Class Notes 2019
Department of Statistics
WST143 – Foundation Mathematical Statistics
Name & Surname: _______________________________
Student number: ________________________________
Cellphone number: ______________________________
E-mail address: _________________________________
“Work hard in silence, let success make the noise”
Copyright Reserved
Table of Contents
Introduction: Distributions .................................................................................................................................... 4
Chapter 6 – Continuous Probability Distributions .......................................................................................... 6
6.1 Continuous Uniform Probability Distribution ....................................................................................... 7
6.2 Normal Probability Distribution ................................................................................................................ 9
6.3 The F distribution ....................................................................................................................................... 18
Lab session component 1: Creating a graph of a probability density function in Excel ................ 19
L1.1: Creating and modifying charts ....................................................................................................................... 19
L1.2: Self-evaluation Exercise 1............................................................................................................................... 20
Lab session component 2: Probability......................................................................................................... 20
L2.1: Rand() and Randbetween() functions ............................................................................................................ 20
L2.2: Random number generator............................................................................................................................ 21
L2.3: Self-evaluation Exercise 2a............................................................................................................................. 22
L2.4: Normal probabilities and percentiles in Excel ................................................................................................ 24
L2.4.1: Normal probabilities.................................................................................................................................... 24
L2.4.2: Normal percentiles ...................................................................................................................................... 24
L2.5: Self-evaluation Exercise 2b ............................................................................................................................ 25
L2.6: Percentile estimates ....................................................................................................................................... 26
L2.7: Self-evaluation Exercise 2c ............................................................................................................................. 26
Chapter 6 Self Evaluation Questions ............................................................................................................ 27
Chapter 7: Sampling and Sampling Distributions ......................................................................................... 28
7.3 Point Estimation ......................................................................................................................................... 28
7.4 Introduction to Sampling Distributions ................................................................................................ 29
̅ : ..................................................................................................................... 30
7.5 Sampling distribution of 𝑿
̅ ....................................................................................................................... 35
7.6 Sampling Distribution of 𝒑
Additional notes on absolute values ............................................................................................................ 38
Chapter 7 Self Evaluation Questions ............................................................................................................ 39
Chapter 8: Interval Estimation ............................................................................................................................ 44
8.1 Population mean: 𝝈 known ...................................................................................................................... 44
8.2 Population mean: 𝝈 unknown ................................................................................................................. 49
8.3 Determining the Sample Size .................................................................................................................. 54
8.4 Population proportion ............................................................................................................................... 55
Lab session component 3: Confidence intervals in Excel ...................................................................... 57
L3.1: Confidence intervals for the population mean (𝝈 known case) .................................................................... 57
L3.2: Confidence intervals for the population mean (𝝈 unknown case) ................................................................ 57
L3.3: Confidence intervals for the population proportion ...................................................................................... 58
L3.4: Self-evaluation Exercise 3............................................................................................................................... 58
Chapter 8 Self Evaluation Questions ............................................................................................................ 58
Chapter 9 Hypothesis tests ................................................................................................................................ 61
9.1 Developing the null and alternative hypotheses................................................................................ 61
Copyright Reserved
2
9.2 Type I and Type II Errors .......................................................................................................................... 62
9.3 Population mean: 𝝈 known ...................................................................................................................... 62
9.4 Population mean: 𝝈 unknown ................................................................................................................. 66
9.5 Population proportion ............................................................................................................................... 69
Lab session component 4: Hypothesis testing in Excel ......................................................................... 71
L4.1: Hypothesis tests for the population mean (𝝈 known case) ........................................................................... 71
L4.2: Self-evaluation Exercise 4............................................................................................................................... 72
Chapter 9 Self Evaluation Questions ............................................................................................................ 73
Chapter 10: Statistical inference about means with two populations ..................................................... 75
10.1 Inferences about the difference between two population means: 𝝈𝟏 and 𝝈𝟐 known ............. 75
10.2 Inferences about the difference between two population means: 𝝈𝟏 and 𝝈𝟐 unknown ........ 77
10.3 The Difference Between Two Population Means: Matched pairs ................................................ 80
10.4 The Difference Between Two Population Proportions ................................................................... 81
Chapter 10 Self Evaluation Questions .......................................................................................................... 83
Chapter 11: Statistical inferences about two population variances......................................................... 85
11.2 The difference between two population variances ......................................................................... 85
Hypothesis Testing Summary ............................................................................................................................ 87
Hypothesis Testing Tree Diagram .............................................................................................................................. 88
Cumulative probabilities for the standard normal distribution ................................................................. 89
Probability tables for the F distribution .................................................................................................................... 93
WST143 Formula list ............................................................................................................................................. 98
Optimisation Techniques ..................................................................................................................................... 99
Chapter 2: Differentiation ................................................................................................................................. 99
Chapter 3: Integration ..................................................................................................................................... 116
Expected values ............................................................................................................................................... 132
Moment Generating Functions ..................................................................................................................... 133
Solutions to Self Evaluation Questions ......................................................................................................... 137
Chapter 6 ............................................................................................................................................................ 137
Chapter 7 ............................................................................................................................................................ 139
Chapter 8 ............................................................................................................................................................ 141
Chapter 9 ............................................................................................................................................................ 142
Chapter 10 .......................................................................................................................................................... 143
Revision Exercise – Chapter 5.......................................................................................................................... 144
Revision Exercise – Chapter 5 – Solution ..................................................................................................... 145
Additional Exercises ........................................................................................................................................... 147
Chapter 6 ........................................................................................................................................................... 147
Chapter 7 ............................................................................................................................................................ 150
Chapter 8 ............................................................................................................................................................ 151
"6 months of genuine focus and alignment can put you 5 years ahead in life. Don't underestimate the power of
consistency. You have what it takes to become the best. Harness your power. Exceed your expectation."
Copyright Reserved
3
Introduction: Distributions
What do we know?
What about
these?????
Copyright Reserved
4
Let us investigate the following graphical presentation of the distribution of variables
Discrete variable
Continuous variable
Consider the experiment of tossing
two coins and let
Plant scientists have developed a new variety of corn with increased
amounts of protein. In a test to see what the effect on the growth of
chickens is, an experimental group of 20 one-day-old male chicks
was fed a ration containing the new corn. The following table
summarises the weight gained (in grams) after 21 days (grouped
data), as well as descriptive statistics calculated on the actual data
set
𝑿 = the number of heads
p(x)
0.6
0.4
0.2
0
0
1
2
Is the above presentation the
same as:
Weight (in
grams)
(300 ; 330]
(330 ; 360]
(360 ; 390]
(390 ; 420]
(420 ; 450]
(450 ; 480]
Frequency (number of
chicks)
2
1
2
9
4
2
Relative
frequency
0.1
0.05
0.1
0.45
0.2
0.1
20
Draw any suitable graph to estimate the percentage of
chickens that gained at least 435g. How could we have used
the following histogram to answer the question?
and…
Could you have said an estimate of the percentage of chickens that
gained at least 435g is 0.2 + 0.1? Why/why not?
Why not?
If we reason that 0.2 is the relative frequency of a chicken gaining anything between 420 and 450 grams
AND that the relative frequency for it to gain between 420 and 435 grams IS THE SAME as the relative
frequency to gain between 435 and 450 grams, what will a reasonable relative frequency be to gain between
435 and 450 grams?
Copyright Reserved
5
Chapter 6 – Continuous Probability Distributions
Introduction
In WST133 we focused on discrete random variables and three discrete probability distributions,
namely the binomial, discrete uniform and geometric distributions. We will now shift our attention to
continuous random variables, their properties and a few continuous probability distributions.
The fundamental difference between discrete and continuous random variables is the way in which
probabilities are calculated. For a discrete random variable 𝑋, the probability mass function 𝑝(𝑥)
is used to calculate the probability that the random variable takes on a specific value. On the other
hand, for a continuous random variable 𝑋, the probability density function 𝑓(𝑥) does not directly
provide probabilities. The probability that a random variable takes on a value in a specific interval of
values, for example the interval [𝑎, 𝑏], can be calculated by finding the area under the function 𝑓(𝑥)
between 𝑎 and 𝑏. This definition implies that the probability of a continuous random variable taking
on a specific value is zero since the area under 𝑓(𝑥) at a particular point is zero.
Comparison between discrete and continuous probability distributions:
Discrete probability distribution
The probability mass function 𝑝(𝑥) provides
the probability that the random variable
assumes a particular value
Continuous probability distribution
The probability density function 𝑓(𝑥) does
NOT directly provide probabilities.
0 ≤ 𝑝(𝑥) ≤ 1
𝑓(𝑥) ≥ 0 for all 𝑥, −∞ < 𝑥 < ∞
for all 𝑥
The AREA under the probability density
function 𝑓(𝑥) for values of 𝑋: − ∞ < 𝑥 < ∞
equals one.
∑ 𝑝(𝑥) = 1
𝑥
Class exercise:
A supplier of paraffin has a 150𝑙 tank that is filled at the beginning of each week. His weekly
demand shows a relative frequency behaviour that increases steadily up to 100𝑙 and then levels
off between 100 and 150𝑙. If 𝑌 denotes the weekly demand in hundreds of litres, the relative
frequency of demand can be modelled by
𝑦,
𝑓(𝑦) = {1,
0,
a.
b.
c.
d.
𝑓𝑜𝑟 0 ≤ 𝑦 ≤ 1
𝑓𝑜𝑟 1 ≤ 𝑦 ≤ 1.5
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
Represent 𝒇(𝒚) graphically
Use geometry to verify that 𝒇(𝒚) is indeed a probability density function
Find 𝑷(𝟎 ≤ 𝒀 ≤ 𝟎. 𝟓)
Find 𝑷(𝟎. 𝟓 ≤ 𝒀 ≤ 𝟏. 𝟐)
Copyright Reserved
6
6.1 Continuous Uniform Probability Distribution
If 𝑎 < 𝑏, a random variable 𝑋 is said to have a continuous uniform probability distribution on the
interval (𝑎, 𝑏) if and only if the density function of 𝑋 is:
1
𝑓(𝑥) = {𝑏 − 𝑎
0
for 𝑎 ≤ 𝑥 ≤ 𝑏
elsewhere
“Short hand”-notation: 𝑋 ~ 𝑢𝑛𝑖(𝑎, 𝑏)
𝑎+𝑏
2
(𝑏 − 𝑎)2
𝑣𝑎𝑟(𝑋) =
12
𝐸(𝑋) =
Example (p 253):
The flight time from Chicago to New York is uniformly distributed between 120 and 140 minutes.
Let 𝑋 = the flight time (in minutes) of an airplane traveling from Chicago to New York.
𝑋 ~ 𝑢𝑛𝑖(120,140)
1
1
𝑓(𝑥) = {140 − 120 = 20
0
for 120 ≤ 𝑥 ≤ 140
elsewhere
Note: 𝑓(𝑥) is called the probability density function
Questions:
1. Calculate the probability that the flight time will be between 120 and 130 minutes.
1
1
𝑃(120 < 𝑋 < 130) = 𝑃(120 ≤ 𝑋 ≤ 130) = ∆𝑥 ∙ 𝑓(𝑥) = (130 − 120) ( ) = (10) ( ) = 0.5
20
20
2. Calculate the probability that the flight time will be 125 minutes.
𝑃(𝑋 = 125) = 0
Note 1: 𝑃(𝑋 = 𝑎) = 0 for any value of 𝑎, a constant
Note 2: 𝑃(𝑎 ≤ 𝑋 ≤ 𝑏)
= 𝑃(𝑋 = 𝑎) + 𝑃(𝑎 < 𝑋 < 𝑏) + 𝑃(𝑋 = 𝑏)
= 0 + 𝑃(𝑎 < 𝑋 < 𝑏) + 0
= 𝑃(𝑎 < 𝑋 < 𝑏)
Therefore, 𝑃(𝑎 ≤ 𝑋 ≤ 𝑏) = 𝑃(𝑎 < 𝑋 < 𝑏).
Copyright Reserved
7
3. Calculate the probability that the flight time will be between 125 and 150 minutes.
𝑃(125 < 𝑋 < 150) = 𝑃(125 < 𝑋 < 140) + 𝑃(140 < 𝑋 < 150)
= ∆𝑥 ∙ 𝑓(𝑥) + ∆𝑥 ∙ 𝑓(𝑥)
1
= (15) ( ) + (10)(0)
20
= 0.75
4. The 75th percentile of 𝑋 is:
𝑃(120 < 𝑋 < 𝑥) = 0.75
1
(𝑥 − 120) ( ) = 0.75
20
𝑥 − 120 = (0.75)(20)
𝑥 = 135
∴ 𝑃75 = 135
5. Calculate the expected value, variance and standard deviation of 𝑋:
𝐸(𝑋) =
𝑎 + 𝑏 120 + 140
=
= 130
2
2
𝑉𝑎𝑟(𝑋) =
(𝑏 − 𝑎)2 (140 − 120)2
=
= 33. 3̇
12
12
𝑆𝑡𝑑𝑒𝑣(𝑋) = √33. 3̇ = 5.77
Example:
A random variable 𝑋 is uniformly distributed between 10 and 20.
a) Sketch:
b) 𝑃(𝑋 < 15) = ∆𝑥 ∙ 𝑓(𝑥) = (15 − 10)(0.1) = 0.5
c) 𝑃(12 < 𝑋 < 18) = ∆𝑥 ∙ 𝑓(𝑥) = (18 − 12)(0.1) = 0.6
d) 𝐸(𝑋) =
𝑎+𝑏
2
e) 𝑉𝑎𝑟(𝑋) =
=
10+20
(𝑏−𝑎)2
12
2
=
= 15
(20−10)2
12
= 8. 3̇
f) 𝑆𝑡𝑑𝑒𝑣(𝑋) = √8. 3̇ = 2.8868
More examples: Recommended material B2 (Williams et al, pg 256) – Exercises 1 – 6
Copyright Reserved
8
6.2 Normal Probability Distribution
A random variable 𝑌 is said to have a normal probability distribution if and only if, for 𝜎 > 0 and
−∞ < 𝑦 < ∞ the density function of 𝑌 is
𝑓(𝑦) =
𝜇
𝜎2
𝜋
𝑒
=
=
=
=
1
𝜎√2𝜋
−(𝑦−𝜇)2
𝑒 (2𝜎2 )
, −∞ < 𝑦 < ∞
𝑚𝑒𝑎𝑛
𝑣𝑎𝑟𝑖𝑎𝑛𝑐𝑒
3.1416
2.7183
“Short-hand” notation: 𝑌~𝑁(𝜇, 𝜎 2 )
Characteristics:
1. The entire family for normal probability distributions can be told apart by their means and
standard deviations/variances.
2. The highest point on the normal curve is at the:
(i) Mean (𝜇)
(ii) Median (𝑃50 )
(iii) Mode
3. The mean 𝜇 can be any numerical value:
4. It is symmetric around 𝜇, and the tails of the curve extend to infinity in both directions and
theoretically never touch the horizontal axis.
5. Larger 𝜎 larger variability flatter curves.
6. a. The total area under the curve is 1.
b. The total area under the curve to the left of 𝜇 is always 0.5.
c. The total area under the curve to the right of μ is always 0.5.
Note: Since the normal probability distribution is symmetric, the empirical rule is valid. In
fact, the empirical rule can be derived from the standard normal distribution. Try to do
this.
Copyright Reserved
9
Standard normal probability distribution
If 𝑍 is normally distributed with 𝜇 = 0 and 𝜎 = 1, then 𝑍 is said to have a standard normal
distribution.
𝑍=
𝑋−𝜇
~ 𝑁(0, 1)
𝜎
Tables for the Standard Normal probability distribution are available at the end of the notes
Copyright Reserved
10
Example: Exercise 17 (B2 – pg 271)
Copyright Reserved
11
Using Excel to Compute Standard Normal Probabilities
Syntax:
NORM.S.DIST(𝒛, cumulative) - where 𝑧 is the z-value for which you would like to calculate either
the probability to the left (if cumulative = “True”) or the value of the density function (if cumulative =
“False”).
Note that this function only applies to the standard normal distribution.
Examples:
1. 𝑃(𝑍 < 1) = 𝑃(𝑍 ≤ 1) =
=NORM.S.DIST(1,TRUE)
Answer: 0.8413
2. 𝑃(0 < 𝑍 < 1) = 𝑃(0 ≤ 𝑍 ≤ 1) = 𝑃(𝑍 < 1)– 𝑃(𝑍 < 0) =
=NORM.S.DIST(1,TRUE)-NORM.S.DIST(0.TRUE)
Answer: 0.3413
3. 𝑃(−1 < 𝑍 < 1) = 𝑃(−1 ≤ 𝑍 ≤ 1) = 𝑃(𝑍 < 1)– 𝑃(𝑍 < −1) =
=NORM.S.DIST(1,TRUE)-NORM.S.DIST(-1,TRUE)
Answer: 0.6827
4. 𝑃(𝑍 > 1.58) = 𝑃(𝑍 ≥ 1.58) = 1– 𝑃(𝑍 < 1.58) =
=1-NORM.S.DIST(1.58,TRUE)
Answer: 0.0571
Copyright Reserved
12
5. 𝑃(𝑍 < −0.498) = 𝑃(𝑍 < −0.50) =
Note: -0.498 is rounded to -0.50, but -0.492, for example, would be rounded to -0.49.
=NORM.S.DIST(-0.498,TRUE)
Answer: 0.3092
6. 𝑃(𝑍 > 1.47) = 1– 𝑃(𝑍 < 1.47) =
=1-NORM.S.DIST(1.47,TRUE)
Answer: 0.0708
7. 𝑃(𝑍 < −1.47) =
=NORM.S.DIST(-1.47,TRUE)
Answer: 0.0708
Note: The answers to questions 6 and 7 are the same due to symmetry.
8. 𝑃(𝑍 < −3.3) = 𝑃(𝑍 ≤ −3.3) ≈ 0
Recall that we have an outlier when 𝑧 < −3 or 𝑧 > 3. Therefore, the probability that 𝑧 is less than
−3.3 is approximately zero.
=NORM.S.DIST(-3.3,TRUE)
Answer: 0.000483
Copyright Reserved
13
The Inverse Standard Normal distribution
Given: The area under the curve
Calculate: z-value (i.e. a percentile for a standard normal random variable)
Syntax:
NORM.S.INV(probability) – where the probability that is given to the function is the area under
the curve to the left of the required z-value. Note that this function returns a value from the
standard normal distribution.
Examples:
1.
The area to the left of 𝑧 is 0.6331.
=NORM.S.INV(0.6331)
2.
Calculate the z-value so that the probability to get a larger z-value is 0.1.
=NORM.S.INV(0.9)
3.
Answer: 0.3401
Answer: 1.28155
The area to the right of 𝑧 is 0.119.
=NORM.S.INV(1-0.119) OR =NORM.S.INV(0.881)
4.
Answer: 1.1800
The area to the left of 𝑧 is 0.33.
=NORM.S.INV(0.33)
Answer: -0.4399
Copyright Reserved
14
Percentiles
Recall that in Chapter 3 of the textbook we calculated the 𝑝𝑡ℎ percentile for a sample of size 𝑛 by
first calculating the position of the percentile. This was done by making use of the formula 𝑖 =
𝑝
(100) 𝑛. When finding percentiles of a random variable from a normal distribution we will however
follow a different procedure.
If the 5th percentile is mentioned (for example) then we know that the area to the left of the point is
0.05.
If the 95th percentile is mentioned (for example) then we know that the area to the left of the point
is 0.95.
Once we know what the area to the left of a point is, we can get the corresponding z-value. We
can then calculate the percentile using this z-value.
The corresponding z-value to the 5th percentile:
The corresponding z-value to the 95th percentile:
Example:
Suppose 𝜇 = 100 and 𝜎 = 5.
For the 5th percentile: 𝑧 =
𝑥−𝜇
For the 95th percentile: 𝑧 =
𝜎
, ∴ −1.645 =
𝑥−𝜇
𝜎
, ∴ 1.645 =
𝑥−100
, ∴ 𝑥 = (−1.645)(5) + 100 = 91.775.
5
𝑥−100
5
, ∴ 𝑥 = (1.645)(5) + 100 = 108.225.
These 𝑥 values are the 5th and 95th percentiles respectively.
Copyright Reserved
15
Computing probabilities for any Normal Probability Distribution:
𝑋 = number of miles a set of tires will last
Given:
i.
Data is normally distributed
ii.
𝜇 = 36 500 miles
iii.
𝜎 = 5 000 miles
Question 1:
Calculate the probability that a rear tire will not last more than 20 000 miles:
Answer:
𝑥−𝜇
20 000−36 500
First we standardize the 𝑥 value: 𝑍 = 𝜎 =
= −3.3.
5 000
Therefore, 𝑃(𝑋 < 20 000) = 𝑃(𝑍 < −3.3) ≈ 0 (using the properties of outliers)
Using Excel:
𝑃(𝑋 < 20 000) =
Excel: =NORM.DIST(20000, 36500, 5000, TRUE)
Answer:
0.0005
Question 2:
What percentage of the tires can be expected to last more than 40 000 miles?
Answer:
𝑥−𝜇
40 000−36 500
First we standardize the 𝑥 value: 𝑧 = 𝜎 =
= 0.7.
5 000
Therefore, 𝑃(𝑋 > 40 000) = 𝑃(𝑍 > 0.70) = 1 − 𝑃(𝑍 < 0.70) = 1 − 0.7580 = 0.242
Using Excel:
𝑃(𝑋 > 40 000) = 1 − 𝑃(𝑋 < 40 000) =
Excel: = 1 – NORM.DIST(40000, 36500, 5000, TRUE)
Answer:
0.24196
Copyright Reserved
16
Question 3:
Calculate the probability that a tire’s lifetime is between 20 000 and 40 000 miles:
Answer:
First we standardize the 𝑥 values:
𝑧=
𝑥−𝜇
𝜎
=
40 000−36 500
5 000
= 0.7 and 𝑧 =
𝑥−𝜇
𝜎
=
20 000−36 500
5 000
= −3.3
Therefore, 𝑃(20 000 < 𝑋 < 40 000) = 𝑃(−3.3 < 𝑍 < 0.70) = 𝑃(𝑍 < 0.70) − 𝑃(𝑍 < −3.3)
= 0.7580 − 0.0005 = 0.7575
Using Excel:
𝑃(20 000 < 𝑋 < 40 000) = 𝑃(𝑋 < 40 000) − 𝑃(𝑋 < 20000) =
Excel: = NORM.DIST(40000, 36500, 5000, TRUE) – NORM.DIST(20000, 36500, 5000, TRUE)
Answer:
0.7576
Question 4:
How long must the guarantee period be so that less than 2.5% of the tires that are under
guarantee will be replaced?
Answer:
If we know the area to the left of 𝑧 equals 0.025, we can find the corresponding z-value:
𝑍=
𝑋−𝜇
𝜎
,
∴ −1.96 =
𝑥−36 500
5 000
Now we solve for 𝑥 : 𝑥 = (−1.96)(5 000) + 36 500 = 26 700
Using Excel:
Excel: =NORM.INV(0.025, 36500, 5000)
Answer:
26700.19
Copyright Reserved
17
Question 5:
Compute the minimum tire mileage for the top 2.5% of rear tires.
Answer:
If we know the area to the left of 𝑧 equals 0.975, we can find the corresponding z-value:
𝑍=
𝑋−𝜇
𝜎
,
∴ 1.96 =
𝑥−36 500
5 000
Now we solve for 𝑥 : 𝑥 = (1.96)(5 000) + 36 500 = 46 300
Using Excel:
Excel: =NORM.INV(0.975,36500,5000)
Answer:
46299.81
6.3 The F distribution
The F distribution is a positively skewed distribution that can only take on positive values. The
shape of the distribution is fully defined by two parameters, namely 𝜐1 and 𝜐2 , known respectively
as the numerator and denominator degrees of freedom.
Notes:
The following special relationship exists for F values
𝐹𝜐1 ,𝜐2 ;𝛼 =
1
𝐹𝜐2 ,𝜐1;1−𝛼
The F distribution has important underlying assumptions. We however will not consider these
assumptions and will only focus on the application of the distribution to testing hypotheses
regarding the variances of two independent samples. The relevant assumptions for this test are
stated in Chapter 11.
Copyright Reserved
18
Lab session component 1: Creating a graph of a probability density function in Excel
Outcomes:
At the end of this section you should be able to
create a graph of a given function in Excel, and
use the graph created in Excel to verify that a function is a valid probability density
function, and
be able to create graphs of probability density functions for illustration purposes in your
project work assignments.
L1.1: Creating and modifying charts
A graph of a probability density function can be created in Excel by following a few simple steps.
The process will be explained using an example. Consider the following probability density
function:
3 2
0≤𝑦≤1
𝑓(𝑦) = {2 𝑦 + 𝑦,
0,
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
In order to plot the density function, we need to find some points that lie on the density curve. In
our example, the density function is defined for values of y in the interval [ 0,1 ] . We therefore
need to calculate values of the density function at points within this interval. The calculation of
these values at a few selected points is shown in Figure 1.
(a) Formulae used to calculate points on
the density curve.
(b) Calculated points on
the density curve.
Figure 1: Calculation of points needed to plot the density curve.
After calculating points on the density curve, we now need to decide whether to use smooth or
straight lines to draw the density curve. From the form of the function itself, it is clear that the
density curve is not a straight line and should be drawn using a smooth line. This can be done by
choosing the ‘Smooth Lines’ option under the ‘Scatter’ option. The resulting graph is shown in
Figure fig: smooth lines and density function curve. It is important to note that the ‘Straight Lines’
option should be used if the density function is linear. If the density function is curved, a more
accurate graph can be obtained by plotting more points.
Figure 2: The ‘Smooth Lines’ option and plotted density curve.
Copyright Reserved
19
L1.2: Self-evaluation Exercise 1
Use Excel to plot the following functions, then use geometry to verify that the functions
are density functions.
1.
𝑦,
𝑓(𝑦) = {1,
0,
0≤𝑦≤1
1 < 𝑦 < 1.5
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
2.
𝑓(𝑦) = {
6𝑦(1 − 𝑦),
0,
0≤𝑦≤1
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
3.
𝑓(𝑦) = {
6𝑦(1 − 𝑦),
0,
−1 ≤ 𝑦 ≤ 2
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
4.
𝑓(𝑦) = {
𝑦(1 − 𝑦) + 1,
0,
−1 ≤ 𝑦 ≤ 2
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
Lab session component 2: Probability
Outcomes:
At the end of this section you should be able to
generate ‘observations’ using the rand() and randbetween() functions,
generate ‘observations’ from different distributions using Excel's Random Number
Generator,
calculate empirical probabilities and percentiles for samples generated using Excel's
Random Number Generator,
calculate normal probabilities for values using Excel's norm.s.dist() and norm.dist()
functions,
plot the probability density function of a 𝑁(𝜇 , 𝜎 2 ) distribution,
calculate normal percentiles using Excel's norm.s.inv() and norm.inv() functions. and
use the norm.s.dist(), norm.dist(), norm.s.inv() and norm.inv() to calculate critical values
and p-values in the context of hypothesis testing for your project work assignments.
L2.1: Rand() and Randbetween() functions
You should already be familiar with the rand() function that was introduced to you in the WST 133
Practical Guide. This function randomly generates values between 0 and 1. However, if we are
interested in generating random integers between two specified values, we cannot use this
function without making some adjustments. An easier way of accomplishing this is by making use
of the randbetween() function. In this function we need to specify the minimum and maximum
values that we want generated.
Example formula
What it does
=randbetween(0,10)
Generates random integers between 0 and 10, inclusive
=randbetween(0,10)
Generates random integers between 5 and 50, inclusive
Once you have generated the necessary values, remember to ‘lock’ the numbers by selecting
‘Manual’ from the ‘Calculation Options’ button in the ‘Formulas’ tab. If you do not do this, the
values will change each time you change something in Excel.
Copyright Reserved
20
L2.2: Random number generator
The Random Number Generation analysis tool fills a range of cells with independent random
numbers that are drawn from one of several distributions. You can characterize the subjects in a
population with a probability distribution. For example, you can use a normal distribution to
characterize the population of individuals' heights, or you can use a Bernoulli distribution of two
possible outcomes to characterize the population of coin-flip results. We will not focus on the
theory of the different distributions in this guide. For now we only want to become familiar with how
the Random Number Generator works. We will explain this by making use of an example.
Say we would like to generate 10 values from a Normal (bell-shaped) distribution with mean 0 and
variance 1.
1. On the ‘Data’ tab, in the ‘Analysis’ group, click ‘Data Analysis’.
2. In the ‘Analysis Tools’ box, click ‘Random Number Generator’, and then click OK. On the
‘Data’ tab, in the ‘Analysis’ group, click ‘Data Analysis’. The dialog box that subsequently
appears is shown below.
3. The ‘Number of Variables’ box can be interpreted as the number of samples we would like to
generate. In this case, we are only interested in generating 1 sample of size 10. We therefore
enter ‘1’ in this box.
4. The ‘Number of Random Numbers’ box can be interpreted as the number of observations we
are interested in. In this case we enter ‘10’.
5. Next we need to choose the appropriate distribution from which to generate values. Our
options here include ‘Uniform’, ‘Bernoulli’, ‘Binomial’, ‘Normal’, ‘Poisson’, ‘Patterned’ and
‘Discrete’. Each one of these options require specific parameters to be entered. For now, we
will tell you which distribution to use as well as the required parameters. For our example,
choose ‘Normal’ with mean ‘0’ and standard deviation ‘1’.
6. The ‘Random Seed’ value is optional. If we leave this box empty, the numbers that are
generated will be completely random. If we however specify a seed value, the resulting random
numbers can be obtained again in future by specifying the same parameters and seed value
again. To ensure that you obtain the same random numbers as us, specify a seed value of ‘5’.
7. The ‘Output options’ are the same as we had with the ‘Histogram’ tool in WST133.
8. Click on ‘OK’. The final view of the dialog box as well as the random numbers obtained is
shown on the next page.
Copyright Reserved
21
If we wanted to generate 2 samples of size 10 each, sample 1 would have been placed in column
A while sample 2 would be placed in column B. Play around with this generator and see how
changing different settings will affect your output.
L2.3: Self-evaluation Exercise 2a
1. Use the randbetween() function to generate 30 values between 0 and 5. Create a
bar chart to show how the values are distributed.
