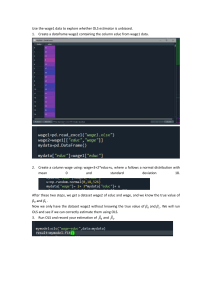
Econometrics I Catarina Pimenta & Miguel Portela: LECO - 2023/2024 Topics 2 I. The classical linear regression model 0. Introduction 1. Simple/two-variable linear regression 2. Multiple linear regression Specification Estimation Inference Specification analysis 3 Introduction Simple/two-variable linear regression Introduction Model Specification Estimation 0. Introduction What is Econometrics and its scope? 5 5 “Measurement in Economics” - application of statistical methods and mathematics to economic data Econometrics aims at: Quantifying economic relationships Testing competing hypotheses/theories Forecasting It is important to be able to apply economic theory to real world data Examples of Econometrics problems 6 Evaluating the effect of participation in training programmes on wages Effect of campaign spending on electoral outcomes How educational expenditures relate to student achievement Impacts of dividend announcement on stock prices Basic steps of econometric modelling 7 Economic theory (previous studies) Specify a estimable, theoretical model Data collection and database construction Model estimation Is it a statistically good model? no Reformulate the model yes Interpret the model analysis Data 8 Data are the raw materials for Quantifying economic relationships Testing competing theories Forecasting Observation Data: set of observation containing information on several variables (e.g., wage, age, education) Data 9 Types of data Cross section Time series Panel data Cross section data 10 Data collected by observing many subjects at the same point of time Each subject/unit of analysis is an individual, a firm, a country, a region, a family, a firm, a city, a state Usually a random sample Cross section data 11 Example: Observation Wage Education Experience Female Married 1 500 9 8 1 0 2 427 4 12 1 1 3 965 16 2 0 1 4 1323 16 6 1 0 … … … … … … 2127 650 12 1 0 0 Time series data 12 The statistical unit is observed over time Examples: stock prices, GDP, car sales, exchange rate, prices, day of the week Time series data 13 Some problems may arise: Trend is relevant: time may provide relevant information; past events may influence future events Observations may not be independent Data frequency: daily, weekly, monthly, quarterly, annually - seasonality Time series data 14 Example Observation Yeas Unemployment rate Average wage GDP 1 1972 9.2 325 77 2 1973 10.5 364 82 3 1974 8.7 351 85 4 1975 11 373 97 … … … … … 37 2008 12.5 498 160 Panel data 15 Cross-sectional time-series data Information on several statistical units over time Hard and expensive to get Panel data 16 Example: Observation Individual Year Wage Urban 1 1 2001 400 1 2 1 2002 407 1 3 1 2003 410 1 4 2 2001 674 0 5 2 2002 677 0 6 2 2003 682 1 … … … … … 298 100 2001 965 0 299 100 2002 971 0 300 100 2003 973 0 Variables 17 Econometric models are based on variables Variable classification Quantitative Qualitative Variables - quantitative 18 Continuous can take any value between its minimum value and its maximum value Example: wage Discrete: can only take on a finite number of values (often, integer – count data) Example: years of experience Variables - qualitative 19 Examples Marital status: married, single, divorced, ... Gender: male, female Secondary education track: Scientific-Humanistic, Professional, .. Self reported health status: very bad, bad, average, good, very good Types of numbers 20 Cardinal The magnitude of differences in values is meaningful Examples ◼ ◼ Stock prices Wage Types of numbers 21 Ordinal categorical variable for which the possible values are ordered Examples ◼ set of programme-institution alternatives of a higher education candidate Types of numbers 22 Nominal Non-ordered values The values have no meaning Examples ◼ ◼ Random numbers: fiscal number, phone number, id card Dummy variables: Gender Male = 1 Female = 0 Data sources 23 Examples Government Non-governmental organizations Research Institutes Researchers Web Links 24 Resources for Economists: http://rfe.wustl.edu/Data/index.html Statistics Portugal (INE): http://www.ine.pt Bank of Portugal: http://www.bportugal.pt OCDE: http://www.oecd.org World Bank: http://www.worldbank.org IMF: http://www.imf.org Check: https://github.com/reisportela/R_Training 1. Simple/two-variable linear regression Introduction: what is regression analysis? 