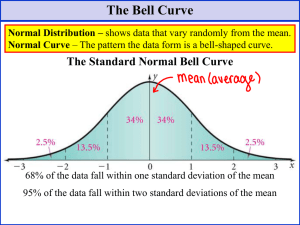
A Transcript of the Lectures in the Normal Distribution Chapter 2 Lecture Objective: In previous lectures, we learned about discrete random variables and their probability distributions. Now, the aim of this set of lectures is for us to learn about a continuous random variable called the normal random variable. References Used: Aguilar, I., Chua, S., Dela Cruz, E., Rodriguez, A., and Puro, L. (2016). Soaring 21 st Century Mathematics – Statistics and Probability: Phoenix Publishing House, Inc., 2016 Albert, J., Albacea, J., Ayaay, M., David, I., and de Mesa, I. (2016) Teaching Guide for Senior High School – Statistics and Probability. Commission on Higher Education K to 12 Transition Program Management Unit. Lim, Y., Nocon, E., Nocon, R., and Ruivivar, L. (2016). Math for Engaged Learning – Statistics and Probability: Sibs Publishing House, Inc Melosantos, L., Antonio, J., Robles, S., Bruce, R., and Sacluti, J (2016). Math Connections in the Digital Age Statistics and Probability. Quezon City: Sibs Publishing House, Inc., 2016 Mendelhall, W., Beaver, R., Beaver, B. (2013). Introduction to Probability and Statistics. Pacific Grove, Calif. : Brooks/Cole ; Andover : Cengage Learning [distributor], 2013. Galton Board. Taken from: https://www.youtube.com/watch?v=6YDHBFVIvIs Lecture 2.1 The Normal Random Variable and its Probability Distribution Introduction Recall that when the random variable is discrete, the sum of all probabilities associated with each random variable value is 1. However, not all experiments are discrete in nature; some are continuous (e.g. height, weight, length of life of products, etc.). For experiments yielding continuous random variables, if we are to assign a probability value to each value of the random variable, the total would no longer be equal to 1. Thus, the methodology used for solving discrete random variables could no longer be employed. In this lecture, we will learn about an approach to solve problems on a continuous random variable called the normal random variable. Lesson Proper 1 A large number of random variables observed in nature, possesses a probability distribution that is approximately “mound- or bell-shaped”. For example, given the following data pertaining to hospital weights (in pounds) of thirty-six (36) babies that were born in the maternity ward of a hospital: 4.94 4.69 5.16 7.29 9.47 6.61 5.84 6.83 4.94 3.45 2.93 6.38 6.76 9.01 8.47 6.8 6.4 3.45 8.6 3.99 7.68 5.32 6.24 6.19 5.63 5.37 8.6 5.26 7.35 6.11 5.87 6.56 6.18 7.35 4.21 5.26 (Illustration taken from the Teaching Guide for Senior High School Statistics and Probability - Commission on Higher Education) the histogram shows that the data set is approximately bell-shaped. In fact, many real-world continuous random variables is bell-shaped (see video: https://www.youtube.com/watch?v=6YDHBFVIvIs). This, bell-shaped curve is also called the Normal Distribution. The normal distribution is widely regarded as the most important distribution in statistical science. Many random variables are either normally distributed or, at least, approximately normally distributed. Heights, weights, examination scores, the length of life of some equipment are among a few random variables that are approximately normally distributed. Although