library(tsibble)
library(tsibbledata)
library(feasts)
library(fable)
library(tidyverse)
library(lubridate)
library(magrittr)
library(ggthemes)
theme_set(theme_light())
theme_update(plot.title = element_text(hjust = 0.5))
Question 1 (Exercise 2.10.4)
library(USgas)
ts = tsibble(us_total, index = year, key = state)
ts_new_england = ts %>%
filter(state %in% c('Maine', 'Vermont', 'New Hampshire', 'Massachusetts',
'Connecticut', 'Rhode Island'))
autoplot(ts_new_england, y) +
labs(x = 'Year',
y = 'Demand for natural gas',
title = 'Dynamic of demand for natural gas in New England'
)
Question 2-1 (Exercise 2.10.9)
aus = aus_production %>%
filter(!is.na(Bricks))
aus %>% autoplot(Bricks) + labs(title = 'autoplot')
aus %>% gg_season(Bricks) + labs(title = 'gg_season')
aus %>% gg_subseries(Bricks) + labs(title = 'gg_subseries')
aus %>% ACF(Bricks) %>% autoplot() + labs(title = 'ACF %>% autoplot')
aus %>% gg_lag(Bricks, geom='point') + labs(title = 'gg_lag') +
theme(legend.position = 'top')
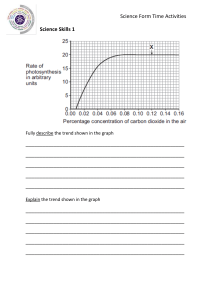
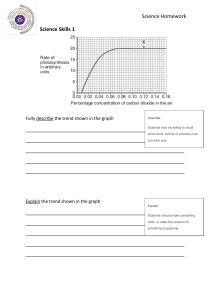
There was very strong upward trend up to 1980 year, then it stopped, and we have some
downward trend after 1980.
Also, there is definitely some seasonality — production in the first quarter almost always
lower, than in other quarters. Third quarter usually is the most productive one.
We have strong cyclicity as well, with period around 5 years. It’s interesting, that each cycle
starts with extreme deep falling down, then ~ 5 years of recovery before next falling down.
Question 2-2 (Exercise 5.11.1)
aus %>%
model(SNAIVE(Bricks ~ lag('year'))) %>%
forecast(h=10) %>%
autoplot(aus) +
labs(title = 'Forecast with SNAIVE model')
Question 2-3 (Exercise 5.11.11)
A. STL decomposition
Let’s try different window size for estimating seasonal component and compare their
residuals.
aus %>%
filter(!is.na(Bricks)) %>%
model(STL(Bricks ~ trend() +
season(window = "periodic"),
robust = F)) %>%
gg_tsresiduals() +
labs(title = 'Season window = infinity')
aus %>%
filter(!is.na(Bricks)) %>%
model(STL(Bricks ~ trend() +
season(window = 4),
robust = F)) %>%
gg_tsresiduals() +
labs(title = 'Season window = 4')
aus %>%
filter(!is.na(Bricks)) %>%
model(STL(Bricks ~ trend() +
season(window = 10),
robust = F)) %>%
gg_tsresiduals() +
labs(title = 'Season window = 10')
Decomposition with fixed seasonal component produces less autocorrelated residuals, let’s
choose this one.
dcmp = aus %>%
filter(!is.na(Bricks)) %>%
model(STL(Bricks ~ trend() +
season(window = "periodic"),
robust = F)) %>%
components()
autoplot(dcmp)
B + C. Seasonally adjusted data
dcmp %<>% select(-.model)
dcmp %>%
model(NAIVE(season_adjust)) %>%
forecast(h=10) %>%
autoplot(dcmp) +
labs(title = 'Seasonally adjusted data with naive forecast')
D. decomposition_model()
dcmp_full = aus %>%
model(decomposition_model(
STL(Bricks ~ trend() + season(window = "periodic"), robust = F),
NAIVE(season_adjust)
))
dcmp_full %>%
forecast(h=10) %>%
autoplot(aus)
E. Autocorrelation of residuals
dcmp_full %>%
gg_tsresiduals()
At certain periods residuals looks autocorrelated. But in general — not much.
F. Comparing with robust STL.
dcmp_robust = aus %>%
model(decomposition_model(
STL(Bricks ~ trend() + season(window = "periodic"), robust = T),
NAIVE(season_adjust)
))
dcmp_robust %>%
gg_tsresiduals()
I don’t see much difference here. Probably it’s because we don’t have a lot of outliers in the
data.