26 Statistical method that allows you to examine the relationship between two or more variables of interest Income elasticity of demand Impact of education on wages It is used to model the relationship between a dependent variable and one or a set of independent variables Introduction: regression versus correlation 27 Most times, the establishment of a relationship is not enough, we need to look at a causal effect Causality (an event causes other event) versus correlation (association between two variables) There is a high positive relationship between the number of fire fighters sent to a fire and the amount of damage done. Does this mean that the fire fighters cause the damage? Or is it more likely that the bigger the fire, the more fire fighters are sent and the more damage is done? In this example, the variable "size of the fire" is the causal variable, correlating with both the number of fire fighters sent and the amount of damage done. There is a positive relationship between the consumption of ice creams and crimes against property. Does this mean that having ice creams cause crime? Causality may be difficult to define Introduction: regression and ceteris paribus condition 28 Ceteris paribus: other things equal, all other things being equal It is a way of isolating the effect of a given variable Example: Demand A = f(price of good A, other goods price, income) Introduction: relationship between variables 29 Regression analysis: A dependent variable (Y) – which we want to explain is explained by means of explanatory variable(s) ◼ Simple regression – only one explanatory variable (X) ◼ Multiple regression – more than one explanatory variable ( 𝑋1 , … , 𝑋𝑘 ) Introduction: relationship between variables - example 30 Observation 1 2 3 4 … 730 Sun’s height (Y) 1.66 1.67 1.63 1.72 … 1.68 Father’s height (X) 1.70 1.71 1.66 1.70 … 1.63 Introduction: relationship between variables - example 31 1.85 Summarizes the relationship between the sun’s height and the father’s height Sun’s height (y) 1.80 1.75 1.70 1.65 What is the meaning of the trend line? What is the equation of that line? 1.60 1.55 1.50 1.50 1.55 1.60 1.65 1.70 1.75 Father’s height (x) 1.80 1.85 Model Specification 32 Starting point: Model (more realistic): 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 Y is ◼ Dependent variable ◼ Explained variable ◼ Regressand 𝑌𝑡 = 𝛽0 + 𝛽1 𝑋𝑡 + 𝑢𝑡 Model Specification 33 X is: ◼ Independent variable ◼ Explanatory variable ◼ Regressor Model Specification 34 ui is: ◼ Error ◼ Residual ◼ Disturbance Why an error term? ◼ some determinants of Y are not in the model ◼ Specification errors or wrong functional form ◼ Measurement errors in Y ◼ Other random influences on Y that cannot be modelled What does linear mean? 35 The model is linear with respect to parameters (𝛽0 and 𝛽1 ) It does not need to be linear with respect to variables Estimation 36 How do we estimate the values of 𝛽0 and 𝛽1 ? We need a method to determine the line that best fits the data That is, we need to choose 𝛽0 and 𝛽1 that minimizes vertical distance from each point to the fitted line Estimation 37 Notation Observed values of Estimated values of Estimated residuals: 𝑌𝑖 : 𝑌𝑖 : 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 0 + 𝑌𝑖 = 𝛽 𝛽1 𝑋𝑖 𝑢ෝ𝑖 = 𝑌𝑖 − 𝑌𝑖 PRF – Population regression function SRF – Sample regression function Estimators versus estimates 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢ො𝑖 Estimation 38 When deciding on the estimation method, several objectives may be defined: Minimize the sum of residuals ◼ Problem: Positive and negative values cancel out Minimize the sum of the absolute value of the residuals Minimize the sum of the squared residuals ◼ The most popular method – Ordinary Least Squares (OLS) Estimation: Ordinary Least Squares (OLS) 39 Minimize the sum of the squared residuals is a standard calculus problem Write the first order partial derivative with respect to each of the parameter to be estimated Equal each derivative to zero and solve the system composed by the two equations Estimation: Ordinary Least Squares (OLS) 40 How to estimate the model coefficients by OLS? The parameters are to be estimated based on a sample Consider a random sample of size n For each observation in the sample, we observe that 