Bio321 Genetics Lecture Notes: DNA Structure & Replication
advertisement

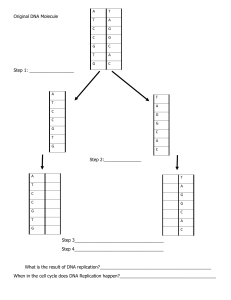
Bio321 genetics Chap 1 Bio321 genetics Chap 1 The molecule that carries the genetic information is DNA (deoxyribonucleic acid) Discovered in the 1940s and early 50s in a series of experiments. The first and most easily understood was carried out by Frederick Griffith in 1928. Frederick Griffith worked with two strains of pneumococci bacteria, one pathogenic, capable of causing pneumonia in mice, and the other non-pathogenic. The pathogenic strain formed smooth S colonies (masses of cells) on semi-solid media in petri dishes while the avirulent strain formed rough R colonies. This difference arises from a polysaccharide coat that the virulent strain has which both allows it to be virulent and gives colonies the smooth appearance If cells from the smooth colonies were injected in mice, the mice died of pneumonia, but if the cells were heat-killed, the mice survived. Cells from the rough colonies did not cause pneumonia, but if injected into mice along with heat-killed smooth cells, the mice did die, and only live smooth type cells could be recovered from the dead mice. He proved transformation (virulence going from S to R) Macleod, McCarty and Avery (1944) follow up of Griffith’s experiment and showed transformation could take place in a mouse or in a test tube. They demonstrated that DNA and only DNA prepared from the smooth cells was the active agent in transferring the genes for the polysaccharide coat, and, therefore, virulence to rough cells (tested each cell component and found that only DNA could transform R to S). The rough cells took up DNA from the medium and became transformed to virulence. transformation is an inherited characteristic of bacteria. Then they Treated the heat killed S cells with different enzymes to determine what component had transforming activity. Treated the cells with three chemicals: DNases - degrade DNA RNases - degrade RNA Proteases - degrade proteins. Hershey and Chase conducted their experiments on the T2 phage, a virus whose structure had recently been shown by electron microscopy. o Consists only of a protein shell containing its genetic material. The phage infects a bacterium by attaching to its outer membrane and injecting its genetic material, causing the bacterium's genetic machinery to produce more viruses, leaving its empty shell attached to the bacterium. Bio321 genetics • • Chap 1 In a first experiment, they labeled the DNA of phages with radioactive Phosphorus-32 (the element phosphorus is present in DNA but not present in any of the 20 amino acids from which proteins are made). They allowed the phages to infect E. coli, then removed the protein shells from the infected cells with a blender and separated the cells and viral coats by using a centrifuge. They found that the radioactive tracer was visible only in the pellet of bacterial cells and not in the supernatant containing the protein shells. In a second experiment, they labeled the phages with radioactive Sulfur-35 (Sulfur is present in the amino acids cysteine and methionine, but not in DNA). After separation, the radioactive tracer then was found in the protein shells, but not in the infected bacteria, supporting the hypothesis that the genetic material which infects the bacteria is DNA. Hershey shared the 1969 Nobel Prize in Physiology or Medicine for his “discoveries concerning the genetic structure of viruses.” As a molecule, the structure of DNA was ultimately solved in 1953 by James Watson and Francis Crick (Rosalind Franklin who was never acknowledged) using X ray diffraction techniques. “Central dogma of molecular biology” • DNA→RNA →Protein now many view it as • RNA →DNA→RNA →Protein An RNA molecule that is catalytic is an argument for the RNA world theory:2 roles: role of a protein and DNA at the same time. It is the 2’OH that gives the RNA catalytic characteristics DNA carries information through the bases A molecule which carries the genetic information must have three important properties: (DNA) 1. It must be capable of faithful replication so that when a cell divides, it can be passed on to the two progeny cells. 2. It must be capable of carrying information. 