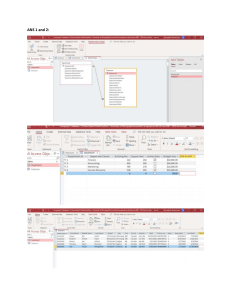
Introduction This week, you will learn some important details about the relational model's logical structure and how the entity relationship diagram (ERD) can be used to design a relational database (Kroenke & Auer, 2016). You will see that a table is a structure that contains the relational database's basic data components, entities, and their attributes (Kroenke & Auer, 2016). This is a simple approach that treats the tables as a logical structure instead of a physical one. Each table within the database is treated as independent and related to other tables through relationships. After learning about tables, their components, and their relationships, you will be introduced to the basic concepts that shape the design of tables and the characteristics of good design and poor design (Kroenke & Auer, 2016). Relational Tables By this time, it should be clear to you that a table is basically a two-dimensional entity that has rows (also called records and tuples) and columns (also called fields and attributes), which look similar to a spreadsheet; however, a spreadsheet is not a relational database table because it does not meet some very precise constraints on the rows and columns. A spreadsheet is a flat file compared to a table. In particular, the following must be true for a table to be a relational table. • • • • • • Each row of the table holds data that pertains to one, and only one, instance of the entity. Each cell contains a single data value, and each cell is atomic and cannot be further subdivided. All the entries in any column, or attribute, must be of the same data type. Each column, or attribute, has a defined range of values (attribute domain). The order of the rows does not matter. Each row has at least one attribute or a combination of attributes that uniquely identifies that row (the primary key). (Kronke & Auer, 2016) If a table satisfies these conditions, it is then called a relational table. One thing to keep in mind is that the terms relational table and relationship mean two different things. A relationship defines the logical association between two relational tables, whereas relational table means that you have a two-dimensional structure (rows and columns) that satisfies the criteria listed above (Kroenke & Auer, 2016). The goal of relational database design is to define all the relational tables and the logical relationships between the tables. However, it is perfectly acceptable (although not practical) to have a relational database that has no relations defined between the tables. Entity Types We begin our database design by developing an entity relationship diagram, which is any diagram that attempts to show the flow of data and its relationships (Kroenke & Auer, 2016). We could even say that an entity relationship diagram can also serve as the basis for the design of the files in a conventional flat file-based system, such as your Excel spreadsheets (Grauer, 2016). Although there may be different ways to draw diagrams depending on the methodology used, they all have the same basic elements: entities, attributes, and relationships. These three categories are considered to be building blocks for all data modeling of any organization's information processing needs (Kroenke & Auer, 2016). An entity is defined as any type of object about which we wish to store data (Kroenke & Auer, 2016). How many types of entities you decide to include on your diagram depends on what you are attempting to model. For example, in a manufacturing environment, you would probably store data about customers, suppliers, products, invoices, and payments. Because we would want to store data about each of these, we would label them as an entity. We typically draw an entity as a box in our diagram and show it once in the diagram. There may be many entity types in our diagram, and we typically show the relationship between them. Another important thing to remember is that the name of an entity must be singular. We have different types of entities, and they are typically referred to as a set of objects. Many business analysts prefer to use the term entity set. So if you hear the term used, the analysts are referring to the different types of entities. Entities are nothing more than one instance of the type. For example, within the entity type suppliers, we may have Mack Metal as one entity. The company is an individual entity within the type suppliers. Think of it this way: Our starting point in entity relationship diagrams has to be to identify the entities and the types of entities we have in our process. Attributes Now that you have a better understanding of entities, we need to define or determine the type of data we want to keep about each entity within an entity type. In our diagram, this is going to be referred to as an attribute (Kroenke & Auer, 2016). An attribute is nothing more than some characteristic about the entities that we are interested in and want to store in the database (Kroenke & Auer, 2016). The important thing to remember is that each entity within the entity type will have the same set of attributes but different values (Kroenke & Auer, 2016). Did that confuse you a bit? Perhaps an example will clear it up. The value of the attribute address for our metals supplier Mack Metal in the supplier entity type might be 3200 Industrial Lane, Pittsburgh, PA. The important rule to remember is that there will always be the same number of attributes for each entity within an entity type (Kroenke & Auer, 2016). That is one of the characteristics of all entity relationship modeling and relational databases. We store the same type of facts (attributes) about every entity within the entity type. Primary Keys One of the main objectives, when we identify our tables, is to be able to identify each individual instance of the entity, or in other words, uniquely identify a row, record, or tuple (an ordered list of elements). All three terms mean the same thing, and you will hear them used interchangeably. The table attribute is often called a field or a column, so you will want to get used to these terms as well. The most important field that we need to identify is the one that uniquely identifies a row. This field is called a primary key, and as you generate your entities, you may find that identifying the primary key can be a bit challenging. Foreign Keys Now that we know how to find the primary key, we can use it to establish the relationships between our tables. We do this by adding an attribute called the foreign key to another table that matches the primary key of the referenced table (Kroenke & Auer, 2016). Because the foreign key matches the primary key in the other table, the key value can be a composite key (multiple attributes) (Kroenke & Auer, 2016). An ERD Example The reading describes how to create and interpret an ERD in detail. As a further example, consider the following real-world ERD. This diagram illustrates a typical ERD in a commercial database application, and the following items demonstrate how to read the ERD. Before you look at the answers, see if you can identify the relationships. 1. 2. 3. 4. An employee may be an engineer. An engineer must be an employee. A truck can only be assigned to one engineer. An engineer can have only one truck, but an engineer may not be assigned a truck. 5. An engineer can perform many or no services. 6. A service must be performed by only one engineer. 7. An engineer can have many certifications, but may have none. 8. An engineer certification must be related to one engineer. 9. Engineer certification can have only a single certification test. 10. A certification test can create several engineer certifications. 11. A service is associated with many or no clients. 12. A client can have many services, but must have at least one service. Summary This lesson discussed the concepts of functional dependence and how it is used to find the primary key, which is one of the most important attributes in every table. Once we have found the primary key, we can use a table primary key as an attribute in another table, which we called a foreign key (Kroenke & Auer, 2016). By defining the primary key and foreign key relationships, we implemented the relational schema that is defined in our entity relationship diagrams. As part of this process, we determined the business rules that defined the referential integrity rules that we want our DBMS to enforce. In addition, we reviewed the basic building blocks of the entity relationship diagram. References Kroenke & Auer (2016), Data Processing: Fundamentals, Design, and Implementation, Upper Saddle River, New Jersey: Pearson Learning.