MACHINE LEARNING AND DATA MINING
Final syllabus topics and solve
https://drive.google.com/drive/folders/1CoNE3BkgOJNj6q9lhPhjcs
qyK0fYDUAG?usp=sharing
TASNIM
C191267
1
Contents
1
Segment 4 .............................................................................................................................................................................................................. 1
1.1
2
3
1.1.1
Data Cube and OLAP, ............................................................................................................................................................................. 1
1.1.2
Data Warehouse Design and Usage ...................................................................................................................................................... 1
Classification: ......................................................................................................................................................................................................... 6
2.1.1
Basic Concepts,....................................................................................................................................................................................... 6
2.1.2
Decision Tree Induction, ......................................................................................................................................................................... 6
2.1.3
Bayes Classification Methods, ................................................................................................................................................................ 6
2.1.4
Rule-Based Classification, ....................................................................................................................................................................... 8
2.1.5
Model Evaluation and Selection. ............................................................................................................................................................ 9
Classification Advanced Topics: .............................................................................................................................................................................. 9
3.1.1
Techniques to Improve, .......................................................................................................................................................................... 9
3.1.2
classification Accuracy: ........................................................................................................................................................................... 9
3.1.3
Ensemble Methods................................................................................................................................................................................. 9
3.1.4
Bayesian Belief Networks, .................................................................................................................................................................... 10
3.1.5
Classification by Backpropagation, ....................................................................................................................................................... 11
3.1.6
Support Vector Machines, .................................................................................................................................................................... 13
3.1.7
Lazy Learners (or Learning from Your Neighbors): ............................................................................................................................... 13
3.1.8
Other Classification Methods ............................................................................................................................................................... 14
3.2
4
Data Warehouse Modeling: .......................................................................................................................................................................... 1
Cluster Analysis: ........................................................................................................................................................................................... 14
3.2.1
Basic Concepts,..................................................................................................................................................................................... 14
3.2.2
Partitioning Methods,........................................................................................................................................................................... 14
3.2.3
Hierarchical Methods ........................................................................................................................................................................... 16
3.2.4
Density-Based Methods deletion. ........................................................................................................................................................ 20
Segment 5 ............................................................................................................................................................................................................ 20
4.1
Outliers Detection and Analysis: .............................................................................................................................................................. 20
4.2
Outliers Detection Methods....................................................................................................................................................................... 20
4.2.1
5
6
Mining Contextual and Collective ........................................................................................................................................................ 21
From class lecture:............................................................................................................................................................................................... 23
5.1
K-Nearest Neighbor (KNN) Algorithm for Machine Learning ..................................................................................................................... 23
5.2
Apriori vs FP-Growth in Market Basket Analysis – A Comparative Guide .................................................................................................... 25
5.3
Random Forest Algorithm ........................................................................................................................................................................... 30
5.4
Regression Analysis in Machine learning ................................................................................................................................................... 31
5.5
Confusion Matrix in Machine Learning....................................................................................................................................................... 34
Exercise: ............................................................................................................................................................................................................... 35
1 Segment 4
1.1 Data Warehouse Modeling:
1.1.1 Data Cube and OLAP,
1.1.2 Data Warehouse Design and Usage
1. a) What do you mean by Data Warehouse? Do you think if you have proper database, still need data warehouse? Justify your
answer.
b) Consider about Agora Super Shop. Based on "Agora" develop and draw a sample data cube.
c) Why do we need data mart?
1.
a) Draw the multi-tiered architecture of a data warehouse and explain briefly. 4
b) Compare between star and snowflake schema with necessary figures. 3
c) Explain the different choices for data cube materialization. 3
What Is a Data Warehouse?
Tasnim (C191267)
2
Data warehousing provides architectures and tools for business executives to systematically organize, understand, and use their data to make
strategic decisions. Datawarehouse systems are valuable tools in today’s competitive, fast-evolving world. In the last several years, many firms
have spent millions of dollars in building enterprise-wide data warehouses. Many people feel that with competition mounting in every industry,
data warehousing is the latest must-have marketing weapon—a way to retain customers by learning more about their needs.
Let’s take a closer look at each of these key features.
•
•
•
•
Subject-oriented: A data warehouse is organized around major subjects such as customer, supplier, product, and sales. Rather than
concentrating on the day-to-day operations and transaction processing of an organization, a data warehouse focuses on the modeling
and analysis of data for decision makers. Hence, data warehouses typically provide a simple and concise view of particular subject issues
by excluding data that are not useful in the decision support process.
Integrated: A data warehouse is usually constructed by integrating multiple heterogeneous sources, such as relational databases, flat
files, and online transaction records. Data cleaning and data integration techniques are applied to ensure consistency in naming
conventions, encoding structures, attribute measures, and so on.
Time-variant: Data are stored to provide information from an historic perspective (e.g., the past 5–10 years). Every key structure in the
data warehouse contains, either implicitly or explicitly, a time element.
