array of Independent Disks) for data protection and fault tolerance. NAS devices can be configured to perform automatic backups, ensuring regular data protection. 5. Disk-to-Disk (D2D) Backup: D2D backup involves replicating or mirroring data from one disk to another. It can be done locally or over a network, providing fast backup and recovery times. D2D backup can utilize technologies like deduplication and incremental backups to optimize storage space and minimize network bandwidth usage. 6. Disk-to-Disk-to-Tape (D2D2T) Backup: D2D2T backup combines the advantages of disk-based backup for fast backup and recovery with the long-term retention and offline accessibility of tape storage. Backup data is initially stored on disk, and then periodically, the data is transferred to tape for archiving and off-site storage. 7. Hybrid Storage: Hybrid storage combines multiple storage methods, such as local disk storage, cloud storage, and tape storage, to create a comprehensive backup solution. It allows organizations to leverage the benefits of different storage types based on their specific needs, such as fast recovery from local disks and long-term retention on tape or cloud. The choice of storage method depends on factors such as data volume, recovery time objectives, cost considerations, data security requirements, and the overall backup strategy of the organization. It is important to carefully assess the specific needs and priorities before selecting a suitable storage method for backing up network data. Q) Identify and define the common types of backups. There are several types of backups that can be used to protect and restore data. The choice of backup type depends on factors such as the level of data protection required, the time available for backups, and the available storage resources. Here are some common types of backups: 1. Full Backup: ● A full backup involves creating a complete copy of all data and files. It provides a comprehensive backup but can be time-consuming and requires significant storage space. Full backups are typically performed periodically, such as weekly or monthly, to capture all data. 2. Incremental Backup: ● Incremental backups only save changes made since the last backup, whether it was a full or incremental backup. It reduces backup time and storage requirements compared to full backups. However, during a restore, it requires the most recent full backup and all subsequent incremental backups to be restored in sequence. 3. Differential Backup: ● Differential backups capture changes made since the last full backup. Unlike incremental backups, which only store changes since the last backup (whether full or incremental), differential backups store changes since the last full backup. It requires less time for restoration compared to incremental backups, as only the full backup and the most recent differential backup are needed. 4. Mirror Backup: ● A mirror backup creates an exact replica of the source data. It copies all files and directories, overwriting any existing files in the backup location. Mirror backups are useful when you need an identical copy of the data for immediate access and recovery. 5. Snapshot Backup: ● A snapshot backup captures the state of a system or data at a specific point in time. It creates a read-only copy of the data, allowing you to revert to that specific snapshot if needed. Snapshots are commonly used in virtual machine environments and storage systems to provide quick recovery points. 6. Continuous Data Protection (CDP): ● CDP continuously captures and backs up data changes in real-time or near real-time. It captures every change made to the data, allowing for granular recovery at any point in time. CDP systems can provide a high level of data protection but require significant storage resources and may impact system performance. 7. Cloud Backup: ● Cloud backups involve storing data backups in remote cloud storage. It provides off-site data protection, scalability, and accessibility from anywhere with an internet connection. Cloud backup services often offer features like versioning, data deduplication, and encryption for enhanced data security. These are some of the commonly used backup types, and organizations often use a combination of these methods to create a comprehensive backup strategy that aligns with their specific needs and requirements. Q) What common testing utilities would you use to test the functionality of network components? There are several common testing utilities and tools available to test the functionality of network components. These tools help diagnose, troubleshoot, and evaluate the performance of various network components. Here are some commonly used testing utilities: 1. Ping: Ping is a basic utility used to test the reachability and response time of a network device or IP address. It sends ICMP Echo Request packets and measures the round-trip time. Ping is useful for testing connectivity between devices, identifying network latency, and verifying basic network functionality. 2. Traceroute/Tracepath: Traceroute (Windows) or Tracepath (Linux) is a utility used to trace the path of network packets from the source to the destination. It provides information about the routers or network devices traversed along the route. Traceroute helps identify network hops, measure packet delays, and pinpoint potential bottlenecks or routing issues. 3. Netcat (nc): Netcat is a versatile networking utility that can be used for various testing purposes. It can create TCP or UDP connections, send or receive data streams, and test network services or ports. Netcat is helpful for checking port availability, testing network connectivity, and troubleshooting network applications. 4. iperf: iperf is a popular tool used for network performance testing and measuring throughput, bandwidth, and network capacity. It can generate TCP or UDP traffic between two endpoints, allowing you to assess network performance, identify potential bottlenecks, and evaluate the quality of network links. 5. Wireshark: Wireshark is a powerful network protocol analyzer that captures and analyzes network traffic. It allows you to examine packet-level details, dissect protocols, and diagnose network issues. Wireshark is useful for troubleshooting network problems, identifying malformed packets, and understanding network behavior. 6. Nmap: Nmap (Network Mapper) is a versatile security scanning tool that can also be used for network component testing. It can discover network hosts, identify open ports, and determine which services are running on a system. Nmap helps assess network security, validate firewall configurations, and test network devices for vulnerabilities. 