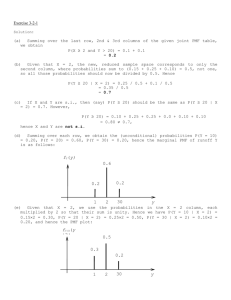
STA355H1F: About the course
I Instructor: Keith Knight (e-mail:
keith.knight@utoronto.ca)
I Textbook: Statistical Models by A.C. Davison plus
“handouts” on Quercus.
I Note that this text is recommended but not required.
I It is available through the UoFT Library system - link provided
on Quercus.
I The book An Introduction to Statistical Learning by James et
al. (STA314H text?) is also quite useful for some topics in
this course.
I Grading scheme:
I
I
I
I
I
4 assignments: 20% total
Midterm exam (November 1 during usual lecture time): 35%
Final exam: 45%
Assignments submitted online.
Exams will be in-person.
I Computing: R (or RStudio)
1 / 21
What else?
I Prerequisites: 2nd year stats + 2nd year calculus + linear
algebra (MAT223 or MAT240)
I Please note that these prerequisites are very strictly enforced
and will not be waived.
I STA302 is a useful corequisite (or prerequisite) for this course.
I Goals:
I STA355 provides a bridge between 200-level STA courses and
the more mathematical STA452/453.
I STA355 gives the necessary theoretical background for
students planning to take STA490 (Statistical Consultation,
Communication, and Collaboration) as well as other 400-level
STA courses.
I Study groups, group chats, etc. are encouraged.
I Ask questions or discuss online via Piazza.
2 / 21
Probability: A review
I Random experiment: Mechanism producing an outcome
(result) perceived as random (or uncertain).
I Sample space: Set of all possible outcomes of the
experiment:
S = {ω1 , ω2 , · · ·}
| {z }
outcomes
I Examples:
1. Toss a coin until heads comes up:
S = {H, TH, TTH, TTTH, · · · }
2. Waiting time until the next bus arrives:
S = {t : t ≥ 0}.
3 / 21
Probability function (measure)
I Given a sample space S, define A to be a collection of subsets
(called events) of S satisfying the following conditions:
1. S ∈ A;
2. A ∈ A implies that Ac ∈ A;
3. A1 , A2 , · · · ∈ A implies that A1 ∪ A2 ∪ A3 ∪ · · · ∈ A.
I If S is finite or countably infinite then A could consist of all
subsets of S (including the empty set ∅).
I A probability function (measure) P on A satisfies the
following conditions:
1. For each A ∈ A, P(A) ≥ 0;
2. P(∅) = 0 and P(S) = 1;
3. If A1 , A2 , · · · are disjoint (mutually exclusive) events
(Ai ∩ Aj = ∅ for i 6= j) then
!
∞
∞
X
[
P(Ai ).
P
Ai =
i=1
i=1
4 / 21
Simple properties of probabilities
I P(Ac ) = 1 − P(A).
I Proof: 1 = P(S) = P(A ∪ Ac ) = P(A) + P(Ac ).
I P(A ∪ B) = P(A) + P(B) − P(A ∩ B).
I Proof: Write A and A ∪ B as unions of disjoint sets:
P(A) = P(A ∩ B) + P(A ∩ B c ) and
P(A ∪ B) = P(B) + P(A ∩ B c ).
I Using Venn diagrams helps with intuition here.
I Note also that P(A ∪ B) ≤ P(A) + P(B).
5 / 21
Simple properties of probabilities
I The identity P(A ∪ B) = P(A) + P(B) − P(A ∩ B) can be
generalized to
!
n
n
X
X
[
=
P(Ai ) −
P(Ai ∩ Aj )
P
Ai
i=1
i=1
|
{z
i<j
}
P(A1 ∪···∪An )
+
X
P(Ai ∩ Aj ∩ Ak )
i<j<k
− · · · − (−1)n P(A1 ∩ · · · ∩ An )
I Similarly, we have Bonferroni’s inequality:
!
n
n
[
X
P
Ai ≤
P(Ai ).
i=1
i=1
6 / 21
Conditional probability
I If we know that an event B has occurred then we can modify
our assessments of probabilities – these are called conditional
probabilities.