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 Estimation: Ordinary Least Squares (OLS) 41 Starting point: 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 0 + 𝑌𝑖 = 𝛽 𝛽1 𝑋𝑖 OLS objective: n min uˆi i =1 2 𝑛 𝑢ෝ𝑖 2 = 𝑌𝑖 − 𝑌𝑖 𝑖=1 𝑢ෝ𝑖 = 𝑌𝑖 − 𝑌𝑖 𝑛 𝑖=1 𝑛 2 = 𝑌𝑖 − 𝛽0 − 𝛽1 𝑋𝑖 𝑖=1 2 Estimation: Ordinary Least Squares (OLS) 42 Resolution: Minimization problem – first order conditions: 𝜕 σ𝑛𝑖=1 𝑢ෝ𝑖 2 𝑛 =0 0 𝜕𝛽 ⟺ 2 𝑛 𝜕 σ𝑖=1 𝑢ෝ𝑖 =0 𝜕 𝛽1 2 𝑌𝑖 − 𝛽0 − 𝛽1 𝑋𝑖 −1 = 0 𝑖=1 𝑛 0 − 2 𝑌𝑖 − 𝛽 𝛽1 𝑋𝑖 −𝑋𝑖 = 0 𝑖=1 Estimation: Ordinary Least Squares (OLS) 43 Dividing both equations by (-2) : 𝑛 𝑌𝑖 − 𝛽0 − 𝛽1 𝑋𝑖 = 0 𝑖=1 𝑛 0 − 𝑌𝑖 − 𝛽 𝛽1 𝑋𝑖 𝑋𝑖 = 0 𝑖=1 Estimation: Ordinary Least Squares (OLS) 44 Solving the equations: 𝑛 𝑛 𝑌𝑖 − 𝑛 𝛽0 − 𝛽1 𝑋𝑖 = 0 𝑛 𝑖=1 𝑛 𝑖=1 𝑛 𝑌𝑖 𝑋𝑖 − 𝛽0 𝑋𝑖 − 𝛽1 𝑋𝑖 2 = 0 𝑖=1 𝑖=1 𝑖=1 Estimation: Ordinary Least Squares (OLS) 45 Rearranging the equations: 𝑛 𝑛 𝑛 𝛽0 + 𝑋𝑖 𝛽1 = 𝑌𝑖 𝑛 𝑖=1 𝑛 𝑖=1 𝑛 𝑋𝑖 𝛽0 + 𝑋𝑖 2 𝛽1 = 𝑌𝑖 𝑋𝑖 𝑖=1 𝑖=1 𝑖=1 Estimation: Ordinary Least Squares (OLS) 46 Solving the system of equations using the Kramer rule: σ𝑛𝑖=1 𝑌𝑖 σ𝑛𝑖=1 𝑋𝑖 σ𝑛𝑖=1 𝑌𝑖 𝑋𝑖 σ𝑛𝑖=1 𝑋𝑖 2 0 = 𝛽 σ𝑛𝑖=1 𝑋𝑖 𝑛 σ𝑛𝑖=1 𝑋𝑖 σ𝑛𝑖=1 𝑋𝑖 2 𝑛 σ𝑛𝑖=1 𝑋𝑖 𝛽1 = 𝑛 σ𝑛𝑖=1 𝑋𝑖 σ𝑛𝑖=1 𝑌𝑖 σ𝑛𝑖=1 𝑋𝑖 𝑌𝑖 σ𝑛𝑖=1 𝑋𝑖 σ𝑛𝑖=1 𝑋𝑖 2 Estimation: Ordinary Least Squares (OLS) 47 Then: 0 = 𝛽 σ𝑛𝑖=1 𝑋𝑖 2 σ𝑛𝑖=1 𝑌𝑖 − σ𝑛𝑖=1 𝑋𝑖 σ𝑛𝑖=1 𝑌𝑖 𝑋𝑖 𝛽1 = 𝑛 σ𝑛𝑖=1 𝑋𝑖 2 − 2 𝑛 σ𝑖=1 𝑋𝑖 𝑛 σ𝑛𝑖=1 𝑋𝑖 𝑌𝑖 − σ𝑛𝑖=1 𝑋𝑖 σ𝑛𝑖=1 𝑌𝑖 𝑛 σ𝑛𝑖=1 𝑋𝑖 2 − 2 𝑛 σ𝑖=1 𝑋𝑖 Estimation: Ordinary Least Squares (OLS) 48 Or, in an alternative way: 0 = 𝑌ത − 𝛽 𝛽1 𝑋ത σ𝑛𝑖=1 𝑋𝑖 − 𝑋ത 𝑌𝑖 − 𝑌ത σ𝑛𝑖=1 𝑥𝑖 𝑦𝑖 𝛽1 = = 𝑛 𝑛 2 ത σ𝑖=1 𝑥𝑖 2 σ𝑖=1 𝑋𝑖 − 𝑋 Deviation from the mean form OLS estimators Estimation: Example 49 Obs. Wage (Y) Educ (X) 𝑌𝑖 − 𝑌ത 1 200 4 -170 2 450 12 80 3 340 9 -30 4 290 6 -80 5 570 14 200 𝑌ത =370 𝑋ത =9 𝑋𝑖 − 𝑋ത 𝑌𝑖 − 𝑌ത 𝑋𝑖 − 𝑋ത 𝑋𝑖 − 𝑋ത -5 3 0 -3 5 850 240 0 240 1000 25 9 0 9 25 𝑛 2 𝑛 𝑋𝑖 − 𝑋ത 𝑌𝑖 − 𝑌ത 𝑖=1 𝑋𝑖 − 𝑋ത 𝑖=1 =2330 =68 2 Estimation: Example 50 Determine 𝛽1 σ𝑛𝑖=1 𝑋𝑖 − 𝑋ത 𝑌𝑖 − 𝑌ത 2330 𝛽1 = = = 34.26471 𝑛 2 ത 68 σ𝑖=1 𝑋𝑖 − 𝑋 0 Determine 𝛽 0 = 370 − 34.26471 x 9 = 61.61765 𝛽 Estimation: Example 51 Those estimates allow us to write the estimated model: 𝑤𝑎𝑔𝑒 ෟ = 61.61765 + 34.26471𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 The estimated average wage of an individual with no educations is about €61.61765 Each additional year of education raises the wage, on average, by €34.26471. Homework 1 – excel + “paper and pencil” 52 Estimate the following equation by OLS 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 Using the data: -- task -- i 1 2 3 4 Xi 10 20 30 40 Yi 300 400 500 600 5 50 1000 Homework 2 53 Consider the model 𝑌𝑖 = 𝛽1 𝑋𝑖 + 𝑢𝑖 determine the OLS estimator for 𝛽1 54 Learning outcomes Homework correction Notes Multiple choice questions Linear model functional forms Takeaways 55 Upon completion of this lesson, you should be able to do the following: Distinguish between different types of data and recognize its specificities Distinguish between regression and correlation Distinguish between a deterministic relationship and a statistical relationship Understand the concept of the least squares’ criterion Recognize the distinction between a population regression line and the estimated regression line Interpret the intercept 𝛽0 and slope 𝛽1 of an estimated regression equation Homework 1 – Solution 56 i 1 2 3 4 5 Média Somatório Xi 10 20 30 40 50 30 Yi 300 400 500 600 1000 560 Xi-Xmedia Yi-Ymedia -20 -260 -10 -160 -60 0 10 20 40 440 (Xi-Xmedia)(Yi-Ymedia) 5200 1600 0 400 8800 16000 estimativa estimativa beta1 beta0 16 80 =16000/1000 =560-16*30 (Xi-Xmedia)2 400 100 0 100 400 1000 Homework 1 – Solution 57 1200 Para fazer o gráfico: Inserir Gráfico Gráfico de dispersão 1000 800 600 400 200 0 0 10 20 30 40 50 60 Homework 1 – Solution 58 Yi 1200 1000 y = 16x + 80 800 600 400 200 0 0 10 20 30 40 50 60 Homework 2 59 Consider the model estimator for 𝛽1 𝑌𝑖 = 𝛽1 𝑋𝑖 + 𝑢𝑖 Starting point: 𝑌𝑖 = 𝛽1 𝑋𝑖 + 𝑢𝑖 𝑛 𝑛 𝑢ෝ𝑖 2 = 𝑌𝑖 − 𝑌𝑖 𝑌𝑖 = 𝛽1 𝑋𝑖 𝑖=1 𝑢ෝ𝑖 = 𝑌𝑖 − 𝑌𝑖 n And determine the OLS 2 OLS objective: min uˆi i =1 𝑖=1 𝑛 2 = 𝑌𝑖 − 𝛽1 𝑋𝑖 𝑖=1 2 Homework 2 60 Resolution: Minimization problem – first order conditions: 𝑛 𝑛 𝜕 σ𝑛𝑖=1 𝑢ෝ𝑖 2 0 − = 0 ⟺ 2 𝑌𝑖 − 𝛽1 𝑋𝑖 −𝑋𝑖 = 0 ⟺ 𝑌𝑖 − 𝛽 𝛽1 𝑋𝑖 𝑋𝑖 = 0 𝜕𝛽1 ⟺ 𝑖=1 σ𝑛𝑖=1 𝑌𝑖 𝑋𝑖 − 𝛽1 σ𝑛𝑖=1 𝑋𝑖 2 =0⟺ 𝛽1 = σ𝑛 𝑖=1 𝑋𝑖 𝑌𝑖 2 σ𝑛 𝑖=1 𝑋𝑖 𝑖=1 Notes 61 1. Population versus sample 2. Population Regression Function and Sample Regression Function 3. Estimator versus estimate Note 1: Population versus sample 62 Population: