Data Representation: User-Defined Types, Files, Floating-Point
advertisement

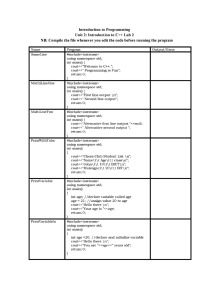
13 Data representation
By NNM
13.1 User-defined data types
A data type based on an existing data type or other data types that have
been defined by a programmer.
(A) Non-composite data types
i. Enumerated data type
ii. Pointer data type
(B) Composite data types
i. Record
ii. Sets
iii. Classes
13.1 Activity
13.2 File organisation and access
File organization
Computers are used to access vast amounts of data and to present it as useful information.
Data of all types is stored as records in files. These files can be organized using different
methods.
• Serial file organization
• Sequential file organization
• Random file organization
File access
File access is the method used to physically find a record in the file.There are different
methods of file access.We will consider two of them:
• Sequential access
• Direct access
Hashing algorithms
13.2 Activity
13.3 Floating-point numbers, representation
and manipulation
Floating-point number representation
• Converting binary floating-point numbers into denary
• Converting denary numbers into binary floating-point numbers
• Potential rounding errors and approximations
• Precision versus range
• Floating-point problems
• A non-composite data type can be defined without referencing
another data type
• Non-composite user-defined data types are usually used for a special
purpose.
• An enumerated data type is non-composite data type and is defined by a given
list of all possible values that has an implied order.
• contains no references to other data types when it is defined.
• TYPE identifier (value1, value2,…)
eg: TYPE Tmonth (January, February,….,December)
• Note: January, February,.. are not string, no need to put in quotation marks
• Then variable can be defined as
DECLARE thismonth,nextmonth: Tmonth
thismonthNovember
nextmonththismonth+1 //nextmonth will be December
Activity
ACTIVITY 13A
Using pseudocode,
• declare an enumerated data type for the days of the week.
• Then declare two variables today and yesterday,
• assign a value of Wednesday to today, and
• write a suitable assignment statement for tomorrow.
Check Answer
ACTIVITY 13B
• Using pseudocode for the enumerated data type for days of the week,
• declare a suitable pointer to use.
• Set your pointer to point at today.
• Remember, you will need to set up the pointer data type and the
pointer variable.
Check Answer
• A pointer data type is a non-composite data type that uses the memory
address of where the data is stored.
• It is used to reference a memory location.
• This data type needs to have information about the type of data that will be
stored in the memory location.
• ^ shows that the type being declared is a pointer
TYPE pointer = ^ Typename
eg: TYPE Tmonthptr=^Tmonth
• Then variable can be defined as
DECLARE mptr: Tmonthptr
mptr^thismonth
currentmonthmptr^
Activity
• A data type that refers to any other data type in its type definition is a
composite data type.
Record
Type Typename
DECLARE identifier: datatype
DECLARE identifier: datatype
.
.
DECLARE identifier: datatype
ENDTYPE
• Type Tstudent
DECLARE id: INTEGER
DECLARE name: STRING
DECLARE score: REAL
ENDTYPE
Python does not
natively support
record types.
However, you can
represent a record by
defining a class with
attributes but no
methods. The
constructor method
__init__ will be called
automatically when a
new instance of the
PlayerRecord class is
created.
{'apple'}
{'apple'}
Sets
• A set is a given list of unordered elements that can
use set theory operations such as intersection and
union.
• A set data type includes the type of data in the set.
• TYPE set_identifier=SET OF (basic data type)
• DEFINE identifier (value1,value2, …):setidentifier
eg : TYPE Sletter=SET OF (CHAR)
DEFINE vowel(‘a’, ’e’, ’i’, ’o’, ’u’):Sletter
x = {"apple", "melon", "strawberry"}
y = {"google", "microsoft", "apple"}
z = x.intersection(y)
u = x.union(y)
print(z)// {"apple"}
print(u)//{"apple", "melon",
"google", "microsoft", "strawberry"}
Classes
• A class is a composite data type that includes variables of given data
types and methods.
• An object is defined from a given class; several objects can be
defined from the same class.
• To be continued in Chapter 20
ACTIVITY 13C
1. Explain, using examples, the difference between composite and noncomposite data types.
2. Explain why programmers need to define user-defined data types.
Use examples to illustrate your answers.
3. Choose an appropriate data type for the following situations. Give the
reason for your choice in each case.
a) A fixed number of colours to choose from.
b) Data about each house that an estate agent has for sale.
c) The addresses of integer data held in main memory.
Check Answer
13A Answer Key
TYPE Tday = (Monday, Tuesday, Wednesday, Thursday, Friday, Saturday,
Sunday)
DECLARE today : Tday
DECLARE yesterday : Tday
today Wednesday
yesterday today - 1
13B Answer Key
TYPE TdayPointer = ^Tday
DECLARE dayPointer : TdayPointer
dayPointer ^today
13C Answer Key
1. A composite data type refers to other data types in its definition. A noncomposite data type does not refer to other data types.
2. User defined data types allow programs to be more readable for other
programmers. For example, using the days of the week as an
enumerated data type.
3. (a) An enumerated data type, as a list of colours can be provided with
meaningful names used for each colour in the list.
(b) A record structure that contains different types of data would be
used, so the data for each house can be used together in one
structure.
(c)pointer data type as this will reference the address/location of the
integer stored in main memory.
• The serial file organization method physically stores records of data in a
file, one after another, in the order they were added to the file.
• New records are appended to the end of the file.