2. Use the ‘Random Number Generator’ to generate 10, 100, 1000 and 10000 values from a
normal distribution with a mean of 10 and a variance of 16. Repeat this process using seed
values of 26, 52, 15 and 8. In each case, use the ‘Histogram’ tool to create a frequency
distribution and a chart of the observations. Comment on what you observe.
3. For each of the samples generated in question 2, calculate the mean and variance. Comment
on what you observe
4. For each of the samples generated in question 2, calculate the percentage of observations that
lie within one, two, three and four standard deviation of the mean. Complete the following
tables and comment on what you observe.
Copyright Reserved
22
Seed = 26
𝒏
Number of standard deviations
1
2
3
4
10
100
1000
10000
Seed = 52
𝒏
Number of standard deviations
1
2
3
4
10
100
1000
10000
Seed = 15
𝒏
Number of standard deviations
1
2
3
4
10
100
1000
10000
Seed = 8
𝒏
Number of standard deviations
1
2
3
4
10
100
1000
10000
Copyright Reserved
23
L2.4: Normal probabilities and percentiles in Excel
L2.4.1: Normal probabilities
Given a value from a normal distribution, Excel can calculate the probability of obtaining an
observation smaller than the specified value. When dealing with a standard normal distribution,
this is done by making use of the norm.s.dist() function while the norm.dist() function is used for
all other normal distributions. The syntax for the norm.s.dist() function is given by
NORM.S.DIST(z, cumulative)
where z is the value for which you want the probability and cumulative can be set to either TRUE
or FALSE .
Example:
Let 𝑍~𝑁(0,1). Then the 𝑃(𝑍 < 2.16) is calculated using the Excel code norm.s.dist(2.16,TRUE)
as 0.98461. The value of the density function at the point 2.16 is calculated by
norm.s.dist(2.16, FALSE) as 0.03871. When cumulative is set to FALSE, the norm.s.inv()
function can therefore be used to plot the density function.
The syntax for the norm.dist() function is given by
NORM.DIST(x,mean,standard_dev,cumulative)
where x is the value for which you want the probability, mean and standard_dev specify the
parameters of the required normal distribution and cumulative can again be set to either TRUE or
FALSE.
L2.4.2: Normal percentiles
Percentiles for the normal distribution can be calculated in Excel using the norm.s.inv() function in
the case of the standard normal distribution, and the norm.inv() function in the case of all other
normal distributions. The syntax for the norm.s.inv() function is given by
NORM.S.INV(probability)
where probability specifies the percentile to be calculated.
Example:
Let 𝑍~𝑁(0,1). Then the 80th percentile is calculated using the Excel code norm.s.inv(0.8) as
0.84162 .
The syntax for the norm.inv() function is given by
NORM.INV( probability,mean,standard_dev )
where probability specifies the percentile to be calculated and mean and standard_dev specify
the parameters of the required normal distribution.
Figure 3: Summary of the norm.s.dist(), norm.dist(), norm.s.inv() and norm.inv() functions.
Copyright Reserved
24
L2.5: Self-evaluation Exercise 2b
1.
Plot the density function for the 𝑍~𝑁(0,1).
Using the appropriate Excel functions, calculate 𝑃(𝑍 < 3.67).
[Solution: 0.999879]
Using the appropriate Excel functions, calculate 𝑃(𝑍 > −1.43).
[Solution: 0.923641]
Using the appropriate Excel functions, calculate 𝑃( −1.75 < 𝑍 < 0.89).
[Solution: 0.773208]
Using the appropriate Excel functions, calculate the 70th percentile.
[Solution: 0.524401]
2. Plot the density function for the 𝑋~𝑁(25,25).
Using the appropriate Excel functions, calculate 𝑃(𝑋 < 23.5).
[Solution: 0.382089]
Using the appropriate Excel functions, calculate the 1 7 th percentile.
[Solution: 20.229174]
3. Plot the density function for the 𝑋~𝑁(25,5).
Using the appropriate Excel functions, calculate 𝑃(𝑋 < 23.5).
[Solution: 0.251167]
Using the appropriate Excel functions, calculate the 17th percentile.
[Solution: 22.866422]
(a) 𝑋~𝑁(25,25)
(b) 𝑋~𝑁(25,5)
Figure 4: Graphs for the density functions given in questions 2 and 3
Copyright Reserved
25
L2.6: Percentile estimates
In Section L2.4.2 we saw how Excel can be used to calculate the theoretical percentiles of a
variable with a normal distribution. We will now explore how Excel can be used to calculate
empirical percentiles when we have a sample of observations available.
The ‘Empirical Data 2018.xlsx’ file (available on ClickUP) will be used to explain this application.
In the worksheet labeled ‘Raw Data’, 250 samples of size 50 are given. These values were
generated from a 𝑈𝑛𝑖𝑓(10,25) distribution. The sample averages (means) were calculated for
each of the different samples. In Section 7.5 you will learn that 𝑋̅~𝑁(𝜇𝑋 , 𝜎 2 ⁄𝑛) since 𝑛 > 30. We
can calculate the theoretical parameters of our original variable 𝑋 as
𝜇𝑋 =
𝑎 + 𝑏 25 − 10
=
= 17.5
2
2
and
𝜎𝑋2 =
(𝑏 − 𝑎)2 (25 − 10)2 225
=
=
= 18.75
12
12
12
Using these values we can now calculate the theoretical distribution of 𝑋̅.
Theoretically, we know that the 75th percentile of 𝑋̅ can be estimated by calculating the 75th
percentile of a 𝑁(17.5,0.375) random variable. Using the norm.inv() function in Excel we find that
𝑥̅ 0.75 ≈ 𝑛𝑜𝑟𝑚. 𝑖𝑛𝑣(0.75,17.5, 𝑆𝑄𝑅𝑇(0.375)) = 17.913039
This percentile can also be estimated from the sample data. We will do this by making use of the
percentile.inc() function. The syntax for this is given as
PERCENTILE.INC(array,k)
where array is the range containing the different 𝑥̅ sample values and k, 0 ≤ 𝑘 ≤ 1, is the
𝑘(100)𝑡ℎ percentile. To get an estimate 𝑥̅̂0.75 for the 75th percentile of 𝑋̅ using the data in the
worksheet labelled ‘Practical 4 data’, we use the following Excel code:
𝑥̅̂0.75 ≈ 𝑃𝐸𝑅𝐶𝐸𝑁𝑇𝐼𝐿𝐸. 𝐼𝑁𝐶(𝐵: 𝐵, 0.75) = 17.90420164
It is clear that the theoretical and empirical estimates are very close to each other. As the sample
size 𝑛 increases, the empirical estimate should approach the theoretical estimate of the percentile.
L2.7: Self-evaluation Exercise 2c
Open the file `Self Evaluation Exercise 2c Data.xlsx'. The values given in this file
were generated from a normal distribution with mean 10 and standard deviation 5.
Various empirical and theoretical values were calculated for this data and the results
are given below. Check that you are able to obtain the same results.
Copyright Reserved
26
Chapter 6 Self Evaluation Questions
Questions 1 to 5 are based on the following information:
The time spent waiting in queues (in minutes) to buy tickets for a soccer match is uniformly
distributed between 25 and 40 minutes.
Let 𝑋 = time (in minutes) spent in queues.
1. The probability density function of 𝑋 is:
1
, 𝑤ℎ𝑒𝑟𝑒 25 ≤ 𝑥 ≤ 40
a) 𝑓(𝑥) = {15
0, 𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
0 , 𝑤ℎ𝑒𝑟𝑒 25 ≤ 𝑥 ≤ 40
b) 𝑓(𝑥) = { 1
, 𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
15
1
,
c) 𝑓(𝑥) = {65
0,
0 ,
d) 𝑓(𝑥) = { 1
,
65
𝑤ℎ𝑒𝑟𝑒 25 ≤ 𝑥 ≤ 40
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
𝑤ℎ𝑒𝑟𝑒 25 ≤ 𝑥 ≤ 40
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
1
, 𝑤ℎ𝑒𝑟𝑒 25 ≤ 𝑥 ≤ 40
e) 𝑓(𝑥) = {45
0, 𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
2. Calculate the 75th percentile of 𝑋.
3. Calculate the variance of 𝑋 .
4. The probability that the time (in minutes) spent in queues is more than 22 minutes is?
5. The probability that the time (in minutes) spent in queues is between 27 and 36 minutes is?
6. In the following probability statement, 𝑃(𝑍 > 𝑎) = 0.95, the value 𝑎 represents:
Given: 𝑍 is a standard normal random variable.
a)
b)
c)
d)
e)
the median of the standard normal distribution.
the 5th percentile of the standard normal distribution.
the 95th percentile of the standard normal distribution.
the standard error of the standard normal distribution.
the 95th value of the standard normal distribution.
7. The IQs of people are normally distributed with an average of 100 and a standard deviation of
15. Calculate the 90th percentile of the IQ values.
Hint: The value of NORM.S.INV(0.1) in Excel is -1.282.
Copyright Reserved
27
Chapter 7: Sampling and Sampling Distributions
7.1 – 7.2 Revision of Semester 1
Population parameter
Sample statistic
(Point Estimator)
Sampling error
Mean
∑ 𝑋𝑖
𝜇=
𝑁
∑ 𝑋𝑖
𝑋=
𝑛
|𝑋̅ − 𝜇|
OR
|𝜇 − 𝑋|
Variance
7.3 Point Estimation
∑(𝑋𝑖 − 𝜇)2
𝜎2 =
𝑁
∑(𝑋𝑖 − 𝑋)
𝑆2 =
𝑛−1
|𝑆 2 − 𝜎 2 |
OR
|𝜎 2 − 𝑆 2 |
Standard
deviation
𝜎 = √𝜎 2
𝑆 = √𝑆 2
|𝑆 − 𝜎|
OR
|𝜎 − 𝑆|
Proportion
2
𝑝
𝑋
𝑝=
𝑛
|𝑝 − 𝑝|
OR
|𝑝 − 𝑝|
Example:
The life expectancy (in years) of 10 VCRs are as follow:
6.5
8.0
6.2
7.4
7.0
8.4
9.5
4.6
5.0
7.4
What is the point estimate of the population average for the life time of the VCRs?
𝑥=
∑ 𝑥𝑖
𝑛
=
6.5+8.0+6.2+7.4+7.0+8.4+9.5+4.6+5.0+7.4
10
70
= 10 = 7
What is the point estimate of the population standard deviation for the life time of the VCRs?
∑(𝑥𝑖 −𝑥)2
𝑠=√
𝑛−1
= 1.497
What is the point estimate of the population proportion for VCRs with a life time of more than 5
years?
8
𝑝 = 10 = 0.8
Note: Remember that random variables/point estimators are indicated with capital letters and
calculated statistics/point estimates with lower case letters.
Copyright Reserved
28
7.4 Introduction to Sampling Distributions
Notes
Copyright Reserved
29
̅:
7.5 Sampling distribution of 𝑿
Important note:
Let 𝑋̅ be the sample average of a random sample of size 𝑛 from a Normal distribution.
Then: The sampling distribution of 𝑋̅ has a Normal distribution for all 𝑛.
Central limit theorem:
Let 𝑋̅ be the sample average of a random sample of size 𝑛 from any population.
Then: The sampling distribution of 𝑋̅ has an approximate Normal distribution for 𝑛 large
(𝑛 ≥ 30).
Note that the original population can be discrete or continuous.
The expected value of 𝑋̅:
∑𝑋
∑ 𝐸(𝑋)
𝑛𝜇
𝐸(𝑋̅) = 𝐸 ( 𝑛 ) = 𝑛 = 𝑛 = 𝜇
The sample average (𝑋̅) is an unbiased estimator of the population mean (𝜇) since
𝐸(𝑋̅) = 𝜇𝑋̅ = 𝜇
The standard deviation of 𝑋̅:
Finite population:
𝑁−𝑛
𝜎
𝜎𝑋̅ = √𝑁−1 ( 𝑛)
√
𝜎𝑋̅
Infinite population:
𝜎𝑋̅ =
(A)
𝜎
√𝑛
(B)
is also known as the standard error of the mean.
𝑁−𝑛
𝑛
Note: For 𝑁 large and 𝑛 small, then √𝑁−1 ≈ 1 and we use the formula (B). If 𝑁 ≤ 0.05 we use
formula (B).
Copyright Reserved
30
Example 1:
Salary of managers: 𝜇 = 51 800 and 𝜎 = 4 000.
Note: This notation implies that the average salary of all managers (i.e. the population average) is
51 800 with a (population) standard deviation of 4000.
Question:
Calculate the probability that 𝑋̅ will be within $500 from the population average for a sample of
size 100.
Answer:
̅ ) = 𝜇 = 51 800
𝐸(𝑋
𝜎𝑋̅ =
𝜎
√𝑛
=
4 000
√100
= 400
First we standardize the 𝑥 values:
𝑧=
𝑥−𝜇
𝜎𝑋
̅
=
51 300−51 800
400
= −1.25 and 𝑧 =
𝑥−𝜇
𝜎𝑋
̅
=
52 300−51 800
400
= 1.25
Therefore,
̅ < 52 300) = 𝑃(−1.25 < 𝑍 < 1.25)
𝑃(51 300 < 𝑋
= 𝑃(𝑍 < 1.25) − 𝑃(𝑍 < −1.25)
= 0.8944 − 0.1056
= 0.7888
Answer using Excel’s NORM.S.DIST function:
𝑃(−1.25 < 𝑍 < 1.25) = 𝑃(𝑍 < 1.25) − 𝑃(𝑍 < −1.25)
= 𝑁𝑂𝑅𝑀. 𝑆. 𝐷𝐼𝑆𝑇(1.25, 𝑻𝑹𝑼𝑬) – 𝑁𝑂𝑅𝑀. 𝑆. 𝐷𝐼𝑆𝑇(−1.25, 𝑻𝑹𝑼𝑬)
= 0.7887
Answer using Excel’s NORM.DIST function:
̅ < 52 300) = 𝑃(𝑋
̅ < 52 300) − 𝑃(𝑋
̅ < 51 300)
𝑃(51 300 < 𝑋
= 𝑁𝑂𝑅𝑀. 𝐷𝐼𝑆𝑇(52300, 51800, 400, 𝑇𝑅𝑈𝐸)– 𝑁𝑂𝑅𝑀. 𝐷𝐼𝑆𝑇(51300, 51800, 400, 𝑇𝑅𝑈𝐸)
= 0.7887
IN GENERAL: = NORM.DIST( 𝑥, 𝜇, 𝜎𝑋̅ , TRUE)
Copyright Reserved
31
Example 2
Suppose that the delivery time of pizzas has a uniform distribution over the interval from 20 to 40
minutes. Let 𝑋 = the delivery time in minutes.
1. The probability function of 𝑋 is:
1
1
=
𝑓(𝑥) = {40 − 20 20 = 0.05
0
for 20 ≤ 𝑥 ≤ 40
elsewhere
2. The average delivery time of a pizza is:
𝐸(𝑋) = 𝜇 =
𝑎 + 𝑏 20 + 40
=
= 30
2
2
3. The standard deviation of 𝑋 is:
𝑉𝑎𝑟(𝑋) = 𝜎 2 =
(𝑏 − 𝑎)2 (40 − 20)2
=
= 33. 3̇
12
12
𝑆𝑡𝑑𝑒𝑣(𝑋) = 𝜎 = √33. 3̇ = 5.7735
4. The probability that it will take between 28 and 32 minutes to deliver a pizza is:
𝑃(28 < 𝑋 < 32) = ∆𝑥 ∙ 𝑓(𝑥) = (32 − 28)(0.05) = 0.2
5. Let 𝑋̅ = the average delivery time of 36 pizzas
(a) Give the sampling distribution of 𝑋̅ .
̅ ) = 𝜇 = 30
𝐸(𝑋
𝜎𝑋 =
𝜎
√𝑛
=
5.7735
√36
= 0.962
Copyright Reserved
32
(b) The probability that 𝑋̅ is between 28 and 32 minutes is:
First we standardize the 𝑋 values:
𝑧=
𝑥−𝜇
𝜎𝑋
̅
=
28−30
0.962
= −2.078 ≈ −2.08 and 𝑧 =
𝑥−𝜇
𝜎𝑋
̅
=
32−30
0.962
= 2.078 ≈ 2.08
Therefore,
𝑃(28 < 𝑋̅ < 32) = 𝑃(−2.08 < 𝑍 < 2.08)
= 𝑃(𝑍 < 2.08) − 𝑃(𝑍 < −2.08)
= 0.9812 − 0.0188
= 0.9624
Answer using Excel’s NORM.S.DIST function:
𝑃(−2.08 < 𝑍 < 2.08) = 𝑃(𝑍 < 2.08) − 𝑃(𝑍 < −2.08)
= NORM.S.DIST(2.08,TRUE) – NORM.S.DIST(-2.08,TRUE)
= 0.9623
Answer using Excel’s NORM.DIST function:
𝑃(28 < 𝑋 < 32) = 𝑃(𝑋 < 32) − 𝑃(𝑋 < 28)
= NORM.DIST(32, 30, 0.962, TRUE) – NORM.DIST(28, 30, 0.962, TRUE)
= 0.9623
Copyright Reserved
33
Example 3
Question:
𝑋 is normally distributed with 𝜇 = 60 and 𝜎 = 10. If 𝑃(𝑎1 < 𝑋 < 𝑎2 ) = 0.95 and 𝑛 = 100, what are
the values of 𝑎1 and 𝑎2 ? Note that the area of 0.95 represents the middle 95% of the data.
Answer:
𝜎𝑋̅ = 𝜎⁄ = 10⁄
=1
√𝑛
√100
If we know that the area to the left of 𝑎1 is 0.025, we can find the corresponding z-value of -1.96.
If we know that the area to the left of 𝑎2 is 0.975, we can find the corresponding z-value of 1.96.
Now to find 𝑎1 and 𝑎2 :
𝑧=
𝑎1 − 𝜇
𝜎𝑋̅
−1.96 =
𝑧=
𝑎1 − 60
1
𝑎2 − 𝜇
𝜎𝑋̅
1.96 =
𝑎1 = (−1.96)(1) + 60 = 58.04
𝑎2 − 60
1
𝑎2 = (1.96)(1) + 60 = 61.96
Answer using Excel:
We know that the area to the left of 𝑎1 is 0.025, therefore:
𝑎1 = NORM.INV(0.025, 60, 1) = 58.04
We know that the area to the left of 𝑎2 is 0.975, therefore:
𝑎2 = NORM.INV(0.975, 60, 1) = 61.96
IN GENERAL:
=NORM.INV(area to the left, 𝜇, 𝜎𝑋̅ )
Copyright Reserved
34
7.6 Sampling Distribution of 𝒑
Expected value of 𝑝:
𝐸(𝑝) = 𝑝
The sample proportion (𝑝) is an unbiased estimator of the population proportion (𝑝) since 𝐸(𝑝) =
𝑝
Standard deviation of 𝑝:
Finite population:
Infinite population:
𝑁 − 𝑛 𝑝(1 − 𝑝)
√
𝜎𝑝 = √
𝑁−1
𝑛
𝑝(1 − 𝑝)
𝜎𝑝 = √
𝑛
𝜎𝑝 is also known as the standard error of the proportion.
The sampling distribution of 𝑝 is approximately normally distributed for “large” samples.
A sample is “large” if
𝑛𝑝 ≥ 5
𝑛(1 − 𝑝) ≥ 5
This means that we can standardize 𝑝̅ as follows:
𝑍=
𝑝̅ − 𝐸(𝑝̅ )
=
𝜎𝑝̅
𝑝̅ − 𝑝
√𝑝(1 − 𝑝)
𝑛
Copyright Reserved
35
Example 1:
Proportion of managers that participated in the training program is:
𝑝=
1 500
= 0.6
2 500
Question:
Calculate the probability that 𝑝 is within 0.05 of the population proportion for 𝑛 = 30.
Answer:
𝐸(𝑝) = 𝑝 = 0.6
𝑝(1−𝑝)
𝜎𝑝 = √
𝑛
0.6(1−0.6)
=√
30
= 0.089
First we standardize the values:
𝑧=
𝑝−𝑝
𝜎𝑝
=
0.55−0.6
0.089
= −0.559 ≈ −0.56 and 𝑧 =
𝑝−𝑝
𝜎𝑝
=
0.65−0.6
0.089
= 0.559 ≈ 0.56
Therefore,
𝑃(0.55 < 𝑝 < 0.65) = 𝑃(−0.56 < 𝑍 < 0.56)
= 𝑃(𝑍 < 0.56) − 𝑃(𝑍 < −0.56)
= 0.7123 − 0.2877
= 0.4246
Answer using Excel’s NORM.S.DIST function:
𝑃(−0.56 < 𝑍 < 0.56) = 𝑃(𝑍 < 0.56) − 𝑃(𝑍 < −0.56)
= NORM.S.DIST(0.56,TRUE) – NORM.S.DIST(-0.56,TRUE)
= 0.4245
Answer using Excel’s NORM.DIST function:
𝑃(0.55 < 𝑝 < 0.65) = 𝑃(𝑝 < 0.65) − 𝑃(𝑝 < 0.55)
= NORM.DIST(0.65, 0.6, 0.089, TRUE) – NORM.DIST(0.55, 0.6, 0.089, TRUE)
= 0.4238
IN GENERAL: = NORM.DIST( 𝑝, 𝑝, 𝜎𝑝 , TRUE)
Copyright Reserved
36
More examples:
Given:
Suppose that 70% of the students passed the re-exam. A simple random sample of size 40
students is drawn.
Question 1:
Calculate the probability that more than three quarters passed the re-exam.
Answer:
The question is: 𝑃(𝑝 > 0.75)
𝑝(1−𝑝)
𝜎𝑝 = √
𝑛
0.7(1−0.7)
=√
40
= 0.072
𝑧=
𝑝 − 𝑝 0.75 − 0.7
=
= 0.69006 ≈ 0.69
𝜎𝑝
0.072
Therefore,
𝑃(𝑝 > 0.75) = 𝑃(𝑍 > 0.69)
= 1 − 𝑃(𝑍 < 0.69)
= 1 − 0.7549
= 0.2451
Question 2:
Let 𝑝 = sample proportion of students that passed for 𝑛 = 40.
Calculate 𝑎 such that 𝑃(𝑝 ≤ 𝑎) = 0.9.
Answer :
𝑧=
𝑝−𝑝
𝜎𝑝
1.28 =
𝑎 − 0.7
0.072
𝑎 = (1.28)(0.072) + 0.7 = 0.792
Excel: 𝑎 = NORM.INV(0.9, 0.7, 0.072) = 0.792
IN GENERAL:
=NORM.INV(area to the left, 𝑝, 𝜎𝑝 )
Copyright Reserved
37
Additional notes on absolute values
|𝑥| ≥ 𝑎:
𝑥 ≥ 𝑎 or 𝑥 ≤ −𝑎
|𝑥| ≤ 𝑎:
−𝑎 ≤𝑥 ≤𝑎
Example 1:
Given 𝜎𝑋 = 25. What is the probability that the sampling error of 𝑋̅ is greater than 10?
𝑃(|𝑋̅ − 𝜇| > 10) = 𝑃(𝑋̅ − 𝜇 > 10) + 𝑃(𝑋̅ − 𝜇 < −10)
𝑋̅ −𝜇
𝑋̅ −𝜇
10
= 𝑃( 𝜎
> 25) + 𝑃 ( 𝜎
̅
𝑋
̅
𝑋
<
−10
25
)
= 𝑃(𝑍 > 0.4) + 𝑃(𝑍 < −0.4)
= 1 − 𝑃(𝑍 < 0.4) + 𝑃(𝑍 < −0.4)
= 1 − 0.6554 + 0.3446 = 0.6892.
Example 2:
Given 𝜎𝑋 = 25. What is the probability that the sampling error of 𝑋̅ is less than 5?
𝑃(|𝑋̅ − 𝜇| < 5) = 𝑃(−5 < 𝑋̅ − 𝜇 < 5)
−5
= 𝑃 ( 25 <
𝑋̅ −𝜇
𝜎𝑋
̅
5
< 25)
= 𝑃(−0.2 < 𝑍 < 0.2)
= 𝑃(𝑍 < 0.2) − 𝑃(𝑍 < −0.2)
= 0.5793 − 0.4207
= 0.1586.
Example 3:
Given 𝜎𝑝 = 0.0115. What is the probability that the sampling error of 𝑝 is greater than 0.01?
𝑃(|𝑝 − 𝑝| > 0.01) = 𝑃(𝑝 − 𝑝 > 0.01) + 𝑃(𝑝 − 𝑝 < −0.01)
𝑝−𝑝
0.01
𝑝−𝑝
−0.01
= 𝑃 ( 𝜎 > 0.0115) + 𝑃 ( 𝜎 < 0.0115)
𝑝
𝑝
= 𝑃(𝑍 > 0.87) + 𝑃(𝑍 < −0.87)
= 1 − 𝑃(𝑍 < 0.87) + 𝑃(𝑍 < −0.87)
= 1 − 0.8078 + 0.1922
= 0.3844.
Example 4:
Given 𝜎𝑝 = 0.0115. What is the probability that the sampling error of 𝑝 is less than 0.01?
𝑃(|𝑝 − 𝑝| < 0.01) = 𝑃(−0.01 < 𝑝 − 𝑝 < 0.01)
−0.01
= 𝑃 (0.0115 <
𝑝−𝑝
𝜎𝑝
0.01
< 0.0115)
= 𝑃(−0.87 < 𝑍 < 0.87)
= 𝑃(𝑍 < 0.87) − 𝑃(𝑍 < −0.87)
= 0.8078 − 0.1922
= 0.6156.
Copyright Reserved
38
Chapter 7 Self Evaluation Questions
Questions 1 to 3 are based on the following information:
The age of soccer supporters is normally distributed with a mean of 50 years and a standard
deviation of 12 years.
Let 𝑋 = the age (in years) of a soccer supporter.
𝑋̅ = the average age (in years) of 25 randomly selected soccer supporters.
1. The probability that the age (in years) of a randomly selected soccer supporter is within 10
years of the population mean is:
2. The highest 15% of ages (in years) is higher than:
3. The 25th percentile of the average age (in years) of a randomly selected sample of 25 soccer
supporters is:
Copyright Reserved
39
Questions 4 to 6 are based on the following information:
The time that it takes a student to travel to campus by car is uniformly distributed between 10 and
50 minutes.
Let 𝑋 = time (in minutes) that it takes a student to travel to campus by car.
𝑋̅ = average time (in minutes) that it takes 40 randomly selected students to travel to campus
by car.
4. The probability that a randomly selected student will travel for between 20 and 60 minutes is:
5. According to the Central Limit Theorem 𝑋̅ is approximately normally distributed with 𝜇 = 30
and 𝜎𝑋̅ =
6. 𝑃(𝑋̅ > 28) =
Copyright Reserved
40
Questions 7 to 9 are based on the following information:
JET Airline knows that 20% of passengers are using their laptops during a flight.
Let:
𝑋 = the number of travellers using their laptops during a flight.
𝑝̅ = the sample proportion of 32 randomly selected passengers using their laptops during a
flight.
7. The variance of 𝑝 is:
8. The probability that the sampling error of 𝑝 is less than 0.05 is:
9. 𝑃(𝑝 > 𝑎) = 0.1. The value of 𝑎 is:
.
Important: There is a connection between Chapter 5 Section 5.4: Binomial Distribution and
Chapter 7 that will be discussed in class.
Copyright Reserved
41
Questions 10 to 15 are based on the following information:
Consider the Bargain Clothing Store. It is known that 60% of the customers prefer name brand
clothing. Consider the following results in Excel:
Let: 𝑋 = number of customers who prefer name brand clothing.
𝑝 = sample proportion of 30 customers who prefer name brand clothing.
Given: 𝜎𝑝 = 0.0894
Formula sheet:
Value sheet:
10. The probability that more than 17 but less than 26 customers will prefer name brand clothing
is:
11. The probability that more than 18 customers will prefer name brand clothing is:
12. The expected number of customers who don’t prefer name brand clothing is:
Copyright Reserved
42
13. A random sample of 30 customers is chosen and 22 out of 30 prefer name brand clothing. The
sampling error of the proportion 𝑝, is:
14. The sampling distribution of 𝑝 can be approximated by a normal probability distribution
whenever:
a)
b)
c)
d)
e)
𝑛 = 30 and 𝑛𝑝(1 – 𝑝) ≥ 5
𝑝 = 0.6
𝑛𝑝 ≥ 5
𝑛𝑝 ≥ 5 and 𝑛(1 – 𝑝) ≥ 5
𝑝 = 0.6 and 𝑛 = 30
15. The sixtieth percentile of the distribution of 𝑝 is:
Copyright Reserved
43
Chapter 8: Interval Estimation
What do we know about the standard normal distribution?
𝑷 (−𝒛𝜶⁄ ≤ 𝒁 ≤ 𝒛𝜶⁄ ) = 𝟏 − 𝜶
𝟐
𝟐
where
𝑍=
𝑣𝑎𝑟𝑖𝑎𝑏𝑙𝑒 − (𝑚𝑒𝑎𝑛 𝑜𝑓 𝑣𝑎𝑟𝑖𝑎𝑏𝑙𝑒)
(𝑠𝑡𝑎𝑛𝑑𝑎𝑟𝑑 𝑑𝑒𝑣𝑖𝑎𝑡𝑖𝑜𝑛 𝑜𝑓 𝑣𝑎𝑟𝑖𝑎𝑏𝑙𝑒)
We are going to use this relationship to derive the interval estimate of any future unknown
population parameter where the population is normally distributed. You are expected to be able to
derive any interval estimate (also called a confidence interval).
