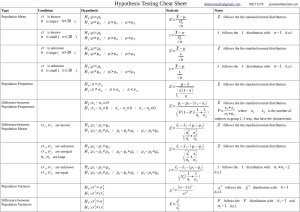
Facilitator: Chuah Soo Cheng (PhD) DAT E : 1 9 JUN E 2 0 2 1 T I ME: 9 3 0 AM TO 1 2 3 0PM Theory Research Model Develop Hypothesis Collect & Analysis Data Accept/Reject Hypothesis Data Screening Blank Responses Straight Lining Data Entry Errors ◦Detect using SPSS Data Transformation Compute Recode •Recoding Continuous Data •Combining Categories •Reverse Coding Descriptive analysis Numerical methods Graphic methods Reliability scale : Cronbach Alpha Choosing the right statistic Descriptive Analysis Categorical Variables Continuous Variables Missing Data ◦ Exclude cases listwise ◦ Exclude cases pairwise ◦ Replace with mean Normality Skewness and Kurtosis Tests of Normality ◦ Kolmogorov-Smirnov ◦ Shapiro-Wilk ◦ A non-significant result (p > 0.05) normal-normality ◦ A complication that can arise here occurs when the results of the two tests don’t agree – that is, when one test shows a significant result and the other doesn’t. In this situation, use the Shapiro-Wilk result – in most circumstances, it is more reliable. Histogram Normal Q-Q Plot Boxplot Graphical Methods Histogram ◦ Shape of the histrogram distribution of data (normally distributed, skewed to the left or right) Bar graph Line graph Scatterplot ◦ Correlation between two variables Boxplot ◦ Distribution of data ◦ Outliers Reliability Scale: Cronbach Alpha Source: Hair, Josept F :, Celsi, mary;Money, Arthur; Samouel, Philip; and Page, Michael, "The Essentials of Business Research Method, 3rd Edition " (2016). Choosing the Right Statistic Type of question ◦ The researcher should consider the technique that he would be using before choosing the research design and that will also influence the type of data that needs to be collected. Number of variables ◦ Univariate (one variable) ◦ Bivariate (2 variables) ◦ Multivariate (> 2 variables) Scale of measurement Nominal, ordinal, interval, ratio scale data Parametric vs Non-parametric hypothesis test ◦ Parametric - interval and ratio scale measurement ◦ Assumptions to follow: ◦ The observations must be independent ◦ The observation must be drawn from normally distributed populations ◦ The population should have equal variances ◦ The measurement scales should be at least interval. ◦ Non-parametric – nominal and ordinal scale measurement Compare Groups Independent-Samples t-Test Independent-Samples t-Test The t test for independent samples is used to determine whether the means of two groups are significantly different. It is called a t test for independent samples because you use it when you are comparing two groups that are composed of different people (i.e., groups that are independent of each other). Examples of research questions that would use an independent t test: ◦ Do men and women have different average amounts of self-esteem? ◦ Does the number of physical symptoms differ among groups of heart disease patients receiving medication versus receiving a placebo? Independent-Samples t-Test “Levene’s T test for Equality of Variances” ◦ The purpose of this t test is to determine whether the variances between the two groups are significantly different from each other. This is important because one of the assumptions of a standard independent test is that the 2 groups have equal variance. ◦ The null hypothesis for Levene’s t test is that the variances are equal, so: ◦ If the p-value (the number listed in the “Sig.” column) is greater than .05, you can assume your variances are indeed equal. ◦ If the p-value is less than .05 for this t test, this suggests that the variances are not equal and that the data violates the assumption. ◦ If the p-value (Sig.) for Levene’s T test was greater than .05 -> USE THE TOP LINE (equal variances assumed) ◦ if the p-value (Sig.) for Levene’s T test was less than .05 -> USE THE BOTTOM LINE (equal variances not assumed). If the p-value is less than .05, we reject the null hypothesis and conclude that there is a significant difference between the groups. If the p-value is greater than .05, we fail to reject the null hypothesis and conclude that there is not significant difference between the groups. 