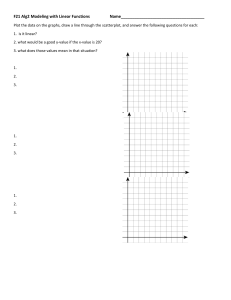
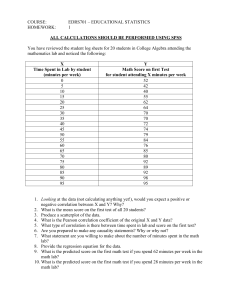
Uploaded by
khurana_akanksha
R Data Analysis Homework: Possum, MPG, Flights, Boston Datasets
advertisement

Assignment- 5
Homework policies- Please provide concise, clear answers for each question. Note that only writing the result
of a calculation (e.g., "SD = 3.3") without explanation is not sufficient. For problems involving R, include the
code in your solution, along with any plots.
Please submit your homework assignment as a PDF file.
Max points: 100 (Each problem is 20 points.)
Student Name: Akanksha Khurana
PROBLEM 1
For the data frame possum (DAAG package)
a) Use the function str() to get information on each of the columns.
o There are 14 variables/columns in possum data frame.
o The code is illustrated in the screenshot below, with the function str() being utilized.
b) Using the function complete.cases(), determine the rows in which one or more values is missing.
Print those rows. In which columns do the missing values appear?
o There are two missing values in column age and one missing value in column footlgth.
o Rows BB36, BB41, and BB45 have the missing values.
o Row BB36 has one value missing in column footlgth.
o Row BB41 and BB45 each has one value missing in column age.
o The code is illustrated in the screenshot below, with the function complete.cases() being
utilized.
1
PROBLEM 2
Run library(ggplot2) and data(‘mpg’) before answering questions below.
a) How many rows are in mpg? How many columns?
o There are 234 rows and 11 columns in the data frame for mpg.
o Using several functions, we can determine the number of rows and columns. The code is illustrated
in the screenshot below, with functions str(), nrow(), ncol(), and glimpse().
b) What does the drv variable describe? Read the help for ?mpg to find out.
o The drv is a categorical variable. It categorizes the type of car drive:
§ f as front-wheels drive,
§ r as rear-wheels, and
§ 4 as four-wheel drive.
o The code is illustrated in the screenshot below, with the function ?mpg being utilized.
2
c) Make a scatterplot of hwy versus cyl. Comment on the outcome.
o It suggests a strong negative linear relationship. As the number of cylinders increases, the Highway
MPG tends to decrease. This negative correlation suggests that vehicles with more cylinders tend to
have lower fuel efficiency on the highway.
o The code for creating a scatterplot of hwy versus cyl is illustrated in the screenshot below.
d) What happens if you make a scatterplot of class versus drv? Why is the plot not useful?
o class is a categorical variable that represents the vehicle class (compact, subcompact, SUV, and so
on).
o drv is a categorical variable that represents the type of drive (for example, front-wheel drive, rearwheel drive, and four-wheel drive).
o A scatterplot is typically the best choice for plotting continuous data. Because class and drv are
both categorical variables, a scatterplot is inefficient for demonstrating their relationship.
o Furthermore, the generated scatterplot has only a few points. In this data, drv takes three values and
class takes seven, hence there are 21 possible plots. However, only 12 values were plotted in the
scatterplot.
o The code for creating a scatterplot of class versus drv is illustrated in the screenshot below.
3
PROBLEM 3
Run following codes:
library(nycflights13)
data('flights')
str(flights)
a) Plot arr_delay versus distance.
o In the arr_delay column of the flights data frame, there are 9,430 missing values. As a result, in
order to create a scatterplot for arr_delay and distance, we have to first eliminate the NAs, build a
new data set, and then plot a scatterplot.
o The code for creating a scatterplot of arr_delay versus distance is illustrated in the screenshot
below.
b) Use the hist() command to plot a histogram of the distance.
o The code containing the method hist() used to create a histogram of the distance is illustrated in the
screenshot below.
4
c) Repeat (a) and (b) after taking logarithms of distance.
o The code for creating a scatterplot of arr_delay versus log of distance is illustrated in the screenshot
below.
5
o
The code for creating a histogram of distance logarithms is illustrated in the screenshot below.
d) Describe the differences between two histograms.
o Histogram of Distance:
§ The histogram represents the distribution of the actual distance values in the flight’s
dataset.
§ The x-axis represents the distance values, and the y-axis represents the frequency or
count of flights for each distance bin.
o Histogram of Log of Distance:
§ The histogram represents the distribution of the logarithm of the distance values in the
flight’s dataset. We take the log of each distance value and create bins based on those
logarithm values.
§ The x-axis represents the log of distance values, and the y-axis represents the
frequency or count of flights for each logarithm distance bin. Logarithm values has
compressed the data and made patterns more apparent.
PROBLEM 4
This problem involves the Boston housing data set.
To begin, load in the Boston data set. The Boston data set is part of the MASS library in R. The data set is
contained in the object Boston.
> library (MASS)
> Boston
Read about the data set:
> ?Boston
a) How many rows are in this data set? How many columns? What do the rows and
columns represent?
o The data frame for Boston contains 506 rows and 14 columns.
o The statistic depicts the house values in Boston's suburbs. Each row reflects the set of predictor
observations for a specific Boston neighborhood. Each column represents a predictor variable for
which an observation was made in one of Boston's 506 neighborhoods.
o The code is illustrated in the screenshot below, with the function str() being utilized.
6
b) How many of the suburbs in this data set bound the Charles River?
o Column chas represents: Charles River dummy variable (= 1 if tract bounds river; 0 otherwise),
hence this column can be utilized to see the count results.
o The code for filter() is illustrated in the screenshot below. The Charles River is bounded by 35
suburbs.
PROBLEM 5
Continue with the data in problem-4 and answer questions below.
a) Make two meaningful scatterplots of the predictors (columns) in this data set. Describe
your findings.
o Scatterplot 1:
§ Scatterplot 1 depicts the relationship between “rm” (average number of rooms) and
"medv" (median value of owner-occupied dwellings in $1000s).
§ The calculated correlation coefficient of 0.6953599 indicates a moderately strong
positive correlation.
§ A positive correlation coefficient shows that as the average number of rooms in homes
increases, so does the median value of those homes.
§ The code for creating a scatterplot of rm versus medv and calculating the correlation
coefficient is illustrated in the screenshot below.
7
o Scatterplot 2:
§ Scatterplot 2 depicts the relationship between “crim” (per capita crime rate by town)
and "age" (proportion of owner-occupied units built prior to 1940).
§ The calculated correlation coefficient of 0.3527343, indicates a moderately weak
positive correlation.
§ The positive correlation indicates that as the proportion of owner-occupied units built
prior to 1940 increases, so does the per capita crime rate. The correlation value of
0.3527343, on the other hand, indicates that the association is not particularly strong.
Overall, it suggests that there may be a link between older housing units and greater
crime rates in a community.
§ The code for creating a scatterplot of crim versus age and calculating the correlation
coefficient is illustrated in the screenshot below.
8
b) Are any of the predictors associated with per capita crime rate? If so, explain the
relationship.
o Yes, in the scatterplot 2, I have considered per capita crime rate to plot a correlation
between per capita crime rate by town and proportion of owner-occupied units built
prior to 1940.
o It indicates a moderately weak positive correlation.
9