Set/Collection of all elements/units under study Objective: Predicting election outcomes Population: all registered voters Sample: Group of subjects of the population Random sample: Each individual is chosen entirely by chance and each member of the population has an equal chance of being included in the sample. Note 2: Population Regression Function and Sample Regression Function 63 Population Regression Function (PRF): The model that generated the data The actual relationship between the variables It is given by: 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢ෝ𝑖 Or: 𝑌𝑖 = 𝑌𝑖 Estimated residuals Observed values of Y Estimated value of Y Note 2: Population Regression Function and Sample Regression Function 64 Sample Regression Function (SRF): The estimated relationship 𝛽1 𝑋𝑖 It is written as: 𝑌𝑖 = 𝛽0 + It is used to infer likely values of the PRF Note 3: Estimator versus estimate 65 Estimator: rule for calculating an estimate (the value of a parameter) Estimate: the value of a parameter obtained using the rule, based on observed data Exercise 1 (Oliveira et al., 1999 - adapted) 66 Consider the following simple regression model (A) 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 And its OLS estimation results 𝐵 𝑌𝑖 = 𝛽መ0 + 𝛽መ1 𝑋𝑖 + 𝑢ෝ𝑖 Exercise 1 (Oliveira et al., 1999 - adapted) 67 Estimators 𝛽መ0 and 𝛽መ1 are: ◼ ◼ ◼ A. observable, non-random variables B. unknown constants C. random variables Exercise 1 (Oliveira et al., 1999) - adapetd 68 𝑋𝑖 is ◼ ◼ ◼ ◼ A. i-th observation of the explanatory variable B. i-th explanatory variable C. i-th observation of the explained variable D. i-th explained variable Exercise 1 (Oliveira et al., 1999) - adapted 69 Parameters 𝛽0 and 𝛽1 ◼ ◼ ◼ ◼ A. vary across samples but are constant for a given population B. vary across populations C. vary across observations within a sample, but are constant across samples D. vary across observations within a sample, but are constant for a given population Exercise 1 (Oliveira et al., 1999 - adapted) 70 Model (A) is linear because: ◼ ◼ ◼ A. There is a linear relationship between 𝑌 and 𝛽0 , 𝛽1 B. There is a linear relationship between 𝑌 and 𝑋 C. There is a linear relationship between 𝑌 and 𝑋, 𝑢 Functional form in the linear model 71 a regression equation (or function) is linear when it is linear in the parameters Examples of functional forms: Linear Double logarithmic (“Modelo potência”) Inverse semilogarithmic (“Modelo exponencial”) Semilogarithmic (“Modelo logarítmico”) Reciprocal (“Modelo hiperbólico”) Logarithmic reciprocal (“Modelo exponencial inverso”) Polynomial (“Modelo polynomial”) Linear 72 Function: Model: Main features ◼ ◼ 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 ⇒E(𝑌 𝑋 = 𝛽0 + 𝛽1 𝑋𝑖 𝑑𝑌 Constant slope: 𝛽1 = 𝑑𝑋 Variable elasticity: 𝑑𝑌 𝑌 𝑑𝑋 𝑋 𝑑𝑌 𝑋 𝑋 = 𝑑𝑋 𝑌 = 𝛽1 𝑌 Linear 73 ◼ Relationship between Y and X Y Y X X 𝛽1 > 0 𝛽1 < 0 Linear 74 Interpretation: ◼ ◼ 𝛽1 = 𝑑𝑌 𝑑𝑋 On average, as X increases by 1 unit, Y increases by 𝛽1 units 𝛽0 = E(𝑌 𝑋 = 0 When X=0, the average value of Y is 𝛽0 Double logarithmic (“Modelo potência”) 75 Function: 𝑌𝑖 = 𝛽0𝑋𝑖 𝛽1 Model: 𝑌𝑖 = 𝛽0𝑋𝑖 𝛽1 𝑒 𝑢𝑖 Linearized model: 𝑙𝑛𝑌𝑖 = 𝑙𝑛𝛽0 + 𝛽1𝑙𝑛𝑋𝑖 + 𝑢𝑖 ⇒𝐸(𝑙𝑛𝑌𝑖 |𝑙𝑛𝑋𝑖 ) = 𝑙𝑛𝛽0 + 𝛽1𝑙𝑛𝑋𝑖 Main features ◼ Variable slope: 𝑑𝑌 𝑑𝑋 = 𝛽0 𝛽1 𝑋 𝛽1 −1 (𝑌𝑖 > 0, 𝛽0 > 0, 𝑋𝑖 > 0) Double logarithmic (“Modelo potência”) 76 =Y 𝑑𝑌 𝑌 𝑑𝑋 𝑋 𝑑𝑌 𝑋 ◼ Constant elasticity: ◼ Relationship between Y and X: Y = 𝑑𝑋 𝑌 𝛽1>1 = 𝑋 𝛽0 𝛽1 𝑋𝛽1 −1 𝑌 = 𝛽0 𝛽1 Y 0 < 𝛽1 <1 𝛽1 < 0 X X 𝑋 𝛽1 𝑌 = 𝛽1 Double logarithmic (“Modelo potência”) 77 Interpretation: Relative change on Y ◼ 𝛽1 = 𝑑𝑙𝑛𝑌 𝑑𝑙𝑛𝑋 = 𝑑𝑌 𝑌 𝑑𝑋 𝑋 Relative change on X [a 1% increase in X, will increase/decrease Y by 𝛽1 % ◼ 𝑙𝑛𝛽0 = 𝐸 𝑙𝑛𝑌 𝑋 = 1 the expected mean value of lnY when X=1 Inverse semilogarithmic (“Modelo exponencial”) 85 Function: 𝑌𝑖 = 𝑒 𝛽0 +𝛽1 𝑋𝑖 Model: 𝑌𝑖 = 𝑒 𝛽0 +𝛽1 𝑋𝑖+𝑢𝑖 Linearized model: 𝑙𝑛𝑌𝑖 = 𝛽0 + 𝛽1𝑋𝑖 + 𝑢𝑖 (𝑌𝑖 > 0) ⇒𝐸(𝑙𝑛𝑌𝑖 | 𝑋𝑖 ) = 𝛽0 + 𝛽1 𝑋𝑖 Main features 𝑑𝑌 ◼ Variable slope: 𝑑𝑋 = 𝛽1 𝑒 𝛽0 +𝛽1 𝑋 = 𝛽1 𝑌 =Y Inverse semilogarithmic (“Modelo exponencial”) 86 𝑑𝑌 𝑌 𝑑𝑋 𝑋 𝑑𝑌 𝑋 ◼ Variable elasticity: : ◼ Relationship between Y and X: Y 𝛽1>0 = 𝑑𝑋 𝑌 𝑋 = 𝛽1 𝑌 = 𝛽1 𝑋 𝑌 Y 𝛽1 <0 X X Inverse semilogarithmic (“Modelo exponencial”) 87 Interpretation: ◼ ◼ 𝛽0 = 𝐸 𝑙𝑛𝑌 𝑋 = 0 𝑑𝑌 𝑑𝑙𝑛𝑌 𝛽1 = = 𝑌 𝑑𝑋 𝑋 expected mean value of lnY when X=0 Relative change on Y Absolute change on X Inverse semilogarithmic (“Modelo exponencial”) 88 ◼ What if ∆𝑋 = 1 (discrete variation rather than infinitesimal variation)? 