Nonvolatile: A data warehouse is always a physically separate store of data transformed from the application data found in the
operational environment. Due to this separation, a data warehouse does not require transaction processing, recovery, and concurrency
control mechanisms. It usually requires only two operations in data accessing: initial loading of data and access of data.
Differences between Operational Database Systems and Data Warehouses
Because most people are familiar with commercial relational database systems, it is easy to understand what a data warehouse is by
comparing these two kinds of systems. The major task of online operational database systems is to perform online transaction and
query processing. These systems are called online transaction processing (OLTP) systems. They cover most of the day-to-day
operations of an organization such
as purchasing, inventory, manufacturing, banking, payroll, registration, and accounting. Data warehouse systems, on the other hand,
serve users or knowledge workers in the role of data analysis and decision making. Such systems can organize and present data in
various formats in order to accommodate the diverse needs of different users. These systems are known as online analytical
processing (OLAP) systems.
The major distinguishing features of OLTP and OLAP are summarized as follows: Users and system orientation: An OLTP system
is customer-oriented and is used for transaction and query processing by clerks, clients, and information technology professionals. An
OLAP system is market-oriented and is used for data analysis by knowledge workers, including managers, executives, and analysts.
Data contents: An OLTP system manages current data that, typically, are too detailed to be easily used for decision making. An
OLAP system manages large amounts of historic data, provides facilities for summarization and aggregation, and stores and manages
information at different levels of granularity.
These features make the data easier to use for informed decision making.
4.1.3 But, Why Have a Separate Data Warehouse?
Reasons for having a separate data warehouse:
1. Performance: Operational databases are optimized for specific tasks, while data warehouse queries are more complex and
computationally intensive. Processing OLAP queries directly on operational databases would degrade performance for
operational tasks.
2. Concurrency: Operational databases support concurrent transactions and employ concurrency control mechanisms. Applying
these mechanisms to OLAP queries would hinder concurrent transactions and reduce OLTP throughput.
3. Data Structures and Uses: Operational databases store detailed raw data, while data warehouses require historic data for
decision support. Operational databases lack complete data for decision making, requiring consolidation from diverse sources
in data warehouses.
Although separate databases are necessary now, vendors are working to optimize operational databases for OLAP queries, potentially
reducing the separation between OLTP and OLAP systems.
Tasnim (C191267)
3
Data Warehousing: A Multitiered Architecture
Data warehouses often adopt a three-tier architecture, as presented in Figure 4.1.
Figure from Slide
Figure from book
The three-tier data warehousing architecture consists of a bottom tier with a warehouse database server, a middle tier with an OLAP server, and
a top tier with front-end client tools.
The bottom tier, implemented as a relational database system, handles data extraction, cleaning, transformation, and loading functions. It
collects data from operational databases or external sources, merges similar data, and updates the data warehouse. Gateways like ODBC, OLEDB,
and JDBC are used for data extraction, and a metadata repository stores information about the data warehouse.
The middle tier consists of an OLAP server, which can be based on a relational OLAP (ROLAP) or a multi-dimensional OLAP (MOLAP) model.
ROLAP maps multidimensional operations to relational operations, while MOLAP directly implements multidimensional data and operations. The
OLAP server is responsible for processing and analyzing the data stored in the data warehouse.
The top tier is the front-end client layer that provides tools for querying, reporting, analysis, and data mining. It includes query and reporting
tools, analysis tools, and data mining tools. These tools allow users to interact with the data warehouse, perform ad-hoc queries, generate
reports, and gain insights through analysis and data mining techniques.
Overall, the three-tier data warehousing architecture facilitates efficient data extraction, processing, and analysis, enabling organizations to make
informed decisions and leverage business intelligence.
Data Warehouse Models: Enterprise Warehouse,
Data Mart, and Virtual Warehouse
The three data warehouse models are the enterprise warehouse, data mart, and virtual warehouse.
1. Enterprise Warehouse: An enterprise warehouse collects data from various sources across the entire organization. It provides
corporate-wide data integration and is cross-functional in scope. It contains detailed and summarized data, and its size can
range from gigabytes to terabytes or more. It requires extensive business modeling and may take a long time to design and
build. Examples include a data warehouse that integrates sales, marketing, finance, and inventory data from multiple
departments within a company.
Tasnim (C191267)
4
2. Data Mart: A data mart is a subset of data from the enterprise warehouse that is tailored for a specific group of users or a
particular subject area. It focuses on selected subjects, such as sales, marketing, or customer data. Data marts usually contain
summarized data and are implemented on low-cost departmental servers. They have a shorter implementation cycle compared
to enterprise warehouses. Examples include a marketing data mart that provides data on customer demographics, purchase
history, and campaign performance for the marketing department.