7. SNMP-based Tools: SNMP-based monitoring tools, such as SNMPwalk, SNMPget, or SNMP MIB browsers, can be used to test the functionality and retrieve information from SNMP-enabled network devices. These tools help verify SNMP communication, query device parameters, and monitor performance metrics. 8. Load Testing Tools: Load testing tools, such as Apache JMeter or Gatling, are used to simulate heavy network traffic and evaluate the performance and capacity of network components under load. They help identify performance bottlenecks, measure response times, and assess the scalability of network infrastructure. These testing utilities provide valuable insights into the functionality, performance, and behavior of network components. Network administrators and engineers often use a combination of these tools based on their specific testing requirements and the components being evaluated. Q) What technologies could be used to minimise network downtime? Several technologies can be used to minimize network downtime and ensure high availability of network services. Here are some commonly employed technologies for this purpose: 1. Redundant Network Components: Implementing redundancy at critical network components, such as routers, switches, firewalls, and load balancers, helps minimize downtime. Redundancy can be achieved through technologies like hot standby, failover clustering, or virtualization, where backup components automatically take over in case of failure. 2. Network Load Balancing: Load balancing distributes network traffic across multiple servers or network devices to ensure efficient resource utilization and avoid single points of failure. By evenly distributing the workload, load balancers help prevent service disruptions and improve overall network performance. 3. Virtualization: Virtualization technologies, such as virtual machines (VMs) or containers, enable the consolidation of multiple network services or applications onto a single physical server. By isolating services and applications within virtual environments, organizations can achieve greater flexibility, scalability, and resilience. 4. High Availability (HA) Protocols: Some network protocols, such as Virtual Router Redundancy Protocol (VRRP) and Hot Standby Router Protocol (HSRP), provide mechanisms for achieving high availability in routing. These protocols enable multiple routers to work together as a single virtual router, ensuring continuous availability of routing services. 5. Fault-Tolerant Link Technologies: Technologies like Spanning Tree Protocol (STP) or Rapid Spanning Tree Protocol (RSTP) help ensure loop-free network topologies and fast recovery from link failures. They detect and eliminate redundant links while providing alternate paths to prevent network downtime. 6. Network Monitoring and Management: Implementing robust network monitoring and management solutions allows for proactive detection of network issues, performance bottlenecks, or potential failures. By continuously monitoring network devices, traffic, and performance metrics, administrators can identify problems early and take corrective actions before they cause significant downtime. 7. Disaster Recovery and Business Continuity Planning: Having a comprehensive disaster recovery (DR) plan and business continuity strategy in place is crucial. This includes regular data backups, offsite storage, redundant data centers, and predefined procedures for recovering network services in the event of a catastrophic failure. 8. Quality of Service (QoS): QoS technologies prioritize critical network traffic over less important traffic, ensuring that essential services receive adequate bandwidth and low latency. By managing network resources effectively, QoS helps maintain the performance and availability of mission-critical applications during periods of high network congestion. 9. Software-Defined Networking (SDN): SDN separates the network control plane from the underlying hardware, allowing for centralized network management and dynamic network configuration. This flexibility enhances network resilience, simplifies network management, and enables faster response to network failures or changes. 10.Cloud-Based Solutions: Cloud-based network services and infrastructure provide built-in redundancy and high availability. By leveraging cloud providers' infrastructure, organizations can benefit from distributed data centers, load balancing, and automatic failover capabilities to minimize network downtime. Implementing a combination of these technologies, tailored to the specific needs and scale of the network infrastructure, can significantly reduce network downtime and enhance the reliability of network services. Compare and contrast approaches to maintaining system performance and integrity K15 K18 S8 S11 Q) Describe different approaches to maintaining system performance and integrity. Compare the differences in the approaches described. There are different approaches to maintaining system performance and integrity. Here are three commonly used approaches: proactive monitoring and optimization, preventive maintenance, and reactive troubleshooting. Proactive Monitoring and Optimization: 1. This approach focuses on continuously monitoring system performance, identifying potential issues, and optimizing the system to prevent performance degradation or failures. Key elements of this approach include: ● Real-time monitoring: Utilizing monitoring tools and techniques to collect and analyze system performance data in real-time. This helps detect anomalies, bottlenecks, or signs of potential issues before they impact system performance. ● Capacity planning: Predicting future resource requirements based on historical data and growth projections. It involves monitoring resource utilization trends, identifying potential capacity constraints, and scaling the system proactively to meet future demands. ● Performance tuning: Optimizing system configurations, resource allocation, and software parameters to maximize performance. This may involve adjusting settings, fine-tuning algorithms, or optimizing database queries to improve system response times and throughput. Preventive Maintenance: 2. Preventive maintenance focuses on regular and scheduled activities aimed at preventing system failures or performance issues. The goal is to proactively address potential problems before they occur. Key elements of this approach include: ● Patch management: Regularly applying software patches, updates, and security fixes to address known vulnerabilities, bugs, or performance issues. This helps keep the system up-to-date and protected against security threats and software flaws. ● Hardware maintenance: Performing routine checks, inspections, and cleaning of hardware components to ensure they are functioning properly. This includes tasks like dust removal, cable management, and hardware testing. ● Backup and recovery: Regularly backing up critical