𝑙𝑛𝑌1 = 𝛽0 + 𝛽1 𝑋1 𝑙𝑛𝑌0 = 𝛽0 + 𝛽1 𝑋0 𝑙𝑛𝑌1 − 𝑙𝑛𝑌0 = 𝛽0 + 𝛽1 𝑋1 − (𝛽0 + 𝛽1 𝑋0) 𝑙𝑛 𝑙𝑛 𝑌1 𝑌0 𝑌1 𝑌0 𝑌1 𝑙𝑛 𝑌1 𝑌0 𝑌0 = 𝛽1 (𝑋1 − 𝑋0 ) =1 = 𝛽1 ∆𝑋 = 𝛽1 =𝑒 𝛽1 ⇒ 𝑌1 −𝑌0 𝑌0 = 𝑒 𝛽1 − 1 Inverse semilogarithmic (“Modelo exponencial”) 89 ◼ What if X = time? ◼ ◼ 𝛽1 = instant growth rate of Y 𝑒 𝛽1 − 1 = discrete growth rate of Y Semilogarithmic (“Modelo logarítmico”) 90 Function: 𝑌𝑖 = 𝛽0 + 𝛽1 𝑙𝑛𝑋𝑖 Model: 𝑌𝑖 = 𝛽0 + 𝛽1 𝑙𝑛𝑋𝑖 + 𝑢𝑖 ⇒ 𝐸 𝑌𝑖 𝑋𝑖 = 𝛽0 + 𝛽1𝑙𝑛𝑋𝑖 Main features ◼ Variable slope: 𝑑𝑌 1 = 𝛽1 𝑋 𝑑𝑋 Semilogarithmic (“Modelo logarítmico”) 91 𝑑𝑌 𝑌 𝑑𝑋 𝑋 𝑑𝑌 𝑋 ◼ Variable elasticity: ◼ Relationship between Y and X: = Y 𝑑𝑋 𝑌 = 𝛽1 𝑋1 𝑌𝑋 = 𝛽1 𝑌 Y 𝛽1 > 0 𝛽1 < 0 X X Semilogarithmic (“Modelo logarítmico”) 92 Interpretation: ◼ ◼ 𝛽0 = 𝐸 𝑌 𝑋 = 1 Expected mean value of Y when X=1 𝛽1 = 𝑑𝑙𝑌 𝑌 = 𝑑𝑙𝑛𝑋 𝑑𝑋 𝑋 Absolute change on Y Relative change on X [When X increases by 1%, Y increases/decreases by 𝛽1 100 aproximately] Reciprocal (“Modelo hiperbólico”) 93 Function: Model: 𝑌𝑖 = 𝛽0 + 𝛽1 𝑌𝑖 = 𝛽0 + 𝛽1 Main features ◼ Variable slope: 1 𝑋𝑖 1 + 𝑢𝑖 𝑋𝑖 𝑑𝑌 1 = −𝛽1 2 𝑑𝑋 𝑋 Reciprocal (“Modelo hiperbólico”) 94 𝑑𝑌 𝑌 = 𝑑𝑌 𝑋 = −𝛽 1 𝑋 = −𝛽 1 1 2 1 𝑑𝑋 𝑑𝑋 𝑌 𝑋 𝑌 𝑋𝑌 𝑋 ◼ Variable elasticity: ◼ Relationship between Y and X Y 𝛽0 > 0, 𝛽1 < 0 𝛽0 Y 𝛽0 < 0, 𝛽1 > 0 − − 𝛽1 𝛽0 X 𝛽0 𝛽1 𝛽0 X Reciprocal (“Modelo hiperbólico”) 95 Interpretation: ◼ 𝐸(𝑌|𝑋 = − 𝛽1 )=0 𝛽0 When the mean value of Y is 0, − value of X ◼ lim 𝐸 𝑌 = 𝛽0 𝑋→+∞ Limit of the mean Y, as X goes to infinity 𝛽1 𝛽0 is the Logarithmic reciprocal (“Modelo exponencial inverso”) 96 Function: 𝑌𝑖 = 𝑒 Model: 𝑌𝑖 = 𝑒 𝛽0 +𝛽1 𝛽0 +𝛽1 1 𝑋𝑖 1 +𝑢𝑖 𝑋𝑖 , 𝑋 ≠ 0, 𝛽1 < 0 Linearized model: 𝑙𝑛𝑌𝑖 = 𝛽0 + 𝛽1 1 𝑋𝑖 E(𝑙𝑛𝑌𝑖 |𝑋𝑖 = 𝛽0 + 𝛽1 + 𝑢𝑖 1 𝑋𝑖 Logarithmic reciprocal (“Modelo exponencial inverso”) 97 Main features ◼ Variable slope: 𝑑𝑌 1 𝛽0+𝛽1 1 𝑌 𝑋 = −𝛽1 = −𝛽1 2 𝑒 𝑑𝑋 𝑋 𝑋2 ◼ Variable elasticity: 𝑑𝑌 𝑌 = 𝑑𝑌 𝑋 = −𝛽 𝑌 𝑋 = −𝛽 1 1 2 1 𝑑𝑋 𝑑𝑋 𝑌 𝑋 𝑌 𝑋 𝑋 Logarithmic reciprocal (“Modelo exponencial inverso”) 98 ◼ Relationship between Y and X: Y 𝑒 𝛽0 𝑒 𝛽0−2 − 𝛽1 2 X Logarithmic reciprocal (“Modelo exponencial inverso”) 99 Interpretação: ◼ ◼ 𝛽 Até 𝑋 = − 1 , Y cresce a taxas crescentes e, a partir desse valor, cresce 2 a taxas decrescentes lim 𝐸 𝑙𝑛𝑌 = 𝛽0 , o valor médio de lnY estabiliza no valor assintótico 𝑋→+∞ How do we choose the functional form? 100 The economic theory The use of logs to get relative values Adjustment quality evaluation to choose among alternatives Properties of the OLS estimation 107 1. 2. 3. Written as a function of Y and X Point estimators Once we get the OLS estimators, the sample regression function can easily be written Algebraic implications of the OLS estimation 108 Recovering from the OLS estimation: 𝜕 σ𝑛𝑖=1 𝑢ො𝑖 2 𝑛 =0 𝑛 2 𝑌𝑖 − 𝛽መ0 − 𝛽መ1 𝑋𝑖 −1 = 0 𝑢ො𝑖 = 0 𝑖=1 𝑖=1 𝜕 𝛽መ0 𝑖=1 𝑖=1 ⟺ ⟺ 𝑛 𝑛 2 𝜕 σ𝑛𝑖=1 𝑢ො𝑖 =0 2 𝑌𝑖 − 𝛽መ0 − 𝛽መ1 𝑋𝑖 −𝑋𝑖 = 0 𝑢ො𝑖 𝑋𝑖 = 0 𝜕𝛽መ1 𝛽መ0 = 𝑌ത − 𝛽መ1 𝑋ത 𝛽መ1 = 𝑛 σ𝑛𝑖=1 𝑌𝑖 𝑋𝑖 − σ𝑛𝑖=1 𝑋𝑖 σ𝑛𝑖=1 𝑌𝑖 𝑛 σ𝑛𝑖=1 𝑋𝑖 2 − σ𝑛𝑖=1 𝑋𝑖 2 Algebraic implications of the OLS estimation 109 Properties of the regression equation: 1. 𝑌 = 𝑌ത 2. 𝑢ො = 0 3. 𝑌ത = 𝛽መ0 + 𝛽መ1 𝑋ത Algebraic implications of the OLS estimation 110 Algebraic implications of the OLS estimation 111 𝑛 4. 5. 𝑛 𝑢ො𝑖 𝑋𝑖 = 𝑢ො𝑖 𝑥𝑖 = 0 𝑖=1 𝑖=1 𝑛 𝑛 𝑢ො𝑖 𝑌𝑖 = 𝑢ො𝑖 𝑦ො𝑖 = 0 𝑖=1 𝑖=1 Assumptions: H1 112 𝑌𝑖 = 𝛼 + 𝛽𝑋𝑖 + 𝑢𝑖 The classical linear regression model: ◼ ◼ ◼ ◼ Establishes a relationship between Y and X through two parameters Y is the explained variable and X is the explanatory variable u is a random, non-observable error term The model is linear in both parameters (it has not to be linear on the variables) and in the error term Assumptions : H2 113 The explanatory variable is deterministic (non-random) ◼ ◼ That is the reason for the null correlation between the explained variable and the error term The values of X are “fixed when selecting the observations that take part in the sample” Assumptions: H3 114 The error term has a population mean of zero 𝐸 𝑢𝑖 |𝑋𝑖 = 0 ◼ ◼ Intuition: positive and negative errors cancel out If the constant term is included in the regression, this assumption is automatically assumed. 