G. Compare SNAIVE and decomposition_model() forecasts
train = head(aus, nrow(aus)-8)
test = tail(aus, 8)
fc = train %>%
model(SNaive = SNAIVE(Bricks),
Decomposition = decomposition_model(
STL(Bricks ~ trend() + season(window = "periodic"), robust = F),
NAIVE(season_adjust))) %>%
forecast(h=8)
fc %>%
autoplot(tail(aus, 40), level=NULL)
accuracy(fc, test)
## # A tibble: 2 x
##
.model
##
<chr>
## 1 Decomposition
## 2 SNaive
10
.type
ME RMSE
MAE
MPE MAPE MASE RMSSE
ACF1
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
<dbl>
Test
8.00 18.1 13.8 1.82
3.36
NaN
NaN 0.0957
Test
2.75 20
18.2 0.395 4.52
NaN
NaN -0.0503
Decomposition model looks better. Seasonal recession in winter 2004 was unusually small, it
gave some points to seasonal naive which predicts lower winter recession, but actually most
winters had recession more like in decomposition model forecast. And even with that winter,
RMSE, MAE and MAPE are all better with decomposition model. So I would choose it instead of
seasonal naive model.
Question 3 (Exercise 7.10.1)
A. Relationship of temperature and demand
jan14_vic_elec = vic_elec %>%
filter(yearmonth(Time) == yearmonth("2014 Jan")) %>%
index_by(Date = as_date(Time)) %>%
summarise(
Demand = sum(Demand),
Temperature = max(Temperature)
)
jan14_vic_elec %>%
ggplot() +
aes(Temperature, Demand) +
geom_point(size=2) +
geom_smooth(method='lm') +
labs(title = 'January, 2014',
x = 'Maximum daily temperature')
Demand has positive correlation with temperature, because in hot days people are using airconditioner for cooling, it increases electricity demand.
B. Residuals plot
fit = jan14_vic_elec %>%
model(TSLM(Demand ~ Temperature))
augment(fit) %>%
ggplot(aes(Date)) +
geom_line(aes(y = Demand, colour = "Data")) +
geom_line(aes(y = .fitted, colour = "Fitted")) +
scale_colour_manual(values = c(Data = "black", Fitted = "#D55E00")) +
labs(title = 'Electricity demand for Victoria, Australia') +
guides(colour = guide_legend(title = "Series"))
augment(fit) %>%
ggplot() +
geom_point(aes(.fitted, .resid)) +
geom_hline(yintercept = 0) +
labs(x = 'Fitted value',
y = 'Residual')
report(fit)
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
Series: Demand
Model: TSLM
Residuals:
Min
1Q
-49978.2 -10218.9
Median
-121.3
3Q
18533.2
Max
35440.6
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 59083.9
17424.8
3.391 0.00203 **
Temperature
6154.3
601.3 10.235 3.89e-11 ***
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 24540 on 29 degrees of freedom
Multiple R-squared: 0.7832, Adjusted R-squared: 0.7757
F-statistic: 104.7 on 1 and 29 DF, p-value: 3.8897e-11
In general, this model isn’t too bad. With R² 78% it catches most demand’s variability. Has
some slightly outliers, days with very low demand regardless temperature 26-27 C. But it
could be rainy days with relatively high temperature maximum which didn’t last long.
C. Forecast
Our model equation is
Demand = 59083.9 + Temperature * 6154.3
With temperature = 15 C we wil predict demand 151398, with temperature 35 C — demand
274484. Second forecast looks fine for me, but I’m not so confident about forecast for 15 C,
because I think, that there is some bottom line when people don’t use air-conditioned
anymore, and maybe even turn on heater, so this linear relationship will not valid under that
line. Since we don’t have such low temperature in January 2014, it’s hard to guess where that
bottom line is.
D. Confidence intervals
One of easy ways to get confidence intervals is to use hilo() function:
fit %>%
forecast(
new_data(jan14_vic_elec, 2) %>%
mutate(Temperature = c(15, 35))
) %>%
hilo(level=c(80,95)) %>%
unpack_hilo(c(`80%`, `95%`)) %>%
select(Temperature, `80%_lower`, `80%_upper`, `95%_lower`, `95%_upper`,
`.mean`) %>%
mutate_all(round)
## # A tsibble: 2 x 7 [1D]
##
Temperature `80%_lower` `80%_upper` `95%_lower` `95%_upper` .mean Date
##
<dbl>
<dbl>
<dbl>
<dbl>
<dbl> <dbl> <date>
## 1
15
117908
184889
100179
202617 151398 2014-0201
## 2
35
242088
306880
224939
324029 274484 2014-0202
E. Using whole dataset
vic_elec_full = vic_elec %>%
index_by(Date = as_date(Time)) %>%
summarise(
Demand = sum(Demand),
Temperature = max(Temperature)
)
vic_elec_full %>%
ggplot() +
aes(Temperature, Demand) +
geom_point(color = 'midnightblue') +
labs(title = 'Daily electricity demand for Victoria, Australia',
x = 'Maximum daily temperature')
As we suggested earlier, at some point all air-conditioners already off, so decreasing in
temperature don’t cause decreasing in energy demand. And when temperature goes even
lower, approximately lower than 20C, people starting to use electricity for heating, so
temperature and demand have negative correlation below 20C.