Interval Estimation:
𝝁: 𝑥 ± Margin of Error
Confidence interval for 𝝁:
𝑥 ± Margin of Error
𝝈 known
𝑥 ± 𝑧𝛼 𝜎𝑥 = 𝑥 ± 𝑧𝛼 𝜎⁄
√𝑛
2
2
𝝈 unknown
𝑥 ± 𝑡𝛼 𝑠⁄
√𝑛
2
8.1 Population mean: 𝝈 known
𝑃 (−𝑧𝛼⁄2 ≤ 𝑍 ≤ 𝑧𝛼⁄2 ) = 1 − 𝛼
𝑋̅ − 𝜇𝑋̅
𝑃 (−𝑧𝛼⁄2 ≤
≤ 𝑧𝛼⁄2 ) = 1 − 𝛼
𝜎𝑋̅
𝑋̅ − 𝜇
𝑃 (−𝑧𝛼⁄2 ≤ 𝜎
≤ 𝑧𝛼⁄2 ) = 1 − 𝛼
⁄ 𝑛
√
𝜎
𝜎
𝑃 (−𝑧𝛼⁄2
≤ 𝑋̅ − 𝜇 ≤ 𝑧𝛼⁄2 ) = 1 − 𝛼
√𝑛
√𝑛
𝜎
𝜎
𝑃 (−𝑋̅ − 𝑧𝛼⁄2
≤ −𝜇 ≤ −𝑋̅ + 𝑧𝛼⁄2 ) = 1 − 𝛼
√𝑛
√𝑛
𝜎
𝜎
𝑃 (𝑋̅ + 𝑧𝛼⁄2
≥ 𝜇 ≥ 𝑋̅ − 𝑧𝛼⁄2 ) = 1 − 𝛼
√𝑛
√𝑛
𝜎
𝜎
𝑃 (𝑋̅ − 𝑧𝛼⁄2
≤ 𝜇 ≤ 𝑋̅ + 𝑧𝛼⁄2 ) = 1 − 𝛼
√𝑛
√𝑛
Copyright Reserved
44
Example 1
Given:
Consider marks that are normally distributed with 𝜎 = 10.
Let 𝑥 = sample average = 58 with 𝑛 = 16.
Question:
Calculate a 95% confidence interval for 𝜇:
Answer:
1 – 0.95 = 0.05 = 𝛼 = level of significance
𝛼 0.05
=
= 0.025
2
2
𝑥 ± 𝑧0.05 𝜎⁄ = 58 ± (1.96)(10⁄
) = 58 ± 4.9
√𝑛
√16
2
(58 − 4.9, 58 + 4.9) = (53.1, 62.9)
Interpretation: We are 95% confident that the average mark 𝜇 is between 53.1 and 62.9.
Margin of Error = 𝑧0.025 𝜎⁄ = (1.96) (10⁄
) = 4.9
√𝑛
√16
95% of the time the sampling error: |𝑋 − 𝜇| = |𝜇 − 𝑋| will be 4.9 or less.
OR
There is a 0.95 probability that the sample mean, 𝑥, will provide a sampling error of 4.9 or less.
Copyright Reserved
45
Example 2
Given:
Consider marks that are normally distributed with 𝜎 = 10.
Let 𝑥 = sample average = 58 with 𝑛 = 16.
Question:
Calculate a 90% confidence interval for 𝜇:
Answer:
1 – 0.9 = 0.1 = 𝛼 = level of significance
𝛼 0.1
=
= 0.05
2
2
𝑥 ± 𝑧0.1 𝜎⁄ = 58 ± (1.645) (10⁄
) = 58 ± 4.1125
√𝑛
√16
2
(58 − 4.1125, 58 + 4.1125) = (53.8875, 62.1125)
Interpretation: We are 90% confident that the average mark 𝜇 is between 53.8875 and 62.1125.
Margin of Error = 𝑧0.05 𝜎⁄ = (1.645) (10⁄
) = 4.1125
√𝑛
√16
90% of the time the sampling error : |𝑋 − 𝜇| = |𝜇 − 𝑋| will be 4.1125 or less.
OR
There is a 0.90 probability that the sample mean, 𝑋̅, will provide a sampling error of 4.1125 or less.
Copyright Reserved
46
Example 3
Given:
Consider marks that are normally distributed with 𝜎 = 10.
Let 𝑥 = sample average = 58 with 𝑛 = 16.
Question:
Calculate a 99% confidence interval for 𝜇:
Answer:
1 – 0.99 = 0.01 = 𝛼 = level of significance
𝛼 0.01
=
= 0.005
2
2
𝑥 ± 𝑧0.01 𝜎⁄ = 58 ± (2.576) (10⁄
) = 58 ± 6.44
√𝑛
√16
2
(58 − 6.44, 58 + 6.44) = (51.56, 64.44)
Interpretation: We are 99% confident that the average mark 𝜇 is between 51.56 and 64.44.
Margin of Error = 𝑧0.005 𝜎⁄ = (2.576) (10⁄
) = 6.44
√𝑛
√16
99% of the time the sampling error : |𝑋 − 𝜇| = |𝜇 − 𝑋| will be 6.44 or less.
OR
There is a 0.99 probability that the sample mean, 𝑥, will provide a sampling error of 6.44 or less.
Copyright Reserved
47
Useful summary – Two sided confidence intervals
Confidence Level
Confidence
coefficient
𝜶
𝜶
𝟐
𝒛𝜶
Margin of Error
90%
0.90
0.10
0.05
1.645
1.645𝜎𝑋
95%
0.95
0.05
0.025
1.960
1.960𝜎𝑋
99%
0.99
0.01
0.005
2.576
2.576𝜎𝑋
Note:
𝟐
• 𝛼 = level of significance
• 1 − 𝛼 = confidence coefficient
• level of significance + confidence coefficient = 1
Very important:
Ensure that you are able to use the normal probability tables to find the values given in the table
above.
Exercise:
Derive an upper one-sided confidence interval for 𝜇 for the case where 𝜎 is known.
Hint: Start your derivation using the following statement
𝑃(𝑍 ≥ 𝑧𝛼 ) = 1 − 𝛼
Exercise:
Derive a lower one-sided confidence interval for 𝜇 for the case where 𝜎 is known.
Hint: Start your derivation using the following statement
𝑃(𝑍 ≤ 𝑧𝛼 ) = 1 − 𝛼
Copyright Reserved
48
8.2 Population mean: 𝝈 unknown
𝑃 (−𝑡𝛼⁄2 ≤ 𝑇 ≤ 𝑡𝛼⁄2 ) = 1 − 𝛼
𝑋̅ − 𝜇
𝑃 (−𝑡𝛼⁄2 ≤ 𝑠
≤ 𝑡𝛼⁄2 ) = 1 − 𝛼
⁄ 𝑛
√
𝑠
𝑠
𝑃 (−𝑡𝛼⁄2
≤ 𝑋̅ − 𝜇 ≤ 𝑡𝛼⁄2 ) = 1 − 𝛼
√𝑛
√𝑛
𝑠
𝑠
𝑃 (−𝑋̅ − 𝑡𝛼⁄2
≤ −𝜇 ≤ −𝑋̅ + 𝑡𝛼⁄2 ) = 1 − 𝛼
√𝑛
√𝑛
𝑠
𝑠
𝑃 (𝑋̅ + 𝑡𝛼⁄2
≥ 𝜇 ≥ 𝑋̅ − 𝑡𝛼⁄2 ) = 1 − 𝛼
√𝑛
√𝑛
𝑠
𝑠
𝑃 (𝑋̅ − 𝑡𝛼⁄2
≤ 𝜇 ≤ 𝑋̅ + 𝑡𝛼⁄2 ) = 1 − 𝛼
√𝑛
√𝑛
𝑥 ± 𝑡𝛼 𝑠⁄
√𝑛
2
Relationship between the normal and t – distributions
Characteristics of the t-distribution:
Symmetric around 0.
Has one parameter called the degrees of freedom (𝑑𝑓), given by 𝑛 − 1.
As the degrees of freedom increase, the t-distribution tends to the standard normal distribution.
For “large sample cases” (𝑛 ≥ 30) the t-distribution approaches the standard normal
distribution.
In Figure 1 it is illustrated that as the degrees of freedom increase, i.e. as 𝑛 − 1 increases, i.e. as
the sample size 𝑛 increases, the t-distribution tends to the standard normal distribution.
Figure 1
The bottom curve represents the t-distribution with 4 degrees of freedom (denoted t(4));
The middle curve represents the t-distribution with 10 degrees of freedom (denoted t(10));
The top curve represents both the t-distribution with 𝑑𝑓 tending to infinity (denoted t(∞)) and
the standard normal distribution (denoted z-distribution).
Copyright Reserved
49
The importance of this? Take note of the following:
95% confidence interval
When working with a 95% confidence interval using the standard normal distribution we have:
The 𝑧𝛼⁄2 value is obtained using the standard normal table.
When working with a 95% confidence interval using the t-distribution where the 𝑑𝑓 tends to
infinity we have:
The 𝑡𝛼⁄2 value is obtained using the t-table with area in the upper tail = 0.025 and 𝑑𝑓 = ∞.
Note:
The 𝑧𝛼⁄2 and 𝑡𝛼⁄2 values are the same, since the t-distribution tends to the standard normal
distribution as the 𝑑𝑓 increase.
90% confidence interval
When working with a 90% confidence interval using the standard normal distribution we have:
The 𝑧𝛼⁄2 value is obtained using the standard normal table.
When working with a 90% confidence interval using the t-distribution where the 𝑑𝑓 tends to
infinity we have:
The 𝑡𝛼⁄2 value is obtained using the t-table with area in the upper tail = 0.05 and 𝑑𝑓 = ∞.
Note:
The 𝑧𝛼⁄2 and 𝑡𝛼⁄2 values are the same, since the t-distribution tends to the standard normal
distribution as the 𝑑𝑓 increase.
Copyright Reserved
50
99% confidence interval
When working with a 99% confidence interval using the standard normal distribution we have:
The 𝑧𝛼⁄2 value is obtained using the standard normal table.
When working with a 99% confidence interval using the t-distribution where the 𝑑𝑓 tends to
infinity we have:
The 𝑡𝛼⁄2 value is obtained using the t-table with area in the upper tail = 0.005 and 𝑑𝑓 = ∞.
Note:
The 𝑧𝛼⁄2 and 𝑡𝛼⁄2 values are the same, since the t-distribution tends to the standard normal
distribution as the 𝑑𝑓 increase.
Copyright Reserved
51
Example 1
Given: 𝑛 = 15, 𝑥 = 53.87 and 𝑠 = 6.82.
Take note: 𝜎 is unknown (Why?)
Question:
Calculate a 95% confidence interval for 𝜇:
Answer:
1 – 0.95 = 0.05 = 𝛼 = level of significance
𝛼 0.05
=
= 0.025
2
2
𝑑𝑓 = 𝑛 − 1 = 15 − 1 = 14
𝑥 ± 𝑡𝛼 𝑠⁄ = 53.87 ± (2.145) (6.82⁄
) = 53.87 ± 3.78
√𝑛
√15
2
(53.87 − 3.78, 53.87 + 3.78) = (50.09, 57.65)
Interpretation: We are 95% confident that the unknown population parameter 𝜇 is between 50.09
and 57.65.
Obtaining 𝑡𝛼 using Excel:
2
= T.INV.2T(𝛼, df)
= T.INV.2T(0.05, 14)
= 2.144787
Margin of Error: 𝑡𝛼 𝑠⁄ = (2.145) (6.82⁄
) = 3.78
2
√𝑛
√15
95% of the time the sampling error: |𝑋 − 𝜇| = |𝜇 − 𝑋| will be 3.78 or less.
OR
There is a 0.95 probability that the sample mean, 𝑥, will provide a sampling error of 3.78 or less.
Copyright Reserved
52
Example 2
Given: 𝑛 = 15, 𝑥 = 53.87 and 𝑠 = 6.82.
Take note: 𝜎 is unknown
Question:
Calculate a 90% confidence interval for 𝜇:
Answer:
1 – 0.9 = 0.1 = 𝛼 = level of significance
𝛼 0.1
=
= 0.05
2
2
𝑑𝑓 = 𝑛 − 1 = 15 − 1 = 14
𝑥 ± 𝑡𝛼 𝑠⁄
= 53.87 ± (1.761) (6.82⁄
) = 53.87 ± 3.1
√𝑛
√15
2
(53.87 − 3.1, 53.87 + 3.1) = (50.77, 56.97)
Interpretation: Thus we are 90% confident that the unknown population parameter 𝜇 is between
50.77 and 56.97.
Obtaining 𝑡𝛼 using Excel:
2
= T.INV.2T(𝛼, df)
= T.INV.2T(0.1, 14)
= 1.76131
Margin of Error: 𝑡𝛼 𝑠⁄ = (1.761) (6.82⁄
) = 3.1
2
√𝑛
√15
90% of the time the sampling error : |𝑋 − 𝜇| = |𝜇 − 𝑋| will be 3.1 or less.
OR
There is a 0.90 probability that the sample mean, 𝑥, will provide a sampling error of 3.1 or less.
Copyright Reserved
53
8.3 Determining the Sample Size
Additional information on the range rule used to obtain a planning value for 𝝈:
http://statistics.about.com/od/Descriptive-Statistics/a/Range-Rule-For-Standard-Deviation.htm
Copyright Reserved
54
8.4 Population proportion
𝑝 = population proportion
𝑝 = sample proportion
Interval estimate of a population proportion:
𝑝 ± Margin of error
𝑝 ± 𝑧𝛼 𝜎𝑝
2
𝑝 ± 𝑧𝛼 √
2
𝑝(1 − 𝑝)
𝑛
To use this expression to develop an interval estimate of a population proportion, 𝑝, the value of 𝑝
would have to be known. But, the value of 𝑝 is what we are trying to estimate, so we simply substitute
the sample proportion 𝑝 for 𝑝. Therefore,
𝑝 ± 𝑧𝛼 √
2
𝑝(1 − 𝑝)
𝑛
Homework:
Derive the above expression for a (1 − 𝛼) × 100% confidence interval for 𝑝.
Hint: The first step has been given.
𝑃 (−𝑧𝛼 ≤ 𝑍 ≤ 𝑧𝛼 ) = 1 − 𝛼
2
2
Copyright Reserved
55
Example: Female Golfers
Given:
A national survey of 902 female golfers was taken to learn how women golfers view themselves as
being treated at golf courses. The survey found that 397 if the female golfers felt that they were
being treated fairly.
Let 𝑝 = the proportion of female golfers who feel they are being treated fairly
Question:
Calculate a 95% confidence interval for 𝑝.
Answer:
𝑝=
397
= 0.4401
902
(0.4401)(1 − 0.4401)
𝑝(1 − 𝑝)
𝑝 ± 𝑧𝛼 √
= 0.4401 ± 1.96√
= 0.4401 ± 0.0324
𝑛
902
2
(0.4401 − 0.0324, 0.4401 + 0.0324) = (0.4077, 0.4725)
Interpretation: We are 95% confident that the proportion of female golfers who feel they are being
treated fairly is between 0.4077 and 0.4725.
𝑝(1−𝑝)
Margin of error: 𝑧𝛼 √
2
𝑛
(0.4401)(1−0.4401)
= 1.96√
902
= 0.0324
95% of the time the sampling error : |𝑝 − 𝑝| = |𝑝 − 𝑝| will be 0.0324 or less.
OR
There is a 0.95 probability that the sample proportion, 𝑝, will provide a sampling error of 0.0324 or
less.
Question:
Calculate a 90% confidence interval for 𝑝.
Answer:
(0.4401)(1 − 0.4401)
𝑝(1 − 𝑝)
𝑝 ± 𝑧𝛼 √
= 0.4401 ± 1.645√
= 0.4401 ± 0.027189
𝑛
902
2
(0.4401 − 0.027189, 0.4401 + 0.027189) = (0.4129, 0.467)
Interpretation: We are 90% confident that the proportion of female golfers who feel they are being
treated fairly is between 0.4129 and 0.467.
𝑝(1−𝑝)
Margin of error: 𝑧𝛼 √
2
𝑛
(0.4401)(1−0.4401)
= 1.645√
902
= 0.027189
90% of the time the sampling error : |𝑝 − 𝑝| = |𝑝 − 𝑝| will be 0.027189 or less.
OR
There is a 0.9 probability that the sample proportion, 𝑝, will provide a sampling error of 0.027189 or
less.
Copyright Reserved 56
Lab session component 3: Confidence intervals in Excel
Outcomes:
At the end of this section you should be able to
calculate and interpret confidence intervals for the population mean using the
confidence.norm() and confidence.t() functions or by setting up your own function,
calculate and interpret confidence intervals for the population proportion using the
confidence.norm() function or by setting up your own function in Excel,
identify which of these functions are appropriate to use in a given practical problem.
L3.1: Confidence intervals for the population mean (𝝈 known case)
A (1 − 𝛼) × 100% confidence interval for 𝜇 in the 𝜎 known case is given by
𝜎
𝑥̅ ± 𝑧𝛼⁄2
√𝑛
where 𝑥̅ is the observed sample mean, 𝑛 is the sample size, 𝜎 is the population standard deviation
and 𝑧𝛼⁄2 is a normal percentile. From Section L2.4.2 we know that the value of 𝑧𝛼⁄2 can be found
using the norm.s.inv() function, and this value can then be used to calculate the margin of error
for the confidence interval given above. There is however an even simpler method of doing this in
Excel, namely the confidence.norm() function. This function calculates the margin of error for a
two-sided confidence interval and uses the following syntax:
confidence.norm(alpha, standard_dev, size)
where standard_dev refers to the population standard deviation and size refers to the sample
size. It is important to note that alpha refers to the level of significance, not 𝛼⁄2, as illustrated in
the following example.
Example:
The margin of error for a 98% confidence interval for the population mean with 𝜎 = 10 and 𝑛 =
123 can be found by typing the following in Excel:
=confidence.norm(0.02,10,123).
L3.2: Confidence intervals for the population mean (𝝈 unknown case)
A (1 − 𝛼) × 100% confidence interval for 𝜇 in the 𝜎 unknown case is given by
𝑠
𝑥̅ ± 𝑡𝑛−1,𝛼⁄2
√𝑛
where 𝑥̅ is the observed sample mean, 𝑛 is the sample size, 𝑠 is the observed sample standard
deviation and 𝑡𝑛−1,𝛼⁄2 is a percentile of the t-distribution with 𝑛 − 1 degrees of freedom. We can
calculate the margin of error manually by finding a t-value using the t.inv() function. Alternatively,
the margin of error can be calculated directly in Excel using the confidence.t() function. This
function calculates the margin of error for a two-sided confidence interval and uses the following
syntax:
confidence.t(alpha, standard_dev, size)
where alpha again refers to the level of significance, standard_dev refers to the sample standard
deviation, and size refers to the sample size.
Example:
The margin of error for a 98% confidence interval for the population mean with 𝑠 = 10 and 𝑛 = 123
can be found by typing the following in Excel:
=confidence.t(0.02,10,123).
Copyright Reserved
57
L3.3: Confidence intervals for the population proportion
A (1 − 𝛼) × 100% confidence interval for 𝑝 is given by
𝑝̅ (1 − 𝑝̅ )
𝑝̅ ± 𝑧𝛼⁄2 √
𝑛
where 𝑝̅ is the sample proportion, 𝑛 is the sample size and 𝑧𝛼⁄2 is a normal percentile.
Unfortunately there are no built-in Excel functions to calculate the margin of error like we had in
the previous sections. The user therefore either needs to enter the formula manually in Excel or
adapt the formula used in Section L3.1.
L3.4: Self-evaluation Exercise 3
Consider the ‘EAI.xlsx’ file that contains the salaries of 2500 managers as well as the
details of whether they completed a training program.
1. Calculate a 96% confidence interval for the population mean.
Solution: [51635.61; 51964.39]
2. Calculate a 92% confidence interval for the proportion of managers who completed the training
program.
Solution: [ 0.58285; 0.61715 ]
Chapter 8 Self Evaluation Questions
Questions 1 and 2 are based on the following information:
The proportion of business travellers who are dissatisfied with the service of an airline is
investigated. A manager selects a systematic sample of 50 business travellers, from which 10 said
that they are dissatisfied with the service.
Let:
𝑝 = population proportion of dissatisfied business travellers
1. The lower limit of a 95% confidence interval for the population proportion is:
2. If the confidence coefficient of a confidence interval decreases from 0.95 to 0.90 the:
a) sample size increases.
b) interval is narrower.
c) significance level is smaller.
d) margin of error is larger.
e) standard error is larger.
3. A Business travel magazine rates the service of airlines on a regular basis (the rating scale
with a low score of 0 and a high score of 10 was used). It is known that \sigma=1.05. An airline
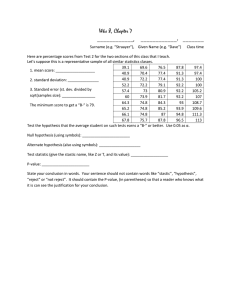
was rated by 30 randomly selected business travellers which provided a sample mean of 7.5
The upper limit of a 99% confidence interval for the population mean is:
Copyright Reserved
58
Questions 4 to 10 are based on the following information:
The management team of a soccer stadium wants to estimate the average amount (in Rand) spent
on snacks and cool drinks per spectator. It is known that the amount (in Rand) is normally distributed.
They are also interested in the method of payment used for the purchase namely, credit card or
cash.
Let: 𝜇 = the population mean of the amount (in Rand) spent on snacks and cool drinks per
spectator.
𝑝 = the population proportion of spectators who paid with cash.
𝑥̅ = the average amount (in Rand) spent on snacks and cool drinks.
Consider the following results in Excel:
Formula worksheet:
Note: Rows 10 to 40 are hidden.
Value worksheet:
Note: Rows 10 to 40 are hidden
4. The point estimate for the population mean of the amount (in Rand) spent is:
5. The point estimate of the population proportion is:
Copyright Reserved
59
6. When 𝑠 is used to estimate 𝜎, the interval estimate for the population mean is based on the:
a)
b)
c)
d)
e)
standard normal distribution
binomial distribution
normal distribution
𝑡-distribution
uniform distribution
7. The margin of error of a 95% confidence interval for 𝜇 is:
8. The lower limit of a 99% confidence interval for the population proportion is:
9. The margin of error of a 95% confidence interval for the population proportion is:
10. If the confidence coefficient of a confidence interval for 𝜇 is decreased from 95% to 90%, then:
a)
b)
c)
d)
e)
the standard error decreases, which implies a narrower interval.
the standard error increases, which implies a wider interval.
the sample size increases, which implies a narrower interval.
lower limit increases, which implies a wider interval.
the margin of error decreases, which implies a narrower interval.
Copyright Reserved
60
Chapter 9 Hypothesis tests
9.1 Developing the null and alternative hypotheses
𝑯𝟎 :
● Null hypothesis
● Tentative assumption about a population parameter
𝑯𝒂 :
● Alternative hypothesis
● Opposite of what is stated in 𝐻0
● Research hypothesis
Different types of hypotheses about the population mean:
𝜇0 = a specific numerical value
𝜇 = population mean
One-tailed test
Lower tail test
Upper tail test
𝐻0 : 𝜇 ≥ 𝜇0
𝐻𝑎 : 𝜇 < 𝜇0
𝐻0 : 𝜇 ≤ 𝜇0
𝐻𝑎 : 𝜇 > 𝜇0
Two-tailed test
𝐻0 : 𝜇 = 𝜇0
𝐻𝑎 : 𝜇 ≠ 𝜇0
Testing research
hypotheses:
Testing the validity of a
claim:
Testing in decision-making
situations:
A car model currently attains
an average fuel efficiency of 24
miles per gallon. A product
research group has
developed a new fuel injection
system specifically designed to
increase the miles-per-gallon
rating.
A manufacturer of soft drinks
states that 2-liter containers
of its products have an
average of at least 67.6 fluid
ounces.
Assume the specifications for
a particular part requires a
mean length of 2 inches per
part. If the mean length is
greater or less than the 2inch standard, the parts will
cause quality problems in the
assembly operation.
𝐻0 : 𝜇 ≤ 24
𝐻𝑎 : 𝜇 > 24
(Alternative hypothesis /
Research hypothesis)
𝐻0 : 𝜇 ≥ 67.6
(Manufacturer’s claim)
𝐻𝑎 : 𝜇 < 67.6
𝐻0 : 𝜇 = 2
𝐻𝑎 : 𝜇 ≠ 2
Copyright Reserved
61
9.2 Type I and Type II Errors
Type I Error
We reject 𝐻0 , given 𝐻0 is true.
The probability of making a Type I error is called the level of significance for the test,
denoted by 𝛼.
𝛼 = 𝑃(Reject 𝐻0 | 𝐻0 true)
Errors and correct conclusions in hypothesis testing:
True state in population
𝑯𝟎 true
𝑯𝑨 true
We do not reject 𝐻0 , given 𝐻𝑎 is true.
𝛽 = 𝑃(Do not reject 𝐻0 | 𝐻𝑎 is true)
Conclusion
Type II Error
Do not Reject 𝑯𝟎
Correct
decision
Type II error
Reject 𝑯𝟎
Type I error
Correct
decision
Note that we NEVER accept 𝐻0 or 𝐻𝐴 !!!
9.3 Population mean: 𝝈 known
9.4 Population mean: 𝝈 unknown
𝑥 − 𝜇0
𝑧= 𝜎
⁄ 𝑛
√
𝑥 − 𝜇0
𝑡= 𝑠
⁄ 𝑛
√
9.3 Population mean: 𝝈 known
Lower tail test
Upper tail test
Two-tailed test
Hypotheses
𝐻0 : 𝜇 ≥ 𝜇0
𝐻𝑎 : 𝜇 < 𝜇0
𝐻0 : 𝜇 ≤ 𝜇0
𝐻𝑎 : 𝜇 > 𝜇0
𝐻0 : 𝜇 = 𝜇0
𝐻𝑎 : 𝜇 ≠ 𝜇0
Test statistic
𝑥 − 𝜇0
𝑧= 𝜎
⁄ 𝑛
√
𝑥 − 𝜇0
𝑧= 𝜎
⁄ 𝑛
√
𝑥 − 𝜇0
𝑧= 𝜎
⁄ 𝑛
√
Rejection rule:
Critical value
approach
Reject 𝐻0 if
𝑧 ≤ −𝑧𝛼
Reject 𝐻0 if
𝑧 ≥ 𝑧𝛼
Reject 𝐻0 if
𝑧 ≤ −𝑧𝛼 or if 𝑧 ≥ 𝑧𝛼
Rejection rule:
p-value approach
Reject 𝐻0 if
p-value ≤ 𝛼
Reject 𝐻0 if
p-value ≤ 𝛼
Reject 𝐻0 if
p-value ≤ 𝛼
2
2
Copyright Reserved
62
Copyright Reserved
63
Example 1:
Given:
The label on a large can of coffee states that the can contains at least 3 kg of coffee.
𝑛 = 36 coffee cans, 𝑥 = 2.92kg, 𝜎 = 0.18kg and 𝛼 = 0.01.
(Note: 𝜎 is known)
Answer:
Using the critical value approach
Using the p-value approach
Hypotheses:
𝐻0 : 𝜇 ≥ 3
𝐻𝑎 : 𝜇 < 3
Graph:
Obtaining the p-value:
Rejection rule / rejection criteria:
Rejection rule / rejection criteria:
Reject 𝐻0 if 𝑧 ≤ −𝑧𝛼
Reject 𝐻0 if 𝑧 ≤ −2.33
Reject 𝐻0 if p-value ≤ 𝛼
Test statistic:
𝑥 − 𝜇0
2.92 − 3
𝑧= 𝜎
=
= −2.67
0.18⁄
⁄ 𝑛
√
√36
p-value:
𝑝 − 𝑣𝑎𝑙𝑢𝑒 = 𝑃(𝑍 < −2.67)
= 0.0038
Decision:
Decision:
Reject 𝐻0 at a 1% level of significance since
the test statistic (𝑧 = −2.67) is less than the
critical value (𝑧0.01 = −2.33).
Reject 𝐻0 at a 1% level of significance, since
p-value (0.0038) < 𝛼 (0.01).
Conclusion:
At 1% level of significance we have enough evidence to conclude that the mean weight of a can
of coffee is less than 3kg.
Copyright Reserved
64
Example 2:
Given:
Max Flight uses a high-technology manufacturing process to produce golf balls with a mean driving
range distance of 295 yards. The process is out of adjustment if the driving distance deviates from
295 yards.
𝑛 = 50, 𝑥 = 297.6, 𝜎 = 12 and 𝛼 = 0.05.
(Note: 𝜎 is known)
Answer :
Using the critical value approach
Using the p-value approach
Hypotheses:
𝐻0 : 𝜇 = 295
𝐻𝑎 : 𝜇 ≠ 295
Graph:
Obtaining the p-value:
Rejection rule / rejection criteria:
Rejection rule / rejection criteria:
Reject 𝐻0 if 𝑧 ≤ −𝑧𝛼 or if 𝑧 ≥ 𝑧𝛼
Reject 𝐻0 if p-value ≤ 𝛼
2
2
Reject 𝐻0 if 𝑧 ≤ −1.96 or if 𝑧 ≥ 1.96
Test statistic:
𝑥 − 𝜇0 297.6 − 295
𝑧= 𝜎
=
= 1.53
12⁄
⁄ 𝑛
√
√50
p-value:
𝑝 − 𝑣𝑎𝑙𝑢𝑒 = 2 × 𝑃(𝑍 > 1.53)
= 2 × 0.063
= 0.126
Decision:
Decision:
Do not reject 𝐻0 at a 5% level of significance
since the test statistic (𝑧 = 1.53) lies between
the critical values (±𝑧0.025 = ±1.96).
Do not reject 𝐻0 at a 5% level of significance,
since p-value (0.126) > 𝛼 (0.05).
Conclusion:
Thus, at a 5% level of significance, the evidence is insufficient to indicate that the mean driving
range deviates from 295 yards.
Copyright Reserved
65
9.4 Population mean: 𝝈 unknown
Lower tail test
Upper tail test
Two-tailed test
Hypotheses
𝐻0 : 𝜇 ≥ 𝜇0
𝐻𝑎 : 𝜇 < 𝜇0
𝐻0 : 𝜇 ≤ 𝜇0
𝐻𝑎 : 𝜇 > 𝜇0
𝐻0 : 𝜇 = 𝜇0
𝐻𝑎 : 𝜇 ≠ 𝜇0
Test statistic
𝑥 − 𝜇0
𝑡= 𝑠
⁄ 𝑛
√
𝑥 − 𝜇0
𝑡= 𝑠
⁄ 𝑛
√
𝑥 − 𝜇0
𝑡= 𝑠
⁄ 𝑛
√
Rejection rule:
Critical value
approach
Reject 𝐻0 if
𝑡 ≤ −𝑡𝛼
Reject 𝐻0 if
𝑡 ≥ 𝑡𝛼
Reject 𝐻0 if
𝑡 ≤ −𝑡𝛼 or if 𝑡 ≥ 𝑡𝛼
Rejection rule:
p-value approach
Reject 𝐻0 if
p-value ≤ 𝛼
Reject 𝐻0 if
p-value ≤ 𝛼
Reject 𝐻0 if
p-value ≤ 𝛼
2
2
Copyright Reserved
66
Example 1:
Given:
A magazine has decided to classify airports according to a rating they received. Airports that have
a population mean rating of more than 7 will be designated as superior service airports.