𝐸 𝑌𝑖 |𝑋𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 Assumptions: H3 115 The factors that are not explicitly included in the model and, consequently, included in u, do not affect the mean of Y in a systematic manner Assumptions: H4 116 Homoscedasticity: the error term has a constant variance 𝑣𝑎𝑟 𝑢𝑖 |𝑋𝑖 = 𝐸 𝑢𝑖 − 𝐸 𝑢𝑖 |𝑋𝑖 2 = 𝐸 𝑢𝑖 2 |𝑋𝑖 = 𝑣𝑎𝑟 𝑢𝑖 = 𝜎 2 ◼ ◼ Variance is constant across observations in the same sample Implication: the variance of the dependent variable is the same across observations –𝑣𝑎𝑟 𝑌𝑖 |𝑋𝑖 = 𝑣𝑎𝑟 𝑢𝑖 |𝑋𝑖 Assumptions: H4 117 Assumptions: H4 118 ◼ ◼ ◼ Sometimes it is often hard to argue that it is an appropriate assumption Example: the average wage may be the same in both a small firm and a large firm. But would its dispersion be the same? heteroscedasticity is the absence of homoscedasticity Assumptions: H4 119 Assumptions: H5 120 No autocorrelation: Observations of the error term are uncorrelated with each other 𝑐𝑜𝑣 𝑢𝑖 ,𝑢𝑗 |𝑋𝑖 , 𝑋𝑗 = 0 Assumptions: H5 121 Assumptions: H6 122 All independent variables are uncorrelated with the error term 𝑐𝑜𝑣 𝑢𝑖 ,𝑋𝑖 = 0 Assumptions: H7 123 𝑛>2 ◼ Number of observations > number of parameters Assumptions: H8 124 There is enough variability of X ◼ Var (X) is a positive, finite number Assumptions: H9 125 The regression model is “correctly” specified ◼ There is no specification error Assumptions: H10 126 No independent variable is a perfect linear function of other explanatory variables Summarizing… 131 Model: 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 Stochastic Deterministic Variable? Observable? Random? i-th observation of Y 𝑌𝑖 Yes Yes Yes i-th observation of X 𝑋𝑖 Yes Yes No 𝛽0 ,𝛽1 No No --- 𝑢𝑖 Yes No Yes Regression parameters i-th observation error term Summarizing… 132 The model is linear in the parameters, but different functional forms are possible: Linear: 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 Power: 𝑙𝑛𝑌𝑖 = 𝛽0 + 𝛽1 𝑙𝑛𝑋𝑖 + 𝑢𝑖 Exponential: 𝑙𝑛𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 Lin-Log: 𝑌𝑖 = 𝛽0 + 𝛽1 𝑙𝑛𝑋𝑖 + 𝑢𝑖 1 Hyperbolic: 𝑌𝑖 = 𝛽0 + 𝛽1 + 𝑋𝑖 Inverse Exponential: 𝑙𝑛𝑌𝑖 = 1 𝛽0 + 𝛽1 𝑋 𝑖 + 𝑢𝑖 Summarizing… 133 The model: 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 The model is estimated based on a sample of size n: 𝑌1 = 𝛽0 + 𝛽1 𝑋1 + 𝑢1 𝑌2 = 𝛽0 + 𝛽1 𝑋2 + 𝑢2 𝑌3 = 𝛽0 + 𝛽1 𝑋1 + 𝑢3 … 𝑌𝑛 = 𝛽0 + 𝛽1 𝑋𝑛 + 𝑢𝑛 Summarizing… 134 OLS estimation method: 𝑛 min 𝑢ො𝑖 2 0 ,𝛽 1 𝛽 𝑖=1 OLS estimators: 𝛽0 = 𝑌ത − 𝛽መ 𝑋ത 𝛽1 = 𝑛 σ𝑛𝑖=1 𝑌𝑖 𝑋𝑖 − σ𝑛𝑖=1 𝑋𝑖 σ𝑛𝑖=1 𝑌𝑖 𝑛 σ𝑛𝑖=1 𝑋𝑖 2 − σ𝑛𝑖=1 𝑋𝑖 2 𝑐𝑜𝑣 𝑋, 𝑌 = 𝑣𝑎𝑟 𝑋 Summarizing… 135 OLS implications: 𝑛 σ𝑖=1 𝑢 ො𝑖 = 0 𝑛 σ𝑖=1 𝑢 ො 𝑖 𝑋𝑖 = 0 0 + 𝛽መ 𝑋ത ത=𝛽 𝑌 𝑛 σ𝑖=1 𝑢 ො 𝑖 𝑌𝑖 = σ𝑛𝑖=1 𝑢ො 𝑖 𝑦ො𝑖 = 0 𝑌 = 𝑌ത Summarizing… 136 Model assumptions: 0 + 𝛽𝑋𝑖 + 𝑢𝑖 describes the H1: For a given population, 𝑌𝑖 = 𝛽 relationship between Y and X - the model is linear on parameters H2: 𝑋 deterministic H3: 𝐸 𝑢𝑖 |𝑋𝑖 = 𝐸 𝑢𝑖 = 0 H4: Homoscedasticity - 𝑣𝑎𝑟 𝑢𝑖 |𝑋𝑖 = 𝑣𝑎𝑟 𝑢𝑖 = 𝜎 2 (constant, finite, unknown) H5: 𝑐𝑜𝑣 𝑢𝑖 , 𝑢𝑗 |𝑋𝑖 , 𝑋𝑗 = 0 Summarizing… 137 H6: 𝑐𝑜𝑣 𝑢𝑖 , 𝑋𝑖 = 0 H7: number of observations is higher than the number of parameters to be estimated H8: Var (X) is a positive, finite number H9: The model is correctly specified H10: There is no perfect collinearity OLS estimator properties 138 0 and Under H1-H6, the OLS estimators, 𝛽 𝛽1 , are BLUE: ◼ Best = Minimum variance estimators in the class of linear and unbiased estimators – Gauss Markov Theorem 0 and 𝛽1 are linear estimators ◼ Linear = 𝛽 ◼ Unbiased = On average, 𝛽0 and 𝛽1 are equal to the population parameters 0 and 𝛽1 are estimators of the population parameters ◼ Estimator = 𝛽 OLS estimator - Unbiasedness 139 ◼ Under H1-H6, the OLS estimators are: unbiased 𝐸 𝐸 𝛽0 = 𝛽0 𝛽1 = 𝛽1 OLS estimator - variance 140 ◼ Efficiency The OLS estimator is a minimum variance estimator (no other estimator has smaller variance than the OLS estimator) OLS estimator - variance 141 Standard error and variance: σ𝑛𝑖=1 𝑋𝑖 − 𝑋ത 𝑌𝑖 − 𝑌ത 𝑣𝑎𝑟 𝛽1 = 𝑣𝑎𝑟 σ𝑛𝑖=1 𝑋𝑖 − 𝑋ത 2 𝑠𝑒 𝛽1 = σ𝑛𝑖=1 𝜎2 𝑋𝑖 − 𝑋ത = 2 = σ𝑛𝑖=1 𝜎 σ𝑛𝑖=1 𝑋𝑖 − 𝑋ത 2 𝜎2 𝑋𝑖 − 𝑋ത 2 OLS estimator - variance 142 𝜎 2 σ𝑛𝑖=1 𝑋𝑖2 𝑣𝑎𝑟 𝛽0 = 𝑛 σ𝑛𝑖=1 𝑋𝑖2 − 𝑛𝑋ത 2 0 = 𝑠𝑒 𝛽 σ𝑛𝑖=1 𝑋𝑖2 𝜎 2 σ𝑛𝑖=1 𝑋𝑖2 =𝜎 𝑛 σ𝑛𝑖=1 𝑋𝑖2 − 𝑛 𝑋ത 2 𝑛 σ𝑛𝑖=1 𝑋𝑖2 − 𝑛𝑋ത 2 OLS estimator - variance 143 Estimator for the variance of the error term 𝑛 𝐸 𝑢ො𝑖 2 = 𝑛 − 2 𝜎 2 𝑖=1 2 𝑛 σ 𝑢 ො 𝑆𝑆𝑅 𝑖 𝑖=1 𝜎ො 2 = = 𝑛−2 𝑛−2 𝜎ො = σ𝑛𝑖=1 𝑢ො𝑖 2 = 𝑛−2 𝑆𝑆𝑅 𝑛−2 𝜎ො 2 unbiased estimator of 𝜎 2 OLS estimator - variance 144 Notes: Both 𝜎𝛽0 and 𝜎𝛽1 (𝜎ෞ 𝛽0 and 𝜎ෞ 𝛽1 ) depend on s (or s). The higher the s2 (or s2) the higher the error term dispersion around its mean The bigger the sample, the smaller the variances OLS estimator - variance 145 The