the distributions are only approximately normal, the approximation is usually quite close. Further, the normal distribution is important because many hypothesis tests and regression models are based on the assumption that the data is normal. The following are some statements about the Normal Distribution: 2 𝑓(𝑋) 𝑃(𝑎 < 𝑥 < 𝑏) 𝑋 𝑏 𝑎 Figure 1 1. The depth (or density/height) of the probability which varies with the continuous random variable 𝑋 is described by the formula 1 𝑓(𝑋) = 𝜎√2𝜋 𝑒 −(𝑋−𝜇)2 2𝜎2 , where 𝑒 is the natural number that is approximately equal to 2.71823; 𝜋 is irrational constant pi; −∞ < 𝑋 < ∞; the mean 𝜇 and standard deviation 𝜎 are the parameters of the formula. 2. The area under the probability distribution is equal to 1. 3. The probability that 𝑋 will fall into particular interval, say between 𝑎 to 𝑏, is the shaded area above. 4. 𝑃(𝑋 = 𝑎) = 0 for continuous random variables. This implies that 𝑃(𝑋 ≥ 𝑎) = 𝑃(𝑋 > 𝑎) and 𝑃(𝑋 ≤ 𝑎) = 𝑃(𝑋 < 𝑎) (Note that this is not true for discrete random variables). 𝑓(𝑋) 𝜎 𝜇 3 𝑋 Figure 2 5. The graph of a normal distribution depends on two (2) factors, the mean 𝜇 and standard deviation 𝜎. One can get the areas under the normal curve given the mean and standard deviation. 6. The mean determines the location of the center of the bell-shaped curve. Thus, a change in the value of the mean shifts the graph of the normal curve to the right or to the left. 7. The normal curve is symmetrical with respect to the line containing the mean. This means that the two areas under the curve between the mean and any two points equidistant on either side of the mean are identical. One side of the distribution is the mirror image of the other side. 8. For symmetric distributions with a single peak, such as the normal distribution, it is the case that the mean = median = mode. 9. When a continuous random variable 𝑋 is determined as approximately normal with mean 𝜇 and variance 𝜎 2 , we denote this as 𝑋~𝑁(𝜇, 𝜎 2 ). 10. As 𝑥 increases without bound, the graph approaches the horizontal axis. Similarly, as 𝑥 decreases without bound, the graph approaches the horizontal axis. 𝜇 − 3𝜎 𝜇 − 2𝜎 𝜇−𝜎 𝜇 𝜇+𝜎 𝜇 + 2𝜎 𝜇 + 3𝜎 Figure 3 11. Regardless of any mean 𝜇 and standard deviation 𝜎, a normal curve conforms to the Empirical Rule. That is, about 68% of the area under the normal curve falls within 1 standard deviation from the mean; about 95% of the area under the curve falls within 2 standard deviations of the mean; and about 99.7% of the area under the curve falls within 3 standard deviations of the mean. Example 2.1.1. The data below and the accompanying histogram give the weights to the nearest hundredth of a gram, of a sample of 100 coins (each with a value of 10 php). The mean weight is 8.69 grams and the standard deviation is approximately 0.055 grams. 4 8.57 8.57 8.58 8.59 8.6 8.6 8.61 8.61 8.62 8.62 8.62 8.62 8.63 8.63 8.63 8.63 8.64 8.64 8.64 8.64 8.65 8.65 8.65 8.65 8.65 8.66 8.66 8.66 8.66 8.66 8.67 8.67 8.67 8.67 8.67 8.67 8.68 8.68 8.68 8.68 8.68 8.68 8.69 8.69 8.69 8.69 8.69 8.69 8.7 8.7 8.7 8.7 8.7 8.7 8.7 8.71 8.71 8.71 8.71 8.71 8.71 8.71 8.71 8.72 8.72 8.72 8.72 8.72 8.72 8.72 8.73 8.73 8.73 8.73 8.73 8.73 8.73 8.74 8.74 8.74 8.74 8.74 8.74 8.75 8.75 8.75 8.76 8.76 8.76 8.76 8.77 8.77 8.77 8.78 8.78 8.79 8.79 8.8 8.81 8.81 (Illustration taken from the Teaching Guide for Senior High School Statistics and Probability - Commission on Higher Education) Answer the following: 1. Would you say that the data is approximately normal? Explain. Answer: Yes, we can assume that the data is approximately normal because it looks bell-shaped. 