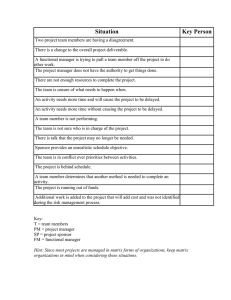
Flight Delays Report Group Assignment Study Program: International Marketing & Management, Year 1 ISM University of Management and Economics Subject: Multivariate Statistics Vilnius, Lithuania November 18, 2022 Project group: Agnieška Paškevič Karolis Čipkus We have chosen to analyze a data set about flight delays. We want to understand whether flight delays (on time or delayed) can be predicted based on flight destination, an origin and a carrier. Hypothesis: ● The dependent variable we chose was “delay”, which is whether the flight was delayed or on time. ● The independent variable was “destination”, which is the flight’s landing place. ● The second independent variable was “origin”, which indicates the start point of the flight. ● The third independent variable “carrier”, which indicates the airlines. Descriptive Statistics - Frequency Table Figure 1 Frequency Table of Delay First of all, we ran descriptive statistics for our dependent variable. On this frequency table (Figure 1), we can assume that more flights were on time, even 80.6%. Figure 2 shows us the frequency visualization of the delayed flights and on time flights. Figure 2 Graph of Delay Frequency Descriptive Statistics - Crosstabs As we want to see whether flights are affected by destination, origin and carrier, we ran Crosstabs, to see the frequency relationship between delay and each of them. Figure 3 Crosstab of Delay and Carrier Figure 3 shows us the frequency of delayed flights and on time flights based on the carrier. We can indicate that the biggest delay percentage has DH (32%), and the smallest one OH (0.9%). Looking at the second row, we can point out that DH has also the biggest on time percentage (23.4%), which might happen, because this carrier has the biggest amount of flight number (551) among all the chosen carriers. The lowest on time percentage is OH (1.5%) and UA (1.5%). Figure 4 Crosstab of Delay and Destination Figure 4 indicates the frequency between delays/on time and destination. Here we can see that LGA has the biggest percentage for delays (42.8%), but also highest on time percentage (54.5%), because LGA has the biggest number of flights (1150) among all the chosen destinations. JFK has the smallest delay (19.6%) and on time (17%) rate. Figure 5 Crosstab of Delay and Origin In figure 5, we can notice the same situation. The origin DCA, which has the biggest number of flights (1370), are leading in delayed (51.6%) and on time (64.8%) rows. The smallest percentage for delayed (8.6%) and on time (6.1%) flights has BWI origin. Examination For our examination we chose logistic regression analysis, as we want to predict if delayed/on time flights are affected by destination, origin and carrier. Hypothesis: H0: �1 =⋯= �n = 0 H1: at least one �i ≠ 0. (Example nr. 1) In Example nr. 1 we can see that the table contains the Cox & Snell R Square and Nagelkerke R Square values, which are both methods of calculating the explained variation. These values are sometimes referred to as pseudo R2 values (and will have lower values than in multiple regression). However, they are interpreted in the same manner, but with more caution. Therefore, the explained variation in the dependent variable based on our model ranges from 38% to 61% , depending on whether you reference the Cox & Snell R2 or Nagelkerke R2 methods, respectively. (Example nr. 2) In our case Logistic regression estimates the probability of an event that will occur, in our case it’s whether or not the flight was delayed (2004 data). If the estimated probability of the event occurring is greater than or equal to 0.5 (better than even chance), SPSS Statistics classifies the event as occurring (e.g., flight was not delayed). If the probability is less than 0.5, SPSS Statistics classifies the event as not occurring (e.g., flight was delayed). It is very common to use logistic regression to predict whether cases can be correctly classified (i.e., predicted) from the independent variables. Therefore, it becomes necessary to have a method to assess the effectiveness of the predicted classification against the actual classification. In Example nr. 2 we see that 0% of the observations that were predicted by the model to be delayed were correct. On the other hand, flights that have not been delayed were 100% correctly predicted by the model to not be delayed. So in total the model correctly classifies 80.6% of cases “Percentage Correct”. (Example nr. 3) Moving on to Example nr. 3 we see that out of the three independent variables only one of them can be classified as significant which is “Carrier” that has p value much lower than 5%. Origin comes pretty close to being significant with a p value of 5.9%, however the destination variable is the most insignificant and has p value of 63%. Next important parameter is the Wald test, which is used to determine statistical significance for each of the independent variables. Additional data we can use from this table is the “B” coefficients that shows us how different carriers, origins and destinations affect the likelihood whether or not the flight will be delayed. Another important metric to look at is “Exp(B)”. When