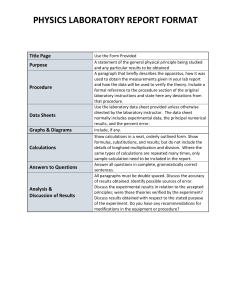
ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 Reliability Engineering 101: Definition, Goals, Techniques How do you evaluate the quality of the products you buy? Traditional quality control in a factory will consist of performing predefined checks and tests. If the product satisfies set requirements, it is deemed good to go. However, you will never say that you bought a quality product if you had to go through the reclamation process two or more times before the warranty period expired. Reliability and reliability engineering help us quantify product quality by adding the dimension of time to the quality equation. In other words, we no longer just want to know if a product can perform its intended function at the moment of purchase. Instead, we want to make sure that the product works without major malfunctions under normal conditions for as long as possible. Reliability engineering does not only help organizations produce more reliable products, but it also informs maintenance teams on how to maintain them to increase MTBF (mean time between failures) and asset lifespan. If you’re interested in learning more, in continuation of this article, we will talk about: • • • • the concept of reliability core principles of reliability engineering the basics of reliability assessment and ways in which reliability engineers can improve equipment reliability What is reliability? Reliability is a term used to describe the ability of a component or system to meet certain performance standards over a certain period of time, assuming normal operating conditions. To put it in another perspective, if we have two systems that operate under the same conditions, the one that works longer with less major hiccups is the more reliable one. Since no one can predict the future and guarantee that a product won’t fail for exactly X hours of use, calculating reliability (see page 8)comes with a dose of uncertainty that is expressed in the form of probability. Among other things, we can use reliability calculation to estimate what is the chance that a system will work properly after x hours or days of use. Naturally, the reliability of any system will be high in the beginning and decline over time. Reliability is often confused with durability, quality, and availability. While the concepts are similar, they should not be used interchangeably. Here’s a short explanation for each. 1|Page ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 Reliability vs durability Durability can be defined as the ability of a physical product to remain functional, without requiring excessive maintenance or repair, when faced with the challenges of normal operation over its design lifetime (definition stolen from Tim Cooper). The main difference between reliability and durability is that durability is mostly concerned with how long a product can last despite the breakdowns it survives, while reliability is trying to reduce the overall number and frequency of those breakdowns. Moreover, the durability component is used to describe a characteristic of physical items, while reliability can be used for virtual systems too. Depending on the product and its field of application, durability can be expressed in hours of use, the number of operational cycles, or years of existence. Reliability vs quality Quality is a concept that is hard to define. One popular way to describe it is by looking at the factors that affect product quality. This leads us to the concept of eight dimensions of quality. This is actually an easy way to differentiate between reliability and quality as we can just consider reliability (and durability if you look closer) to be one dimension of quality. If we take reliability as a standalone concept, another way to look at their relationship is by saying that a reliable system is one that keeps his quality over time. 2|Page ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 Reliability vs availability Availability shows the percentage of time that a system is available (fully operational) to perform what it is designed to do. The concept is very often used in IT to describe the availability of cloud infrastructure. Systems with the highest availability are in the 99.99% range (which means that a service/system is not available for only ~52 minutes out of the whole year; often just to perform scheduled maintenance). Availability is impacted by reliability and maintainability. More reliable systems will experience fewer failures which will improve their availability. Similarly, the faster you perform scheduled maintenance, the less downtime you will have, which again leads to increased availability. What is reliability engineering? Reliability engineering refers to the systematic application of best engineering practices and techniques to make more reliable products in a cost-effective manner. Reliability engineering methodology can be applied across the product lifecycle: from design and manufacturing to operation and maintenance. That being said, the main value of reliability engineering lies in the early detection of possible reliability issues. If we catch a reliability issue at an early stage of the product lifecycle like the design stage, we can greatly minimize future costs (i.e. by eliminating the need for a significant product redesign after it is already in the market). This idea is represented in the graph below. Image source The goals of reliability engineering are as follows: 3|Page ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 1. To use engineering knowledge and techniques to prevent certain failure modes and to reduce the likelihood and frequency of failures. 2. To identify and correct the causes of failures that do occur, despite the efforts to prevent them. 3. To determine ways of dealing with failures that do occur, if their causes have not been corrected. 