𝐻𝑜: 𝜇1 = 𝜇2 𝐻1: 𝜇1 ≠ 𝜇2 Independent-Samples t-Test – Effect size COHEN’S D 𝐶𝑜ℎ𝑒𝑛′ 𝑠 𝑑= EFFECT SIZE ETA SQUARED 𝑥1 −𝑥2 𝑠𝑝2 Guidelines ◦ d = 0.2, small effect ◦ d = 0.5, medium effect ◦ d = 0.8, large effect 𝐸𝑡𝑎 𝑠𝑞𝑢𝑎𝑟𝑒𝑑 = 𝑡2 𝑡 2 +(𝑁1+𝑁2 −2) Guidelines ◦ d = 0.01, small effect ◦ d = 0.06, medium effect ◦ d = 0.14, large effect https://www.socscistatistics.com/effectsize/default3.aspx http //web.uccs. edu/lbecker/psy590/escalc3.htm Cohen, J. (1988), Statistical Power Analysis for the Behavioral Sciences, 2nd Edition. Hillsdale: Lawrence Erlbaum. One-Way Analysis of Variance (ANOVA) Non-Parametric: Chi-Square Test of Independence Two categorical variables with two or more categories Contingency/ Crosstabulation Table Gender & Smoker Effect size ◦ Phi coefficient ◦ Cramer’s V ◦ For R-1 or C-1 equal to 1 (two categories) small = 0.01, medium = 0.30, large = 0.50 ◦ For R-1 or C-1 equal to 2 (three categories) small = 0.07, medium = 0.21, large = 0.35 ◦ For R-1 or C-1 equal to 3 (four categories) small = 0.06, medium = 0.17, large = 0.29 Explore Relationship Among Variables Correlation Describe the strength and direction of the linear relationship between two variables. Pearson correlations Spearman rank order correlation Negative/ positive correlation Strength of the relationship (Cohen, 1988, p. 79-81) Presenting correlation results P Multiple Regression used to analysed the relationship between a single dependent (continuous) and several independent variables (continuous or nominal) ◦ How well a set of variables in predicting a particular outcome ◦ Which variable in a set of variables is the best predictor of an outcome ◦ Whether a particular predictor variable is still able to predict an outcome when the effects of another variable are controlled for Assumptions of Multiple Regression Sample size Multicollinearity Outliers Assumptions of Multiple Regression Sample size ◦ “for social science research, about 15 subjects per predictor are needed for a reliable equation” (Stevens (1996, p.72). ◦ N > 50 + 8M (m = number of independent variables) (Tabachnick & Fidell, 2007, p.123). ◦ IVs = 5, N > 50 + 8(5) = 90 Multicollinearity ◦ ◦ ◦ ◦ ◦ The relationship between the independent variables Multicolinearity exists if the independent variables are highly correlated . Multicollinearity is a problem because it undermines the statistical significance of an independent variable. Multicollinearity does not affect the model's predictive accuracy Correlation / VIF Correlation < 0.8, VIF 5 no multicollinearity problem Outliers Normal Probability Plot (P-P) Normality, linearity, homoscediticity and independence of residuals ◦ The residuals should be normally distributed about the predicted DV. ◦ The residuals should have a straight-line relationship with predicted DV. ◦ The variance of the residuals about predicted DV scores should be the same for all predicted scores Multiple Regression (Interpretation) R2 how much of the variance in the dependent variable is explained by the model (IVs) F-test The F-ratio in the ANOVA table tests whether the overall regression model is a good fit for the data. Coefficients ◦ Unstandardized beta represents the amount of change in a dependent variable Y due to a change of 1 unit of independent variable X. ◦ less useful for direct comparison when the measurement scales of the independent variables are different. ◦ Standardized beta means IVs be in terms of standard deviations and so easily compared with each other. ◦ Compare the strength of the effect of each individual variable to the dependent variable p-value < 0.5 the variable is significantly contributing to the prediction of the dependent variable