5 2. Compare the mean and the median Answer: Since we noted that the graph is approximately bell-shaped, the mean and the median should be very close to each other (the median is 8.7 grams). 3. What percentage of the data is within one standard deviation from the mean? What are these values? Answer: According to the empirical rule, about around 68% of the data should be within one standard deviation from the mean. Now, since the standard deviation is equal to 0.055, this means that we are looking for the weights 𝑤 that is 8.635 < 𝑤 < 8.745. These weights are the values in black shown on the table below: 8.57 8.57 8.58 8.59 8.6 8.6 8.61 8.61 8.62 8.62 8.62 8.62 8.63 8.63 8.63 8.63 8.64 8.64 8.64 8.64 8.65 8.65 8.65 8.65 8.65 8.66 8.66 8.66 8.66 8.66 8.67 8.67 8.67 8.67 8.67 8.67 8.68 8.68 8.68 8.68 8.68 8.68 8.69 8.69 8.69 8.69 8.69 8.69 8.7 8.7 8.7 8.7 8.7 8.7 8.7 8.71 8.71 8.71 8.71 8.71 8.71 8.71 8.71 8.72 8.72 8.72 8.72 8.72 8.72 8.72 8.73 8.73 8.73 8.73 8.73 8.73 8.73 8.74 8.74 8.74 8.74 8.74 8.74 8.75 8.75 8.75 8.76 8.76 8.76 8.76 8.77 8.77 8.77 8.78 8.78 8.79 8.79 8.8 8.81 8.81 4. Suppose you were to select a coin from this collection. Given that the data is assumed to be normal, what is the chance that its weight would be below the mean? Answer: Through the use of the properties of the normal distribution, it’s reasonable to conclude that the chance that the weight would be below the mean should be about 50%. 6 Lecture 2.2 Areas Under the Normal Distribution Introduction Recall that to find the probability that a normal random variable 𝑋 lies in the interval 𝑎 to 𝑏, we need to find 𝑓(𝑋) 𝑃(𝑎 < 𝑥 < 𝑏) 𝑏 𝑎 𝑋 the area under the normal curve from 𝑎 to 𝑏. This means that when we refer to the probability of a normal random variable, we also refer to the area under the curve. However, seeing that there are countless normal curves; each having different means and standard deviations, a employing a separate method of solving for each individual normal curve is obviously unrealistic to do. To this end, we should use a standardization procedure that allows us to solve all normal distributions regardless of the given parameters. Lesson Proper Def. Standard Normal Random Variable A normal random variable 𝑋 is standardized by expressing its value as the number of standard deviations (𝜎) it lies to the left or to the right of its mean 𝜇. The standard normal random variable 𝑧 (or sometimes called the 𝑧-score) is defined as 𝓏= 𝑥−𝜇 𝜎 or equivalently, 𝑥 = 𝜇 + 𝓏𝜎 Remark. Changing the normal random variable 𝑋 into a 𝑧-score is just merely a change in units measure— like as if we were measuring in inches rather than in centimeters! 7 𝑓(𝑧) 0 𝑧0 𝑧 Figure 4 Given the graph of the standard normal distribution above, we derive the following statements: 1. 2. 3. 4. 5. In the standard normal distribution, 𝜇 = 0, and 𝜎 = 1. When 𝑋 is less than the mean, 𝑧 is negative. When 𝑋 is greater than the mean, 𝑧 is positive. When 𝑋 is equal to 𝜇, 𝑧 = 0. The cumulative area under the standard normal curve, say the area that is on the left of 𝑧0 , is the probability 𝑃(𝑧 ≤ 𝑧0 ). 