• It is often used for temporary files storing transactions to be made to
more permanent files
• For example, storing customer meter readings for gas or electricity
before they are used to send the bills to all customers.
Customer
Customer
Customer
Customer
Customer
Customer
and so on
6
5
3
1
4
2
• The sequential file organization method physically stores records of data
in a file, one after another, in a given order.
• The order is usually based on the key field of the records as this is a
unique identifier.
• For example, a file could be used by a supplier to store customer records
for gas or electricity in order to send regular bills to each customer. All
records are stored in ascending customer number order, where the
customer number is the key field that uniquely identifies each record.
Customer
Customer
Customer
Customer
Customer
Customer
1
2
3
4
5
6
and so on
• The random file organization method physically stores records of data in
a file in any available position.
• The location of any record in the file is found by using a hashing
algorithm on the key field of a record
Customer
Customer
Customer
Customer
Customer
Customer
and so on
5
3
1
2
6
4
sequential access
A method of file access in which records are searched one after another from
the physical start of the file until the required record is found.
This method is used for serial and sequential files.
For a serial file, if a particular record is being searched for, every record needs to be checked until that record is found or the whole file has
been searched and that record has not been found.
For a sequential file, if a particular record is being searched for, every record needs to be checked until the record is found or the key field of
the current record being checked is greater than the key field of the record being searched for.
direct access
The direct access method can physically find a record in a file without other
records being physically read. Both sequential and random files can use direct
access. This allows specific records to be found more quickly than using
sequential access.
For a sequential file, an index of all the key fields is kept and used to look up the address of the file location where a given record is stored.
For large files, searching the index takes less time than searching the whole file.
For a random access file, a hashing algorithm is used on the key field to calculate the address of the file location where a given record is
stored
• Hashing algorithm is a mathematical formula used to perform a calculation on the key field of
the record; the result of the calculation gives the address where the record should be found.
• a simple hashing algorithm:
• If a file has space for 2000 records.
• key field can take any values between 1 and 9999
• Find key MOD 2000
• Start address+ mod * the size of the space allocated to each record.
• Eg where the start address is 0 and each record is stored in 2 location.
• key field value =3024, the hashing algorithm would give address
2048 (0+2 x 1024)
• Unfortunately, storing another record with a key field would result in trying to use the same file
location and a collision would occur.
• There are two ways of dealing with this:
1. An open hash where the record is stored in the next free space.
2. A closed hash where an overflow area is set up and the record is stored in the next free
space in the overflow area.
Extension
Activity
Activity
ACTIVITY 13D
• A file of records is stored at address 500.
• Each record takes up five locations and there is space for 1000 records.
• The key field for each record can take the value 1 to 9999.
• The hashing algorithm used to calculate the address of each record is the
remainder when the value of key field is divided by 1000 together with the
start address of the file and the size of the space allocated to each record.
• Calculate the address to store the record with key field 9354.
• If this location has already been used to store a record and an open hash is
used, what is the address of the next location to be checked?
Check Answer
EXTENSION ACTIVITY 13B
Write a program to
• find the ASCII value for each character in a name of up to 10
characters
• add the values together
• divide by 1000 and find the remainder
• multiply this value by 20 and add it to 2000
• display the result.
If this program simulates a hashing algorithm for a file, what is the start
address of the file and the size of each record?
Check Answer
ACTIVITY 13E
1. Explain, using examples, the difference between serial and sequential
files.
2. Explain the process of direct access to a record in a file using a hashing
algorithm.
3. Choose an appropriate file type for the following situations. Give the
reason for your choice in each case.
a) Borrowing books from a library.
b) Providing an annual tax statement for employees at the end of the
year.
c) Recording daily rainfall readings at a remote weather station to be
collected every month.
Check Answer
Activity 13D Answer
• As 9354 / 1000 is 9 remainder is 354,
• with 5 locations for each record,
• this record would be stored at address 2175 = 500 + 353 x 5 and the
next four locations, assuming that the first record is stored at address
500.
• If this location has already been used, the record is stored in the next
free space for open hash.
Activity 13E Answer
1. Serial file each new record is added to the end of a file, for example a log
of temperature readings taken at a weather station. Sequential file
records are stored in a given order, usually based on the key field, for
example ascending number of employee number for a personnel file.
Check
2.
Answer
3. a) Random access as only one record is required at a time, low hit rate.
b) Sequential access as all the records need to be accessed, high hit
rate.
c) Serial access, as each record is added to the end of the file in
chronological order.
• Using scientific notation system in binary, we get:
• M × 2E
• M is the mantissa and E is the exponent. This is known as binary
floating-point representation.
• 0.31211 × 10 24 means:
• the binary floating-point equivalent
Convert this binary floating-point number into denary.
More Examples
Convert this binary floating-point number into denary.
Answer
Answer
ACTIVITY 13F
• Convert these binary floating-point numbers into denary numbers
(the mantissa is 8 bits and the exponent is 8 bits in all cases).
Activity 13F Answer
• a) 39/64 × 25 = 19.5
• b) 41/128 × 27 = 41
• c) 7/8 × 2−5 = 7/256 (0.02734375)
• d) 15/64 × 2−4 = 15/1024 (0.0146484375)
• e) 7/8 × 23 = 7
• f) −13/16 × 22 = −3.25
• g) −3/32 × 24 = −1.5
• h) −5/8 × 25 = −20
• i) −5/8 × 2−3 = −5/64 (−0.078125)
• j) −1/4 × 2−6 = −1/256 (−0.00390625)