𝑛 = 60, 𝑥 = 7.25, 𝑠 = 1.052 and 𝛼 = 0.05.
(Note: 𝜎 is unknown)
Answer:
Using the critical value approach
Using the p-value approach
Hypotheses:
𝐻0 : 𝜇 ≤ 7
𝐻𝑎 : 𝜇 > 7
Graph:
Obtaining the p-value:
Rejection rule / rejection criteria:
Rejection rule / rejection criteria:
Reject 𝐻0 if 𝑡 ≥ 𝑡𝛼
Reject 𝐻0 if 𝑡 ≥ 1.671
Reject 𝐻0 if p-value ≤ 𝛼
Test statistic:
𝑥 − 𝜇0
7.25 − 7
𝑡= 𝑠
=
= 1.84
1.052⁄
⁄ 𝑛
√
√60
p-value:
𝑝 − 𝑣𝑎𝑙𝑢𝑒 = 𝑃(𝑇 > 1.87)
= 0.0354 (𝑢𝑠𝑖𝑛𝑔 𝐸𝑥𝑐𝑒𝑙)
From the probability tables:
0.025 < p-value < 0.05
Decision:
Decision:
Reject 𝐻0 at a 5% level of significance since
the test statistic (𝑡 = 1.84) is greater than the
critical value (𝑡59,0.05 = 1.671).
Reject 𝐻0 at a 5% level of significance, since
the p-value < 𝛼 (0.05).
Conclusion:
At 5% level of significance it can be concluded that the mean rating for airports is more than 7.
Copyright Reserved
67
More examples on p-values:
Obtain the p-values for the following scenarios for one and two-sided tests.
Hint: Sketch the graphs for left-sided, right-sided and two-sided test.
Example 2:
𝑛 = 10, 𝑡 = 2. What is the p-value?
Answer:
𝑑𝑓 = 𝑛 − 1 = 10 − 1 = 9
Therefore,
Example 3:
𝑛 = 20, 𝑡 = 1. What is the p-value?
Answer:
𝑑𝑓 = 𝑛 − 1 = 20 − 1 = 19
Therefore,
Example 4:
𝑛 = 7, 𝑡 = 9.33. What is the p-value?
Answer:
𝑑𝑓 = 𝑛 − 1 = 7 − 1 = 6
Therefore,
Copyright Reserved
68
9.5 Population proportion
Different types of hypotheses about the population proportion:
𝑝0 = a specific numerical value
𝑝 = population proportion
One-tailed test
Lower tail test
Upper tail test
𝐻0 : 𝑝 ≥ 𝑝0
𝐻𝑎 : 𝑝 < 𝑝0
𝐻0 : 𝑝 ≤ 𝑝0
𝐻𝑎 : 𝑝 > 𝑝0
Hypotheses
Test statistic
Two-tailed test
𝐻0 : 𝑝 = 𝑝0
𝐻𝑎 : 𝑝 ≠ 𝑝0
Lower tail test
Upper tail test
Two-tailed test
𝐻0 : 𝑝 ≥ 𝑝0
𝐻𝑎 : 𝑝 < 𝑝0
𝐻0 : 𝑝 ≤ 𝑝0
𝐻𝑎 : 𝑝 > 𝑝0
𝐻0 : 𝑝 = 𝑝0
𝐻𝑎 : 𝑝 ≠ 𝑝0
𝑧=
𝑝 − 𝑝0
√𝑝0 (1 − 𝑝0 )
𝑛
𝑧=
𝑝 − 𝑝0
√𝑝0 (1 − 𝑝0 )
𝑛
𝑧=
𝑝 − 𝑝0
√𝑝0 (1 − 𝑝0 )
𝑛
Rejection rule:
Critical value
approach
Reject 𝐻0 if
𝑧 ≤ −𝑧𝛼
Reject 𝐻0 if
𝑧 ≥ 𝑧𝛼
Reject 𝐻0 if
𝑧 ≤ −𝑧𝛼 or if 𝑧 ≥ 𝑧𝛼
Rejection rule:
p-value approach
Reject 𝐻0 if
p-value ≤ 𝛼
Reject 𝐻0 if
p-value ≤ 𝛼
Reject 𝐻0 if
p-value ≤ 𝛼
2
2
Copyright Reserved
69
Example:
Given:
𝐻0 : 𝑝 ≤ 0.2
𝐻𝑎 : 𝑝 > 0.2
𝑝 = 0.25, 𝑛 = 400 and 𝛼 = 0.05.
Answer:
Using the critical value approach
Using the p-value approach
Hypotheses:
𝐻0 : 𝑝 ≤ 0.2
𝐻𝑎 : 𝑝 > 0.2
Graph:
Obtaining the p-value:
Rejection rule / rejection criteria:
Rejection rule / rejection criteria:
Reject 𝐻0 if 𝑧 ≥ 𝑧𝛼
Reject 𝐻0 if 𝑧 ≥ 1.645
Reject 𝐻0 if p-value ≤ 𝛼
𝑧=
Test statistic:
𝑝 − 𝑝0
0.25 − 0.2
√𝑝0 (1 − 𝑝0 )
𝑛
=
√0.2(1 − 0.2)
400
= 2.50
p-value:
𝑝 − 𝑣𝑎𝑙𝑢𝑒 = 𝑃(𝑍 > 2.50)
= 0.0062
Decision:
Decision:
Reject 𝐻0 at a 5% level of significance since
the test statistic (𝑧 = 2.5) is greater than the
critical value (𝑧0.05 = 1.645).
Reject 𝐻0 at a 5% level of significance, since pvalue (0.0062) < 𝛼 (0.05).
Conclusion:
At 5% level of significance it can be concluded that the population proportion is greater than 0.2.
Copyright Reserved
70
Lab session component 4: Hypothesis testing in Excel
Outcomes:
At the end of this section you should be able to
use and understand the hypothesis testing template for the population mean in the case
where 𝜎 is known,
set up and use a hypothesis testing template for the population mean in the case where 𝜎
is unknown,
set up and use a hypothesis testing template for the population proportion,
set up and use hypothesis testing template for the difference in population means in the
case where 𝜎1 and 𝜎2 are known, unknown but assumed equal and unknown and not
assumed equal,
set up and use a hypothesis testing template for the difference in population proportions,
and
use your hypothesis testing templates to test hypotheses in the context of Project Work
and interpret these results.
L4.1: Hypothesis tests for the population mean (𝝈 known case)
Hypothesis tests can be performed quite easily in Excel by making use of custom made
hypothesis testing templates. Decisions about these tests can be made based on a p-value
approach. This is most easily explained by making use of an example.
Example:
Suppose that a manufacturer of golf balls believes that they have developed a new, more
aerodynamic golf ball. The manufacturer believes that the new ball has an improved driving range
of more than 295 yards. This hypothesis is given by
𝐻0 : 𝜇 = 295
𝐻𝐴 : 𝜇 > 295
To test this belief, a sample of 50 golf balls is tested and the driving range for each ball is noted.
These values are contained in the ‘GolfTest.xlsx’ file. In order to perform this test, the data first
needs to be copied into column A of the template. The template then calculates the sample size,
sample mean, standard error of the sample mean, test statistic as well as p-values for lower,
upper and two sided tests. The output can be seen in Figure 5. It should be noted that the user
needs to enter the values for the population standard deviation as well as the hypothesized value.
Figure 5: The formulae and values obtained when using the hypothesis test template designed for tests
for
the population mean in the case where σ is known.
Copyright Reserved
71
The decision for the hypothesis test can now be made by looking at the relevant p-value. In our
example we are performing an upper tailed test. From the output we obtain a p-value of 0.0628.
We can therefore reject the null hypothesis at a 10% level of significance, but not at a 5% level of
significance.
L4.2: Self-evaluation Exercise 4
Set up hypothesis testing templates for the population mean for the case when the
population variance is unknown. Complete the following exercise.
1. Review Section L4.1 and make sure that your understand how to use a hypothesis testing
template to aid you in solving hypothesis testing problems. Also review Section L3.1 – L3.2 and
your Class Notes Book to understand the link between hypothesis testing and confidence
intervals. Add functions to your hypothesis testing templates for the mean (both 𝜎 known and
unknown cases) to calculate
(a) critical values for a hypothesis test based on a given level of significance, 𝛼.
(b) two-sided confidence intervals test based on a given level of significance, 𝛼.
(c) one-sided confidence intervals test based on a given level of significance, 𝛼.
2. Set up a hypothesis testing template that can be used to solve problems involving the
population proportion.
3. Set up a hypothesis testing template that can be used to solve problems involving the
difference of two population means for the case where σ 1 and σ 2 are known.
4. Set up a hypothesis testing template that can be used to solve problems involving the
difference of two population means for the case where σ 1 and σ 2 are unknown but assumed
equal.
5. Set up a hypothesis testing template that can be used to solve problems involving the
difference of two population means for the case where σ 1 and σ 2 are unknown but not
assumed equal.
6. Set up a hypothesis testing template that can be used to solve problems involving the
difference of two population proportions.
7. Consider the templates set up in questions 2 - 6. Add appropriate functions to these templates
in order to calculate
(a) critical values for a hypothesis test based on a given level of significance, 𝛼.
(b) two-sided confidence intervals test based on a given level of significance, 𝛼.
(c) one-sided confidence intervals test based on a given level of significance, 𝛼.
Copyright Reserved
72
Chapter 9 Self Evaluation Questions
Questions 1 to 5 are based on the following information:
According to regulations the maximum registered baggage weight is 20kg. Passengers want to
investigate the matter because they know that their baggage weight was less than 20kg and they
had to pay an unfair penalty for overweight baggage. A simple random sample of 12 pieces of
baggage was selected and the weights (in kg) were recorded as follows:
17.7
19.7
20.5
17.8
20
21.9
18.5
19.4
17.8
11.8
16.9
14
Given: Test statistic t = - 2.472
Test at 𝛼 = 0.01 whether the average baggage weight is less than 20kg.
1. The hypothesis that is tested here, is:
2. The point estimate of the population mean is:
3. The point estimate of the population standard deviation is:
4. The p-value is in the interval:
5. The average baggage weight is:
a)
b)
c)
d)
e)
significantly less than 20kg, because t > -2.681
not significantly less than 20kg, because t > -2.718
not significantly less than 20kg, because t > -2.326
significantly less than 20kg, because t > -3.055
not significantly less than 20kg, because t > -3.106
Questions 6 to 9 are based on the following information:
A certain cell phone provider wants to prove that first year students spend on average less than
100 minutes a day on Mxit. It is also known that σ = 25 minutes. To test his claim a random
sample of 50 students is selected. The sample average is calculated as 90 minutes .
Given: p-value = 0.0023
6. The probability that the null hypothesis is true and wrongly rejected, is called the probability of
a:
Copyright Reserved
73
7. The hypotheses are:
8. The value of the test statistic is:
9. Which one of the following statements is true:
a)
b)
c)
d)
e)
𝐻0 cannot be rejected at a 5% level of significance.
𝐻0 can be rejected at a 5% level of significance, but not at a 2.5% level of significance.
𝐻0 can be rejected at a 2.5% level of significance, but not at a 1% level of significance.
𝐻0 can be rejected at a 1% level of significance, but not at a 0.5% level of significance.
𝐻0 can be rejected at a 0.5% level of significance.
Questions 10 to 13 are based on the following information:
A certain bank group claims that 40% of students are using credit cards to make a purchase. To
test this claim a random sample of 80 students is selected and found that 20 out of 80 students
are using a credit card to make a purchase.
𝐻 : 𝑝 = 0.4
The hypotheses tested here at a 1% level of significance are: 0
𝐻𝑎 : 𝑝 ≠ 0.4
Let: 𝑝̅ = sample proportion of the students who pay with credit cards.
Given: 𝑧 = −2.74
10. The standard error of the sampling proportion under the null hypothesis is:
11. The p-value is:
12. The proportion of students who use a credit card to make a purchase:
a) does not differ from 0.4 because 𝑧 ≠ −2.33.
b) is more than 0.4 because 𝑧 > −2.576.
c) differs from 0.4 because 𝑧 < −2.33.
d) is less than 0.4 because 𝑧 < −2.576.
e) differs from 0.4 because 𝑧 < −2.576.
13. If the hypothesis tested changes to
𝐻0 : 𝑝 ≥ 0.4
, then the p-value is:
𝐻𝑎 : 𝑝 < 0.4
Copyright Reserved
74
Chapter 10: Statistical inference about means with two populations
10.1 Inferences about the difference between two population means: 𝝈𝟏 and 𝝈𝟐 known
Population 1:
Population 2
Inner-City Store Customers
Suburban Store Customers
𝝁𝟏 = mean age of inner-city
store customers
𝝁𝟐 = mean age of suburban
store customers
𝑛1
𝑛2
𝜇1 − 𝜇2 = the difference between the two population means
𝑥1 − 𝑥2 = the point estimator of the difference between the two population means
𝑥1 = sample mean age for the inner-city store customers
𝑥2 = sample mean age for the suburban store customers
Different types of hypotheses
One-tailed test
Lower tail test
Upper tail test
𝑯𝟎 : 𝝁𝟏 − 𝝁𝟐 ≥ 𝑫𝟎
𝑯𝒂 : 𝝁𝟏 − 𝝁𝟐 < 𝑫𝟎
𝑯𝟎 : 𝝁𝟏 − 𝝁𝟐 ≤ 𝑫𝟎
𝑯𝒂 : 𝝁𝟏 − 𝝁𝟐 > 𝑫𝟎
Two-tailed test
𝑯𝟎 : 𝝁𝟏 − 𝝁𝟐 = 𝑫𝟎
𝑯𝒂 : 𝝁𝟏 − 𝝁𝟐 ≠ 𝑫𝟎
Copyright Reserved
75
Example:
Given:
As part of a study to evaluate differences in education quality between two training centers, a sample
from each centre is drawn. Test at a 5% level of significance whether there is a statistically significant
difference in the education quality.
Training Centre A
Training Centre B
𝑛1 = 30
𝑥1 = 82
𝜎1 = 10
𝑛2 = 40
𝑥2 = 78
𝜎2 = 10
Answer:
Using the critical value approach
Using the p-value approach
Hypotheses:
𝐻0 : 𝜇1 − 𝜇2 = 0
𝐻𝑎 : 𝜇1 − 𝜇2 ≠ 0
Graph:
Obtaining the p-value:
Rejection rule / rejection criteria:
Rejection rule / rejection criteria:
Reject 𝐻0 if 𝑧 ≤ −𝑧𝛼 or if 𝑧 ≥ 𝑧𝛼
Reject 𝐻0 if p-value ≤ 𝛼
2
2
Reject 𝐻0 if 𝑧 ≤ −1.96 or if 𝑧 ≥ 1.96
Test statistic:
𝑧=
(𝑥1 − 𝑥2 ) − 𝐷0
𝜎2
√ 1
𝜎22
𝑛1 + 𝑛2
=
(82 − 78) − 0
2
2
√10 + 10
30
40
= 1.66
p-value:
𝑝 − 𝑣𝑎𝑙𝑢𝑒 = 2 × 𝑃(𝑍 > 1.66)
= 2 × 0.0485
= 0.097
Decision:
Do not reject 𝐻0 at a 5% level of significance
since the test statistic (𝑧 = 1.66) is between
the critical values (±𝑧0.025 = ±1.96).
Decision:
Do not reject 𝐻0 at a 5% level of significance,
since p-value (0.097) > 𝛼 (0.05).
Conclusion:
Thus, at a 5% level of significance, the evidence is insufficient to indicate that there is a
difference in the education quality.
Copyright Reserved
76
10.2 Inferences about the difference between two population means: 𝝈𝟏 and 𝝈𝟐 unknown
Example:
Given:
Consider a new software package developed to reduce design, develop and implement of an
information system. The researcher in charge of the new software evaluation project hopes to show
that the new software package will provide a shorter mean project completion time. Use 𝛼 = 0.05.
Current Technology
New Software
𝑛𝑐 = 12
𝑥𝑐 = 325
𝑠c = 40
𝑛𝑛 = 12
𝑥𝑛 = 286
𝑠n = 44
𝜇𝑐 = the mean project completion time for all systems analysts using the current technology
𝜇𝑛 = the mean project completion time for all systems analysts using the new software package
Answer:
Using the critical value approach
Using the p-value approach
Hypotheses:
𝐻0 : 𝜇𝑐 − 𝜇𝑛 ≤ 0
𝐻𝑎 : 𝜇𝑐 − 𝜇𝑛 > 0
Graph:
Obtaining the p-value:
Use t - table with 𝑑𝑓 (degrees of freedom):
2
𝑑𝑓 =
=
2 2
𝑠
𝑠
( 𝑐+ 𝑛)
𝑛𝑐 𝑛𝑛
2
2
2
𝑠
𝑠2
1
1
( 𝑐) +
( 𝑛)
𝑛𝑐 −1 𝑛𝑐
𝑛𝑛 −1 𝑛𝑛
2
2
40
442
( + )
12
12
2
2
1
402
1
442
( ) +
( )
12−1 12
12−1 12
= 21.8 ≈ 21
Using the t – table we find 0.01 < p-value <
0.025
Note: 𝑑𝑓 is rounded down to the nearest
integer.
Rejection rule / rejection criteria:
Rejection rule / rejection criteria:
Reject 𝐻0 if 𝑡 ≥ 𝑡𝛼
Reject 𝐻0 if 𝑡 ≥ 1.721
Reject 𝐻0 if p-value ≤ 𝛼
Copyright Reserved
77
Test statistic:
𝑡=
(𝑥𝑐 − 𝑥𝑛 ) − 𝐷0
𝑠2 𝑠2
√ 𝑐 + 𝑛
𝑛𝑐 𝑛𝑛
=
(325 − 286) − 0
2
2
√40 + 44
12
12
= 2.27
p-value:
𝑝 − 𝑣𝑎𝑙𝑢𝑒 = 𝑃(𝑇 > 2.27)
= 0.016929 (𝑢𝑠𝑖𝑛𝑔 𝐸𝑥𝑐𝑒𝑙)
From the probability tables:
0.01 < p-value < 0.025
Decision:
Reject 𝐻0 at a 5% level of significance since
the test statistic (𝑡 = 2.27) is greater than the
critical value (𝑡21,0.05 = 1.721).
Decision:
Reject 𝐻0 at a 5% level of significance, since pvalue < 𝛼 (0.05).
Conclusion:
Thus, at a 5% level of significance it can be concluded that the mean project completion time is
decreased when using the new software.
Alternative approach:
Inferences about the difference between two population means can also be made by making the
assumption that the two unknown population standard deviations are equal. Under this
assumption the two sample standard deviation are combined to provide the following pooled
sample variance:
(𝑛1 − 1)𝑠12 + (𝑛2 − 1)𝑠22
𝑠𝑝2 =
𝑛1 + 𝑛2 − 2
The t-test statistic then becomes:
𝑡=
(𝑦̅1 − 𝑦̅2 ) − 𝐷0
1
1
𝑠𝑝 √𝑛 + 𝑛
1
2
with degrees of freedom equal to 𝑛1 + 𝑛2 − 2.
Note that this assumption is difficult to verify and population variances often differ. The pooled
procedure may not provide satisfactory results, especially if the sample sizes are very different.
This approach should therefore be followed with caution and will work best in a situation where the
two sample sizes are approximately the same.
Note that the assumption of equal variance needs to be tested and cannot merely be assumed.
The procedure for this test is discussed in Section 11.2.
Copyright Reserved
78
Example
Consider a new software package developed to reduce design, develop and implement of an
information system. The researcher in charge of the new software evaluation project hopes to show
that the new software package will provide a shorter mean project completion time. Use 𝛼 = 0.05
and assume 𝜎1 = 𝜎2
Current Technology
New Software
𝑛1 = 12
𝑥̅1 = 325
𝑠1 = 40
𝑛2 = 12
𝑥̅2 = 286
𝑠2 = 44
𝜇1 = the mean project completion time for all systems analysts using the current technology
𝜇2 = the mean project completion time for all systems analysts using the new software package
Answer (using the critical value approach):
Hypotheses:
𝐻0 : 𝜇1 − 𝜇2 ≤ 0
𝐻𝑎 : 𝜇1 − 𝜇2 > 0
Test statistic:
(𝑛1 − 1)𝑠12 + (𝑛2 − 1)𝑠22 (12 − 1)1600 + (12 − 1)1936
𝑠𝑝2 =
=
= 1768
𝑛1 + 𝑛2 − 2
12 + 12 − 2
𝑡=
(𝑥̅1 − 𝑥̅2 ) − 𝐷0
1
1
𝑠𝑝 √𝑛 + 𝑛
1
2
=
325 − 286
√1768 ( 2 )
12
≈ 2.272
Rejection rule:
Degrees of freedom = 12 + 12 − 2 = 22
Decision: Reject 𝐻0
Conclusion: At a 5% level of significance we have enough evidence to conclude that the new
software package will provide a shorter mean project completion time
Copyright Reserved
79
10.3 The Difference Between Two Population Means: Matched pairs (p438)
In the previous two sections we assumed that the elements in the two samples were obtained
independently of each other. If for example we wanted to test the effectiveness of two different methods of
assembly, we could train one set of workers to use method A and another separate group of workers to use
method B. We can then select a sample from each of these groups. These two samples will be
independent of each other since the workers using method A are independent of the workers using method
B. If we however trained all workers to use both methods, we could again randomly select a sample of
workers. Each selected worker would then be expected to perform the assembly using both method A and
method B. The order in which the methods are used will be randomly assigned to each worker, some
performing A first, others performing B first. We will therefore end up with a pair of observations for each of
the workers. The set of observations for workers using method A will be our first sample whilst the
observations obtained using method B is the second sample. This type of sampling design is known as a
matched sample design and it is clear that the observations in the two samples are dependent.
In a matched sample design the different methods are tested under similar conditions. This usually means
that the sampling error is smaller for matched designs than for independent designs. The main reason for
this is that the individual variation between observations in the two samples is eliminated since the same
elements are observed in both samples.
Example:
Suppose that a shoe company wants to test material for the soles of shoes. For each pair of shoes, the new
material is placed on one shoe and the old material on the other shoe. After a given period of time, a random
sample of ten pairs of shoes is selected. The wear is measured on a ten-point scale (higher is better) with
the following results:
Pair number
1
2
3
4
5
6
7
8
9
10
New material
2
4
5
7
7
5
9
8
8
7
Old material
4
5
3
8
9
4
7
8
5
6
Test at a 1% level of significance whether the average wear for the new material is better than of the old
material.
Copyright Reserved
80
10.4 The Difference Between Two Population Proportions: (p446)
Interval estimation:
𝑃 (−𝑧𝛼⁄2 ≤ 𝑍 ≤ 𝑧𝛼⁄2 ) = 1 − 𝛼
𝑃 (−𝑧𝛼⁄2 ≤
(𝑝̅1 − 𝑝̅2 ) − (𝑝1 − 𝑝2 )
≤ 𝑧𝛼⁄2 ) = 1 − 𝛼
𝜎(𝑝̅1 −𝑝̅2)
𝑃 (−𝑧𝛼⁄2 𝜎(𝑝̅1 −𝑝̅2 ) ≤ (𝑝̅1 − 𝑝̅2 ) − (𝑝1 − 𝑝2 ) ≤ 𝑧𝛼⁄2 𝜎(𝑝̅1 −𝑝̅2) ) = 1 − 𝛼
𝑃 (−𝑧𝛼⁄2 𝜎(𝑝̅1 −𝑝̅2 ) − (𝑝̅1 − 𝑝̅2 ) ≤ −(𝑝1 − 𝑝2 ) ≤ 𝑧𝛼⁄2 𝜎(𝑝̅1 −𝑝̅2) − (𝑝̅1 − 𝑝̅2 )) = 1 − 𝛼
𝑃 (𝑧𝛼⁄2 𝜎(𝑝̅1 −𝑝̅2 ) + (𝑝̅1 − 𝑝̅2 ) ≥ (𝑝1 − 𝑝2 ) ≥ −𝑧𝛼⁄2 𝜎(𝑝̅1 −𝑝̅2) + (𝑝̅1 − 𝑝̅2 )) = 1 − 𝛼
𝑃 ((𝑝̅1 − 𝑝̅2 ) − 𝑧𝛼⁄2 𝜎(𝑝̅1 −𝑝̅2 ) ≤ (𝑝1 − 𝑝2 ) ≤ (𝑝̅1 − 𝑝̅2 ) + 𝑧𝛼⁄2 𝜎(𝑝̅1 −𝑝̅2 ) ) = 1 − 𝛼
where
𝜎(𝑝̅1 −𝑝̅2) = √
𝑝1 (1 − 𝑝1 ) 𝑝2 (1 − 𝑝2 )
+
𝑛1
𝑛2
Therefore, a (1 − 𝛼) × 100% confidence interval is given by
(𝑝̅1 − 𝑝̅2 ) ± 𝑧𝛼⁄ √
2
𝑝1 (1 − 𝑝1 ) 𝑝2 (1 − 𝑝2 )
+
𝑛1
𝑛2
Example:
A tax preparation firm is interested in comparing the quality of work at two of its regional offices.
By randomly selecting samples of tax returns prepared at each office and verifying the sample
returns’ accuracy, the firm will be able to estimate the proportion of erroneous returns prepared at
each office. Of particular interest is the difference between these proportions. From Office 1 a
sample of 250 had 35 returns with errors and from office 2, a sample of 300 had 27 returns with
errors.
A 90% confidence interval for the difference between the two proportions:
Copyright Reserved
81
Hypothesis tests about 𝒑𝟏 − 𝒑𝟐
Under the assumption 𝐻0 is true as an equality, the population proportions are equal and 𝑝1 =
𝑝2 = 𝑝 and the standard error becomes:
𝜎(𝑝̅1 −𝑝̅2 ) = √
𝑝1 (1 − 𝑝1 ) 𝑝2 (1 − 𝑝2 )
1
1
+
= √𝑝(1 − 𝑝) ( + )
𝑛1
𝑛2
𝑛1 𝑛2
With 𝑝 unknown we pool, or combine, the point estimators from the two samples to obtain a single
point estimator of 𝑝 as follows:
𝑝̅ =
𝑛1 𝑝̅1 + 𝑛2 𝑝̅2
𝑛1 + 𝑛2
The test statistic:
𝑧=
(𝑝̅1 − 𝑝̅2 )
1
1
𝑛1 + 𝑛2 )
√𝑝̅ (1 − 𝑝̅ ) (
Example:
Copyright Reserved
82
Chapter 10 Self Evaluation Questions
Questions 1 to 4 are based on the following information:
Consider the following Excel spreadsheets with data for two independent random samples taken
from two normal populations. Use 𝛼 = 0.05 to test the hypothesis that the population mean of
sample 1 is greater than that of sample 2.
Formula worksheet
Value worksheet
1. The expected value of 𝑋̅1 − 𝑋̅2 under the null hypothesis is:
a)
b)
c)
d)
e)
0
0.025
0.49
2
0.05
2. The hypothesis tested here is:
3. The value of the test statistic is:
4. The critical value is:
Copyright Reserved
83
Questions 5 to 9 are based on the following information:
Two independent samples taken from different departments show the average number of hours
that lecturers spend on campus. XYZ University wants to test if the sample means are
significantly different at a 10% level of significance.
Department 1
Department 2
𝑛1 = 4
𝑥1 = 9.25
𝑠1 = 2.87
𝑛2 = 5
𝑥2 = 6.6
𝑠2 = 1.95
Assume: Normal populations and the degrees of freedom for the t-test is 5.
5. The hypothesis tested here is:
6. The value of the test statistic is:
7. The p-value is in the interval:
8. Reject the null hypothesis at the 10% level of significance, if:
9. It can be concluded at the 10% level of significance that 𝐻0 is:
a)
b)
c)
d)
e)
rejected therefore sample sizes differ.
not rejected therefore population means do not differ.
not rejected therefore population standard deviations differ.
rejected therefore population means differ.
rejected therefore population standard deviations do not differ.
Copyright Reserved
84
Chapter 11: Statistical inferences about two population variances
11.2 The difference between two population variances
In chapter 10 we performed hypothesis tests for the difference of two population means. In order
to choose an appropriate testing procedure, a number of assumptions had to be considered.
Firstly, the two samples could be independent or dependent (matched pairs test). For independent
samples, the variances could be known (a 𝑍-test is performed) or unknown (a 𝑇-test is performed).
For the variance unknown case, a further assumption is needed in order to choose an appropriate
test, namely whether or not the two population variances are equal. This section deals with that
assumption.
𝑺𝟐
Sampling distribution of 𝑺𝟏𝟐 when 𝝈𝟐𝟏 = 𝝈𝟐𝟐
𝟐
Let 𝑆12 and 𝑆22 be the sample variances of two independent simple random samples of sizes 𝑛1
and 𝑛2 . If the samples were selected from two normal populations with equal variances, the
sampling distribution of
𝑆12
⁄2
𝑆2
is an 𝐹 distribution with 𝑛1 − 1 degrees of freedom for the numerator and 𝑛2 − 1 degrees of
freedom for the denominator.