higher the sum of the squares of X around its mean, the lower the variances of the estimators y y y y x x 0 x 0 x OLS estimator - variance: example 146 Estimation results w = + educação + u wˆ = 234.45+ 0.509 educação (9.546) (0.104) Coefficient of determination (R squared) 150 ◼ Objective: how well the model fits the data (goodness-of-fit) 𝑅2 𝑆𝑆𝐸 𝑆𝑆𝑅 = =1− 𝑆𝑆𝑇 𝑆𝑆𝑇 𝑛 ത σ 𝑖=1 𝑌𝑖 − 𝑌 2 𝑅 = 𝑛 σ𝑖=1 𝑌𝑖 − 𝑌ത 2 2 σ𝑛𝑖=1 𝑢ො 𝑖2 =1− 𝑛 σ𝑖=1 𝑌𝑖 − 𝑌ത 𝑛 2 መ 2 σ𝑛 𝑥 2 𝛽መ 2 𝑆𝑥2 σ 𝑦 ො 𝛽 𝑖=1 𝑖 𝑖=1 𝑖 𝑅2 = 𝑛 = = 2 σ𝑖=1 𝑦𝑖2 σ𝑛𝑖=1 𝑦𝑖2 𝑆𝑦 2 Coefficient of determination (R squared) 151 ◼ ◼ ◼ ◼ The percentage in the total variation in Y that is explained by the model It is always a non-negative number 0 ≤ 𝑅2 ≤ 1 ◼ 1 perfect fit We can only compare the coefficients of determination of any two models whenever the dependent variable is the same and both are estimated based on the same sample Root Mean Square Error (RMSE) 152 ◼ The formula: 𝑅𝑀𝑆𝐸 = 𝑆𝑆𝑅 𝑛−2 Statistical inference of the model: the normality hypothesis 153 Normality hypothesis: 𝑢𝑖 ~𝑁 0, 𝜎 2 ◼ ◼ H3 ◼ H4 Normality hypothesis: why? ◼ 1. theoretical considerations on the meaning of including the perturbation term in the model ◼ 2. pragmatism Statistical inference of the model: the normality hypothesis 154 Key statistical properties: 𝑍−𝜇 ~𝑁 0,1 𝜎 , 𝑤𝑒 ℎ𝑎𝑣𝑒, 𝑍 2~𝒳 2𝑛 2.1. 𝑍~𝑁 𝜇, 𝜎 2 , 𝑠𝑜, 2.2. If 𝑍~𝑁 0,1 2.3. If 𝑍1 ~𝑁 0,1 , 𝑍2~𝑁 0,1 , …, 𝑍𝑟 ~𝑁 0,1 and 𝑍1 , … 𝑍𝑟 are independent random variables, it becomes σ𝑟𝑖=1 𝑍𝑖2~ 𝒳 2𝑟 2.4. If 𝑍~𝑁 0,1 , if 𝑊~𝒳 2𝑟 and if Z and W are independent, we can write 𝑍 ~𝑡 𝑟 𝑊 𝑟 2.5. If 𝑍~𝒳 2𝑟 e 𝑊~𝒳 2𝑠 , and Z and W are independent, we have, 𝑍 𝑟 𝑊 𝑠 ~𝐹 𝑟, 𝑠 Statistical inference of the model: the normality hypothesis 155 Implications: 1. If 𝑢𝑖 ~𝑁 0, 𝜎 2 , we have, 𝑌𝑖 ~𝑁 𝛽0 + 𝛽1 𝑋𝑖 , 𝜎 2 - Y is a linear combinationof a variable that follows a normal distribution 2. The OLS estimators for 𝛽0 and 𝛽1 are linear combinations of Y, so they will too follow a normal distribution 𝛽0 − 𝛽0 𝛽0 ∼ 𝑁 𝛽0 , 𝑣𝑎𝑟 𝛽0 𝑜𝑟 ~𝑁 0,1 𝜎𝛽0 𝛽1 ∼ 𝑁 𝛽1 ,𝑣𝑎𝑟 𝛽1 𝛽1 − 𝛽1 𝑜𝑟 ~𝑁 0,1 𝜎𝛽1 Statistical inference of the model: the normality hypothesis 156 3. 𝑢ෝ𝑖 ~𝑁 0, 𝑣𝑎𝑟(𝑢ො 𝑖 ) , because 𝑢ෝ𝑖 is a linear combination of random variables that follow a normal distribution 4. σ𝑛 ෝ 2𝑖 𝑖=1 𝑢 𝜎2 = 𝑛−2 𝑠2 𝜎2 ~𝒳 2𝑛−2 𝑠 2 = 𝜎ො 2 Inference: sample distribution of the OLS 157 Putting together theses two results: 0 −𝛽0 𝛽 ~𝑁 𝜎𝛽 0 𝛽1 −𝛽1 𝜎𝛽 0,1 ~𝑁 0,1 1 σ𝑛 ෝ2 𝑖=1 𝑢 𝑖 and 𝜎2 and σ𝑛 ෝ2 𝑖=1 𝑢 𝑖 𝜎2 = = we get: 0 −𝛽0 𝛽 ~𝑡(𝑛−2) se(𝛽0 ) 𝛽1 − 𝛽1 ~𝑡(𝑛−2) se( 𝛽1 ) 𝑛−2 𝑠2 2 ~𝒳 𝑛−2 𝜎2 𝑛−2 𝑠2 𝜎2 ~𝒳 2𝑛−2 Inference: Normal versus t-student 158 f(x) normal distribution t-distribution µ x Inference: Hypothesis testing, steps 159 Define the hypothesis under test ◼ ◼ Ho: null hypothesis = it is always related to a specific parameter in the population Example - 𝐻0 : 𝛽𝑗 = 𝑎 H1: alternative hypothesis = can take three forms Bilateral - 𝐻1 : 𝛽𝑗 ≠ 𝑎 One-sided to the left - 𝐻1 : 𝛽𝑗 < 𝑎 One-sided to the right - 𝐻1 : 𝛽𝑗 > 𝑎 Inference: Hypothesis testing, steps 160 ◼ Example: 𝑊 = 𝛽0 + 𝛽1 𝐸𝑑𝑢𝑐 + 𝑢 = 234,45 +0,509𝐸𝑑𝑢𝑐 𝑊 (9,546) 0,104 Hypothesis under test: 𝐻0 : 𝛽1 = 0,5 𝐻1 : 𝛽1 ≠ 0,5 Inference: Hypothesis testing, steps 161 Define an estimator for the parameter of interest Significance level: specify a decision rule. The level of significance (α) tells us whether or not we should reject the null hypothesis, given a certain value of the test statistic. = 1% = 5% = 10% Inference: Hypothesis testing, steps 162 Note on the significance – error types True situation Test result Ho is true Ho is false Reject Ho 𝐸𝑟𝑟𝑜𝑟 𝑇𝑦𝑝𝑒 𝐼 = 𝛼 √ Do not reject Ho √ 𝐸𝑟𝑟𝑜𝑟 𝑇𝑦𝑝𝑒 𝐼𝐼 = 𝛽 Inference: Hypothesis testing, steps 163 Compute the test statistic, under H0 Identify the critical value of the test statistic based on the significance level (α) and probability distribution of the test statistic Compare the test statistic value with the critical value and decide whether or not to reject the null hypothesis Inference: Hypothesis testing: individual parameters 164 Consider the following example: 𝑌𝑖 = 𝛽0 + 𝛽1 𝑋𝑖 + 𝑢𝑖 estimated with a sample of 98 observations: 𝑌 = 2 + (1,211) 0,05𝑋𝑖 0,001 (note: estimated standard-errors are reported in parenthesis) Inference: Hypothesis testing: individual parameters 165 Bilateral test ▪ Goal: test if the coefficient 𝛽1 is statistically differentfrom 𝑎. For example, 𝑎 = 0,04. ▪ Hypothesis under