6. The probability is traditionally determined through a table (widely known as the 𝑧-table) that reports the probability associated with a particular 𝑧-score. Example 2.2.1. Convert the given values of 𝑋 to 𝑧–scores, or vice versa. 𝑋 98 28 𝑧 2.5 – 1.64 𝜇 125 18 49 10.5 𝜎 20 5 32 2.2 Solution to Example 2.2.1 a) Given 𝑋 = 98, 𝜇 = 125, 𝜎 = 20 𝑋−𝜇 𝜎 98 − 125 𝑧= 20 𝑧 = −1.35 𝑧= 8 b) Given 𝑋 = 28, 𝜇 = 18, 𝜎 = 5 𝑋−𝜇 𝜎 28 − 18 𝑧= 5 𝑧=2 𝑧= c) Given 𝑧 = 2.5, 𝜇 = 49, 𝜎 = 32 𝑋 = 𝜇 + 𝑧𝜎 𝑋 = 49 + (2.5)(32) 𝑋 = 129 d) Given 𝑧 = −1.64, 𝜇 = 10.5, 𝜎 = 2.2 𝑋 = 𝜇 + 𝑧𝜎 𝑋 = 10.5 + (−1.64)(2.2) 𝑋 = 6.892 Example 2.2.2. Find 𝑃(0 ≤ 𝑧 ≤ 1.28). Solution to Example 2.2.2 The probability (or the area under the curve) we are solving for is shown on the next page. 𝑓(𝑧) 𝑃(0 ≤ 𝑧 ≤ 1.28) −3 −2 −1 0 2 1 3 𝑧 𝑧 = 1.28 Now, using a 𝑧-table, we see that 𝑃(0 ≤ 𝑧 ≤ 1.28) = 𝑃(𝑧 ≤ 1.28) − 𝑃(𝑧 ≤ 0) = 0.8997 − 0.5 = 0.3997. Example 2.2.3. Find 𝑃(𝑧 < 1.06). 9 Solution to Example 2.2.3. 𝑓(𝑧) 𝑃(𝑧 < 1.06) −3 −2 −1 0 1 2 3 𝑧 = 1.06 Using the cumulative distribution table for the normal random variable (𝑧-table), we have 𝑃(𝑧 < 1.06) = 0.8554. Remark. If say we want to compute for 𝑃(𝑧 > 1.06), since the whole area under the curve is equal to one (1), then 𝑃(𝑧 > 1.06) = 1 − 𝑃(𝑧 < 1.06) = 0.1446. Remark. Note that in the previous examples, we calculated the area of a specific standard normal random variable using the table for the cumulative distribution of a standard normal curve. Now, a modern way to compute this is through the use of the computing program, Excel. So, to get, the area 𝑃(𝑧 < 1.06), we input in excel the following syntax: 10 which gives us approximately, 0.8554. Example 2.2.4. Let 𝑋 be a normal random variable with a mean of 10 and a standard deviation of 2. Find the probability that 𝑋 lies between 11 and 13.6 through the NORMSDIST function of Excel. Solution to Example 2.2.4 Since we are asked to use the NORMSDIST function of Excel, we must standardize our random variables first. And so, we have, 𝑧1 = 11 − 10 = 0.5 2 and 𝑧2 = 13.6 − 10 = 1.8. 2 Our desired probability can be expressed therefore as 𝑃(0.5 < 𝑧 < 1.8). Now, we can determine this probability by entering the syntax for computing 𝑃(𝑧 < 1.8) − 𝑃(𝑧 < 0.5), that is, From here we see that 𝑃(0.5 < 𝑧 < 1.8) = 0.2726. Remark. Besides the NORMSDIST function of Excel, there is also the NORMSINV function. This inverse function gives the standard normal variable given the area under the normal curve. Example 2.2.5. Given that 𝑃(𝑧 < 𝑘) = 0.9049. Find 𝑘. Solution to Example 2.2.5 In this problem, we are tasked to find the value 𝑘 that corresponds the 𝑧-score that gives an area of 0.9049 to its left. To illustrate this, we have the following graph: 11 𝑓(𝑧) 𝑃(𝑧 < 𝑘) = 0.9049 −3 −2 −1 0 2 1 3 𝑧=𝑘 Through excel, we can find 𝑧 by using the syntax “=norm.s.inv(0.9049)” in any of the cells of the spreadsheet. This means that 𝑘 = 1.31. Example 2.2.6. Suppose 𝑋~𝑁(0,1). Find the value of 𝑏 given 𝑃(−1.33 ≤ 𝑋 ≤ 𝑏) = 0.6373. Solution to Example 2.2.6 From the given, we see that the random variable 𝑋 meets the criteria for a standard normal random variable. And so, 𝑃(−1.33 ≤ 𝑋 ≤ 𝑏) = 𝑃(−1.33 ≤ 𝑧 ≤ 𝑏) = 0.6373 which implies that 𝑃(−1.33 ≤ 𝑧 ≤ 𝑏) = 𝑃(𝑧 ≤ 𝑏) − 𝑃(𝑧 ≤ −1.33) = 0.6373. Now, after computing for, 𝑃(𝑧 ≤ −1.33), we have 𝑃(−1.33 ≤ 𝑧 ≤ 𝑏) = 𝑃(𝑧 ≤ 𝑏) − 0.0918 = 0.6373, which after some algebra reduces to 𝑃(𝑧 ≤ 𝑏) = 0.7291. Finally, using the NORMSINV function we get 𝑏 ≈ 0.6101. Remark. Recall that the 𝑧-score also indicates the direction and the degree that any given raw score deviates from the mean of the distribution (which is equal to 0) on a scale of 𝜎 units. In this regard, therefore, we can also use the 𝑧-score to compare relative values of quantities from different data set. 12 Example 2.2.7. Different typing skills are required for secretaries depending on whether one is working in a law office, an accounting firm, or for a mathematical research group at a major university. In order to evaluate candidates for those positions, an agency administers 3 distinct standardized typing samples. A time penalty has been incorporated into the scoring of each sample based on the number of typing errors. The mean and standard deviation for each test, together with the scores achieved by Shenika, an applicant, are given in the following table. Law Office Shenika’s Score 141 sec Mean 180 sec Standard Deviation 30 sec Accounting Firm 7 min 10 min 2 min Math Research Group 33 min 26 min 5 min Where should Shenika be placed? Solution to Example 2.2.7 To compare these three set of data amongst each other, we standardize the values of Shenika’s scores. That is, Shenika’s Law Office 𝑧-score: 𝑧1 = 141−180 30 Shenika’s Accounting Firm 𝑧-score: 𝑧2 = = −1.3 7−10 2 Shenika’s Math Research Group 𝑧-score: 𝑧3 = = −1.5 33−26 5 = 1.4 Clearly, Shenika is best fit for a secretarial job in the mathematical research group. Example 2.2.8. Assuming that the distribution of heights of all female grade 11 students can be modeled well by a normal curve with a mean of 1620 mm and a standard deviation of 50 mm. Find out the a) proportion of grade 11 students shorter than 1550 mm, b) taller than 1650 mm, c) the height of a grade 11 student for which 10% of the students are shorter than it, and last, d) the height of a female grade 11 student for which 75% of the students are taller than it. Solution to Example 2.2.8 a) Let 𝑋 represent the distribution of the heights of all female grade 11 students. Given that 𝜇 = 1620 and 𝜎 = 50, 𝑃(𝑋 < 1550) = 𝑃(𝑧 < −1.4) = 0.0808. b) 𝑃(𝑋 > 1650) = 1 − 𝑃(𝑋 < 1650) = 1 − 𝑃(𝑧 < 0.6) = 0.2743 c) The question can be visualized through the graph found on the next page 13 10% −3 −1 −2 1 0 3 2 𝑋 =? Note that 𝑃(𝑧 < 𝑘) = 0.10 if and only if 𝑘 = −1.2816. Now, converting this 𝑧-score to its equivalent normal random variable value we have, 𝑋 = −1.2186(50) + 1620 𝑋 = 1559.07 mm. d) The height of a female grade 11 student for which 75% of the students are taller than it corresponds to the random variable 𝑋 such that the area on the left of it is 25%. Now, using the same approach we used in the previous problem, we have: 𝑃(𝑧 < 𝑘) = 0.25 ⟺ 𝑘 = 0.6745 which means that 𝑋 = −0.6745(50) + 1620 𝑋 = 1586.28 mm. Supplementary Exercises (Formative Test) 1. Assume that 𝑋 is a normally distributed random variable and 𝑧 is the corresponding standard normal variable. Complete the entries of the given table below. 𝑥 = 𝑧(𝜎) + 𝜇 200 88 103.2 ? 𝑥−𝜇 𝜎 1.29 ? 