Different types of hypotheses
One-tailed test
Lower tail test
Upper tail test
Hypotheses
Test statistic
Rejection rule:
Critical value
approach
Two-tailed test
𝐻0 : 𝜎12 = 𝜎22
𝐻0 : 𝜎12 = 𝜎22
𝐻0 : 𝜎12 = 𝜎22
𝐻𝑎 : 𝜎12 < 𝜎22
or
𝜎12
𝐻𝑎 : 2 < 1
𝜎2
𝐻𝑎 : 𝜎12 > 𝜎22
or
𝜎12
𝐻𝑎 : 2 > 1
𝜎2
𝐻𝑎 : 𝜎12 ≠ 𝜎22
or
𝜎12
𝐻𝑎 : 2 ≠ 1
𝜎2
𝑆12
𝐹= 2
𝑆2
Distribution of test
statistic under 𝑯𝟎
𝐹(𝑛1 − 1, 𝑛2 − 1)
Reject 𝐻0 if
𝑓 ≤ 𝐹𝑛1 −1,𝑛2 −1;1−𝛼
i.e. if
1
𝑓≤
𝐹𝑛2 −1,𝑛1 −1;𝛼
Reject 𝐻0 if
𝑓 ≤ 𝐹𝑛1 −1,𝑛2 −1;1−𝛼⁄2
Reject 𝐻0 if
𝑓 ≥ 𝐹𝑛1 −1,𝑛2−1;𝛼
𝑓≤
i.e. if
1
𝐹𝑛2 −1,𝑛1 −1;𝛼⁄2
or if
𝑓 ≥ 𝐹𝑛1 −1,𝑛2 −1;𝛼⁄2
p-value calculation
𝑃(𝐹 ≤ 𝑓)
𝑃(𝐹 ≥ 𝑓)
Rejection rule:
p-value approach
Reject 𝐻0 if
p-value ≤ 𝛼
Reject 𝐻0 if
p-value ≤ 𝛼
𝑚𝑖𝑛 {
2𝑃(𝐹 ≤ 𝑓),
}
2𝑃(𝐹 ≥ 𝑓)
Reject 𝐻0 if
p-value ≤ 𝛼
Example:
Copyright Reserved
85
It is well known that the average stopping distance of vehicles is larger on a wet surface than on a
dry surface. A student would like to test the theory that the variances in these stopping distances
differs. A sample of 26 vehicles was tested under wet conditions leading to a sample variance of
48, whilst a sample of 16 vehicles was tested under dry conditions, leading to a sample variance
of 20. You may assume that the two samples are from a normal distribution. Use a 5% level of
significance to conduct your test.
Solution:
Given:
𝑛𝑤 = 26
𝑛𝑑 = 16
𝑠𝑤2 = 48
𝑠𝑑2 = 20
Hypotheses:
𝐻0 : 𝜎𝑤2 = 𝜎𝑑2
𝐻𝑎 : 𝜎𝑤2 ≠ 𝜎𝑑2
Test statistic:
𝑠𝑤2 48
𝑓= 2=
= 2.40
𝑠𝑑 20
Rejection rule:
Numerator degrees of freedom = 26 − 1 = 25
Denominator degrees of freedom = 16 − 1 = 15
p-value:
Using Excel:
𝑝 − 𝑣𝑎𝑙𝑢𝑒 = 2 × 𝑃(𝐹 > 2.40) ≈ 0.0812
From the probability tables:
Since 2.28 < (𝑓 = 2.40) < 2.69
0.025 < 𝑃(𝐹 ≥ 2.40) < 0.05
∴ 2 × 0.025 < 2 × 𝑃(𝐹 ≥ 2.40) < 2 × 0.05
∴ 0.05 < 𝑝 − 𝑣𝑎𝑙𝑢𝑒 < 0.10
Decision: Do not reject 𝐻0
Conclusion: At a 5% level of significance we do not have enough evidence to conclude that the
variance in stopping times on wet and dry surfaces differ.
Copyright Reserved
86
Hypothesis Testing Summary
H 0 : 0
Is this hypothesis
testing about:
H 0 : p p0
H 0 : p1 p2
H 0 : 1 2
H 0 : d 0
A population mean
A population proportion
p z / 2
z
x z 2
z
n
x 0
n
s
x t 2
t
p (1 p )
n
p1 p2 z / 2
p p0
p0 (1 p0 )
n
2
( 2 ) known ( ) unknown
The difference between two
population means
n
x 0
s
n
Degrees of
freedom(d.o.f.) =n-1
z
1, 2 known
12 22
2
n1 n2
x1 x 2
X1 X 2 z
z
12 22
n1
n2
The difference between two
population proportions
p1 (1 p1 ) p2 (1 p2 )
n1
n2
p1 p2
n1 p1 n2 p2
n1 n2
1 1
p (1 p )
n1 n2
1 , 2 unknown
1 2
( y y ) ( D0 )
t 1 2
1 1
sp
n1 n2
s 2p
p
(n1 1) s12 (n2 1) s22
n1 n2 2
d.o.f.=n1+n2-2
paired data
t
d d
sd
n
Copyright Reserved
87
Hypothesis Testing Tree Diagram
One Sample
Two Samples
𝒑
𝑝̅ − 𝑝0
𝝁
𝑍=
𝝈 𝒌𝒏𝒐𝒘𝒏
𝑋̅ − 𝜇0
𝑍=
𝜎 ~𝑁(0,1)
√𝑛
𝜎
𝑥̅ ± 𝑧𝛼⁄
2 𝑛
√
𝝈 𝒖𝒏𝒌𝒏𝒐𝒘𝒏
Assume 𝑋~̇𝑁(𝜇, 𝜎 2 )
𝑋̅ − 𝜇0
𝑇=
~𝑡(𝑛 − 1)
𝑆
√𝑛
𝑠
𝑥̅ ± 𝑡𝛼⁄
2 𝑛
√
√𝑝0 (1 − 𝑝0 )
𝑛
𝒑𝟏 − 𝒑𝟐
Means
~̇𝑁(0,1)
𝑍=
𝑝̅ (1 − 𝑝̅ )
𝑝̅ ± 𝑧𝛼⁄2 √
𝑛
1
1
√𝑝̅ (1 − 𝑝̅ ) ( + )
𝑛1 𝑛2
where 𝑝̅ =
~̇𝑁(0,1)
𝑛1 𝑝̅1 +𝑛2 𝑝̅2
𝑛1 +𝑛2
𝑝̅1 (1 − 𝑝̅1 ) 𝑝̅2 (1 − 𝑝̅2 )
(𝑝̅1 − 𝑝̅2 ) ± 𝑧𝛼⁄ √
+
2
𝑛1
𝑛2
Dependent samples (𝝁𝑫 )
Independent samples (𝝁𝟏 − 𝝁𝟐 )
Matched pairs
Assume 𝐷~̇𝑁(𝜇𝐷 , 𝜎𝐷2 )
Then
𝑇=
̅ −𝜇𝐷,0
𝐷
~𝑡(𝑛
𝑆𝑑
⁄
√𝑛
𝝈𝟏 , 𝝈𝟐 𝒌𝒏𝒐𝒘𝒏
𝑍=
𝑝̅1 − 𝑝̅2
(𝑋̅1 − 𝑋̅2 ) − 𝐷0
~𝑁(0,1)
𝜎2 𝜎2
√ 1 + 2
𝑛1 𝑛2
𝜎2 𝜎2
(𝑋̅1 − 𝑋̅2 ) ± 𝑧𝛼⁄ √ 1 + 2
2 𝑛
𝑛2
1
𝝈𝟏 , 𝝈𝟐 𝒖𝒏𝒌𝒏𝒐𝒘𝒏
− 1)
𝝈𝟏 , 𝝈𝟐 𝒂𝒔𝒔𝒖𝒎𝒆𝒅 𝒆𝒒𝒖𝒂𝒍
𝑇=
(𝑋̅1 − 𝑋̅2 ) − 𝐷0
1
1
𝑆𝑝 √ +
𝑛1 𝑛2
~𝑡(𝑑𝑓)
(𝑛1 − 1)𝑆12 + (𝑛2 − 1)𝑆22
𝑆𝑝2 =
𝑛1 + 𝑛2 − 2
𝑑𝑓 = 𝑛1 + 𝑛2 − 2
𝝈𝟏 , 𝝈𝟐 𝒂𝒔𝒔𝒖𝒎𝒆𝒅 𝒖𝒏𝒆𝒒𝒖𝒂𝒍
(𝑋̅1 − 𝑋̅2 ) − 𝐷0
𝑇=
~𝑡(𝑑𝑓)
2
2
𝑆
𝑆
√ 1+ 2
𝑛1 𝑛2
2
𝑑𝑓 =
𝑆2 𝑆2
(𝑛1 + 𝑛2 )
1 Reserved
2
Copyright
2
882
𝑆2
𝑆2
1
1
( 1) +
( 2)
𝑛1 − 1 𝑛1
𝑛2 − 1 𝑛2
TABLES
Cumulative probabilities for the standard normal distribution
Cumulative
probability
z
z
-3.0
-2.9
-2.8
-2.7
-2.6
-2.5
-2.4
-2.3
-2.2
-2.1
-2.0
-1.9
-1.8
-1.7
-1.6
-1.5
-1.4
-1.3
-1.2
-1.1
-1.0
-0.9
-0.8
-0.7
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
-0.0
.00
.0013
.0019
.0026
.0035
.0047
.0062
.0082
.0107
.0139
.0179
.0228
.0287
.0359
.0446
.0548
.0668
.0808
.0968
.1151
.1357
.1587
.1841
.2119
.2420
.2743
.3085
.3446
.3821
.4207
.4602
.5000
.01
.0013
.0018
.0025
.0034
.0045
.0060
.0080
.0104
.0136
.0174
.0222
.0281
.0351
.0436
.0537
.0655
.0793
.0951
.1131
.1335
.1562
.1814
.2090
.2389
.2709
.3050
.3409
.3783
.4168
.4562
.4960
0
.02
.0013
.0018
.0024
.0033
.0044
.0059
.0078
.0102
.0132
.0170
.0217
.0274
.0344
.0427
.0526
.0643
.0778
.0934
.1112
.1314
.1539
.1788
.2061
.2358
.2676
.3015
.3372
.3745
.4129
.4522
.4920
.03
.0012
.0017
.0023
.0032
.0043
.0057
.0075
.0099
.0129
.0166
.0212
.0268
.0336
.0418
.0516
.0630
.0764
.0918
.1093
.1292
.1515
.1762
.2033
.2327
.2643
.2981
.3336
.3707
.4090
.4483
.4880
.04
.0012
.0016
.0023
.0031
.0041
.0055
.0073
.0096
.0125
.0162
.0207
.0262
.0329
.0409
.0505
.0618
.0749
.0901
.1075
.1271
.1492
.1736
.2005
.2296
.2611
.2946
.3300
.3669
.4052
.4443
.4840
.05
.0011
.0016
.0022
.0030
.0040
.0054
.0071
.0094
.0122
.0158
.0202
.0256
.0322
.0401
.0495
.0606
.0735
.0885
.1056
.1251
.1469
.1711
.1977
.2266
.2578
.2912
.3264
.3632
.4013
.4404
.4801
.06
.0011
.0015
.0021
.0029
.0039
.0052
.0069
.0091
.0119
.0154
.0197
.0250
.0314
.0392
.0485
.0594
.0721
.0869
.1038
.1230
.1446
.1685
.1949
.2236
.2546
.2877
.3228
.3594
.3974
.4364
.4761
.07
.0011
.0015
.0021
.0028
.0038
.0051
.0068
.0089
.0116
.0150
.0192
.0244
.0307
.0384
.0475
.0582
.0708
.0853
.1020
.1210
.1423
.1660
.1922
.2206
.2514
.2843
.3192
.3557
.3936
.4325
.4721
.08
.0010
.0014
.0020
.0027
.0037
.0049
.0066
.0087
.0113
.0146
.0188
.0239
.0301
.0375
.0465
.0571
.0694
.0838
.1003
.1190
.1401
.1635
.1894
.2177
.2483
.2810
.3156
.3520
.3897
.4286
.4681
.09
.0010
.0014
.0019
.0026
.0036
.0048
.0064
.0084
.0110
.0143
.0183
.0233
.0294
.0367
.0455
.0559
.0681
.0823
.0985
.1170
.1379
.1611
.1867
.2148
.2451
.2776
.3121
.3483
.3859
.4247
.4641
Copyright Reserved
89
Cumulative probabilities for the standard normal distribution
Cumulative
probability
0
z
.0
.1
.2
.3
.4
.5
.6
.7
.8
.9
1.0
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2.0
2.1
2.2
2.3
2.4
2.5
2.6
2.7
2.8
2.9
3.0
.00
.5000
.5398
.5793
.6179
.6554
.6915
.7257
.7580
.7881
.8159
.8413
.8643
.8849
.9032
.9192
.9332
.9452
.9554
.9641
.9713
.9772
.9821
.9861
.9893
.9918
.9938
.9953
.9965
.9974
.9981
.9987
.01
.5040
.5438
.5832
.6217
.6591
.6950
.7291
.7611
.7910
.8186
.8438
.8665
.8869
.9049
.9207
.9345
.9463
.9564
.9649
.9719
.9778
.9826
.9864
.9896
.9920
.9940
.9955
.9966
.9975
.9982
.9987
.02
.5080
.5478
.5871
.6255
.6628
.6985
.7324
.7642
.7939
.8212
.8461
.8686
.8888
.9066
.9222
.9357
.9474
.9573
.9656
.9726
.9783
.9830
.9868
.9898
.9922
.9941
.9956
.9967
.9976
.9982
.9987
z
.03
.5120
.5517
.5910
.6293
.6664
.7019
.7357
.7673
.7967
.8238
.8485
.8708
.8907
.9082
.9236
.9370
.9484
.9582
.9664
.9732
.9788
.9834
.9871
.9901
.9925
.9943
.9957
.9968
.9977
.9983
.9988
.04
.5160
.5557
.5948
.6331
.6700
.7054
.7389
.7704
.7995
.8264
.8508
.8729
.8925
.9099
.9251
.9382
.9495
.9591
.9671
.9738
.9793
.9838
.9875
.9904
.9927
.9945
.9959
.9969
.9977
.9984
.9988
.05
.5199
.5596
.5987
.6368
.6736
.7088
.7422
.7734
.8023
.8289
.8531
.8749
.8944
.9115
.9265
.9394
.9505
.9599
.9678
.9744
.9798
.9842
.9878
.9906
.9929
.9946
.9960
.9970
.9978
.9984
.9989
.06
.5239
.5636
.6026
.6406
.6772
.7123
.7454
.7764
.8051
.8315
.8554
.8770
.8962
.9131
.9279
.9406
.9515
.9608
.9686
.9750
.9803
.9846
.9881
.9909
.9931
.9948
.9961
.9971
.9979
.9985
.9989
.07
.5279
.5675
.6064
.6443
.6808
.7157
.7486
.7794
.8078
.8340
.8577
.8790
.8980
.9147
.9292
.9418
.9525
.9616
.9693
.9756
.9808
.9850
.9884
.9911
.9932
.9949
.9962
.9972
.9979
.9985
.9989
.08
.5319
.5714
.6103
.6480
.6844
.7190
.7517
.7823
.8106
.8365
.8599
.8810
.8997
.9162
.9306
.9429
.9535
.9625
.9699
.9761
.9812
.9854
.9887
.9913
.9934
.9951
.9963
.9973
.9980
.9986
.9990
.09
.5359
.5753
.6141
.6517
.6879
.7224
.7549
.7852
.8133
.8389
.8621
.8830
.9015
.9177
.9319
.9441
.9545
.9633
.9706
.9767
.9817
.9857
.9890
.9916
.9936
.9952
.9964
.9974
.9981
.9986
.9990
Copyright Reserved
90
t – distribution tables:
Area or
Probability
Symmetric around 0.
Degrees of freedom (df) = n – 1.
0
Degrees
of
freedom
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
t
Area in Upper Tail
0.20
1.376
1.061
0.978
0.941
0.920
0.906
0.896
0.889
0.883
0.879
0.876
0.873
0.870
0.868
0.866
0.865
0.863
0.862
0.861
0.860
0.859
0.858
0.858
0.857
0.856
0.856
0.855
0.855
0.854
0.854
0.853
0.853
0.853
0.852
0.852
0.852
0.851
0.851
0.851
0.851
0.850
0.850
0.850
0.850
0.850
0.850
0.849
0.849
0.849
0.849
0.10
3.078
1.886
1.638
1.533
1.476
1.440
1.415
1.397
1.383
1.372
1.363
1.356
1.350
1.345
1.341
1.337
1.333
1.330
1.328
1.325
1.323
1.321
1.319
1.318
1.316
1.315
1.314
1.313
1.311
1.310
1.309
1.309
1.308
1.307
1.306
1.306
1.305
1.304
1.304
1.303
1.303
1.302
1.302
1.301
1.301
1.300
1.300
1.299
1.299
1.299
0.05
6.314
2.920
2.353
2.132
2.015
1.943
1.895
1.860
1.833
1.812
1.796
1.782
1.771
1.761
1.753
1.746
1.740
1.734
1.729
1.725
1.721
1.717
1.714
1.711
1.708
1.706
1.703
1.701
1.699
1.697
1.696
1.694
1.692
1.691
1.690
1.688
1.687
1.686
1.685
1.684
1.683
1.682
1.681
1.680
1.679
1.679
1.678
1.677
1.677
1.676
0.025
12.706
4.303
3.182
2.776
2.571
2.447
2.365
2.306
2.262
2.228
2.201
2.179
2.160
2.145
2.131
2.120
2.110
2.101
2.093
2.086
2.080
2.074
2.069
2.064
2.060
2.056
2.052
2.048
2.045
2.042
2.040
2.037
2.035
2.032
2.030
2.028
2.026
2.024
2.023
2.021
2.020
2.018
2.017
2.015
2.014
2.013
2.012
2.011
2.010
2.009
0.01
31.821
6.965
4.541
3.747
3.365
3.143
2.998
2.896
2.821
2.764
2.718
2.681
2.650
2.624
2.602
2.583
2.567
2.552
2.539
2.528
2.518
2.508
2.500
2.492
2.485
2.479
2.473
2.467
2.462
2.457
2.453
2.449
2.445
2.441
2.438
2.434
2.431
2.429
2.426
2.423
2.421
2.418
2.416
2.414
2.412
2.410
2.408
2.407
2.405
2.403
0.005
63.657
9.925
5.841
4.604
4.032
3.707
3.499
3.355
3.250
3.169
3.106
3.055
3.012
2.977
2.947
2.921
2.898
2.878
2.861
2.845
2.831
2.819
2.807
2.797
2.787
2.779
2.771
2.763
2.756
2.750
2.744
2.738
2.733
2.728
2.724
2.719
2.715
2.712
2.708
2.704
2.701
2.698
2.695
2.692
2.690
2.687
2.685
2.682
2.680
2.678
Copyright Reserved
91
t distribution (Continued)
Degrees
of
freedom
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
∞
Area in Upper Tail
0.20
0.10
0.05
0.025
0.01
0.005
0.849
0.849
0.848
0.848
0.848
0.848
0.848
0.848
0.848
0.848
0.848
0.847
0.847
0.847
0.847
0.847
0.847
0.847
0.847
0.847
0.847
0.847
0.847
0.847
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.846
0.845
0.845
0.845
0.845
0.845
0.845
0.845
0.842
1.298
1.298
1.298
1.297
1.297
1.297
1.297
1.296
1.296
1.296
1.296
1.295
1.295
1.295
1.295
1.295
1.294
1.294
1.294
1.294
1.294
1.293
1.293
1.293
1.293
1.293
1.293
1.292
1.292
1.292
1.292
1.292
1.292
1.292
1.292
1.291
1.291
1.291
1.291
1.291
1.291
1.291
1.291
1.291
1.291
1.290
1.290
1.290
1.290
1.290
1.282
1.675
1.675
1.674
1.674
1.673
1.673
1.672
1.672
1.671
1.671
1.670
1.670
1.669
1.669
1.669
1.668
1.668
1.668
1.667
1.667
1.667
1.666
1.666
1.666
1.665
1.665
1.665
1.665
1.664
1.664
1.664
1.664
1.663
1.663
1.663
1.663
1.663
1.662
1.662
1.662
1.662
1.662
1.661
1.661
1.661
1.661
1.661
1.661
1.660
1.660
1.645
2.008
2.007
2.006
2.005
2.004
2.003
2.002
2.002
2.001
2.000
2.000
1.999
1.998
1.998
1.997
1.997
1.996
1.995
1.995
1.994
1.994
1.993
1.993
1.993
1.992
1.992
1.991
1.991
1.990
1.990
1.990
1.989
1.989
1.989
1.988
1.988
1.988
1.987
1.987
1.987
1.986
1.986
1.986
1.986
1.985
1.985
1.985
1.984
1.984
1.984
1.960
2.402
2.400
2.399
2.397
2.396
2.395
2.394
2.392
2.391
2.390
2.389
2.388
2.387
2.386
2.385
2.384
2.383
2.382
2.382
2.381
2.380
2.379
2.379
2.378
2.377
2.376
2.376
2.375
2.374
2.374
2.373
2.373
2.372
2.372
2.371
2.370
2.370
2.369
2.369
2.368
2.368
2.368
2.367
2.367
2.366
2.366
2.365
2.365
2.365
2.364
2.326
2.676
2.674
2.672
2.670
2.668
2.667
2.665
2.663
2.662
2.660
2.659
2.657
2.656
2.655
2.654
2.652
2.651
2.650
2.649
2.648
2.647
2.646
2.645
2.644
2.643
2.642
2.641
2.640
2.639
2.639
2.638
2.637
2.636
2.636
2.635
2.634
2.634
2.633
2.632
2.632
2.631
2.630
2.630
2.629
2.629
2.628
2.627
2.627
2.626
2.626
2.576
Note:
As the sample size increases (and therefore the degrees of freedom increase), the t-values
converge to the z-values for corresponding levels of 𝛼.
Copyright Reserved
92
Probability tables for the F distribution
Area / Upper
probability
Denominator
df (𝝂𝟐 )
Entries in the table give 𝐹𝜈1 ,𝜈2 ; 𝛼 values, where 𝛼 is the area or probability in the upper tail of the F distribution.
