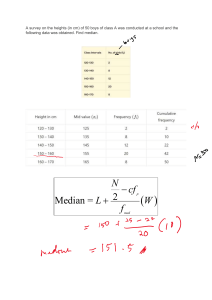
WEEK 1: Descriptive Statistics Types of data (concepts) • A variable is a characteristic of a population or of a sample from a population. A data set contains observations on variables - Discrete (whole numbers that can’t be broken down such as number of items) or continuous variables (numbers that can be broken down e.g height and weight) à Under continuous there is interval (numbers with known differences between variables e.g time) and ratio (numbers that have measurable intervals where difference can be determined such as height or weight) - Quantitative or qualitative (nominal is when variables are simply labelled, ordinal is when variables are labelled and also in a specific order e.g poor, good, very good) To apply statistical analyses directly to qualitative data, it must be converted to quantitative data. Types of observations The type of observation made by the statistician can also be used to classify data: • Time series data consists of measurements of the same concept at different points in time (e.g Sydney-area births per day) for each day in a year • Cross sectional data consists of measurements of one or more concepts at a single point in time (e.g age, gender, marital status of sample of UNSW staff in a particular year) • Longitudinal/panel data features both characteristics The type of data you have influences what type of analysis is appropriate: • Examining monthly or seasonal patterns in the number of births would be sensible. • Also suppose the marital status is coded as Single = 1, Married = 2, Divorced = 3, Widowed = 4. It would not make sense to calculate the ‘average marital status’ of the UNSW staff 1. Summaries for categorical variables Frequency distribution (graphical summary) Frequency distributions are summaries of categorical data using counts. Categories need to be mutually exclusive and exhaustive. xxx A B Total Frequency Relative frequency Relative frequency = frequency of n/total frequency 100 Pie charts and bar charts are graphical representation of frequency distributions: • Pie charts show relative frequencies more explicitly Histograms (graphical summary) Assuming data is ordinal (whether discrete or continuous), the obvious categories for the data values may not exist, but we can create categories by defining lower and upper category limits. These categories need to be mutually exclusive and exhaustive. • Categories are called bins in excel Describing histograms • Symmetry (or lack of) describes whether the left half of a symmetric histogram is a mirror image of the right half • Skewness – a feature of an asymmetric histogram - Long tail to the right = positively skewed (mean > median) - Long tail to the left = negatively skewed (mean < median) - A skewed distribution may also be associated with outliers • Clusters • Number of modal classes/bins - The modal class is the class with highest frequency. If a histogram has a single modal class, it is unimodal. - Histograms may be unimodal or multimodal 1.2 Describing bivariate relationships How can relationships between multiple variables be characterised? • • Contingency table (‘cross-tabulation’ or ‘cross-tab’ table) which captures the relationship between two qualitative variables e.g mode of transport & gender Scatterplots captures the relationship between two quantitative variables. If one of these variables is ‘time’ then we get a time series plot The purpose of these plots is to understand the data and to help you solve a problem. Thus, always ask yourself is the data appropriate and if not what else do you need to answer the question and solve the problem. There are three categories of numerical summaries, measures of location, measures of variability and measures of association. Measures of central tendency (location) • A parameter describes a key feature of a population • A statistic describes a key feature of a sample A natural measure of ‘location’ or ‘central tendency’ (a key feature) is the arithmetic mean (other variants include weighted mean/WAM and geometric mean) • The median is the middle value of ordered observations: - When n is odd the median will be a particular value - When n is even, the median is the average of the middle two values • The mode is the most frequently occurring value (s) – ‘the modal class’ was previously defined in the context of unimodal histograms. The mean, median and mode each provide different notions of ‘representative’ or ‘typical’ central values. • For symmetric distributions, mean = median • For positively (negatively) skewed data: mean > (<) median. The median is preferred when the data contains outliers Measures of relative location Sometimes we wish to measure variation relative to location: • Case 1: Observations all measured in millions, and standard deviation is 20 – relatively little variability • Case 2: Observations all positive but less than 100 à s = 20 may indicate a lot of variability (Sample) coefficient of variation provides a measure of relative variabilityà Percentiles – measures of relative location The median relies on a ranking of observations to measure location. This idea generalizes to percentiles – the Pth percentile is the value for which P percent of observations are less than that value. • The median is the 50th (Q2) percentile • The 25th (Q1) and 75th (Q3) percentiles are called, respectively, the lower and upper quartiles • The difference between the upper and lower quartiles is called the interquartile range – another measure of spread - Q1 = (x2 + x3)/2 - Q2 = (x4 + x5)/d2 - Q3 = (x6 + x7)/2 - IQR = Q3 – Q1 Measures of variability Variance and standard deviation are two basic measures of variability. • • Range is a simple measure of variability. Range = maximum – minimum Variance is the most common measure of variability. It measures average squared distance from the mean - Division by n-1 for sample variance relates to properties of estimators • The standard deviation is the spread measured in the original units of the data (not squared) Z-score We can create a transformed variable with zero mean and ‘unit’ i.e variance from any original quantitative variable. This transformed variable is free of units of measurement, which is called calculating z-scores (one z-score per observation). Calculate (observation – mean) and then divide this difference by the standard deviation: Z = [xi−μ]/σ - E.g suppose for mutual fund A, the maximum return is 63%. This point has a z-score of (63-10.95)/21.89 = 2.38 which implies that 63% is 2.38 standard deviations above the mean return Coefficient of variation To understand whether the variance or standard variation is large or small depends on the scale of the units. These are measures of relative variability and allows us to compare the variability across different variables and datasets (Sample) coefficient of variation: s/x Population coefficient of variation: σ/μ Measures of association To examine the relation of two variables, there are two main measures which are covariance and correlation Introduction to linear regression Covariance is a numerical measure: • Positive (negative) covariance à Positive (negative) linear association • Zero covariance à No linear association • • xi and yi are values of observation μx and μy represent the mean for x and y Thus [xi - μx] represents the x-axis distance of the observation to the mean of x and tells you the direction (applies to y value as well) However covariance is not scale free. The correlation coefficient is a standardized, unit-free measure of association: It ranges between 1 (perfect positive linear relationship) and -1 (perfect negative linear relationship). Linear regression Covariance and correlation are the two basic measures of association. This relationship can be further characterised by running a simple linear regression. To determine the linear relationship between x&y, and to choose the intercept and slope values to give the best fit, we minimise the residual sum of squares (least squares method – a basis of regression analysis). Assuming: Where b0 and b1 are chosen to minimize The ‘solution’ to this minimization problem consists of one intercept estimate and one slope estimate that together minimize the residual sum of squares’ • • The point that consists of the mean of x and y will lie on the line of best fit b1 will have the same sign as the covariance (correlation) between y and x The fit of the ‘model’ (the fitted line) to the actual data (= the y-values observed at each x value) is described by the Rsquared statistic. A fit statistic considers how much variation the residuals (the variation in the y variable that is not explained by the model) compared to how much variation is in the whole y variable. The ‘larger’ this unexplained variation, the less the model ‘fits’ In a simple bivariate regression à R2 = [correlation of x and y]2 à R2 is also known as the coefficient of determination Example b1 = 15.296/(9.095) = 1.682 b0 = 10 – 1.682*12.677 = -11.323 • Excel assumes the covariances has the whole population so to recover sample covariances, we have to multiply by n/(n-1) à 14.267*(15/14) = 15.296 is actually the sample variance WEEK 2: Probability, discrete random variables, and the binomial distribution WEEK 3: Continuous random variables and the normal distribution WEEK 4: Estimators, the sampling distribution and estimating the population proportion WEEK 5: Estimating the population mean WEEK 6: Errors with hypothesis testing and the Chi-squared test WEEK 7: Simple linear regression, assumptions and OLS inference WEEK 8: The multiple linear regression model and model building WEEK 9: Addendum: Addressing causality, experiments and regressions