this coefficient is =1 it means that there is no relationship, when it’s >1 the relationship is positive and <1- relationship is negative. “B” and “Exp(B)” directly correlate. For example “Origin(2)” has a much bigger positive impact on the probability “B”=0.44; “Exp(B)”=1.553 that the flight will not being delayed than “Carrier(1)”, “B”=-1.5 ; “Exp(B)”=0.223 in fact “Origin(2)” has the biggest positive impact out of all the variables we have in this table. (Example nr. 4) Example nr. 4 graph shows us that out of all carriers “DH” and “US” got the most “ontime” flights, also it’s easy to notice that when it comes to “origin” (the starting point of the flight) the most successful one is “DCA”. When it comes to which carrier had the most delayed flights it is “DH”. It’s convenient to say that “DH” is not the reason for the delayed flights, its origins fault “IAD”, but when you look at other carriers that depart from the same “IAD” location, it becomes clear that the carrier is the one to correlate the delays to. (Example nr. 5) (Example nr. 5) is pretty similar like the previous chart except for the “origin”, we have destination variable. Pretty similarly out of all carriers “DH” and “US” got the most “ontime” flights. When it comes to delayed flights, the situation also hasn't changed that much in terms of which variable is more correlatable to delayed flights. At first sight we see that “EWR” destination is to blame for the delay, however it’s not because when we look at the other carriers we see that only “RU” has delayed flights to “EWR”. So we come back to the previous conclusion that the one, most responsible variable for delaying flights is carrier “DH”. In this case every single destination had their flights delayed. For an additional diagnosis, we decided to run a discriminant analysis. It will also show the importance of independent variables to predict outcomes. (Example nr. 6) After applying discriminant analysis, Example nr. 6 shows us “Standardized Canonical Discriminant Function Coefficients” and these coefficients can be used to calculate the discriminant score for a given case. Normally we should get two functions (one for on time, one for delayed flight), however we had some difficulties preparing the data for discriminant analysis (the main problem was converting “string” values). Still we got the coefficients and it’s important to show how they can be used: Function 1 = 0.589*origin - 0.511*carrier + 0.84*dest And incase were we get the second set of coefficients that indicates how strongly the discriminating variables effect the score, we could put the same variables into both equations (with different coefficients) and select the one with the highest discriminant function value. (Example nr. 7) Moving on to Example nr. 7 we see the “Structure Matrix”. It shows us the correlations between the observed variables and grouping variable. “Origin” has the highest value of 0.738 then comes “dest” with 0.5 and the liest correlatable value is “carrier” with -0.28. Summary o Did you manage to find support for your hypothesis? Yes. Even though not every variable was significant, we found that there is a relationship between the X variables and the Y variable. o If several techniques were tried, did the conclusions from them agree? Kinda, because the logistic regression showed us that the most influential (negative) variable was “carrier”, however in discriminant analysis we got different results that showed us “carrier” has actually the least correlation with the function (hence it’s important to note that we had problems preparing the data for discriminant analysis). On the other hand we can see that both statistical methods showed that there is a significant relationship between some variables and we can reject the null hypothesis that states: there is no relationship between the X variables and the Y variable. o Which of the employed methods produced the most accurate (i.e. least biased) results? Logistic regression analysis. Because like in the Example nr. 4, we discussed which variable is more crucial when it comes to predicting whether or not the flight will be delayed, carrier was the answer. Out of the two methods we used, Logistic regression analysis showed that “carrier” was the most influencing variable. o What were the limitations of your data and analysis? The limitations of our data and analysis were the small number of examined variables. Some of them were not even vital for the examination. o How would you improve your analysis in the future? For future analysis, we could collect a broader amount of information. For instance, we only had information about delays of three destinations: EWR, JFK and LGA. All of them are in New York, so in the future analysis, it would be interesting to see how situations are different in whole US airports, and see what are the biggest reasons for delayed flights. Also, as we believe, the most common delays happen due to weather conditions. In this data set, there was a small amount of information about the weather. Collecting information about meteorological conditions as cloudy, sunny, rainy, windy, would give more precise and logical results of delayed/on time flights.