4. To apply methods for estimating the likely reliability of new designs and for analyzing reliability data. If you look at the list more closely, you will see that the goals are ordered in a way that follows the natural progress of the application of different reliability methods. There is no sense in trying to add redundancies for all identified failures if some of them can be prevented with simple design changes. In other words, the above list represents steps that should be followed in sequential order to ensure reliability practices are applied costeffectively. The basics of reliability assessment The end goal of reliability assessment is to have a robust set of qualitative and quantitative evidence that the use of our component/system will not come with an unacceptable level of risk. It is an integral part of reliability engineering. In this context, risk can be defined as the combination of probability of failure (how likely it is that failure will happen) and failure severity (what is the fallout of the failure; can include safety risk, potential secondary damage, cost of spare parts and labor, production losses, etc.). Understanding failure mechanisms and failure modes It is not always easy to draw the line between cause and failure. If that wasn’t the case, there would be little need for reliability engineers and failure analysis. To understand failure modes and failure mechanisms well enough to address them efficiently, complex systems need to be “broken down” into components. This way you can analyze them on an individual level, as well as based on how they interact with one another. In addition to everything said, the way the system interacts with its user and the environment is another element to add to the list of things that need to be considered as both misuse and poor working conditions can reduce product reliability. 4|Page ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 Common tasks and techniques used in reliability engineering Depending on how complex the system is and the type of the system we are looking at, there are a variety of techniques and tasks that can be applied as a part of our reliability engineering efforts: • • • • • • • • • • • • • • • Root cause analysis (RCA) Reliability centered maintenance (RCM) FMEA and FMECA Design FMEA and Process FMEA Physics of failure (PoF) Built-in self-test Reliability block analysis Field data analysis Fault tree analysis Eliminating single point of failure (SPOF) Human error analysis Operational hazard analysis Looking at maintenance history to analyze failure rates and collect failure data All kinds of data collection tests that measure how system/component perform under stress … By using all of these measures, we can find weak points of our system and see what are the chances that these weaknesses might result in malfunctions. If the perceived risk is high enough, we have to deal with them through corrective action. Common solutions come in the form of design changes (e.g. adding redundancy), detection control, maintenance guidelines, and user training. Quantifying reliability As we mentioned in the intro of this article, reliability is often the game of chances (probability). Since you are dealing with percentages and statistical data to define risk, it is very important that the whole team is on the same page and agrees about the acceptable levels of risk that they are trying to achieve. This is why it is very important to use a precise language when describing problems and proposing solutions. Moreover, because of incomplete statistical data and other uncertainties, some reliability professionals recommend focusing on solutions rather than failure chances. 5|Page ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 ″ For part/system failures, reliability engineers should concentrate more on the “why and how”, rather than predicting “when”. Understanding “why” a failure has occurred (e.g. due to over-stressed components or manufacturing issues) is far more likely to lead to improvement in the designs and processes used than quantifying “when” a failure is likely to occur (e.g. via determining MTBF). To do this, first the reliability hazards relating to the part/system need to be classified and ordered (based on some form of qualitative and quantitative logic if possible) to allow for more efficient assessment and eventual improvement. “ O’Connor, Patrick D. T. (2002), Practical Reliability Engineering How can reliability engineers improve equipment reliability at their facility? There are several ways in which reliability engineers can help to improve and optimize maintenance processes at their facility that will ultimately result in increased equipment reliability. We discuss a few of them below. Helping with the design and development of spare parts Wear and tear that comes with daily use doesn’t discriminate. Most assets will need to be fitted with spare parts on a regular basis to continue operating in an efficient manner. Companies that have the right resources might opt-in to use CNC machines or 3-D printing to create their own parts instead of constantly restocking their spare parts inventory. Furthermore, they might have an old machine with spare parts that are no longer sold or have to deal with a nasty breakdown that requires a custom part. In these scenarios, reliability engineers can work closely with the maintenance team to design, test, and produce quality replacement parts that will improve the reliability of onsite assets. Performing root cause analysis One thing reliability engineers should be very good at is identifying and understanding failure causes. Because of that, they can be tasked with performing root cause analysis (RCA). They can examine OEM manuals, maintenance practices, equipment maintenance logs, and other documentation to find the reasons why specific machines are failing and suggest how to eliminate and/or mitigate each of the found failure causes. One way to address potential causes is by applying RCM practices. 