Question 4 (Exercise 7.10.4)
A. Time plot
library(fpp3)
autoplot(souvenirs) +
labs(title = 'Sales of souvenir shop in Australia')
We have clear yearly seasonality in this dataset — very high peaks before every Christmas,
small peaks during the local surfing festival. Also, there is some trend over time — during
years sells were increased. Peak before Christmas 1994 is ~ 5 times higher, than it was before
Christmas 1988.
B. Logging the data.
Let’s take a look at distribution of monthly sales.
ggplot(souvenirs) +
geom_histogram(aes(Sales), bins=45, fill = 'midnightblue')
As we can see, it has heavily right skewed distribution. Difference between most observations
is relatively very small, some observations to the right are very far away. With such
distribution it’s unlikely will have linear relationship with other variables, unless that variable
will have same shape of distribution. If we take a log of it, it will look like this:
souv = souvenirs %>%
tsibble(index = Month) %>%
mutate(Sales = log(Sales))
ggplot(souv) +
geom_histogram(aes(Sales), bins=45, fill = 'midnightblue')
autoplot(souv) +
labs(y = 'Log of sales')
Such variable will probably have more linear relationship with other variables. Also, trend is
much more linear now, which is important because we wil use linear trend as predictor.
C. Fitting linear model
For adding linear trend over time we can just add numbers from 0 up to 83 (because we have
84 observations), this way trend will be estimated during linear regression and will be chosen
the trend which minimize squared errors. Also, we need to add seasonal dummy variables as
well as “surfing festival”, which will equal 1 every March and 0 at any other month.
In order to avoid perfect multicollinearity among 4 seasons, we will use spring as baseline
season, so coefficients for rest 3 seasons will reflect the difference in compare with spring.
souv$trend = 0:83
souv$fest = 0
souv[month(souv$Month) == 3, 'fest'] = 1
souv$winter = 0
souv$spring = 0
souv$summer = 0
souv$autumn = 0
souv[month(souv$Month) %in% c(12, 1, 2), 'winter'] = 1
souv[month(souv$Month) %in% c(3, 4, 5), 'spring'] = 1
souv[month(souv$Month) %in% c(6, 7, 8), 'summer'] = 1
souv[month(souv$Month) %in% c(9, 10, 11), 'autumn'] = 1
souv_lm = souv %>%
model(TSLM(Sales ~ trend + fest + winter + summer + autumn))
augment(souv_lm) %>%
ggplot(aes(Month)) +
geom_line(aes(y = Sales, colour = "Data")) +
geom_line(aes(y = .fitted, colour = "Fitted")) +
scale_colour_manual(values = c(Data = "black", Fitted = '#0055CC')) +
labs(title = 'Fitted linear model', y = 'Log of sales') +
guides(colour = guide_legend(title = "Series"))
D. Residuals plots against time and fitted values
gg_tsresiduals(souv_lm) +
labs(title = 'Residuals against time')
augment(souv_lm) %>%
ggplot() +
geom_point(aes(.fitted, .innov), color = 'midnightblue') +
geom_hline(yintercept = 0) +
labs(x = 'Fitted value',
y = 'Residual',
title = 'Residuals against fitted values'
)
Plot of residuals against fitted values doesn’t reveal much of interesting for me, but against
time — definitely does. We can see strong yearly seasonality for some months, not for each
month though. Also if we’ll take a look at ACF plot of residuals, there is very strong
autocorrelation with lag 12, which tells same thing once more time — yearly seasonality of
residuals.
E. Boxplots of the residuals month
augment(souv_lm) %>%
ggplot() +
geom_boxplot(aes(.innov, factor(month.name[month(Month)], levels =
month.name), fill = as.factor(month(Month)))) +
labs(x = 'Residual', y = 'Month',
title = 'Residuals for each month') +
coord_flip() +
theme(legend.position = 'none',
axis.text.x = element_text(angle=-90, hjust = 0))
Here we can see more clearly, which months have bias residuals. Predictions for period from
November up to February are very poor with our current model, especially December.