system data and implementing disaster recovery plans to ensure data integrity and facilitate recovery in the event of system failures or data loss. Reactive Troubleshooting: 3. This approach involves responding to system issues and failures as they occur and taking immediate actions to resolve them. Key elements of this approach include: ● Incident management: Establishing processes and procedures for logging, tracking, and resolving system incidents. This includes having a helpdesk or support team available to respond to user-reported issues promptly. ● Troubleshooting and diagnostics: Conducting detailed investigations to identify the root cause of system issues or performance degradation. This may involve analyzing log files, reviewing system configurations, and using diagnostic tools to pinpoint the problem. ● Remediation and problem resolution: Taking appropriate actions to address identified issues and restore system performance. This may include applying patches, reconfiguring settings, restarting services, or replacing faulty hardware components. Differences between the approaches: ● Proactivity: Proactive monitoring and optimization approach emphasizes identifying and addressing issues before they impact system performance, whereas preventive maintenance focuses on scheduled activities to prevent failures. Reactive troubleshooting, on the other hand, addresses issues as they arise. ● Timing: Proactive monitoring and optimization and preventive maintenance are ongoing processes, whereas reactive troubleshooting occurs in response to incidents or problems. ● Focus: Proactive monitoring and optimization and preventive maintenance focus on preventing issues and optimizing system performance. Reactive troubleshooting focuses on resolving specific issues or incidents. ● Resource utilization: Proactive monitoring and optimization and preventive maintenance aim to optimize resource utilization and prevent overloads or bottlenecks. Reactive troubleshooting focuses on resolving issues but may not address underlying performance optimization. Overall, combining these approaches can help organizations maintain system performance and integrity effectively. Proactive measures reduce the likelihood of issues, preventive maintenance minimizes the occurrence of failures, and reactive troubleshooting addresses incidents promptly when they do occur. K21 Approaches to change management Change management refers to the process of planning, implementing, and managing changes within an organization to minimize disruptions and maximize the chances of successful outcomes. Here are three common approaches to change management: Top-Down Approach: 1. The top-down approach to change management involves a centralized decision-making process where senior leaders or executives drive and initiate changes. Key elements of this approach include: ● Clear vision and direction: Senior leaders communicate a clear vision for change and establish the direction in which the organization is heading. ● Strategic planning: Leaders develop a comprehensive change strategy, including goals, objectives, and a roadmap for implementing the change. ● Communication and engagement: Leaders communicate the change to employees, stakeholders, and affected parties, ensuring understanding and buy-in. They actively engage employees and involve them in the change process. ● Resource allocation: Leaders allocate necessary resources, including budget, personnel, and technology, to support the change initiative. ● Monitoring and evaluation: Leaders monitor the progress of the change, evaluate its impact, and make adjustments as necessary. The top-down approach is effective for large-scale changes, as it provides a clear direction and unified approach. However, it may result in resistance or lack of ownership from employees if they feel excluded from the decision-making process. Participatory Approach: 2. The participatory approach emphasizes involving employees at various levels in the change management process. It promotes collaboration, shared decision-making, and active engagement. Key elements of this approach include: ● Employee involvement: Employees are encouraged to participate in identifying problems, proposing solutions, and shaping the change process. ● Communication and transparency: Open and transparent communication channels are established to keep employees informed about the change, its rationale, and progress. ● Training and support: Employees are provided with necessary training, resources, and support to adapt to the change effectively. ● Empowerment: Employees are empowered to take ownership of the change process and contribute their ideas and expertise. ● Continuous feedback and improvement: Regular feedback loops are established to gather input from employees, address concerns, and make improvements to the change process. The participatory approach fosters a sense of ownership and engagement among employees, increasing the likelihood of successful change implementation. However, it can be time-consuming and may require additional effort in terms of coordination and consensus-building. Agile Approach: 3. The agile approach to change management draws inspiration from agile project management methodologies. It emphasizes iterative and incremental changes, flexibility, and adaptability. Key elements of this approach include: ● Small, manageable changes: Changes are broken down into smaller, manageable chunks, allowing for faster implementation and easier adaptation. ● Continuous feedback and adaptation: Regular feedback from stakeholders and users is gathered, allowing for adjustments and course corrections as needed. ● Cross-functional collaboration: Teams comprising individuals from various departments or functions work collaboratively, promoting knowledge sharing and collective problem-solving. ● Quick iterations and experimentation: Changes are implemented in quick iterations, allowing for rapid learning, experimentation, and adjustment based on feedback. ● Embracing change as a norm: The organization embraces change as an ongoing process and encourages a culture of flexibility and continuous improvement. The agile approach is well-suited for dynamic environments and complex changes. It allows organizations to respond quickly to changing circumstances and iteratively refine the change implementation. However, it may require a cultural shift and may not be suitable for all types of changes or organizations. Each approach to change management has its advantages and considerations. The choice of approach depends on factors such as the nature of the change, organizational culture, employee involvement, and the level of complexity involved. Organizations often tailor their approach based on these factors to increase the chances of successful change implementation.