6|Page ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 Making sure maintenance actions address the right failure modes This is an extension of the previous point. Since the last point was concentrated on finding what you are not doing (which failure modes you are not addressing), let’s focus here on what you might be doing wrong. Most companies will find themselves in a situation where they are performing regular maintenance on an asset and that asset is still experiencing breakdowns. While there can be many reasons for that, one of them is that maintenance technicians are doing something wrong – like not addressing the right failure modes. This is where referring to RCA analysis can be very helpful. Similarly, reliability engineers can occasionally check how different maintenance practices are executed and how they can be improved. They can check if the maintenance team is using outdated practices and doing preventive maintenance tasks that add value and address the right problems. All of these should be easily accessible in a good CMMS system. To learn more about CMMS you can check out our guide What is a CMMS and how does it work. Last but not least, reliability engineers can also help with choosing the right condition monitoring sensors and equipment for the implementation of advanced maintenance strategies like Condition-based maintenance and Predictive maintenance. Final thoughts Serious reliability engineering efforts bring serious results. With the right knowledge, reliability techniques can be implemented regardless of the size of your company. Going forward, we hope that organizations will continue to invest in reliability as it helps everyone involved. Production companies benefit from producing better quality products, maintenance teams have less trouble maintaining them, and users have fewer performance issues over the lifespan of their product. It’s a win-win-win situation. Are you a reliability engineer or a maintenance professional and think we missed an important point? Share your thoughts in the comments below. 7|Page ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 System Reliability & Availability Calculations A business imperative for companies of all sizes, cloud computing allows organizations to consume IT services on a usage-based subscription model. To evaluate the dependability of a system, the promise of cloud computing depends on two viral metrics: • • Service reliability Service vailability Vendors offer service level agreements (SLAs) to meet specific standards of reliability and availability. An SLA breach not only incurs cost penalty to the vendor but also compromises end-user experience of apps and solutions running on the cloud network. Though reliability and availability are often used interchangeably, they are different concepts in the engineering domain. Let’s explore the distinction between reliability and availability, then move into how both are calculated. What is reliability? Reliability is the probability that a system performs correctly during a specific time duration. During this correct operation: o No repair is required or performed o The system adequately follows the defined performance specifications Reliability follows an exponential failure law, which means that it reduces as the time duration considered for reliability calculations elapses. In other words, reliability of a system 8|Page ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 will be high at its initial state of operation and gradually reduce to its lowest magnitude over time. What is availability? Availability refers to the probability that a system performs correctly at a specific time instance (not duration). Interruptions may occur before or after the time instance for which the system’s availability is calculated. The service must: o Be operational o Adequately satisfy the defined specifications at the time of its usage Availability is measured at its steady state, accounting for potential downtime incidents that can (and will) render a service unavailable during its projected usage duration. For example, a 99.999% (Five-9’s) availability refers to 5 minutes and 15 seconds of downtime per year. (Learn more about availability metrics and the 9s of availability.) Incident & service metrics Before discussing how reliability and availability are calculated, let’s understand the incident service metrics used in these calculations. These metrics are computed through extensive experimentation, experience, or industrial standards; they are not observed directly. Therefore, the resulting calculations only provide relatively accurate understanding of system reliability and availability. The graphic, below, and following sections outline the most relevant incident and service metrics: 9|Page ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 Failure rate The frequency of component failure per unit time. It is usually denoted by the Greek letter λ (Lambda) and is used to calculate the metrics specified later in this post. In reliability engineering calculations, failure rate is considered as forecasted failure intensity given that the component is fully operational in its initial condition. The formula is given for repairable and non-repairable systems respectively as follows: Repair rate The frequency of successful repair operations performed on a failed component per unit time. It is usually denoted by the Greek letter μ (Mu) and is used to calculate the metrics specified later in this post. Repair rate is defined mathematically