F. Interpretation of coefficients
report(souv_lm)
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
Series: Sales
Model: TSLM
Residuals:
Min
1Q
Median
-0.97322 -0.24768 -0.04151
3Q
0.17522
Max
1.41261
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.946636
0.160486 49.516 < 2e-16 ***
trend
0.024344
0.002257 10.786 < 2e-16 ***
fest
0.302670
0.231154
1.309 0.19425
winter
0.339953
0.172277
1.973 0.05200 .
summer
0.146501
0.172366
0.850 0.39796
autumn
0.464935
0.172720
2.692 0.00869 **
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4993 on 78 degrees of freedom
## Multiple R-squared: 0.6247, Adjusted R-squared: 0.6007
## F-statistic: 25.97 on 5 and 78 DF, p-value: 2.4365e-15
Trend: each month baseline of prediction increases by 2.5% (starting from 2826 at first
month)
Surfing festival: increases prediction by 35.3%
Winter: increases prediction by 40.5%
Summer: increases prediction by 15.8%
Autumn: increases prediction by 59.2%
G. Ljung-Box test
Box.test(augment(souv_lm)$.innov, lag = 12, type = "Ljung")
##
## Box-Ljung test
##
## data: augment(souv_lm)$.innov
## X-squared = 81.2, df = 12, p-value = 2.435e-12
According to Ljung-Box test, residuals of our model are definitely autocorrelated (well, we
already hadn’t any doubts about that). It means, that we can make our predictions more
accurate.
H. Forecast
souv_lm %>%
forecast(new_data = souv[1:36, ] %>% mutate(trend = 84:119, Month = Month+84))
%>%
mutate(Sales = exp(Sales)) %>%
autoplot(souv %>% mutate(Sales = exp(Sales)))
I. Suggestions about improvement
We added dummy variable for March and median residual for March ic close to zero. We
should do the same for December, it’s absolutely necessary. After we add it, coefficient for
winter will be significantly reduced and predictions for January/February will become much
more accurate kind of automatically. Still, it’s probably worth to add dummy variable for
January as well, because after people buy a lot in December seems like they don’t but much in
January.
Question 5
Introduction
We will analyze dataset with monthly sales for a souvenir shop on the wharf at a beach resort
town in Queensland, Australia. It was opened in January 1987 and we have data up to
December 1993, so it’s 7 years in total. Over time this shop was expanded and sales did grow.
Sales are different depending on which time of year it is — for example, there is local surfing
festival every March, so people buy many gifts at that month. Also, people buy a lot of gifts
before Christmas.
Plot below shows, how sales of this shop changed every month:
We can see high peak every December. Also, there is upward trend over time.
Predictors
We want to model sales, using linear regression. It means, that we will take few variables and
say, that sales at certain month will be a linear combination of those variables at that month.
We will call those variables “predictors”. We will use 6 predictors:
1. Baseline (Intercept): it will have identical value for each month, which will reflect expected
amount of sales, if all other predictors equal to zero.
2. Trend: Since over time our shop is growing, each month we will add some value to
expected amount of sales, same value every time.
3. Surfing festival: this variable will be equal to 1, if there was surfing festival at this month,
and 0 otherwise.
4. Winter: 1 for winter months and 0 otherwise.
5. Summer: 1 for summer months and 0 otherwise.
6. Autumn: 1 for autumn months and 0 otherwise.
Note, that we will not use variable for spring, because if all 3 seasonal variables (winter,
spring and autumn) are equal to 0, we already know that it’s spring then. Also, it means that
our baseline prediction, when all variables are equal to zero, will be prediction as if it would
be spring, even if it’s January, for example. We could choose any season for baseline, I did
choose spring because later it will have the lowest coefficient among 4 seasons, so
coefficient for other seasons will indicate, how much sales are increased at that season
compared to spring, I think it makes interpretation slightly clearer.
Log-transformation
Since each month we will increase expected value of sales at the same value, we will model
trend as straight line. It would look like this:
As you can guess, such model will not very accurate, because in reality the trend isn’t linear, it
grows slowly at the beginning and then grows faster and faster. Convenient way to fix it is to
model logarithm of sales instead of amount of sales itself. In this case it will look like this:
Of course, it’s not perfect, but it’s definitely much better.
Starting point of this trend line is our first variable, “intercept”. Variable “trend” reflects the
slope of this line. Rest 4 variables (Surfing festival and 3 seasonal variables) will increase
expected log of sales at some fixed amount for each variable. We will estimate this amount for
each variable, using OLS regression, i.e. we will estimate them that way, which will give as
small mean squared error, as possible.