Numerator df (𝝂𝟏 )
1
2
3
4
5
6
7
8
9
10
15
20
25
30
40
60
100
1000
1
0.1
0.05
0.025
0.01
39.86
161.45
647.79
4052.18
49.50
199.50
799.50
4999.50
53.59
215.71
864.16
5403.35
55.83
224.58
899.58
5624.58
57.24
230.16
921.85
5763.65
58.20
233.99
937.11
5858.99
58.91
236.77
948.22
5928.36
59.44
238.88
956.66
5981.07
59.86
240.54
963.28
6022.47
60.19
241.88
968.63
6055.85
61.22
245.95
984.87
6157.28
61.74
248.01
993.10
6208.73
62.05
249.26
998.08
6239.83
62.26
250.10
1001.41
6260.65
62.53
251.14
1005.60
6286.78
62.79
252.20
1009.80
6313.03
63.01
253.04
1013.17
6334.11
63.30
254.19
1017.75
6362.68
2
0.1
0.05
0.025
0.01
8.53
18.51
38.51
98.50
9.00
19.00
39.00
99.00
9.16
19.16
39.17
99.17
9.24
19.25
39.25
99.25
9.29
19.30
39.30
99.30
9.33
19.33
39.33
99.33
9.35
19.35
39.36
99.36
9.37
19.37
39.37
99.37
9.38
19.38
39.39
99.39
9.39
19.40
39.40
99.40
9.42
19.43
39.43
99.43
9.44
19.45
39.45
99.45
9.45
19.46
39.46
99.46
9.46
19.46
39.46
99.47
9.47
19.47
39.47
99.47
9.47
19.48
39.48
99.48
9.48
19.49
39.49
99.49
9.49
19.49
39.50
99.50
3
0.1
0.05
0.025
0.01
5.54
10.13
17.44
34.12
5.46
9.55
16.04
30.82
5.39
9.28
15.44
29.46
5.34
9.12
15.10
28.71
5.31
9.01
14.88
28.24
5.28
8.94
14.73
27.91
5.27
8.89
14.62
27.67
5.25
8.85
14.54
27.49
5.24
8.81
14.47
27.35
5.23
8.79
14.42
27.23
5.20
8.70
14.25
26.87
5.18
8.66
14.17
26.69
5.17
8.63
14.12
26.58
5.17
8.62
14.08
26.50
5.16
8.59
14.04
26.41
5.15
8.57
13.99
26.32
5.14
8.55
13.96
26.24
5.13
8.53
13.91
26.14
4
0.1
0.05
0.025
0.01
4.54
7.71
12.22
21.20
4.32
6.94
10.65
18.00
4.19
6.59
9.98
16.69
4.11
6.39
9.60
15.98
4.05
6.26
9.36
15.52
4.01
6.16
9.20
15.21
3.98
6.09
9.07
14.98
3.95
6.04
8.98
14.80
3.94
6.00
8.90
14.66
3.92
5.96
8.84
14.55
3.87
5.86
8.66
14.20
3.84
5.80
8.56
14.02
3.83
5.77
8.50
13.91
3.82
5.75
8.46
13.84
3.80
5.72
8.41
13.75
3.79
5.69
8.36
13.65
3.78
5.66
8.32
13.58
3.76
5.63
8.26
13.47
5
0.1
0.05
0.025
0.01
4.06
6.61
10.01
16.26
3.78
5.79
8.43
13.27
3.62
5.41
7.76
12.06
3.52
5.19
7.39
11.39
3.45
5.05
7.15
10.97
3.40
4.95
6.98
10.67
3.37
4.88
6.85
10.46
3.34
4.82
6.76
10.29
3.32
4.77
6.68
10.16
3.30
4.74
6.62
10.05
3.24
4.62
6.43
9.72
3.21
4.56
6.33
9.55
3.19
4.52
6.27
9.45
3.17
4.50
6.23
9.38
3.16
4.46
6.18
9.29
3.14
4.43
6.12
9.20
3.13
4.41
6.08
9.13
3.11
4.37
6.02
9.03
6
0.1
0.05
0.025
0.01
3.78
5.99
8.81
13.75
3.46
5.14
7.26
10.92
3.29
4.76
6.60
9.78
3.18
4.53
6.23
9.15
3.11
4.39
5.99
8.75
3.05
4.28
5.82
8.47
3.01
4.21
5.70
8.26
2.98
4.15
5.60
8.10
2.96
4.10
5.52
7.98
2.94
4.06
5.46
7.87
2.87
3.94
5.27
7.56
2.84
3.87
5.17
7.40
2.81
3.83
5.11
7.30
2.80
3.81
5.07
7.23
2.78
3.77
5.01
7.14
2.76
3.74
4.96
7.06
2.75
3.71
4.92
6.99
2.72
3.67
4.86
6.89
Copyright Reserved
93
Area / Upper
probability
Denominator
df (𝝂𝟐 )
7
0.1
0.05
0.025
0.01
3.59
5.59
8.07
12.25
3.26
4.74
6.54
9.55
3.07
4.35
5.89
8.45
2.96
4.12
5.52
7.85
2.88
3.97
5.29
7.46
2.83
3.87
5.12
7.19
2.78
3.79
4.99
6.99
2.75
3.73
4.90
6.84
2.72
3.68
4.82
6.72
2.70
3.64
4.76
6.62
2.63
3.51
4.57
6.31
2.59
3.44
4.47
6.16
2.57
3.40
4.40
6.06
2.56
3.38
4.36
5.99
2.54
3.34
4.31
5.91
2.51
3.30
4.25
5.82
2.50
3.27
4.21
5.75
2.47
3.23
4.15
5.66
Numerator df (𝝂𝟏 )
1
2
3
4
5
6
7
8
9
10
15
20
25
30
40
60
100
1000
8
0.1
0.05
0.025
0.01
3.46
5.32
7.57
11.26
3.11
4.46
6.06
8.65
2.92
4.07
5.42
7.59
2.81
3.84
5.05
7.01
2.73
3.69
4.82
6.63
2.67
3.58
4.65
6.37
2.62
3.50
4.53
6.18
2.59
3.44
4.43
6.03
2.56
3.39
4.36
5.91
2.54
3.35
4.30
5.81
2.46
3.22
4.10
5.52
2.42
3.15
4.00
5.36
2.40
3.11
3.94
5.26
2.38
3.08
3.89
5.20
2.36
3.04
3.84
5.12
2.34
3.01
3.78
5.03
2.32
2.97
3.74
4.96
2.30
2.93
3.68
4.87
9
0.1
0.05
0.025
0.01
3.36
5.12
7.21
10.56
3.01
4.26
5.71
8.02
2.81
3.86
5.08
6.99
2.69
3.63
4.72
6.42
2.61
3.48
4.48
6.06
2.55
3.37
4.32
5.80
2.51
3.29
4.20
5.61
2.47
3.23
4.10
5.47
2.44
3.18
4.03
5.35
2.42
3.14
3.96
5.26
2.34
3.01
3.77
4.96
2.30
2.94
3.67
4.81
2.27
2.89
3.60
4.71
2.25
2.86
3.56
4.65
2.23
2.83
3.51
4.57
2.21
2.79
3.45
4.48
2.19
2.76
3.40
4.41
2.16
2.71
3.34
4.32
10
0.1
0.05
0.025
0.01
3.29
4.96
6.94
10.04
2.92
4.10
5.46
7.56
2.73
3.71
4.83
6.55
2.61
3.48
4.47
5.99
2.52
3.33
4.24
5.64
2.46
3.22
4.07
5.39
2.41
3.14
3.95
5.20
2.38
3.07
3.85
5.06
2.35
3.02
3.78
4.94
2.32
2.98
3.72
4.85
2.24
2.85
3.52
4.56
2.20
2.77
3.42
4.41
2.17
2.73
3.35
4.31
2.16
2.70
3.31
4.25
2.13
2.66
3.26
4.17
2.11
2.62
3.20
4.08
2.09
2.59
3.15
4.01
2.06
2.54
3.09
3.92
11
0.1
0.05
0.025
0.01
3.23
4.84
6.72
9.65
2.86
3.98
5.26
7.21
2.66
3.59
4.63
6.22
2.54
3.36
4.28
5.67
2.45
3.20
4.04
5.32
2.39
3.09
3.88
5.07
2.34
3.01
3.76
4.89
2.30
2.95
3.66
4.74
2.27
2.90
3.59
4.63
2.25
2.85
3.53
4.54
2.17
2.72
3.33
4.25
2.12
2.65
3.23
4.10
2.10
2.60
3.16
4.01
2.08
2.57
3.12
3.94
2.05
2.53
3.06
3.86
2.03
2.49
3.00
3.78
2.01
2.46
2.96
3.71
1.98
2.41
2.89
3.61
12
0.1
0.05
0.025
0.01
3.18
4.75
6.55
9.33
2.81
3.89
5.10
6.93
2.61
3.49
4.47
5.95
2.48
3.26
4.12
5.41
2.39
3.11
3.89
5.06
2.33
3.00
3.73
4.82
2.28
2.91
3.61
4.64
2.24
2.85
3.51
4.50
2.21
2.80
3.44
4.39
2.19
2.75
3.37
4.30
2.10
2.62
3.18
4.01
2.06
2.54
3.07
3.86
2.03
2.50
3.01
3.76
2.01
2.47
2.96
3.70
1.99
2.43
2.91
3.62
1.96
2.38
2.85
3.54
1.94
2.35
2.80
3.47
1.91
2.30
2.73
3.37
13
0.1
0.05
0.025
0.01
3.14
4.67
6.41
9.07
2.76
3.81
4.97
6.70
2.56
3.41
4.35
5.74
2.43
3.18
4.00
5.21
2.35
3.03
3.77
4.86
2.28
2.92
3.60
4.62
2.23
2.83
3.48
4.44
2.20
2.77
3.39
4.30
2.16
2.71
3.31
4.19
2.14
2.67
3.25
4.10
2.05
2.53
3.05
3.82
2.01
2.46
2.95
3.66
1.98
2.41
2.88
3.57
1.96
2.38
2.84
3.51
1.93
2.34
2.78
3.43
1.90
2.30
2.72
3.34
1.88
2.26
2.67
3.27
1.85
2.21
2.60
3.18
14
0.1
0.05
0.025
0.01
3.10
4.60
6.30
8.86
2.73
3.74
4.86
6.51
2.52
3.34
4.24
5.56
2.39
3.11
3.89
5.04
2.31
2.96
3.66
4.69
2.24
2.85
3.50
4.46
2.19
2.76
3.38
4.28
2.15
2.70
3.29
4.14
2.12
2.65
3.21
4.03
2.10
2.60
3.15
3.94
2.01
2.46
2.95
3.66
1.96
2.39
2.84
3.51
1.93
2.34
2.78
3.41
1.91
2.31
2.73
3.35
1.89
2.27
2.67
3.27
1.86
2.22
2.61
3.18
1.83
2.19
2.56
3.11
1.80
2.14
2.50
3.02
Copyright Reserved
94
2.70
3.68
4.77
6.36
2.49
3.29
4.15
5.42
2.36
3.06
3.80
4.89
2.27
2.90
3.58
4.56
2.21
2.79
3.41
4.32
2.16
2.71
3.29
4.14
2.12
2.64
3.20
4.00
2.09
2.59
3.12
3.89
2.06
2.54
3.06
3.80
1.97
2.40
2.86
3.52
1.92
2.33
2.76
3.37
1.89
2.28
2.69
3.28
1.87
2.25
2.64
3.21
1.85
2.20
2.59
3.13
1.82
2.16
2.52
3.05
1.79
2.12
2.47
2.98
1.76
2.07
2.40
2.88
16
0.1
0.05
0.025
0.01
3.05
4.49
6.12
8.53
2.67
3.63
4.69
6.23
2.46
3.24
4.08
5.29
2.33
3.01
3.73
4.77
2.24
2.85
3.50
4.44
2.18
2.74
3.34
4.20
2.13
2.66
3.22
4.03
2.09
2.59
3.12
3.89
2.06
2.54
3.05
3.78
2.03
2.49
2.99
3.69
1.94
2.35
2.79
3.41
1.89
2.28
2.68
3.26
1.86
2.23
2.61
3.16
1.84
2.19
2.57
3.10
1.81
2.15
2.51
3.02
1.78
2.11
2.45
2.93
1.76
2.07
2.40
2.86
1.72
2.02
2.32
2.76
Area / Upper
probability
3.07
4.54
6.20
8.68
Denominator
df (𝝂𝟐 )
15
0.1
0.05
0.025
0.01
Numerator df (𝝂𝟏 )
1
2
3
4
5
6
7
8
9
10
15
20
25
30
40
60
100
1000
17
0.1
0.05
0.025
0.01
3.03
4.45
6.04
8.40
2.64
3.59
4.62
6.11
2.44
3.20
4.01
5.18
2.31
2.96
3.66
4.67
2.22
2.81
3.44
4.34
2.15
2.70
3.28
4.10
2.10
2.61
3.16
3.93
2.06
2.55
3.06
3.79
2.03
2.49
2.98
3.68
2.00
2.45
2.92
3.59
1.91
2.31
2.72
3.31
1.86
2.23
2.62
3.16
1.83
2.18
2.55
3.07
1.81
2.15
2.50
3.00
1.78
2.10
2.44
2.92
1.75
2.06
2.38
2.83
1.73
2.02
2.33
2.76
1.69
1.97
2.26
2.66
18
0.1
0.05
0.025
0.01
3.01
4.41
5.98
8.29
2.62
3.55
4.56
6.01
2.42
3.16
3.95
5.09
2.29
2.93
3.61
4.58
2.20
2.77
3.38
4.25
2.13
2.66
3.22
4.01
2.08
2.58
3.10
3.84
2.04
2.51
3.01
3.71
2.00
2.46
2.93
3.60
1.98
2.41
2.87
3.51
1.89
2.27
2.67
3.23
1.84
2.19
2.56
3.08
1.80
2.14
2.49
2.98
1.78
2.11
2.44
2.92
1.75
2.06
2.38
2.84
1.72
2.02
2.32
2.75
1.70
1.98
2.27
2.68
1.66
1.92
2.20
2.58
19
0.1
0.05
0.025
0.01
2.99
4.38
5.92
8.18
2.61
3.52
4.51
5.93
2.40
3.13
3.90
5.01
2.27
2.90
3.56
4.50
2.18
2.74
3.33
4.17
2.11
2.63
3.17
3.94
2.06
2.54
3.05
3.77
2.02
2.48
2.96
3.63
1.98
2.42
2.88
3.52
1.96
2.38
2.82
3.43
1.86
2.23
2.62
3.15
1.81
2.16
2.51
3.00
1.78
2.11
2.44
2.91
1.76
2.07
2.39
2.84
1.73
2.03
2.33
2.76
1.70
1.98
2.27
2.67
1.67
1.94
2.22
2.60
1.64
1.88
2.14
2.50
20
0.1
0.05
0.025
0.01
2.97
4.35
5.87
8.10
2.59
3.49
4.46
5.85
2.38
3.10
3.86
4.94
2.25
2.87
3.51
4.43
2.16
2.71
3.29
4.10
2.09
2.60
3.13
3.87
2.04
2.51
3.01
3.70
2.00
2.45
2.91
3.56
1.96
2.39
2.84
3.46
1.94
2.35
2.77
3.37
1.84
2.20
2.57
3.09
1.79
2.12
2.46
2.94
1.76
2.07
2.40
2.84
1.74
2.04
2.35
2.78
1.71
1.99
2.29
2.69
1.68
1.95
2.22
2.61
1.65
1.91
2.17
2.54
1.61
1.85
2.09
2.43
21
0.1
0.05
0.025
0.01
2.96
4.32
5.83
8.02
2.57
3.47
4.42
5.78
2.36
3.07
3.82
4.87
2.23
2.84
3.48
4.37
2.14
2.68
3.25
4.04
2.08
2.57
3.09
3.81
2.02
2.49
2.97
3.64
1.98
2.42
2.87
3.51
1.95
2.37
2.80
3.40
1.92
2.32
2.73
3.31
1.83
2.18
2.53
3.03
1.78
2.10
2.42
2.88
1.74
2.05
2.36
2.79
1.72
2.01
2.31
2.72
1.69
1.96
2.25
2.64
1.66
1.92
2.18
2.55
1.63
1.88
2.13
2.48
1.59
1.82
2.05
2.37
22
0.1
0.05
0.025
0.01
2.95
4.30
5.79
7.95
2.56
3.44
4.38
5.72
2.35
3.05
3.78
4.82
2.22
2.82
3.44
4.31
2.13
2.66
3.22
3.99
2.06
2.55
3.05
3.76
2.01
2.46
2.93
3.59
1.97
2.40
2.84
3.45
1.93
2.34
2.76
3.35
1.90
2.30
2.70
3.26
1.81
2.15
2.50
2.98
1.76
2.07
2.39
2.83
1.73
2.02
2.32
2.73
1.70
1.98
2.27
2.67
1.67
1.94
2.21
2.58
1.64
1.89
2.14
2.50
1.61
1.85
2.09
2.42
1.57
1.79
2.01
2.32
Copyright Reserved
95
2.55
3.42
4.35
5.66
2.34
3.03
3.75
4.76
2.21
2.80
3.41
4.26
2.11
2.64
3.18
3.94
2.05
2.53
3.02
3.71
1.99
2.44
2.90
3.54
1.95
2.37
2.81
3.41
1.92
2.32
2.73
3.30
1.89
2.27
2.67
3.21
1.80
2.13
2.47
2.93
1.74
2.05
2.36
2.78
1.71
2.00
2.29
2.69
1.69
1.96
2.24
2.62
1.66
1.91
2.18
2.54
1.62
1.86
2.11
2.45
1.59
1.82
2.06
2.37
1.55
1.76
1.98
2.27
24
0.1
0.05
0.025
0.01
2.93
4.26
5.72
7.82
2.54
3.40
4.32
5.61
2.33
3.01
3.72
4.72
2.19
2.78
3.38
4.22
2.10
2.62
3.15
3.90
2.04
2.51
2.99
3.67
1.98
2.42
2.87
3.50
1.94
2.36
2.78
3.36
1.91
2.30
2.70
3.26
1.88
2.25
2.64
3.17
1.78
2.11
2.44
2.89
1.73
2.03
2.33
2.74
1.70
1.97
2.26
2.64
1.67
1.94
2.21
2.58
1.64
1.89
2.15
2.49
1.61
1.84
2.08
2.40
1.58
1.80
2.02
2.33
1.54
1.74
1.94
2.22
25
0.1
0.05
0.025
0.01
2.92
4.24
5.69
7.77
2.53
3.39
4.29
5.57
2.32
2.99
3.69
4.68
2.18
2.76
3.35
4.18
2.09
2.60
3.13
3.85
2.02
2.49
2.97
3.63
1.97
2.40
2.85
3.46
1.93
2.34
2.75
3.32
1.89
2.28
2.68
3.22
1.87
2.24
2.61
3.13
1.77
2.09
2.41
2.85
1.72
2.01
2.30
2.70
1.68
1.96
2.23
2.60
1.66
1.92
2.18
2.54
1.63
1.87
2.12
2.45
1.59
1.82
2.05
2.36
1.56
1.78
2.00
2.29
1.52
1.72
1.91
2.18
Area / Upper
probability
2.94
4.28
5.75
7.88
Denominator
df (𝝂𝟐 )
23
0.1
0.05
0.025
0.01
Numerator df (𝝂𝟏 )
1
2
3
4
5
6
7
8
9
10
15
20
25
30
40
60
100
1000
26
0.1
0.05
0.025
0.01
2.91
4.23
5.66
7.72
2.52
3.37
4.27
5.53
2.31
2.98
3.67
4.64
2.17
2.74
3.33
4.14
2.08
2.59
3.10
3.82
2.01
2.47
2.94
3.59
1.96
2.39
2.82
3.42
1.92
2.32
2.73
3.29
1.88
2.27
2.65
3.18
1.86
2.22
2.59
3.09
1.76
2.07
2.39
2.81
1.71
1.99
2.28
2.66
1.67
1.94
2.21
2.57
1.65
1.90
2.16
2.50
1.61
1.85
2.09
2.42
1.58
1.80
2.03
2.33
1.55
1.76
1.97
2.25
1.51
1.70
1.89
2.14
27
0.1
0.05
0.025
0.01
2.90
4.21
5.63
7.68
2.51
3.35
4.24
5.49
2.30
2.96
3.65
4.60
2.17
2.73
3.31
4.11
2.07
2.57
3.08
3.78
2.00
2.46
2.92
3.56
1.95
2.37
2.80
3.39
1.91
2.31
2.71
3.26
1.87
2.25
2.63
3.15
1.85
2.20
2.57
3.06
1.75
2.06
2.36
2.78
1.70
1.97
2.25
2.63
1.66
1.92
2.18
2.54
1.64
1.88
2.13
2.47
1.60
1.84
2.07
2.38
1.57
1.79
2.00
2.29
1.54
1.74
1.94
2.22
1.50
1.68
1.86
2.11
28
0.1
0.05
0.025
0.01
2.89
4.20
5.61
7.64
2.50
3.34
4.22
5.45
2.29
2.95
3.63
4.57
2.16
2.71
3.29
4.07
2.06
2.56
3.06
3.75
2.00
2.45
2.90
3.53
1.94
2.36
2.78
3.36
1.90
2.29
2.69
3.23
1.87
2.24
2.61
3.12
1.84
2.19
2.55
3.03
1.74
2.04
2.34
2.75
1.69
1.96
2.23
2.60
1.65
1.91
2.16
2.51
1.63
1.87
2.11
2.44
1.59
1.82
2.05
2.35
1.56
1.77
1.98
2.26
1.53
1.73
1.92
2.19
1.48
1.66
1.84
2.08
29
0.1
0.05
0.025
0.01
2.89
4.18
5.59
7.60
2.50
3.33
4.20
5.42
2.28
2.93
3.61
4.54
2.15
2.70
3.27
4.04
2.06
2.55
3.04
3.73
1.99
2.43
2.88
3.50
1.93
2.35
2.76
3.33
1.89
2.28
2.67
3.20
1.86
2.22
2.59
3.09
1.83
2.18
2.53
3.00
1.73
2.03
2.32
2.73
1.68
1.94
2.21
2.57
1.64
1.89
2.14
2.48
1.62
1.85
2.09
2.41
1.58
1.81
2.03
2.33
1.55
1.75
1.96
2.23
1.52
1.71
1.90
2.16
1.47
1.65
1.82
2.05
30
0.1
0.05
0.025
0.01
2.88
4.17
5.57
7.56
2.49
3.32
4.18
5.39
2.28
2.92
3.59
4.51
2.14
2.69
3.25
4.02
2.05
2.53
3.03
3.70
1.98
2.42
2.87
3.47
1.93
2.33
2.75
3.30
1.88
2.27
2.65
3.17
1.85
2.21
2.57
3.07
1.82
2.16
2.51
2.98
1.72
2.01
2.31
2.70
1.67
1.93
2.20
2.55
1.63
1.88
2.12
2.45
1.61
1.84
2.07
2.39
1.57
1.79
2.01
2.30
1.54
1.74
1.94
2.21
1.51
1.70
1.88
2.13
1.46
1.63
1.80
2.02
Copyright Reserved
96
40
0.1
0.05
0.025
0.01
2.84
4.08
5.42
7.31
2.44
3.23
4.05
5.18
2.23
2.84
3.46
4.31
2.09
2.61
3.13
3.83
2.00
2.45
2.90
3.51
1.93
2.34
2.74
3.29
1.87
2.25
2.62
3.12
1.83
2.18
2.53
2.99
1.79
2.12
2.45
2.89
1.76
2.08
2.39
2.80
1.66
1.92
2.18
2.52
1.61
1.84
2.07
2.37
1.57
1.78
1.99
2.27
1.54
1.74
1.94
2.20
1.51
1.69
1.88
2.11
1.47
1.64
1.80
2.02
1.43
1.59
1.74
1.94
1.38
1.52
1.65
1.82
60
0.1
0.05
0.025
0.01
2.79
4.00
5.29
7.08
2.39
3.15
3.93
4.98
2.18
2.76
3.34
4.13
2.04
2.53
3.01
3.65
1.95
2.37
2.79
3.34
1.87
2.25
2.63
3.12
1.82
2.17
2.51
2.95
1.77
2.10
2.41
2.82
1.74
2.04
2.33
2.72
1.71
1.99
2.27
2.63
1.60
1.84
2.06
2.35
1.54
1.75
1.94
2.20
1.50
1.69
1.87
2.10
1.48
1.65
1.82
2.03
1.44
1.59
1.74
1.94
1.40
1.53
1.67
1.84
1.36
1.48
1.60
1.75
1.30
1.40
1.49
1.62
100
0.1
0.05
0.025
0.01
2.76
3.94
5.18
6.90
2.36
3.09
3.83
4.82
2.14
2.70
3.25
3.98
2.00
2.46
2.92
3.51
1.91
2.31
2.70
3.21
1.83
2.19
2.54
2.99
1.78
2.10
2.42
2.82
1.73
2.03
2.32
2.69
1.69
1.97
2.24
2.59
1.66
1.93
2.18
2.50
1.56
1.77
1.97
2.22
1.49
1.68
1.85
2.07
1.45
1.62
1.77
1.97
1.42
1.57
1.71
1.89
1.38
1.52
1.64
1.80
1.34
1.45
1.56
1.69
1.29
1.39
1.48
1.60
1.22
1.30
1.36
1.45
1000
0.1
0.05
0.025
0.01
2.71
3.85
5.04
6.66
2.31
3.00
3.70
4.63
2.09
2.61
3.13
3.80
1.95
2.38
2.80
3.34
1.85
2.22
2.58
3.04
1.78
2.11
2.42
2.82
1.72
2.02
2.30
2.66
1.68
1.95
2.20
2.53
1.64
1.89
2.13
2.43
1.61
1.84
2.06
2.34
1.49
1.68
1.85
2.06
1.43
1.58
1.72
1.90
1.38
1.52
1.64
1.79
1.35
1.47
1.58
1.72
1.30
1.41
1.50
1.61
1.25
1.33
1.41
1.50
1.20
1.26
1.32
1.38
1.08
1.11
1.13
1.16
Copyright Reserved
97
WST143 Formula list
𝑛
1
𝑓(𝑥) = { 𝑏 − 𝑎 ,
0 ,
𝐸(𝑋) =
𝑎≤𝑥≤𝑏
𝑋̅ =
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
1
∑ 𝑋𝑖
𝑛
𝑖=1
𝑎+𝑏
2
𝑣𝑎𝑟(𝑋) =
𝐸(𝑋̅) = 𝜇
𝜎𝑋̅ =
𝐸(𝑝̅ ) = 𝑝
𝜎𝑝̅ = √
𝑋̅ − 𝜇
𝜎𝑋̅
𝑍=
𝑍=
(𝑏 − 𝑎)2
12
𝜎
√𝑛
𝑝(1 − 𝑝)
𝑛
𝑝̅ − 𝑝
𝜎𝑝̅
Area of triangle = 0.5(base)(perpendicular height)
Area of rectangle = (base)(height)
𝐸(𝑎𝑋 + 𝑏) = 𝑎𝐸(𝑋) + 𝑏
𝑣𝑎𝑟(𝑎𝑋 + 𝑏) = 𝑎2 𝑣𝑎𝑟(𝑋)
𝑋̅ ± 𝑧𝛼⁄2
𝑋̅ ± 𝑡𝛼⁄2
𝜎
𝑝̅ =
√𝑛
𝑆
𝑋
𝑛
𝑝̅ (1 − 𝑝̅)
𝑝̅ ± 𝑧𝛼⁄2 √
𝑛
√𝑛
𝜎12 𝜎22
𝑋̅1 − 𝑋̅2 ± 𝑧𝛼⁄2 √ +
𝑛1 𝑛2
𝑝1 (1 − 𝑝1 ) 𝑝2 (1 − 𝑝2 )
𝑝̅1 − 𝑝̅2 ± 𝑧𝛼⁄2 √
+
𝑛1
𝑛2
𝑋̅ − 𝜇0
𝑍= 𝜎
⁄ 𝑛
√
𝑧𝛼⁄ 𝜎 2
𝑛=( 2 )
𝐸
𝑇=
𝑍=
𝑋̅ − 𝜇0
𝑆⁄
√𝑛
𝑍=
𝑝̅ − 𝑝0
√𝑝0 (1 − 𝑝0 )
𝑛
𝑋̅1 − 𝑋̅2 − 𝐷0
𝜎2
√ 1
𝑛1
𝑇=
+
𝑇=
𝜎22
𝑛2
𝑋̅1 − 𝑋̅2 − 𝐷0
𝑆𝑝 √
𝑍=
𝑤ℎ𝑒𝑟𝑒
1
1
+
𝑛1 𝑛2
𝑝̅1 − 𝑝̅2
√𝑝̅(1 − 𝑝̅ ) (
1
1
+ )
𝑛1 𝑛2
𝑆𝑝2 =
𝑤ℎ𝑒𝑟𝑒
̅ − 𝜇𝐷
𝐷
𝑆𝑑
⁄
√𝑛
(𝑛1 − 1)𝑆12 + (𝑛2 − 1)𝑆22
𝑛1 + 𝑛2 − 2
𝑝̅ =
𝑛1 𝑝̅1 + 𝑛2 𝑝̅2
𝑛1 + 𝑛2
Copyright Reserved
98
Optimisation Techniques
Supplemental Material
Reference:
Swanepoel A, Vivier F, Millard SM and Ehlers R, Quantitaive Statistical Techniques (Van Schaiks, 3rd
Edition, 2009)
Please note that the notes supplied to you for this section of your Module are compiled from the above
mentioned source
Chapter 2: Differentiation
2.1 – 2.3
Functions, Limits & Continuity
Class discussion only
2.4 Rates of change
Rate of change (RC)
∆𝑦
𝑅𝐶 = ∆𝑥
Two types
Average rate of change (ARC) over the interval [𝑥1 , 𝑥2 ] → Slope of the line segment
Instantaneous rate of change (IRC) at the point x → Slope of tangent
Example of ARC
The supply of a certain product (in 1000) is given by the following function
𝑦 = 𝑓(𝑥) = 6𝑥 + 𝑥 2
Calculate the ARC over the interval [5,10].
𝐴𝑅𝐶 =
𝑓(10)−𝑓(5)
10−5
=
OR
𝐴𝑅𝐶 =
𝑓(5)−𝑓(10)
5−10
=
where 𝑓(10) = 6(10) + 102 = 160 and 𝑓(5) = 6(5) + 52 = 5
Copyright Reserved
99
2.5 The derivative of a function
The derivative of a function can be found by differentiation.
Example of IRC
If 𝑓(𝑥) = 𝑥 2 then
𝑓(𝑥 + ℎ) − 𝑓(𝑥)
ℎ→0
ℎ
(𝑥 + ℎ)2 − 𝑥 2
= lim
ℎ→0
ℎ
𝑥 2 + 2𝑥ℎ + ℎ2 − 𝑥 2
= lim
ℎ→0
ℎ
2
2𝑥ℎ + ℎ
= lim
ℎ→0
ℎ
ℎ(2𝑥 + ℎ)
= lim
ℎ→0
ℎ
= lim 2𝑥 + ℎ
𝑓 ′ (𝑥) = lim
ℎ→0
= 2𝑥 + 0
∴ 𝑓 ′ (𝑥) = 2𝑥
Notation:
𝑓 ′ (𝑥)
𝑑𝑦
𝑑𝑥
𝑑
𝑑𝑥
𝑓(𝑥)
2.6 Rules of differentiation
Rule 1
If 𝑓(𝑥) = 𝑘, where k is a constant, then 𝑓 ′ (𝑥) = 0.
1. 𝑓(𝑥) = 5 then 𝑓 ′ (𝑥) =
2. 𝑓(𝑥) = 𝑥 0 =
then 𝑓 ′ (𝑥) =
Rule 2
If 𝑓(𝑥) = 𝑥 𝑛 , where n is a real number and 𝑛 ≠ 0, then 𝑓 ′ (𝑥) = 𝑛𝑥 𝑛−1 .
1. 𝑓(𝑥) = 𝑥 6 then 𝑓 ′ (𝑥) =
2. 𝑔(𝑥) = 𝑥 then 𝑔′ (𝑥) =
1
3. 𝑓(𝑥) = 𝑥 =
3
4. 𝑦 = √𝑥 2 =
5. 𝑓(𝑥) =
1
√𝑥
=
then 𝑓 ′ (𝑥) =
then
𝑑𝑦
𝑑𝑥
=
then 𝑓 ′ (𝑥) =
Copyright Reserved
100
Rule 3
If 𝑓(𝑥) = 𝑘𝑔(𝑥), where k is a constant, then 𝑓 ′ (𝑥) = 𝑘𝑔′ (𝑥).
1. 𝑓(𝑥) = 2𝑥 2 then 𝑓 ′ (𝑥) =
1
then 𝑓 ′ (𝑥) =
2. 𝑓(𝑥) = 2𝑥 =
𝑟
3. ℎ(𝑥) = −7𝑥 2 𝑡
then ℎ′ (𝑥) =
Rule 4
If 𝑓(𝑥) = 𝑔(𝑥) + ℎ(𝑥) then 𝑓 ′ (𝑥) = 𝑔′ (𝑥) + ℎ′ (𝑥).
If 𝑓(𝑥) = 𝑔(𝑥) − ℎ(𝑥) then 𝑓 ′ (𝑥) = 𝑔′ (𝑥) − ℎ′ (𝑥).
1. 𝑓(𝑥) = 3 + 𝑥 2 then 𝑓 ′ (𝑥) =
1
𝑑𝑟
2. 𝑟 = √2𝑡 − 𝑡 + 2𝑠. Calculate 𝑑𝑠 and
First we calculate
𝑑𝑟
𝑑𝑠
In order to calculate
𝑟 = √2𝑡
1⁄
2
𝑑𝑟
𝑑𝑡
.
= 0 − 0 + 2 = 2.
𝑑𝑟
𝑑𝑡
we first rewrite r as:
− 𝑡 −1 + 2𝑠 then
𝑑𝑟
𝑑𝑡
=
Example of Rules 1 to 4:
The price of a product (in Rand) depends on the quantity of the product sold and is given by
𝑝 = 350 − 0.08𝑞 − 0.002𝑞 2
(a)
Calculate the sales price if 40 items are sold.
(b)
Calculate the marginal income of the 40 items.
Copyright Reserved
101
Answers:
1. For 𝑞 = 40 we find 𝑝 = 350 − 0.08(40) − 0.002(40)2 =
2. The income function is
𝐼(𝑞) = 𝑝𝑞 = (350 − 0.08𝑞 − 0.002𝑞 2 )𝑞 = 350𝑞 − 0.08𝑞 2 − 0.002𝑞 3
The marginal income function 𝐼 ′ (𝑞) =
The marginal income for the 40 items is 𝐼 ′ (40) =
Rule 5 (Product Rule)
If 𝑓(𝑥) = 𝑔(𝑥) ∙ ℎ(𝑥), then 𝑓 ′ (𝑥) = ℎ(𝑥) ∙ 𝑔′ (𝑥) + 𝑔(𝑥) ∙ ℎ′ (𝑥).
1. 𝑓(𝑥) = 𝑥 2 (𝑥 − 6) then
𝑓 ′ (𝑥) =
2. 𝑔(𝑥) = (𝑥 2 + 3𝑥 − 4)(5𝑥 3 + 2𝑥) then
𝑔′ (𝑥) =
3. ℎ(𝑥) =
5
√
1
(𝑥 2 + 𝑥 2 )=
𝑥
then ℎ′ (𝑥) =
Copyright Reserved
102
Rule 6 (Quotient Rule)
If 𝑓(𝑥) =
𝑔(𝑥)
ℎ(𝑥)
, then it follows that 𝑓 ′ (𝑥) =
ℎ(𝑥)𝑔′ (𝑥)−𝑔(𝑥)ℎ′ (𝑥)
.
[ℎ(𝑥)]2
3𝑥
1. 𝑓(𝑥) = 𝑥 2 +1 then 𝑓 ′ (𝑥) =
6𝑥 2 −1
2. 𝑘(𝑥) = 𝑥 4 +5𝑥+1 then 𝑘 ′ (𝑥) =
1
𝑑𝑟
𝑑𝑟
3. Let 𝑟 = 𝑥 3 . We could calculate 𝑑𝑥 by rewriting r as 𝑟 = 𝑥 −3 and we get 𝑑𝑥 = (−3)𝑥 −4 =
This same question could also be answered using the quotient rule:
𝑑𝑟
𝑑𝑥
−3
𝑥4
.
=
Example of the quotient rule
500𝑥
The profit of tea produced is given by 𝑃(𝑥) = 𝑥+20 − 2𝑥 with x the amount in 100 kg and 𝑃(𝑥) the
profit in R1000.
1. Calculate the profit if 1500 kg of tea is produced
x = 15 (Note the unit!!)
𝑃(15) =
500(15)
15+20
− 2(15) = 184.28571 × 1000 (Note the unit!!)
= 𝑅184 285.71
2. Calculate the marginal profit function
𝑃′ (𝑥) =
(𝑥+20)×(500)−(500𝑥)×(1)
(𝑥+20)2
−2=
500𝑥+10 000−500𝑥
(𝑥+20)2
10 000
− 2 = (𝑥+20)2 − 2
3. Calculate the marginal profit if:
(a)
1500 kg of tea is produced
x = 15
10 000
𝑃′ (15) = (15+20)2 − 2 = 6.16327 × 1000 = 𝑅6 163.27
(b)
15000 kg of tea is produced
x = 150
10 000
𝑃′ (150) = (150+20)2 − 2 = −1.65398 × 1000 = −𝑅1 653.98
Copyright Reserved
103
Rule 7 (Chain Rule)
𝑑𝑦
If 𝑦 = 𝑓{𝑔(𝑥)} then 𝑑𝑥 = 𝑓 ′ {𝑔(𝑥)} ∙ 𝑔′ (𝑥).
1. 𝑓(𝑥) = (4𝑥 2 − 5𝑥 + 6)3 then 𝑓 ′ (𝑥) =
1
2. 𝑦 = (2𝑥 + 5)5 (3𝑥 2 + 7)2 then
𝑑𝑦
𝑑𝑥
=
1
𝑑𝑘
𝑑𝑘
3. 𝑘 = 𝑥 4 +𝑥 2 +1. In this form we can find 𝑑𝑥 using the quotient rule. If we rewrite k we can find 𝑑𝑥
using the chain rule.
1
Re-writing k we find, 𝑘 = 𝑥 4 +𝑥 2 +1 = (𝑥 4 + 𝑥 2 + 1)−1
𝑑𝑘
𝑑𝑥
=
4. 𝑦 = √𝑥 3 + 5 =
𝑑𝑦
𝑑𝑥
=
Copyright Reserved
104
Example
1
Calculate the equation of the tangent line of 𝑓(𝑥) = 𝑥−1 at 𝑥 = 3.
Answer
The equation of a line can be obtained using the equation 𝑦 = 𝑦1 + 𝑏(𝑥 − 𝑥1 ).
Firstly, we need one co-ordinate (𝑥1 , 𝑦1 ).