test 𝐻0 : 𝛽1 = 𝑎 𝐻1 : 𝛽1 ≠ 𝑎 In our example: 𝐻0 : 𝛽1 = 0,04 𝐻1 : 𝛽1 ≠ 0,04 Inference: Hypothesis testing: individual parameters 166 ▪ Test statistic, under H0 𝛽1 − 𝛽1 ~𝑡(𝑛−2) se( 𝛽1 ) 𝛽1 − 𝛽1 0,05 − 0,04 = = 10~𝑡(98−2) 0,001 se(𝛽1 ) ▪ Level of significance 𝛼 = 5% Inference: Hypothesis testing: individual parameters 167 ▪ Critical values Value for the 𝑡 statistic with 96 (= 98 − 2) degrees of freedom 𝑡𝑐 = 1,96 (1 - ) /2 -c 0 /2 c Inference: Hypothesis testing: individual parameters 168 (… ) Inference: Hypothesis testing: individual parameters 169 ▪ Compare the test statistic value with the critical value and decide whether or not to reject the null hypothesis fail to reject reject (1 - ) /2 -c = −1,96 0 ▪ Decision: reject 𝐻0 10 > 𝑇𝑐 = 1,96 reject /2 c = 1,96 Inference: Hypothesis testing: individual parameters 170 Unilateral test ▪ Goal: test if the coefficient 𝛽1 is statistically larger than 𝑎. For example, 𝑎 = 0,04. ▪ Define the hypothesis of the test 𝐻0 : 𝛽1 = 𝑎 𝐻1 : 𝛽1 > 𝑎 In our example: 𝐻0 : 𝛽1 = 0,04 𝐻1 : 𝛽1 > 0,04 Inference: Hypothesis testing: individual parameters 171 ▪ Test statistic, under H0 𝛽መ − 𝛽 ~𝑡(𝑛−2) se(β) 𝛽መ − 𝛽 0,05 − 0,04 = = 10~𝑡(98−2) 0,001 se(β) ▪ Significance level 𝛼 = 5% Inference: Hypothesis testing: individual parameters 172 ▪ Critical values Value for the t statistic with 96 (= 98 − 2) degrees of freedom t𝑐 = 1,65 (1 - ) 0 c Inference: Hypothesis testing: individual parameters 173 (… ) Inference: Hypothesis testing: individual parameters 174 ▪ Compare the test statistic value with the critical value and decide whether or not to reject the null hypothesis Fail to reject (1 - ) 0 ▪ Decision: reject 𝐻0 10 > 𝑡𝑐 = 1,65 reject c = 1,65 Inference: Individual significance test 175 1. Hypothesis 𝐻0 : 𝛽𝑗 = 0 𝐻1 : 𝛽𝑗 ≠ 0 2. Significance level: 𝛼 3. Test statistic 𝛽𝑗 ~𝑇 𝑛−2 𝑠𝑒 𝛽𝑗 4. Critical values 5. Decision Inference: Individual significance test, example 176 From the previous example: 𝑌 = 2 + (1,211) 0,05𝑋𝑖 0,001 (note: estimated standard-errors in parenthesis) Inference: Individual significance test, discussion 177 ▪ How is the decision interpreted? ▪ If we reject the null hypothesis, we typically say that the variable 𝑋 is statistically significant for a significance level of 𝛼 ▪ If we do not reject the null hypothesis, we typically say that the variable 𝑋 is not statistically significant for a significance level of 𝛼 Inference: statistical vs. Economic significance 178 ▪ Statistical significance is determined by the t-test statistic, while economic significance has to do with the magnitude and sign of the estimate. ▪ Check statistical significance: ▪ If the variable is significant, then the magnitude of the coefficient should be discussed to get an idea of the economic importance of the variable. Inference: statistical vs. Economic significance 179 ▪ If it is not statistically significant for the usual levels of significance (1%, 5% and 10%), it should be checked whether the coefficient has the expected sign and whether the effect is large enough. If the effect is large, we should calculate the pvalue for the t-statistic ▪ “Wrong” signal (i.e. different from expected), it may be because we omitted a relevant variable Inference: statistical significance, note 180 A statistically significant result may be of no practical significance. Example: canned beans Inference: p-value 181 p-value: ◼ ◼ Exact significance level The minimum level of significance that allows for the rejection of Ho Example: ◼ ◼ Test statistic = 1.47 (𝑡62) p-value = 0.12 ◼ ◼ ◼ Reject at α = 5%? – No Reject at α = 10%? – No Reject at α = 20%? – Yes Confidence interval 182 ◼ From 0 −𝛽0 𝛽 ~𝑡(𝑛−2) 0 ) se( 𝛽 and 1 − 𝛽1 𝛽 ~𝑡(𝑛−2) se(𝛽 ) 1 We can build conficente intervals (CI) for 𝛽0 and 𝛽1 The confidence interval at 100 1 − 𝛼 % for 𝛼 is defined as ±𝑡 ) 𝛽 se( 𝛽 0 𝑛−2 0 𝛼/2 while the confidence interval at 100 1 − 𝛼 % for 𝛽 is defined as ±𝑡 ) 𝛽 se( 𝛽 1 𝑛−2 1 𝛼/2 Confidence interval 183 ◼ Notas: ◼ ◼ ◼ The Confidence Interval (CI) is built to the true value of the parameter It is always centered on the estimate for the parameter If the CI at 95% for 𝛽𝑗 : 0,57; 1,03 we cannot say that the probability of 𝛽𝑗 be larger than 0,57 and less than 1,03 is 95%. ◼ If we calculate the confidence interval for n samples, the probability of the interval being such that the true value is inside it is 95%