I The probability of A conditional on B is defined by
P(A ∩ B)
P(A|B) =
P(B)
if P(B) > 0.
I If P(B) = 0, we can still (usually) define P(A|B) but we need
to be more careful mathematically.
I Bayes Theorem: If B1 , · · · , Bk are disjoint events with
B1 ∪ · · · ∪ Bk = S then
P(Bj )P(A|Bj )
P(Bj |A) = k
X
P(Bi )P(A|Bi )
i=1
This also holds for a countable collection of disjoint events
B1 , B2 , · · · with B1 ∪ B2 ∪ · · · = S setting k = ∞ above.
7 / 21
Independence
I Two events A and B are independent if
P(A ∩ B) = P(A)P(B).
I When P(A), P(B) > 0, this is equivalent to
P(A|B) = P(A) and P(B|A) = P(B).
I Events A1 , A2 , · · · are independent if
P(Ai1 ∩ Ai2 ∩ · · · Aik ) =
k
Y
P(Aij )
j=1
for all i1 < i2 < · · · < ik .
8 / 21
Interpretation of probabilities
I Long-run frequencies: If we repeat the experiment many
times then
P(A) = proportion of times the event A occurs
I Degrees of belief (subjective probability): If P(A) > P(B)
then we believe that A is more likely to occur than B.
I =⇒ Aleatory (i.e. pure randomness) versus epistemic (i.e.
knowledge or lack of knowledge) uncertainty.
9 / 21
Frequentist versus Bayesian statistical methods
I Frequentists: Pretend that an experiment (for example, a
study) is at least conceptually repeatable.
I Uncertainty is described (ideally) in terms of the (inferred)
variability over replications of the experiment.
I “Probabilities are facts!” ... based on possibly dubious
assumptions!
I Bayesians: Use subjective probability to describe uncertainty
in parameters and data.
I “Probabilities are opinions!” ... possibly a more realistic
viewpoint!
I This course: We’ll mostly treat uncertainty from a
frequentist perspective although a few lectures will be devoted
to the Bayesian perspective.
10 / 21
Random variables
I A random variable is a real-valued function defined on a
sample space S: X : S −→ R (the real line).
I In other words, for each outcome ω ∈ S, X (ω) is a real
number.
I Example: Toss a coin 20 times:
S = {H · · · H, TH · · · H, · · · , T · · · T } .
|
{z
}
220 =1048576 outcomes
I Define X = number of heads: X takes integer values between
0 and 20.
I The probability distribution of X depends on the
probabilities assigned to the outcomes in S.
I Simplest case: Independent tosses with P(heads) = θ:
20 x
P(X = x) =
θ (1 − θ)20−x for x = 0, 1, · · · , 20.
x
11 / 21
Probability distributions
I Define the (cumulative) distribution function (cdf) of X :
F (x) = P(X ≤ x) = P(ω ∈ S : X (ω) ≤ x).
Notation: X ∼ F .
I Properties of F :
1. If x1 ≤ x2 then F (x1 ) ≤ F (x2 );
2. F (x) → 0 as x → −∞ and F (x) → 1 as x → +∞;
3. F is right-continuous with left-hand limits:
lim F (y ) = F (x) lim F (y ) = F (x−) = P(X < x).
y ↓x
y ↑x
4. P(X = x) = F (x) − F (x−).
12 / 21
F(x)
0.6
0.8
1.0
Generic cdf of a random variable X
0.0
0.2
0.4
●
0.0
0.2
0.4
0.6
0.8
1.0
x
I P(X = 0.4) = height of jump in cdf at x = 0.4 =
F (0.4) − F (0.4−)
13 / 21
Continuous and discrete random variables
I If X ∼ F where F is a continuous function then X is a
continuous random variable.
I If F is continous then we can typically find a (non-negative)
probability density function (pdf) f such that
Z x
F (x) =
f (t) dt.
−∞
I Conceptually, we can think of f (x) = F 0 (x).