1
1
Clearly 𝑥1 = 3. To calculate 𝑦1 we use 𝑦1 = 𝑓(𝑥1 ) = 𝑓(3) = 3−1 = 2.
Therefore, (𝑥1 , 𝑦1 ) = (3, 0.5).
To obtain the value of b, we need the derivative:
1
𝑓(𝑥) = 𝑥−1 = (𝑥 − 1)−1
𝑓 ′ (𝑥) =
𝑓 ′ (3) = 𝑏 =
Now will substitute in the values of 𝑥1 , 𝑦1 and b into the slope-point formula:
𝑦 = 𝑦1 + 𝑏(𝑥 − 𝑥1 )
Note:
If the equation of the tangent line is asked, the answer is 𝑦 = 1.25 − 0.25𝑥.
If only the intercept is asked, the answer is 1.25.
If only the slope is asked, the answer is -0.25.
Copyright Reserved
105
2.7 Inverse functions and their derivatives
Consider the following function 𝑦 = 3𝑥 + 2
The inverse function of 𝑦 = 𝑓(𝑥) is:
𝑦 = 3𝑥 + 2
3𝑥 = 𝑦 − 2
1
2
𝑥 = 3 𝑦 − 3 (Inverse function)
𝑥 = 𝑔(𝑦) = 𝑓 −1 (𝑦) (Inverse function)
Note:
𝑑𝑦
𝑑𝑥
=
𝑑𝑥
𝑑𝑦
=
Rule 8
𝑑𝑦
𝑑𝑥
-
=
1
or
𝑑𝑥
𝑑𝑦
𝑑𝑥
𝑑𝑦
=
1
𝑑𝑦
𝑑𝑥
NOTE: Rule 8 only holds for one to one functions.
𝑦 = 𝑥 2 + 5 wouldn’t work
Graph
30
25
20
y
15
10
-4
-2
5
0
2
4
x
Important:
Although one can use Rule 8 to find the derivative of an inverse function; there is an easier way to
find the derivative of an inverse function. If you want to find
𝑑𝑥
𝑑𝑦
then you can rewrite the equation so
that x is on the left hand side and the other variables and constants are on the right hand side.
For example,
𝑦 = (𝑥 − 2)3
𝑦 = (𝑥 − 2)3
𝑑𝑦
= 3(𝑥 − 2)2 (1) = 3(𝑥 − 2)2
𝑑𝑥
𝑥 − 2 = 𝑦3
1
1
𝑥 = 𝑦 3 + 2 (inverse function)
𝑑𝑥 1 − 2
= 𝑦 3
𝑑𝑦 3
Copyright Reserved
106
2.8 The derivatives of special functions
Not included
2.9 Higher derivatives
Calculate the fourth order derivative of 𝑓(𝑥) = 𝑥 4 − 3𝑥 3 + 𝑥 2 + 7𝑥 − 19
𝑓 ′ (𝑥) = 4𝑥 3 − 9𝑥 2 + 2𝑥 + 7
𝑓 ′′ (𝑥) = 12𝑥 2 − 18𝑥 + 2
𝑓 ′′′ (𝑥) = 24𝑥 − 18
𝑓 𝑖𝑣 (𝑥) = 24
𝑓 𝑣 (𝑥) = 0
Calculate the second order derivative of 𝑓(𝑥) = 𝑒 3𝑥
2 −7
:
𝑓 ′ (𝑥) =
𝑓 ′′ (𝑥) =
Copyright Reserved
107
2.10 Optimization problems
Need to find max/min values
Figure 2.10.1
Absolute max: A
All max / min values are extreme values
Critical values
x –values that might indicate extreme values
Consider 𝑓 ′ (𝑥) = 0. How do we test if k will lead to a relative min or relative max
Relative max: C and E
Absolute min: D
Relative min: B
Calculate 𝑓 ′′ (𝑥):
𝑓 ′′ (𝑥) < 0 then k leads to a relative max value
𝑓 ′′ (𝑥) > 0 then k leads to a relative min value
𝑓 ′′ (𝑥) = 0 examine the values of the function at 𝑥 = 𝑘 inflection point
Figure 2.10.3: Rel max in the point k
Figure 2.10.4 Rel min in the point k
Copyright Reserved
108
Example of optimization with one critical value
Calculate the extreme and critical value(s) for: 𝑓(𝑥) = 16𝑥 − 𝑥 2
𝑓 ′ (𝑥) = 16 − 2𝑥
𝑓 ′′ (𝑥) = −2
Critical value(s):
Set 𝑓 ′ (𝑥) = 0
16 − 2𝑥 = 0
𝑥=8
Therefore, 𝑥 = 8 is a critical value.
Type of extreme value: 𝑓 ′′ (8) = −2 < 0 ∴ 𝑥 = 8 leads to a relative maximum.
Extreme value: 𝑓(8) = 16(8) − (8)2 = 64
Example of optimization with two critical values
Calculate the extreme and critical values for: 𝑓(𝑥) = 3𝑥 4 − 4𝑥 3
𝑓 ′ (𝑥) = 12𝑥 3 − 12𝑥 2
𝑓 ′′ (𝑥) = 36𝑥 2 − 24𝑥
Critical values:
Set 𝑓 ′ (𝑥) = 0
12𝑥 3 − 12𝑥 2 = 0
12𝑥 2 (𝑥 − 1) = 0
12𝑥 2 = 0 or 𝑥 − 1 = 0
Therefore, 𝑥 = 0 and 𝑥 = 1 are the critical values.
Type of extreme values:
→ 𝑓 ′′ (1) = 36(1)2 − 24(1) = 12 > 0. ∴ 𝑥 = 1 leads to a relative min.
→ 𝑓 ′′ (0) = 36(0)2 − 24(0) = 0. ∴ 𝑥 = 0 leads to an inflection point.
How do we know that this leads to an inflection point? We examine the values of the function at
𝑥 = 0.
x
4
𝑓(𝑥) = 3𝑥 − 4𝑥
3
-0.1
3(−0.1) − 4(−0.1)3
=0.0043
4
0
3(0) − 4(0)3
=0
4
0.1
3(0.1) − 4(0.1)3
= - 0.0037
4
Copyright Reserved
109
Graphical representation of an inflection point:
Extreme value: 𝑓(1) = 3(1)4 − 4(1)3 = −1.
Homework (work through this example on your own)
The cost (in Rand) to manufacture x products:
𝐶(𝑥) = 0.01𝑥 2 + 20𝑥 + 1 500
The income (in Rand) if x products are sold:
𝐼(𝑥) = 70𝑥 − 0.04𝑥 2
How many products should be sold if we want to maximize the profit?
𝑃(𝑥) = 𝐼(𝑥) − 𝐶(𝑥) = 70𝑥 − 0.04𝑥 2 − (0.01𝑥 2 + 20𝑥 + 1 500) = −0.05𝑥 2 + 50𝑥 − 1 500
𝑃′ (𝑥) = −0.1𝑥 + 50
𝑃′′ (𝑥) = −0.1
Critical value(s):
Set 𝑃′ (𝑥) = 0
−0.1𝑥 + 50 = 0
Therefore, 𝑥 = 500 is a critical value.
Type of extreme value: 𝑃′′ (500) = −0.1 < 0 ∴ 𝑥 = 500 leads to a relative maximum.
Hence, to earn the max profit we need to sell 500 products.
Calculate the maximum profit.
𝑃(500) = −0.05(500)2 + 50(500) − 1 500 = 𝑅11 000
Copyright Reserved
110
Example of optimization with one critical value
A manufacturer produces garden chairs at a cost of 𝑅20 a chair, and his overhead cost is 𝑅3 000 a
week. From previous experience he knows that he will sell 2000 − 40𝑥 chairs a week if he charge
𝑅𝑥 a chair. What must the price be, and how many chairs must he sell a week, to maximize his
profit?
Given:
• Cost per chair:
• Overhead cost:
• Number of chairs:
• Sales price:
Answer:
Profit per chair:
Total profit 𝑃(𝑥) =
𝑃′ (𝑥) =
𝑃′′ (𝑥) =
Critical value(s);
Set 𝑃′ (𝑥) = 0
−80𝑥 + 2800 = 0
𝑥 = 35
Therefore, 𝑥 = 35 is a critical value.
Type of extreme value: 𝑃′′ (35) = −80 < 0 ∴ 𝑥 = 35 leads to a relative maximum.
The profit is maximized if the chair is sold for 𝑅35.
Number of chairs to be sold: 2000 − 40(35) = 600.
Copyright Reserved
111
Check that you understand the meaning of the terms:
Gross profit
Nett profit
Questions 1 to 3 are based on the following information:
An analysis of the financial statements of a coal mine indicates that when x tons of coal are
extracted per day, the income and cost (in Rands) of the mine are, respectively:
𝐼(𝑥) = 1210𝑥 − 2𝑥 2
and
2
𝐶(𝑥) = 𝑥 − 2𝑥 + 1000
The mine is taxed at a rate of 40% on its gross profit.
Question 1:
Determine the value of x that maximises the income.
Answer 1:
𝐼(𝑥) = 1210𝑥 − 2𝑥 2
𝐼 ′ (𝑥) = 1210 − 4𝑥
𝐼 ′′ (𝑥) = −4
Critical value(s):
Set 𝐼 ′ (𝑥) = 0
1210 − 4𝑥 = 0
x = 302.5
Therefore, x = 302.5 is a critical value.
Type of extreme value: 𝐼 ′′ (302.5) = −4 < 0 ∴ x = 302.5 leads to a relative maximum.
Question 2:
Calculate the gross profit and the value of x that maximises it:
Answer 2:
𝐺𝑃(𝑥)
= 𝐼(𝑥) − 𝐶(𝑥)
= 1210𝑥 − 2𝑥 2 − (𝑥 2 − 2𝑥 + 1000)
= 1212𝑥 − 3𝑥 2 − 1000
𝐺𝑃′ (𝑥) = 1212 − 6𝑥
𝐺𝑃′′ (𝑥) = −6
Critical value(s):
Set 𝐺𝑃′ (𝑥) = 0
1212 − 6𝑥 = 0
𝑥 = 202
Therefore, 𝑥 = 202 is a critical value.
Type of extreme value: 𝐺𝑃′′ (202) = −6 < 0 ∴ 𝑥 = 202 leads to a relative maximum.
Copyright Reserved
112
Question 3:
Calculate the nett profit and the value of x that maximises it:
Answer 3:
𝑁𝑃(𝑥)
= 𝐺𝑃(𝑥) − 0.4𝐺𝑃(𝑥)
or
𝑁𝑃(𝑥) = 0.6𝐺𝑃(𝑥)
= 1212𝑥 − 3𝑥 2 − 1000 − 0.4(1212𝑥 − 3𝑥 2 − 1000 )
= 727.2𝑥 − 1.8𝑥 2 − 600
𝑁𝑃′ (𝑥) = 727.2 − 3.6𝑥
𝑁𝑃′′ (𝑥) = −3.6
Critical value(s):
Set 𝑁𝑃′ (𝑥) = 0
727.2 − 3.6𝑥 = 0
𝑥 = 202
Therefore, 𝑥 = 202 is a critical value.
Type of extreme value: 𝑁𝑃′′ (202) = −3.6 < 0 ∴ 𝑥 = 202 leads to a relative maximum.
Copyright Reserved
113
Extra Question 1
We need to enclose a field with a fence. We have 150 meters of fencing material and a building is
on one side of the field and so won’t need any fencing. Determine the dimensions of the field that
will enclose the largest area.
Extra Question 1 Solution:
In this problem we have two functions: the first being the function that we are actually trying to
optimise (this can also be referred to as a goal function) and a second function called a constraint
function. Consider a sketch of the situation:
In this problem we want to maximize the area of a field and we know that it will use 150𝑚 of
fencing material. So, the area will be the function we are trying to optimise and the amount of
fencing is the constraint. The two equations for these are,
Maximise: 𝐴 = 𝑥𝑦
and
Constraint: 150 = 𝑥 + 2𝑦.
We can rewrite 𝐴 as a function of 𝑦 only. From the constraint function it follows that 𝑥 = 150 − 2𝑦,
so it then follows that:
𝐴 = 𝐴(𝑦) = (150 − 2𝑦)𝑦 = 150𝑦 − 2𝑦 2 .
We need to find the value of 𝑦 in the interval [0,75], such that the area function will be maximised.
Note, that the interval is obtained by setting 𝑦 = 0 (i.e. assuming the fence has no sides) and 𝑦 =
75 (i.e. two sides and no width, also if there are two sides each must be 75𝑚 to use the whole
150𝑚).
Next, we calculate 𝐴′ (𝑦) = 150 − 4𝑦 , set 𝐴’(𝑦) = 0 and solve for 𝑦. It follows that
150 − 4𝑦 = 0
∴𝑦=
150
4
= 37.5.
To verify that A is maximised when y=37.5, consider the second derivative of A:
𝐴′′(𝑦) = −4.
Since 𝐴′′(37.5) = −4 < 0 it follows 𝐴 has a relative maximum where 𝑦 = 37.5. From the constraint
function it follows that when 𝑦 = 37.5, then 𝑥 = 150 − 2(37.5) = 150 − 75 = 75. The maximum
area we can obtain using the 150𝑚 of fencing is 𝐴 = 75𝑚(37.5𝑚) = 2812.5𝑚2.
(Try repeating the above example by rewriting 𝐴 as a function of 𝑥 only, using similar principles
and see if you obtain the same answer)
Copyright Reserved
114
Extra Question 2
After playing paintball with his friends and winning the match, Evert decides to shoot some
paintballs in the air to celebrate his tremendous accomplishment. Suppose that the height of the
paintball in the air (in meters) at any given moment in time, 𝑡, is given by the function D(𝑡) = 60 +
6𝑡 − 𝑡 2 .
What is the maximum height the paintball reaches and at what point in time is this achieved?
Copyright Reserved
115
Chapter 3: Integration
3.2 Indefinite integrals
𝐹(𝑥): anti
derivative
∫ : integral
sign
𝑓(𝑥): integrand
𝑑𝑥: operation
𝑐: integral
constant
Rule 1
1
∫ 𝑥 𝑛 𝑑𝑥 = 𝑛+1 𝑥 𝑛+1 + 𝑐 for 𝑛 ≠ 1
1.
∫ 𝑥 5 𝑑𝑥 =
2.
∫ 𝑥 2 𝑑𝑥 = ∫ 𝑥 −2 𝑑𝑥 =
3.
∫ √𝑥 3 𝑑𝑥 = ∫ 𝑥 2 𝑑𝑥 =
4.
∫ 𝑥 𝑑𝑥 = ∫ 𝑥 1 𝑑𝑥 =
1
3
Rule 2
∫ 𝑘𝑓(𝑥) 𝑑𝑥 = 𝑘 ∫ 𝑓(𝑥) 𝑑𝑥
800
𝑑𝑥 = 800 ∫
1.
∫
2.
∫ 8 𝑑𝑥 =
𝑥9
1
𝑥9
𝑑𝑥 = 800 ∫ 𝑥 −9 𝑑𝑥 =
Copyright Reserved
116
Rule 6
∫[𝑓(𝑥) + 𝑔(𝑥)] 𝑑𝑥 = ∫ 𝑓(𝑥) 𝑑𝑥 + ∫ 𝑔(𝑥) 𝑑𝑥
∫[𝑓(𝑥) − 𝑔(𝑥)] 𝑑𝑥 = ∫ 𝑓(𝑥) 𝑑𝑥 − ∫ 𝑔(𝑥) 𝑑𝑥
1.
∫(𝑥 2 + 2𝑥 − 1) 𝑑𝑥
= ∫ 𝑥 2 𝑑𝑥 + ∫ 2𝑥𝑑𝑥 − ∫ 𝑑𝑥
=
=
=
3.3 Definite integrals
The area under a curve 𝑓(𝑥) between a and b:
Indefinite integral
∫ 𝑓(𝑥) 𝑑𝑥 = 𝐹(𝑥) + 𝑐
Definite integral
𝑏
∫𝑎 𝑓(𝑥) 𝑑𝑥 = [𝐹(𝑥)]𝑏𝑎 = 𝐹(𝑏) − 𝐹(𝑎)
Copyright Reserved
117
Property 1: The interchanging of the limits of integration changes the sign
of the definite integral.
𝑎
𝑏
∫ 𝑓(𝑥)𝑑𝑥 = − ∫ 𝑓(𝑥)𝑑𝑥
𝑏
𝑎
5
∫1 𝑥 2 𝑑𝑥 =
1
∫5 𝑥 2 𝑑𝑥
=
𝑥3
1
| =
13
3 5
3
−
53
3
=−
124
3
Property 2: A definite integral has a value of zero when the two limits are
identical.
𝑎
∫ 𝑓(𝑥)𝑑𝑥 = 0
𝑎
3
∫ 𝑥 3 𝑑𝑥 =
3
Property 3:
𝑏
𝑏
∫ −𝑓(𝑥) 𝑑𝑥 = − ∫ 𝑓(𝑥) 𝑑𝑥
𝑎
𝑥4
3
3
𝑎
34
14
∫1 −𝑥 3 𝑑𝑥 = − 4 | = (− 4 ) − (− 4 ) = (−20.25) − (−0.25) = −20
1
3
𝑥4
3
34
14
− ∫1 𝑥 3 𝑑𝑥 = − [ | ] = − [ − ] = −20
4
4
4
1
Copyright Reserved
118
Property 4:
𝑏
𝑏
∫ 𝑘𝑓(𝑥) 𝑑𝑥 = 𝑘 ∫ 𝑓(𝑥) 𝑑𝑥
𝑎
3
∫1 4𝑥 3 𝑑𝑥
𝑥4
𝑎
3
= 4 | = 𝑥 4 |13 = 34 − 14 = 80
4 1
𝑥4
3
3
34
14
4 ∫1 𝑥 3 𝑑𝑥 = 4 [ | ] = 4 [ − ] = 4 × 20 = 80
4
4
4
1
Property 5:
𝑏
𝑏
𝑏
∫ [𝑓(𝑥) ± 𝑔(𝑥)] 𝑑𝑥 = ∫ 𝑓(𝑥) 𝑑𝑥 ± ∫ 𝑔(𝑥) 𝑑𝑥
𝑎
𝑎
𝑎
3
∫1 (𝑥 3 + 1) 𝑑𝑥
3
3
= ∫1 𝑥 3 𝑑𝑥 + ∫1 𝑑𝑥
=
𝑥4
3
| + 𝑥|13
4 1
34
=(
4
14
− ) + (3 − 1)
4
= 20 + 2
= 22
Copyright Reserved
119
Property 6:
𝑑
𝑏
𝑐
𝑑
∫𝑎 𝑓(𝑥) 𝑑𝑥 = ∫𝑎 𝑓(𝑥) 𝑑𝑥 + ∫𝑏 𝑓(𝑥) 𝑑𝑥 + ∫𝑐 𝑓(𝑥) 𝑑𝑥
3
∫1 𝑥 3 𝑑𝑥 =
5
∫3 𝑥 3 𝑑𝑥
5
=
∫1 𝑥 3 𝑑𝑥 =
𝑥4
3
| =
34
4 1
4
5
54
𝑥4
| =
4 3
4
5
54
𝑥4
| =
4 1
5
4
−
−
−
14
4
34
4
14
4
(𝑎 < 𝑏 < 𝑐 < 𝑑)
= 20
= 136
= 156
3
5
Therefore, ∫1 𝑓(𝑥) 𝑑𝑥 = ∫1 𝑓(𝑥) 𝑑𝑥 + ∫3 𝑓(𝑥) 𝑑𝑥
Copyright Reserved
120
Example
Calculate the area between the function 𝑓(𝑥) = 𝑥 3 , the x-axis, the line 𝑥 = −3 and
the line 𝑥 = 5.
Incorrect method:
5
∫−3 𝑥 3 𝑑𝑥
=
𝑥4
5
|
4 −3
=
(5)4
4
−
(−3)4
4
= 156.25 − 20.25 = 136
Correct method:
Hint: Use Property number 6
0
5
𝑥4
0
𝑥4
−3
4 0
|∫−3 𝑥 3 𝑑𝑥| + ∫0 𝑥 3 𝑑𝑥 = | | | +
4
5
| = |−20.25| + 156.25 = 176.5
0
Note: We took the absolute value of the first term (∫−3 𝑥 3 𝑑𝑥), since this area is
below the x-axis.
Copyright Reserved
121
Example
Calculate the area of the region, which is bounded by the function 𝑓(𝑥), the x-axis,
the line 𝑥 = −3 and the line 𝑥 = 4.5.
Answer
−2
0.5
4
4.5
|∫ 𝑓(𝑥)𝑑𝑥 | + ∫ 𝑓(𝑥)𝑑𝑥 + |∫ 𝑓(𝑥)𝑑𝑥| + ∫ 𝑓(𝑥)𝑑𝑥
−3
−2
0.5
4
or
−2
0.5
4
4.5
− ∫ 𝑓(𝑥)𝑑𝑥 + ∫ 𝑓(𝑥)𝑑𝑥 − ∫ 𝑓(𝑥)𝑑𝑥 + ∫ 𝑓(𝑥)𝑑𝑥
−3
−2
0.5
4
Copyright Reserved
122
3.4 Some economic applications of integrals
Definite integrals
Example:
The demand and supply of light bulbs (in 1000):
𝐷(𝑝) = 16 − 𝑝2
𝑆(𝑝) = 4𝑝 + 𝑝2
p = price in Rand
Question: Calculate the consumers’ surplus and producers’ surplus when the
market is in equilibrium.
Equilibrium price:
𝐷(𝑝) = 𝑆(𝑝)
16 − 𝑝2 = 4𝑝 + 𝑝2
Therefore, the equilibrium price is …..
Copyright Reserved
123
Consumers’ surplus:
Set 𝐷(𝑝) = 0:
16 − 𝑝2 = 0
To obtain the consumers’ surplus, we integrate over the demand function
4
∫ 𝐷(𝑝) 𝑑𝑝
2
where R2 is the equilibrium price and R4 is found by setting 𝐷(𝑝) = 0.
4
∫2 𝐷(𝑝) 𝑑𝑝
=
4
∫2 (16 −
𝑝
2 )𝑑𝑝
= [16𝑝 −
𝑝3
3
4
]| = 13. 3̇ × 1 000 = 𝑅13 333.33
2
Producers’ surplus:
Set 𝑆(𝑝) = 0:
4𝑝 + 𝑝2 = 0
To obtain the producers’ surplus, we integrate over the supply function
2
∫ 𝑆(𝑝)𝑑𝑝
0
where R0 is found by setting 𝑆(𝑝) = 0 and R2 is the equilibrium price.
2
∫0 𝑆(𝑝)𝑑𝑝
=
2
∫0 (4𝑝
+𝑝
2 )𝑑𝑝
2
= [2𝑝 +
𝑝3
3
2
]| = 10. 6̇ × 1 000 = 𝑅10 666.67
0
Copyright Reserved
124
More examples (work through these example on your
own)
Example 1:
Given:
• Marginal cost function (in R100) for the production of q units: 𝐶 ′ (𝑞) = 𝑞 2 − 2𝑞 + 10
• Fixed cost is R2 500.
Question 1:
Calculate the total cost function:
Answer 1:
1
𝐶(𝑞) = ∫ 𝐶 ′ (𝑞)𝑑𝑞 = ∫(𝑞 2 − 2𝑞 + 10) 𝑑𝑞 = 𝑞 3 − 𝑞 2 + 10𝑞 + 𝑐
3
But 𝐶(0) = 25
Therefore,
1
𝐶(0) = (0)3 − (0)2 + 10(0) + 𝑐 = 25
3
𝑐 = 25
Therefore, the total cost function is given by:
1
𝐶(𝑞) = 𝑞 3 − 𝑞 2 + 10𝑞 + 25
3
Copyright Reserved
125
Question 2:
Calculate the change in cost when production increases from 5 to 10 units.
Answer 2:
10
∫5 𝐶 ′ (𝑞) 𝑑𝑞 = 𝐶(𝑞)|10
5 = 𝐶(10) − 𝐶(5). From this it can be seen that we have to
10
calculate the definite integral ∫5 𝐶 ′ (𝑞) 𝑑𝑞.
10
∫5 𝐶 ′ (𝑞) 𝑑𝑞
10
= ∫5 (𝑞 2 − 2𝑞 + 10) 𝑑𝑞
1
10
3
5
= ( 𝑞 3 − 𝑞 2 + 10𝑞)|
= 333. 3̇ − 66. 6̇
= 266. 6̇ × 100
= 𝑅26 666.67
Copyright Reserved
126
Example 2:
Given:
The marginal income from the sale of the 𝑞 𝑡ℎ book is given by
𝐼 ′ (𝑞) = 45 − 0.21√𝑞 − 0.01𝑞 with 0 ≤ 𝑞 ≤ 1000
Question:
Calculate the additional income earned when sales increase from 400 to 900 books.
Answer:
900
∫400 𝐼 ′ (𝑞)𝑑𝑞
900
= ∫400 (45 − 0.21√𝑞 − 0.01𝑞)𝑑𝑞
3
= [45𝑞 − 0.14𝑞 2 − 0.005𝑞2 ]
900
400
3
3
= [45(900) − 0.14(900)2 − 0.005(900)2 ] − [45(400) − 0.14(400)2 − 0.005(400)2 ]
= 32 670 − 16 080 = 16 590.
Copyright Reserved
127
Example 3:
Given:
A sales representative sells motor polish. When q bottles of polish are sold, the
marginal income of the 𝑞 𝑡ℎ bottle will be equal to
𝐼 ′ (𝑞) = 34 − 0.06𝑞 − 0.0003𝑞2 with 0 ≤ 𝑞 ≤ 400.
Motor polish cost R10 per bottle and the sales representative must pay a once-off
registration fee of R50.
Question 1:
Calculate the total cost and total income functions when q bottles of polish are sold.
Answer 1:
Income function:
𝐼(𝑞) = ∫ 𝐼 ′ (𝑞)𝑑𝑞 = ∫(34 − 0.06𝑞 − 0.0003𝑞2 ) 𝑑𝑞 = 34𝑞 − 0.03𝑞2 − 0.0001𝑞 3 + 𝑐
But 𝐼(0) = 0 (when 0 bottles of polish are sold, the income will equal R0)
𝐼(0) = 34(0) − 0.03(0)2 − 0.0001(0)3 + 𝑐 = 0
𝑐=0
Therefore, the income function is given by
𝐼(𝑞) = 34𝑞 − 0.03𝑞 2 − 0.0001𝑞3
Cost function:
𝐶(𝑞) = 10𝑞 + 50
Copyright Reserved
128
Question 2:
Calculate the value of q which will maximise profit.
Answer 2:
The profit function is:
𝑃(𝑞) = 𝐼(𝑞) − 𝐶(𝑞)
= 34𝑞 − 0.03𝑞2 − 0.0001𝑞 3 − (10𝑞 + 50)
= −0.0001𝑞3 − 0.03𝑞2 + 24𝑞 − 50
To obtain the critical value(s), set 𝑃′ (𝑞) = 0:
𝑃′ (𝑞) = −0.0003𝑞 2 − 0.06𝑞 + 24 = 0
0.06 ± √(−0.06)2 − 4(−0.0003)(24) 0.06 ± √0.0324
𝑞=
=
2(−0.0003)
−0.0006
q = 200 and q = - 400 economical unacceptable.
Therefore, the critical value is q = 200.
𝑃′′ (𝑞) = −0.0006𝑞 − 0.06
𝑃′′ (200) = −0.0006(200) − 0.06 = −0.18 < 0 ∴ q = 200 leads to a relative max.
Question 3:
Calculate the maximum profit.
Answer 3:
𝑃(200) = −0.0001(200)3 − 0.03(200)2 + 24(200) − 50 = 2 750 in Rand.
Copyright Reserved
129
3.5 Statistical applications of integrals
Calculating probabilities
Let X be a continuous random variable with p.d.f. given by f(x). From Section 1 we know that f(x) is
a valid probability density function when:
1. 𝑓(𝑥) ≥ 0 for all 𝑥 and
∞
2. ∫−∞ 𝑓(𝑥)𝑑𝑥 = 1 (i.e. the area below the entire function equals exactly 1).
We can use integration to determine whether a function is a valid p.d.f. or not.
Example:
Let
𝑥
,
0≤𝑥≤1
2
1
,
1<𝑥<2
𝑓(𝑥) = 2
𝑥 3
− + ,2 ≤ 𝑥 ≤ 3
2 2
{ 0,
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
From the definition of the function it can be seen that 𝑓(𝑥) ≥ 0 for all 𝑥 (verify that this is true). It
follows that
∞
3
∫−∞ 𝑓(𝑥)𝑑𝑥 = ∫0 𝑓(𝑥)𝑑𝑥 (since the function is 0 when 𝑥 is not in [0,3]).
1𝑥
21
3
𝑥
3
= ∫0 2 𝑑𝑥 + ∫1 2 𝑑𝑥 + ∫2 (− 2 + 2) 𝑑𝑥 (Rule 6)
Copyright Reserved
130
Question:
𝑥2
,
−4(𝑥 − 2)
𝑔(𝑥) = {
,
3
0
,
0≤𝑥≤1
1<𝑥≤2
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
Draw a graph of 𝑔
Show that 𝑔 is a valid p.d.f.
Calculate 𝑃(𝑋 > 0.5)
𝑏
Hint: 𝑃(𝑎 < 𝑋 < 𝑏) = 𝑃(𝑎 ≤ 𝑋 ≤ 𝑏) = ∫𝑎 𝑓(𝑥)𝑑𝑥 for 𝑎 < 𝑏.
Challenging Question:
Find C, such that
𝐶𝑥 2 + 𝐶,
𝑓(𝑥) = {
0
,
−2 ≤ 𝑥 ≤ 2
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
is a valid p.d.f.
Copyright Reserved
131
Expected values
If 𝑋 is a continuous random variable from a distribution with a p.d.f. given by 𝑓(𝑥) then
∞
𝐸[𝑋] = ∫−∞ 𝑥𝑓(𝑥)𝑑𝑥.
Example:
Let 𝑋 be a continuous random variable with p.d.f. given by
0.375𝑥 2 , 0 ≤ 𝑥 ≤ 2
ℎ(𝑥) = {
.