as follows: Mean time to failure (MTTF) The average time duration before a non-repairable system component fails. The following formula calculates MTTF: Mean time between failure (MTBF) The average time duration between inherent failures of a repairable system component. The following formulae are used to calculate MTBF: 10 | P a g e ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 Mean time to recovery (MTTR) The average time duration to fix a failed component and return to operational state. This metric includes the time spent during the alert and diagnostic process before repair activities are initiated. (The average time solely spent on the repair process is called mean time to repair.) Mean time to detection (MTTD) The average time elapsed between the occurrence of a component failure and its detection. Reliability and availability calculations The calculations below are computed for reliability and availability attributes of an individual component. The failure rate can be used interchangeably with MTTF and MTBF as per calculations described earlier. Reliability is calculated as an exponentially decaying probability function which depends on the failure rate. Since failure rate may not remain constant over the operational lifecycle of a component, the average time-based quantities such as MTTF or MTBF can also be used to calculate Reliability. The mathematical function is specified as: Availability determines the instantaneous performance of a component at any given time based on time duration between its failure and recovery. Availability is calculated using the following formula: 11 | P a g e ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 Calculation of multi-component systems IT systems contain multiple components connected as a complex architectural. The effective reliability and availability of the system depends on the specifications of individual components, network configurations, and redundancy models. The configuration can be series, parallel, or a hybrid of series and parallel connections between system components. Redundancy models can account for failures of internal system components and therefore change the effective system reliability and availability performance. A reliability block diagram (RBD) may be used to demonstrate the interconnection between individual components. Alternatively, analytical methods can also be used to perform these calculations for large scale and complex networks. RBD demonstrating a hybrid mix of series and parallel connections between system components is provided: The basics of an RBD methodology are highlighted below. Using failure rates The effective failure rates are used to compute reliability and availability of the system using these formulae: • For series connected components, the effective failure rate is determined as the sum of failure rates of each component. o For N series-connected components: • For parallel connected components, MTTF is determined as the reciprocal sum of failure rates of each system component. o For N parallel-connected components: 12 | P a g e ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 For hybrid systems, the connections may be reduced to series or parallel configurations first. Using availability and reliability specifications Calculate reliability and availability of each component individually. For series connected components, compute the product of all component values. For N series-connected components. • For parallel connected components, use the formula: o For N parallel-connected components. • For hybrid connected components, reduce the calculations to series or parallel configurations first. It can be observed that the reliability and availability of a series-connected network of components is lower than the specifications of individual components. For example, two components with 99% availability connect in series to yield 98.01% availability. The converse is true for parallel combination model. If one component has 99% availability specifications, then two components combine in parallel to yield 99.99% availability; and four components in parallel connection yield 99.9999% availability. Adding redundant components to the network further increases the reliability and availability performance. It’s important to note a few caveats regarding these incident metrics and the associated reliability and availability calculations. These metrics may be perceived in relative terms. Failure may be defined differently for the same components in different applications, use cases, and organizations. 13 | P a g e ME402 MAINTENANCE ENGINEERING MODULE 6 LECTURE NOTES 2 The value of metrics such as MTTF, MTTR, MTBF, and MTTD are averages observed in experimentation under controlled or specific environments. These measurements may not hold consistently in real-world applications. Organizations should therefore map system reliability and availability calculations to business value and end-user experience. Decisions may require strategic trade-offs with cost, performance and, security, and decision makers will need to ask questions beyond the system dependability metrics and specifications followed by IT departments. Additional resources The following literature was referenced for system reliability and availability calculations described in this article: Johnson, Barry. (1988). Design & analysis of fault tolerant digital systems. Chapters 1-4. Johnson, Barry. (1996). An introduction to the design and analysis of fault-tolerant systems. 1-87. ______________________________________________________________ About the author Muhammad Raza Muhammad Raza is a Stockholm-based technology consultant working with leading startups and Fortune 500 firms on thought leadership branding projects across DevOps, Cloud, Security and IoT. 14 | P a g e