3. It must be capable of variation within a limited context to allow diversity within a species and the evolution of new species. Chromosome behavior and Mendelian genetics are more easily understood within the context of DNA structure. Bio321 genetics Chap 1 DNA Structure • Nitrogen Bases • Pyrimidines (single ring) 1. Cytosine 2. Thymine • Purines (double ring) 1. Guanine 2. Adenine Deoxyribose-sugar: NUCLEOSIDE: Sugar plus base Phosphate: NUCLEOTIDE: nucleoside plus phosphate 5'C of deoxyribose to phosphate 1'C of deoxyribose to 1N of Pyrimidine 1'C of deoxyribose to 9N of Purine *Polymer *Single-strand structure*Covalent 5',3' phosphodiester bonds *Single-strand has defined 5'to 3' polarity *Base pairing A-T, two H-bonds G-C, three H-bonds *The DNA helix has 10 bases/turn. *Stability of double-helix (very stable) derived from: *Hydrogen bonds mainly between bases (GC more stable than AT) *Stacking interactions (Van der Waal that include hydrophobic interactions between bases (Both are weak but additive) *Strands oriented in the opposite polarity with respect to each other *the 3’ end extends the DNA strand further DNA is stable even though it doesn’t have ionic bonds (it has covalent bonds: phosphodiester) Bio321 genetics Chap 1 There is a major groove and a minor groove formed because of the asymmetry in base pairing mainly. (Imp for transcription factor recognition by interchelating into DNA and “reading” bases). • Standard right-handed DNA seen in vivo is “B” form DNA. 2 other forms are known: • A DNA (also right-handed but wider and fatter) • “Z” DNA, with the negative sugar/P backbone that “zigzags” around and comes in close contact with itself creating repulsion and hence instability. physiological significance not well understood Why are the grooves so important: they allow protein access to bases so that they can bind and differentiate DNA molecules from one another DNA molecules are long. The DNA molecule in a simple bacterium, Escherichia coli contains 3,000 genes and is a circle of 4.1x106 bp, or 1.4 mm long. The DNA molecule in a single human chromosome is in the range of 100x106 bp, or 3.4 cm long. There is about 1.8 m of DNA in a human cell. DNA Replication The principle of DNA replication is obvious: Once one strand is defined, there is a unique second strand that can pair with it. DNA replication proceeds by the rules of base pairing, the strands unzip and two new strands are synthesized according to the A-T, G-C rules. The old strand is the template. This mechanism is termed semi-conservative replication because the two new DNA molecules consist of one new and one old strand. (MeselsonStahl experiment with 15N) The structure of DNA is very regular in that the nucleotide monomers are not terribly different in their chemical properties, so the linear DNA does not take on any different three dimensional structure (Mostly B DNA, other forms like A and Z are possible) according to the base pair sequence. Therefore, the only variation between DNA molecules from different species is the sequence of the base pairs. Thus from the structure alone one would predict, correctly as we now know, that the information content of DNA is encoded in the linear arrangement of the base pairs. To open a DNA molecule: heat it to 95’C • We can extract DNA from fossils but not RNA and proteins (they will degrade) Bio321 genetics Chap 1 Limited Variation in the Genetic Information • It is clear from the structure of DNA how faithful replication occurs and how the information content, the sequence of base pairs, is preserved through the replication process. • But what about the variation in populations that allow individuals within a species to display somewhat different traits, like different eye color in humans, and that ultimately lead to evolution of new species? The information content of DNA must be changeable too, but in very small steps. • This too can be visualized through studying DNA structure. If a gene is comprised of say a 1,000 bp stretch of DNA, be can imagine that a change in a single base pair could have a very small affect on the properties of the gene. This is partly true. Sometimes a single base pair change can completely eliminate the function that the gene encodes, other times it only modifies its function, while other changes might have no affect at all. • These changes happen with some frequency and are called mutations. In humans, the estimated frequency of mutations for a given gene is from 1/10,000 to 1/million. This is an estimate for the chance of an individual passing on a mutation in a given gene to his/her children. Given that the number of genes in humans is somewhere around 20-25,000, the frequency of mutations over the whole genetic content is not trivial. • This mutation rate can be greatly elevated by chemicals or radiation that damages DNA, and this of course is a major environmental concern today. Why do the mutation rate 1/10.0001/ a million have a big gap of 100 folds? Different genes tolerate different mutations Genes that have important functions cannot tolerate mutations and will have a rate of 1/million whereas other genes (not as important such as the color of the eye) can tolerate mutations without causing harm and will have a rate of 1/10.000 Even though the rate of mutations is constant (1/10.0001/million), the rate of passing it to the next generation varies because different regions tolerate different mutations