I If X takes only a finite or countably infinite number of
possible values then it is a discrete random variable.
I If X is discrete then F is a step-function and we can define its
probability mass function (pmf) by
f (x) = F (x) − F (x−) = P(X = x).
14 / 21
1.0
Cumulative distribution function of X ∼ Binomial(5, 1/2)
●
0.8
●
F(x)
0.6
●
0.0
0.2
0.4
●
●
●
0
1
2
3
4
5
x
15 / 21
Expected values
I What are they? Simple descriptive measures of a probability
distribution (e.g. mean and variance).
I Suppose that X is a continuous random variable with pdf
f (x) or a discrete random variable with pmf f (x).
I If h is a function such that P(h(X ) ≥ 0) = 1 then we can
define the expected value of h(X ) by
Z ∞
E [h(X )] =
h(x)f (x) dx (continuous)
−∞
X
h(x)f (x) (discrete)
E [h(X )] =
x
I Under the non-negativity assumption, E [h(X )] ≥ 0 but may
equal +∞.
I How do we define E [h(X )] more generally?
16 / 21
Expected values
I Idea: Write h(x) = h+ (x) − h− (x) where
h+ (x) = max{h(x), 0} and h− (x) = max{−h(x), 0}
I Then E [h(X )] = E [h+ (X )] − E [h− (X )], if this difference is
well-defined.
1. If E [h+ (X )] and E [h− (X )] are both finite then
E [h(X )] = E [h+ (X )] − E [h− (X )].
2. If E [h+ (X )] = +∞ and E [h− (X )] is finite then
E [h(X )] = +∞.
3. If E [h+ (X )] is finite and E [h− (X )] = +∞ then
E [h(X )] = −∞.
4. If E [h+ (X )] and E [h− (X )] are both infinite then E [h(X )] does
not exist.
17 / 21
Example: Cauchy distribution
I X is a continuous random variable with pdf
f (x) =
1
(−∞ < x < ∞)
π(1 + x 2 )
I Note that the density is symmetric around 0 (f (x) = f (−x))
so we might suspect that E (X ) = 0.
I However ...
Z ∞
x
+
−
E (X ) = E (X ) =
dx
π(1 + x 2 )
0
1
ln(1 + x 2 )
= lim
x→∞ 2π
= +∞
I Thus E (X ) = E (X + ) − E (X − ) does not exist!
18 / 21
Variance and standard deviation
I Suppose that X is a random variable with E (X 2 ) < ∞.
I Then we can define the variance of X as
Var(X ) = E [(X − E (X ))2 ] = E (X 2 ) − [E (X )]2
I Note that the units of Var(X ) are the squares of the units of
X;
I For example, if the units of X are metres then the units of
Var(X ) are metres2 .
I Var(X + a) = Var(X ); Var(aX ) = a2 Var(X ) for any constant
a.
p
I The standard deviation of X , sd(X ) = Var(X ) has the
same units as X .
19 / 21
Independent random variables
I Random variables X1 , X2 , · · · are independent if the events
[X1 ∈ A1 ], [X2 ∈ A2 ], · · · are independent events for any
A1 , A2 , · · · .
I If X1 , · · · , Xn are independent continuous (discrete) random
variables with pdfs (pmfs) f1 , · · · , fn then the joint pdf (pmf)
of (X1 , · · · , Xn ) is
f (x1 , · · · , xn ) = f1 (x1 ) × f2 (x2 ) × · · · × fn (xn ) =
n
Y
fi (xi )
i=1
I Independence turns out to be a convenient assumption for
many statistical models.
20 / 21
Sums of independent random variables
I Suppose that X1 , · · · , Xn are independent random variables
with means µ1 , · · · , µn and variances σ12 , · · · , σn2 .
I Define S = X1 + · · · + Xn .
I Then
I E (S) = µ1 + · · · + µn (which is true even if X1 , · · · , Xn are not
independent).
I Var(S) = σ12 + · · · + σn2 .
I Question: Can we say anything more about the probability
distribution of S?
21 / 21