0, 𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
Find 𝐸[𝑋]:
∞
𝐸[𝑋] = ∫ 𝑥ℎ(𝑥)𝑑𝑥
−∞
2
= ∫ 𝑥(0.375𝑥 2 )𝑑𝑥
0
2
= ∫ 0.375𝑥 3 𝑑𝑥
0
0.375 4 2
=
𝑥 |
4
0
0.375(24 )
=
−0
4
3
= = 1.5
2
We can calculate the expected value of a random function too, i.e. a function with respect to the
continuous random variable X, say k(X). The expected value of k(X) is given by:
∞
𝐸[𝑘(𝑋)] = ∫ 𝑘(𝑥)𝑓(𝑥)𝑑𝑥
−∞
Example:
Let 𝑋 have the same p.d.f. as in the previous example. To calculate 𝑉𝑎𝑟(𝑋) we make use of the
fact that 𝑉𝑎𝑟(𝑋) = 𝐸(𝑋 2 ) − [𝐸(𝑋)]2 . It follows that:
2
2
𝐸(𝑋
2)
=∫ 𝑥
0
2 (0.375𝑥 2 )𝑑𝑥
0.375𝑥 5
=
| = 2.4
5
0
and
𝑉𝑎𝑟(𝑋) = 𝐸(𝑋 2 ) − [𝐸(𝑋)]2 = 2.4 − 1.52 = 0.15.
Theoretical Example:
In WST 133 we showed that when 𝑋 is a discrete random variable with probability function 𝑝(𝑥)
and we let 𝑌 = 𝑎𝑋 ± 𝑏 then
𝐸[𝑌] = 𝑎𝐸[𝑋] ± 𝑏
and
𝑉𝑎𝑟(𝑌) = 𝑎2 𝑉𝑎𝑟(𝑋) (where 𝑎 and 𝑏 are constants).
This result is also true for continuous random variables.
Copyright Reserved
132
Proof:
Let 𝑋 be a continuous random variable with p.d.f. f(x). When 𝑌 = 𝑎𝑋 ± 𝑏 it follows that
∞
𝐸[𝑌] = ∫ (𝑎𝑥 ± 𝑏)𝑓(𝑥)𝑑𝑥
−∞
∞
∞
= ∫ 𝑎𝑥𝑓(𝑥)𝑑𝑥 ± ∫ 𝑏𝑓(𝑥)𝑑𝑥
−∞
∞
−∞
∞
= 𝑎 ∫ 𝑥𝑓(𝑥)𝑑𝑥 ± 𝑏 ∫ 𝑓(𝑥)𝑑𝑥
−∞
(Property 5)
(Property 4)
−∞
= 𝑎𝐸[𝑋] ± 𝑏(1)
(Definition of an expected value and
entire area of p.d.f is 1)
To show that 𝑉𝑎𝑟(𝑌) = 𝑎2 𝑉𝑎𝑟(𝑋) use the fact that 𝑉𝑎𝑟(𝑋) = 𝐸[(𝑋 − 𝐸[𝑋])2 ].
Exercise:
Let 𝑋 follow a continuos uniform distribution with parameters 𝑎 and 𝑏, with 𝑎 < 𝑏. Prove that:
1. 𝐸[𝑋] =
𝑎+𝑏
2
2. 𝑉𝑎𝑟[𝑋] =
and
(𝑏−𝑎)2
12
.
Hint: Recall that 𝑉𝑎𝑟(𝑋) = 𝐸(𝑋 2 ) − [𝐸(𝑋)]2 .
Moment Generating Functions
Definition:
Suppose that 𝑋 is a discrete random variable with probability mass function given by 𝑓𝑋 (𝑥) =
𝑃(𝑋 = 𝑥). The Moment Generating Function (MGF) of 𝑋 is defined as
𝑀𝑋 (𝑡) = 𝐸[𝑒 𝑡𝑋 ]
= ∑ 𝑒 𝑡𝑋 𝑓𝑋 (𝑥).
∀𝑥
Provided that the 𝑛-th derivative of 𝑀𝑋 (𝑡) exists at the point 𝑡 = 0, it follows that
(𝑛)
𝑀𝑋 (0) = 𝐸[𝑋 𝑛 ]
The discrete uniform case:
Example 1
Let the random variable 𝑋 be the outcome of rolling a 6-sided die. Find the MGF for 𝑋.
Solution:
The mass function for 𝑋 is given by
1
𝑓(𝑥) = {6 ,
0,
𝑥 = 1, 2, 3, 4, 5, 6
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
It follows that:
𝑀𝑋 (𝑡) = 𝐸[𝑒 𝑡𝑋 ]
6
1
= ∑ 𝑒 𝑡𝑥 ( )
6
𝑥=1
1
= (𝑒 𝑡 + 𝑒 2𝑡 + ⋯ + 𝑒 6𝑡 )
6
Copyright Reserved
133
Example 2
Let the random variable 𝑋 be the outcome of rolling a 6-sided die. Find 𝐸(𝑋) and 𝑣𝑎𝑟(𝑋) using the
MGF of 𝑋.
Solution:
We know that
𝐸(𝑋) = 𝑀𝑋′ (0)
𝐸(𝑋 2 ) = 𝑀𝑋′′ (0)
and
2
𝑣𝑎𝑟(𝑋) = 𝐸(𝑋 2 ) − (𝐸(𝑋))
It follows that
𝑀𝑋′ (𝑡) =
=
𝑑
𝑀 (𝑡)
𝑑𝑡 𝑋
𝑑 1 𝑡
( (𝑒 + 𝑒2𝑡 + 𝑒3𝑡 + 𝑒4𝑡 + 𝑒5𝑡 + 𝑒6𝑡 ))
𝑑𝑡 6
1
= (𝑒𝑡 + 2𝑒2𝑡 + 3𝑒3𝑡 + 4𝑒4𝑡 + 5𝑒5𝑡 + 6𝑒6𝑡 )
6
In addition,
𝑑 ′
𝑀 (𝑡)
𝑑𝑡 𝑋
𝑑 1
= ( (𝑒𝑡 + 2𝑒2𝑡 + 3𝑒3𝑡 + 4𝑒4𝑡 + 5𝑒5𝑡 + 6𝑒6𝑡 ))
𝑑𝑡 6
1
= (𝑒𝑡 + 22 𝑒2𝑡 + 32 𝑒3𝑡 + 42 𝑒4𝑡 + 52 𝑒5𝑡 + 62 𝑒6𝑡 )
6
𝑀𝑋′′ (𝑡) =
Therefore,
𝐸(𝑋) = 𝑀𝑋′ (0)
1
= (𝑒0 + 2𝑒2(0) + 3𝑒3(0) + 4𝑒4(0) + 5𝑒5(0) + 6𝑒6(0) )
6
1
= (1 + 2 + 3 + 4 + 5 + 6)
6
= 3.5
and
which leads to
𝐸(𝑋 2 ) = 𝑀𝑋′′ (0)
1
= (𝑒0 + 22 𝑒2(0) + 32 𝑒3(0) + 42 𝑒4(0) + 52 𝑒5(0) + 62 𝑒6(0) )
6
1
= (12 + 22 + 32 + 42 + 52 + 62 )
6
91
=
6
2
𝑣𝑎𝑟(𝑋) = 𝐸(𝑋 2 ) − (𝐸(𝑋))
91
21 2
=
−( )
6
6
105
=
36
≈ 2.91666667
Copyright Reserved
134
The Binomial case:
In order the derive the expected value and variance of the 𝑋 where 𝑋~𝐵𝑖𝑛(𝑛, 𝑝) we require the
help of the binomial theorem.
Definition: Binomial theorem
For any positive integer 𝑛, it follows that
𝑛
𝑛
(𝑥 + 𝑦) = ∑ ( ) 𝑥 𝑡 𝑦 𝑛−𝑡
𝑡
𝑛
𝑡=0
The MGF of 𝑋 can be derived as follows.
𝑀𝑋 (𝑡) = 𝐸[𝑒 𝑡𝑋 ]
𝑛
= ∑ 𝑒 𝑡𝑥 𝑝(𝑥)
𝑥=0
𝑛
𝑛
= ∑ 𝑒 𝑡𝑥 ( ) 𝑝 𝑥 (1 − 𝑝)𝑛−𝑥
𝑥
𝑥=0
𝑛
𝑛
= ∑ ( ) (𝑝𝑒 𝑡 )𝑥 (1 − 𝑝)𝑛−𝑥
𝑥
𝑥=0
= [𝑝𝑒 𝑡 + (1 − 𝑝)]𝑛
⋯
𝑢𝑠𝑖𝑛𝑔 𝑡ℎ𝑒 𝑏𝑖𝑛𝑜𝑚𝑖𝑎𝑙 𝑡ℎ𝑒𝑜𝑟𝑒𝑚
It follows that
𝑑
𝑀 (𝑡)
𝑑𝑡 𝑋
𝑑
= [𝑝𝑒 𝑡 + (1 − 𝑝)]𝑛
𝑑𝑡
𝑛−1
= 𝑛(𝑝𝑒 𝑡 + (1 − 𝑝))
× 𝑝𝑒 𝑡
𝑀𝑋′ (𝑡) =
⋯ 𝑢𝑠𝑖𝑛𝑔 𝑡ℎ𝑒 𝑐ℎ𝑎𝑖𝑛 𝑟𝑢𝑙𝑒
Therefore,
𝐸(𝑋) = 𝑀𝑋′ (0)
= 𝑛(𝑝𝑒 0 + (1 − 𝑝))
𝑛−1
× 𝑝𝑒 0
𝑛−1
= 𝑛(𝑝 + (1 − 𝑝))
×𝑝
𝑛−1
= 𝑛(1)
×𝑝
= 𝑛𝑝
𝑠𝑖𝑛𝑐𝑒 1𝑛 = 1 ∀ 𝑛
Exercise:
Use the MGF of 𝑋 to prove that 𝑣𝑎𝑟(𝑋) = 𝑛𝑝(1 − 𝑝).
Hints:
1. Find 𝑀𝑋′′ (𝑡) using both the product rule and the chain rule.
2. Find the value of 𝐸(𝑋 2 ) = 𝑀𝑋′′ (0).
2
3. Recall that 𝑣𝑎𝑟(𝑋) = 𝐸(𝑋 2 ) − (𝐸(𝑋)) .
Copyright Reserved
135
Definition:
Suppose that 𝑋 is a continuous random variable with probability density function given by 𝑓𝑋 (𝑥).
The Moment Generating Function (MGF) of 𝑋 is defined as
𝑀𝑋 (𝑡) = 𝐸[𝑒 𝑡𝑋 ]
∞
= ∫ 𝑒 𝑡𝑥 𝑓𝑋 (𝑥) 𝑑𝑥
−∞
Provided that the 𝑛-th derivative of 𝑀𝑋 (𝑡) exists at the point 𝑡 = 0, it follows that
(𝑛)
𝑀𝑋 (0) = 𝐸[𝑋 𝑛 ]
The Continuous Uniform case:
Let 𝑋~𝑈𝑛𝑖𝑓(𝑎, 𝑏). Then the MGF of 𝑋 can be derived as follows.
𝑀𝑋 (𝑡) = 𝐸[𝑒 𝑡𝑋 ]
∞
= ∫ 𝑒 𝑡𝑥 𝑓𝑋 (𝑥) 𝑑𝑥
−∞
𝑏
= ∫ 𝑒 𝑡𝑥
𝑎
1
𝑑𝑥
𝑏−𝑎
𝑏
1
=
∫ 𝑒 𝑡𝑥 𝑑𝑥
𝑏−𝑎
𝑎
1 1 𝑡𝑥 𝑏
=
[ 𝑒 ]
𝑏−𝑎 𝑡
𝑎
1
1 𝑡𝑏 1 𝑡𝑎
=
( 𝑒 − 𝑒 )
𝑏−𝑎 𝑡
𝑡
𝑒 𝑏𝑡 − 𝑒 𝑎𝑡
=
𝑡(𝑏 − 𝑎)
Copyright Reserved
136
Solutions to Self Evaluation Questions
Chapter 6
1. Correct Option: a.
1
𝑤ℎ𝑒𝑟𝑒 25 ≤ 𝑥 ≤ 40
𝑓(𝑥) = {40 − 25 ,
0 ,
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
1
𝑤ℎ𝑒𝑟𝑒 25 ≤ 𝑥 ≤ 40
= {15 ,
0,
𝑒𝑙𝑠𝑒𝑤ℎ𝑒𝑟𝑒
2.
1
) = 0.75
15
1
How did we know 𝑃75 = 36.25? By taking (𝑥 − 25) (15) = 0.75.
Therefore, 𝑥 − 25 = (0.75)(15) and consequently, 𝑥 = 11.25 + 25 = 36.25.
𝑃(25 < 𝑋 < 36.25) = ∆𝑥 ∙ 𝑓(𝑥) = (36.25 − 25) (
3. 𝑉𝑎𝑟(𝑋) =
(𝑏−𝑎)2
12
=
(40−25)2
12
= 18.75
1
4. 𝑃(𝑋 > 22) = ∆𝑥 ∙ 𝑓(𝑥) = (40 − 25) (15) = 1.
1
5. 𝑃(27 < 𝑋 < 36) = ∆𝑥 ∙ 𝑓(𝑥) = (36 − 27) (15) = 0.6.
Copyright Reserved
137
6. The 5th percentile of the standard normal distribution. Answer = b.
7. A TYPICAL MISTAKE THAT STUDENTS MAKE
𝑝
Most of you will probably want to use the formula that was given in Chapter 3: 𝑖 = (100) 𝑛.
This is wrong! You can only use that formula when the original raw data set is given, because the index
𝑖 indicates which position in the ordered original data set you need to go to. Since we did not give you
the original data set; this is a dead end.
The correct answer:
Given:
Due to symmetry we have the following graph:
The value of NORM.S.INV(0.1) in Excel
is -1.282. Therefore,
And: The 90th percentile means that 90% of the values
are to the left of that point. Therefore,
∴ 𝑍=
𝑋−𝜇
,
𝜎
∴ 1.282 =
𝑥−100
,
15
∴ 𝑥 = (1.282)(15) + 100 = 119.23.
Therefore, the 90th percentile is equal to 119.23 (𝑃90 = 119.23).
Copyright Reserved
138
Chapter 7
60−50
40−50
1. 𝑧 = 12 = 0.83̇ and 𝑧 = 12 = −0.83̇.
𝑃(40 < 𝑋 < 60) = 𝑃(−0.83̇ < 𝑍 < 0.83̇)
= 𝑃(𝑍 < 0.83̇) − 𝑃(𝑍 < −0.83̇)
= 0.7967 − 0.2033
= 0.5934.
2.
𝑧=
𝑥−𝜇
𝜎
𝑥−50
∴ 1.04 = 12
∴ 𝑥 = (1.04)(12) + 50 = 62.48.
3.
𝑥̅ − 𝜇 𝑥̅ − 𝜇
= 𝜎
𝜎𝑋̅
√𝑛
𝑥 − 50
∴ −0.67 =
12
√25
12
∴ 𝑥̅ = (−0.67) (
) + 50 = 48.39
√25
𝑧=
1
4. 𝑓(𝑥) = {50−10
0
1
= 40 for 10 ≤ 𝑥 ≤ 50
elsewhere
1
𝑃(20 < 𝑋 < 60) = ∆𝑥. 𝑓(𝑥) = (60 − 50)(0) + (50 − 20) (40) = 0.75.
Copyright Reserved
139
5. 𝑉𝑎𝑟(𝑋) = 𝜎 2 =
(𝑏−𝑎)2
12
=
(50−10)2
12
= 133. 3̇.
Therefore, 𝑠𝑡𝑑𝑒𝑣(𝑋) = 𝜎 = √133. 3̇ = 11.547.
𝜎
11.547
And so 𝜎𝑋̅ = 𝑛 =
= 1.83.
√40
√
28−30
6. 𝑃(𝑋̅ > 28) = 𝑃 (𝑍 > 1.83 )
= 𝑃(𝑍 > −1.09)
= 1 − 𝑃(𝑍 < −1.09)
= 1 − 0.1379
= 0.8621
7. 𝜎𝑝2 =
𝑝(1−𝑝)
𝑛
=
𝑝(1−𝑝)
8. 𝜎𝑝 = √
𝑛
(0.2)(0.8)
32
= 0.005
= 0.0707 and
𝑃(|𝑝 − 𝑝| < 0.05) = 𝑃(−0.05 < 𝑝 − 𝑝 < 0.05)
−0.05
= 𝑃 (0.0707 <
𝑝−𝑝
𝜎𝑝
̅
0.05
< 0.0707)
= 𝑃(−0.71 < 𝑍 < 0.71)
= 0.7611 − 0.2389
= 0.5222
9.
𝑝−𝑝
𝜎𝑝
𝑎 − 0.2
1.28 =
0.0707
𝑧=
𝑎 = 1.28(0.0707) + 0.2 = 0.29
10. 𝑃(17 < 𝑋 < 26) = 𝑃(𝑋 ≤ 25) − 𝑃(𝑋 ≤ 17)
= 0.9828 − 0.4215
= 0.5613
Note: Both 𝑃(𝑋 ≤ 25) and 𝑃(𝑋 ≤ 17) are obtained using the Excel sheets.
11. 𝑃(𝑋 > 18) = 1 − 𝑃(𝑋 ≤ 18) = 1 − 0.5689 = 0.4311
Note: 𝑃(𝑋 ≤ 18) is obtained using the Excel sheets.
12. Let 𝑌 be the number of customers who don’t prefer name brand clothing.
𝐸(𝑌) = 𝑛(1 − 𝑝) = (30)(0.4) = 12
22
13. |𝑝 − 𝑝| = |0.73 − 0.6| = 0.13 where 𝑝 = 30 = 0.73̇.
Copyright Reserved
140
14. The sampling distribution of 𝑝 can be approximated by a normal probability distribution
whenever 𝑛𝑝 ≥ 5 and 𝑛(1 – 𝑝) ≥ 5.
15.
It is given that 𝜎𝑝 = 0.0894.
𝑧=
𝑝−𝑝
𝜎𝑝
0.25 =
𝑝 − 0.6
0.0894
𝑝 = (0.25)(0.0894) + 0.6 = 0.62235
Therefore, 𝑃60 = 0.62235.
Chapter 8
𝑝(1−𝑝)
1. 𝑝 − 𝑧𝛼/2 √
𝑛
(0.2)(0.8)
= 0.2 − (1.96)√
50
10
= 0.089 with 𝑝 = 50 = 0.2.
2. If the confidence coefficient of a confidence interval decreases from 0.95 to 0.90, the 𝑧𝛼/2 value
decreases from 1.96 to 1.645 and, consequently, the interval is narrower. Answer = b.
3. 𝑥 + 𝑧𝛼/2
4. 𝑥 =
∑ 𝑥𝑖
𝑛
𝜎
√
= 7.5 + (2.576)
𝑛
=
1 517.39
40
1.05
√30
= 7.99
= 37.93
5. In cell D3 of Excel the =COUNTIF(B2:B41, B3) function counts the number of payments made
using a credit card, i.e. 30 out of 40 payments were made using a credit card. Therefore, 40 –
30 = 10 payments were made using cash.
10
𝑝=
= 0.25
40
6. 𝑡-distribution
7. To obtain the value of 𝑡𝛼/2 we use the T.INV.2T function of Excel =T.INV,2T(𝛼, 𝑑𝑓) =
T.INV.2T(0.05, 39) = 2.023 (this is given in cell D6 of Excel) with 𝑑𝑓 = 𝑛 − 1 = 40 − 1 = 39.
To obtain the sample standard deviation, we take the square root of the variance (this is given
in cell D4 of Excel).
The margin of error is equal to 𝑡𝛼/2
𝑠
√𝑛
7
= (2.023) (
√40
) = 2.2391.
Copyright Reserved
141
𝑝(1−𝑝)
8. 𝑝 − 𝑧𝛼/2 √
𝑛
𝑝(1−𝑝)
9. 𝑧𝛼/2 √
𝑛
= 0.25 − (2.576)√
(0.25)(0.75)
= (1.96)√
40
(0.25)(0.75)
40
= 0.0736
= 0.1342
10. The margin of error decreases, which implies a narrower interval.
Chapter 9
1.
𝐻0 : 𝜇 ≥ 20
𝐻𝑎 : 𝜇 < 20
2. 𝑥 =
∑ 𝑥𝑖
=
𝑛
216
12
∑(𝑥𝑖 −𝑥)2
3. 𝑠 = √
𝑛−1
= 18
= 2.80
4. 𝑑𝑓 = 𝑛 − 1 = 12 − 1 = 11 and 𝑡 = −2.472.
On the t-table go to the correct degrees of freedom = 11. We look for the absolute value of the
test statistic = 2.472. We find that this is between 2.201 and 2.718 and, consequently, the pvalue is between 0.01 and 0.025.
5. 𝑑𝑓 = 𝑛 − 1 = 12 − 1 = 11 and 𝛼 = 0.01, therefore, −𝑡𝛼 = −2.718.
The null hypothesis in not rejected, since t (=-2.472) > -2.718. Therefore, the average baggage
weight is not significantly less than 20kg. Answer = b.
6. Type I error
7.
𝐻0 : 𝜇 ≥ 100
𝐻𝑎 : 𝜇 < 100
8. 𝑧 =
𝑥−𝜇0
𝜎
√𝑛
=
90−100
25
√50
= −2.83
9. 𝐻0 can be rejected at a 0.5% level of significance, since p-value (0.0023) < 𝛼 (0.005).
Answer = e.
𝑝(1−𝑝)
10. 𝜎𝑝 = √
𝑛
(0.4)(0.6)
=√
80
= 0.0548
11. The area to the left of 𝑧 = −2.74 is 0.0031. Therefore, p-value = (2)(0.0031) = 0.0062.
12. 𝛼 = 0.01, ∴ 𝛼⁄2 = 0.01⁄2 = 0.005. Therefore, 𝑧𝛼/2 = 2.576.
Reject H0 if 𝑧 < −2.576 or 𝑧 > 2.576. Since 𝑧(= −2.74) < −2.576 the null hypothesis is rejected
at a 1% level of significance. Therefore, 𝑝 ≠ 0.4. Answer = e.
13. The area to the left of 𝑧 = −2.74 is 0.0031. Therefore, p-value = 0.0031.
Copyright Reserved
142
Chapter 10
1. Correct option: a
0
2.
𝐻0 : 𝜇1 ≤ 𝜇2
𝐻𝑎 : 𝜇1 > 𝜇2
3. 𝑡 =
𝑥1 −𝑥2
9−7
=
𝑠2 𝑠2
√ 1+ 2
𝑛1 𝑛2
√
5.2 3.2
+
6
6
= 1.69
4. 𝑑𝑓 = 9 and 𝛼 = 0.05. Therefore, 𝑡𝛼 = 1.833.
5.
𝐻0 : 𝜇1 = 𝜇2
𝐻 : 𝜇 − 𝜇2 = 0
or 0 1
𝐻𝑎 : 𝜇1 ≠ 𝜇2
𝐻𝑎 : 𝜇1 − 𝜇2 ≠ 0
6. 𝑡 =
𝑥1 −𝑥2
𝑠2 𝑠2
√ 1+ 2
𝑛1 𝑛2
=
9.25−6.6
2
√2.87 +1.95
4
2
= 1.58
5
7. On the t-table, go to the correct 𝑑𝑓 = 5. We find that the test statistic 𝑡 = 1.58 lies between
1.476 and 2.015. Consequently, the area in the upper tail is between 0.05 and 0.1. Since we
are working with a two-tailed test, we need to multiply the area in the upper tail by 2 and we
obtain
0.05 < area in the upper tail < 0.1
0.1 < 𝑝 − value < 0.2
8. 𝛼 = 0.1, ∴ 𝛼⁄2 = 0.1⁄2 = 0.05 and 𝑑𝑓 = 5. Therefore, 𝑡𝛼/2 = 2.015.
The null hypothesis is rejected if 𝑡 ≤ −2.015 or 𝑡 ≥ 2.015.
9. The null hypothesis is not rejected at a 10% level of significance, since the test statistic, 𝑡 =
1.58, is not smaller than −2.015 or greater than 2.015. Therefore, 𝜇1 = 𝜇2 . Answer = b.
Copyright Reserved
143
Revision Exercise – Chapter 5
According to BusinessWeek/Harris poll of 1035 adults, 40% of those surveyed agreed strongly
with the proposition that business has too much power over American life (BusinessWeek, Sept
11, 2000). Assume this percentage is representative of the American population. In sample of 20
individuals taken from a cross-section of the American population.
(a) What is the probability that at least five of these individuals will feel that business has too much
power over American life?
Use Excel to answer the following questions:
(b) Calculate the cumulative probability distribution of X for 0 X 20
(c) What is the probability that exactly five of these individuals will feel that business has too much
power over American life?
(d) What is the probability that at least five of these individuals will feel that business has too much
power over American life? Compare answer with a.
(e) What is the probability that at most two of these individuals will feel that business has too
much power over American life?
(f) What is the probability that more than one of these individuals will feel that business has too
much power over American life?
(g) What is the probability that at least fourteen of these individuals will feel that business has too
much power over American life?
(h) What is the probability that less than ten of these individuals will feel that business has too
much power over American life?
(i) What is the probability that less than two of these individuals will feel that business has no
power over American life?
(j) What is the expected number of individuals that will feel that business has too much power
over American life?
(k) What are the variance and standard deviation of individuals that will feel that business has too
much power over American life?
Copyright Reserved
144
Revision Exercise – Chapter 5 – Solution
(a) 𝑋 = the number of Americans who believe that business has too much power over American
life.
P X 5 1 P X 5
= 1 - f (0) - f (1) - f (2) - f (3) - f (4)
= 1 - .0000 - .0005 - .0031 - .0123 - .0350
= .9491
Formula worksheet:
Copyright Reserved
145
Value worksheet:
Copyright Reserved
146
Additional Exercises
Chapter 6
Question 1
Which one of the following is a valid discrete probability distribution?
-2
-1
0
1
2
(A) x
0.2
0.1
0
0.1
0.2
f (x )
(B) x
f (x )
(C) x
f (x )
(D) x
f (x )
(E) x
f (x )
1
0.1
2
0.2
3
0.3
4
0.4
5
0.5
2
-0.2
4
-0.1
6
0
8
0.1
10
0.2
1
-0.2
2
-0.1
3
1
4
0.1
5
0.2
-2
0.4
-1
0.1
0
0
1
0.1
2
0.4
Questions 2 and 3 are based on the following information:
The time (in hours) that it takes a bus to travel from Johannesburg to Bloemfontein
has the following uniform density function:
1
for
4 x6
2
f ( x)
0 elsewhere
Question 2
The probability that the bus takes longer than 5.5 hours to travel from Johannesburg
to Bloemfontein is:
(A)
(C)
(E)
0.25
0.50
0.75
(B)
(D)
0.45
0.55
Question 3
The probability that the bus takes 5 hours to travel from Johannesburg to
Bloemfontein is:
(A)
(C)
(E)
0.1
0.2
0.5
(B)
(D)
0
0.25
Copyright Reserved
147
Questions 4 and 5 are based on the following information: The probability
distribution of the number of home loans that are approved weekly by the local branch
office of a bank, is represented in the following Excel spreadsheet:
Excel: Formula sheet
Excel: Value sheet
Question 4
The variance for the distribution of the number of home loans that are approved
weekly is:
(A)
(C)
(E)
2.60
9.00
0
(B)
(D)
4.67
11.60
Question 5
The probability that less than 3 home loans are approved per week is:
(A)
(C)
(E)
0.20
0.35
0.55
(B)
(D)
0.25
0.45
Copyright Reserved
148
Questions 6 and 7 are based on the following information:
The random variable Z is normally distributed with average 0 and standard deviation
1.
Question 6
P(1.62 Z 0.5)
(A)
(C)
(E)
0.2559
0.4474
0.7441
(B)
(D)
0.3612
0.6388
Question 7
If the area to the right of z is equal to 0.95, then z is equal to:
(A)
(C)
(E)
-1.960
-0.8289
1.645
(B)
(D)
-1.645
0.8289
Question 8
Consider the following probabilities of a binomial distribution:
Excel: Formula sheet
Excel Value sheet
P( X 10)
(A)
(C)
(E)
Memo
0.8829
0.8725
0.9290
Q1 - E
Q2 - A
Q3 - B
(B)
(D)
0.8403
0.7553
Q4 - A
Q5 - C
Q6 - A
Q7 - B
Q8 - D
Copyright Reserved
149
Chapter 7
Questions 1 to 4 are based on the following information:
Suppose 60% of the students at university XYZ own a cell phone. For a random
sample of 200 students, from this population, it was found that 130 students owned a
cell phone.
Let p denote the point estimator of the proportion students owning a cell phone.
Question 1
The point estimate for the proportion of students who own a cell phone is:
(A)
(C)
(E)
0.13
0.65
130
Question 2
The sampling error of
(A)
(C)
(E)
p
0.6
120
(B)
(D)
0.050
0.480
(B)
(D)
0.050
0.480
is:
0.035
0.240
6.928
Question 3
The standard deviation of
(A)
(C)
(E)
(B)
(D)
p
is:
0.035
0.240
6.928
Question 4
The sampling distribution of
p
can be approximated by a:
(A)
binomial distribution whenever,
(B)
binomial distribution whenever,
(C)
binomial distribution whenever,
(D)
(E)
normal distribution whenever,
normal distribution whenever,
n 30
np 5
np 5
and
n(1 p) 5
and
n 30
and
n(1 p) 5
n 30
np 5
Memorandum:
130
0.65
200
2. Option B p p 0.65 0.6 0.05
1. Option C
p
3. Option A
p
p1 p
0.60.4
0.035
n
200
4. Option E (theory on page 301 in textbook)
Copyright Reserved
150
Chapter 8
Question 1
The fuel consumption (in l/100km) of 10 motors that conducted a 500 km test is as
follows:
8.93
7.75
7.90
8.20
8.41
8.50
8.05
7.93
8.60
8.33
x 8.26
Given:
s 0.3645
Assume: The fuel consumption is normally distributed.
The upper limit of the 99% confidence limit of the population mean is:
(A)
(C)
(E)
8.528
8.587
8.635
(B)
(D)
8.557
8.626
Memorandum:
Question 1
x tα / 2
s
n
= 8.26 3.250
0.3645
= 8.6346
10
Answer: (E)
Copyright Reserved
151