Linear model summary
After we did it, we have the linear model, which can be described with summary table below:
##
##
##
##
##
##
##
##
##
##
##
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.946636
0.160486 49.516 < 2e-16 ***
trend
0.024344
0.002257 10.786 < 2e-16 ***
fest
0.302670
0.231154
1.309 0.19425
winter
0.339953
0.172277
1.973 0.05200 .
summer
0.146501
0.172366
0.850 0.39796
autumn
0.464935
0.172720
2.692 0.00869 **
--Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Residual standard error: 0.4993 on 78 degrees of freedom
## Multiple R-squared: 0.6247, Adjusted R-squared: 0.6007
## F-statistic: 25.97 on 5 and 78 DF, p-value: 2.4365e-15
Column “estimate” shows, how much that variable increases logarithm of sales. The right
column, called “Pr(>|t|)”, shows probability, that estimate for that variable actually should be
zero and it’s not zero only due random chance.
It’s not very clear, what increasing in logarithm of sales represents. It’s easy to look at them
this way:
Trend: each month expected value increases by 2.5% (starting from 2826 at first
month)
Surfing festival: increases prediction by 35.3%
Winter: increases prediction by 40.5%
Summer: increases prediction by 15.8%
Autumn: increases prediction by 59.2%
In case you wonder, how I calculated these percentage values, I used this formula:
((exp(estimate) - 1) * 100)
Adjusted R² in that summary table shows, how much of total variability of sales our model was
able to catch.
P-value of F-statistic (it’s the last row in summary table) shows the probability, that all our
predictors are useless. This probability basically equal to zero.
On the plot below we can see, how fitted values of our model looks like:
Residuals
Now let’s analyze not what our model catches, but what it didn’t. Group of 3 plot below shows
some information about residuals of our model, i.e how much each fitted value is off from the
real data.
From the first sublot we can see, that each November and, especially, each December real
amount of sales is higher than what our model predicts. For January and February, it’s the
opposite — real data always lower.
From second subplot, the one at the left, we can see, that each residual is very similar to
residual for same month previous year. So, if we would correct prediction based on residual 12
months ago, our predictions would become much better.
The last subplot shows distribution of residuals. In perfect scenario it would look like Gaussian
distribution, but of course it doesn’t.
Also, we can check residuals for each month separately, using plot like this:
Here we can see basically same things, just with different representation, clearer in some
aspects.
Forecast
Now we will forecast sales in next 3 years, 1994—1996 (regardless downsides of our current
model). Painted over areas will represent confidence intervals of our predictions, with 80%
and 95% level of certainty. Here it is:
Here is the same forecast as a table:
Date
1994 Jan
1994 Feb
1994 Mar
1994 Apr
1994 May
1994 Jun
1994 Jul
1994 Aug
1994 Sep
1994 Oct
1994 Nov
1994 Dec
1995 Jan
1995 Feb
1995 Mar
1995 Apr
1995 May
1995 Jun
1995 Jul
1995 Aug
1995 Sep
Prediction
For sales
80%
lower
80%
upper
95%
lower
95%
upper
30685
31441
31037
23496
24075
28561
29265
29986
42246
43287
44353
40107
41095
42108
41567
31468
32244
38251
39193
40159
56579
15746
16125
15443
11946
12233
14631
14983
15343
21641
22162
22694
20442
20931
21432
20524
15873
16253
19441
19905
20380
28756
59797
61304
62375
46214
47381
55753
57161
58605
82467
84549
86685
78691
80686
82732
84186
62384
63968
75261
77173
79134
111323
11061
11324
10672
8351
8549
10268
10512
10761
15188
15548
15917
14308
14645
14990
14126
11050
11309
13587
13906
14232
20097
85126
87298
90258
66113
67803
79441
81473
83558
117505
120511
123595
112428
115320
118288
122317
89619
91930
107689
110467
113318
159288
1995 Oct
1995 Nov
1995 Dec
1996 Jan
1996 Feb
1996 Mar
1996 Apr
1996 May
1996 Jun
1996 Jul
1996 Aug
1996 Sep
1996 Oct
1996 Nov
1996 Dec
57973
59402
53715
55038
56395
55670
42145
43183
51229
52491
53785
75775
77642
79556
71939
29443
30146
27131
27777
28437
27232
21057
21557
25788
26401
27028
38145
39051
39978
35951
114150
117051
106345
109056
111837
113805
84351
86504
101766
104365
107031
150527
154371
158315
143951
20569
21052
18899
19340
19792
18650
14584
14924
17932
18349
18776
26524
27141
27773
24902
163397
167615
152666
156626
160691
166171
121790
124957
146353
150160
154068
216478
222109
227889
207819