3.2 – 2.28 𝑧= 𝜇 𝜎 155 108 52 38.5 35 12 16 9.4 2. Let 𝑋 be normally distributed random variable with the following mean and standard deviation. Draw the normal curve for each random variable by plotting the points that are one, two, and three standard deviations way from the mean. 14 a) 𝜇 = 80, 𝜎 = 15 Note: The shaded region indicates the interval (65-95) is within 1-standard deviation. 15 While 50-100, is within 2-standard deviation and 35-125 is within 3-sd. b) 𝜇 = 125, 𝜎 = 20 c) 𝜇 = 20, 𝜎=6 3. A normally distributed random variable has a mean of 449. a) If a score of 325 has a standard normal score −1.38, compute for the variance of 𝑋. Ans. 89.86 b) If a score of 404 is three standard deviations below the mean, find the standard deviation of 𝑋. c) If a score of 433 lies two standard deviations above the mean, find the variance of 𝑋. For numbers 4 to 5: Consider a standard normal random variable with mean 𝜇 = 0 and standard deviation 𝜎 = 1. Find the area of the shade region. 4. 5. Ans. P(x<2.18) = 0.9854 6. Find the probabilities associated with the standard normal random variable 𝑧. a) 𝑃( 𝑧 < 2.18) Ans. 0.9854 b) 𝑃( 𝑧 > 1.08) c) 𝑃( −2.14 < 𝑧 < 3.02) d) 𝑃( 𝑧 < −1.78) 7. Determine the value of 𝑘. a) 𝑃( 𝑧 < 𝑘) = 0.9500 Ans. 1.645 b) 𝑃( 𝑧 > 𝑘) = 0.8670 c) 𝑃(−1.5 < 𝑧 < 𝑘) = 0.9 15 8. The office for admission of AUC College found out that the IQ of incoming 1200 freshmen normally distributed with a mean of 108 and a standard deviation of 10. According to Resing and Blok (2002), IQ can be interpreted as: IQ Score > 130 121 – 130 111 – 120 90 – 110 80 – 89 70 – 79 Interpretation Very gifted Gifted Above average intelligence Average intelligence Below average intelligence Cognitively impaired The school administration is planning to organize different programs that will be beneficial to their students. In analyzing the IQ scores, they want to answer the following questions: a) If a freshman is selected at random to become student assistant, what is the probability of selecting a student with an IQ between 90 and 120? Ans. P(90<x<120)=0.8490 b) How many students have an average IQ or lower? Ans. 696 student (round-up) c) If all gifted and very gifted students will be given scholarships, how much budget is needed if each scholar is expected to receive 20,000 pesos per year? Ans. 3,323,200 pesos d) If all students with an IQ of 87 and lower will be required to attend the remedial program, how many are they? Ans. 22 students (round-up) e) Considering the IQ results, the school administrator is also planning to offer additional math courses to the top 20%. What should be the IQ score of the students to be qualified to take the additional math course? Ans. 116.42 IQ score 9. The average weekly income of 1,500 workers is 1,500 pesos with a standard deviation of 80 pesos. Assuming that the weekly incomes are normally distributed, find the number of workers who earn: a) between 1,440 pesos and 1,640 pesos. Ans. 1100 workers b) at most 1,350 pesos. Ans. 46 workers c) At least how much should a worker receive to be included in the top 10% earners? Ans. 1,602.52 pesos 10. It is known that in a company, the average time required to process invoices is 8 days with a 16 standard deviation of 36 hours. If the processing time is normally distributed, what proportion of the invoices is processed between 6 and 11 days? Ans. 88.6% - End of the Lecture Transcript - 17