3. Virtual Warehouse: A virtual warehouse is a set of views over operational databases. It provides efficient query processing by
materializing only selected summary views. Virtual warehouses are relatively easy to build but require excess capacity on
operational database servers. They can be used when real-time access to operational data is required, but with the benefits of a
data warehouse's querying capabilities.
Pros and Cons of Top-Down and Bottom-Up Approaches:
• Top-Down Approach: In the top-down approach, an enterprise warehouse is developed first, providing a systematic solution
and minimizing integration problems. However, it can be expensive, time-consuming, and lacks flexibility due to the difficulty
of achieving consensus on a common data model for the entire organization.
• Bottom-Up Approach: The bottom-up approach involves designing and deploying independent data marts, offering flexibility,
lower cost, and faster returns on investment. However, integrating these disparate data marts into a consistent enterprise data
warehouse can pose challenges.
It is recommended to develop data warehouse systems in an incremental and evolutionary manner. This involves defining a high-level
corporate data model first, which provides a consistent view of data across subjects and reduces future integration problems. Then,
independent data marts can be implemented in parallel with the enterprise warehouse, gradually expanding the data warehouse
ecosystem.
houses and departmental data marts, will greatly reduce future integration problems.
Second, independent data marts can be implemented in parallel with the enterprise
Data Cube: A Multidimensional Data Model:
•
What Are the Elements of a Data Cube?
Now that we’ve laid the foundations, let’s get acquainted with the data cube terminology. Here is a summary of the individual
elements, starting from the definition of a data cube itself:
•
A data cube is a multi-dimensional data structure.
•
A data cube is characterized by its dimensions (e.g., Products, States, Date).
•
Each dimension is associated with corresponding attributes (for example, the attributes of the Products dimensions are T-Shirt,
Shirt, Jeans and Jackets).
•
The dimensions of a cube allow for a concept hierarchy (e.g., the T-shirt attribute in the Products dimension can have its own,
such as T-shirt Brands).
•
All dimensions connect in order to create a certain fact – the finest part of the cube.
•
A data cube, such as sales, allows data to be modeled and viewed in multiple dimensions
•
Dimension tables, such as item (item_name, brand, type), or time(day, week, month, quarter, year)
•
Fact table contains measures (such as dollars_sold) and keys to each of the related dimension tables
•
In data warehousing literature, an n-D base cube is called a base cuboid. The top most 0-D cuboid, which holds the highestlevel of summarization, is called the apex cuboid. The lattice of cuboids forms a data cube.
What Are the Data Cube Operations?
Data cubes are a very convenient tool whenever one needs to build summaries or extract certain portions of the entire dataset. We will
cover the following:
•
Rollup – decreases dimensionality by aggregating data along a certain dimension
•
Drill-down – increases dimensionality by splitting the data further
•
Slicing – decreases dimensionality by choosing a single value from a particular dimension
•
Dicing – picks a subset of values from each dimension
•
Pivoting – rotates the data cube
Advantages of data cubes:
•
Multi-dimensional analysis
•
Interactivity
•
Speed and efficiency:
•
Data aggregation
•
Helps in giving a summarized view of data.
•
Data cubes store large data in a simple way.
•
Data cube operation provides quick and better analysis,
•
Improve performance of data.
Disadvantages of data cube:
Tasnim (C191267)
5
•
Complexity:
•
Data size limitations:
•
Performance issues:
•
Data integrity
•
Cost:
•
Inflexibility
Stars, Snowflakes, and Fact Constellations: Schemas for Multidimensional Data Models
Schema is a logical description of the entire database. It includes the name and description of records of all record types including all
associated data-items and aggregates. Much like a database, a data warehouse also requires to maintain a schema. A database uses
relational model, while a data warehouse uses Star, Snowflake, and Fact Constellation schema. In this chapter, we will discuss the
schemas used in a data warehouse.
Star Schema:
• Each dimension in a star schema is represented with only one-dimension table.
• This dimension table contains the set of attributes.
• The following diagram shows the sales data of a company with respect to the four dimensions, namely time, item, branch, and
location.
•
•
There is a fact table at the center. It contains the keys to each of four dimensions.
The fact table also contains the attributes, namely dollars sold and units sold.
Snowflake Schema
• Some dimension tables in the Snowflake schema are normalized.
• The normalization splits up the data into additional tables.
• Unlike Star schema, the dimensions table in a snowflake schema are normalized. For example, the item dimension table in star
schema is normalized and split into two dimension tables, namely item and supplier table.
Tasnim (C191267)
6
•
•
Now the item dimension table contains the attributes item_key, item_name, type, brand, and supplier-key.
The supplier key is linked to the supplier dimension table. The supplier dimension table contains the attributes supplier_key
and supplier_type.
Fact Constellation Schema
• A fact constellation has multiple fact tables. It is also known as galaxy schema.
• The following diagram shows two fact tables, namely sales and shipping.
•
•
•
•
The sales fact table is same as that in the star schema.
The shipping fact table has the five dimensions, namely item_key, time_key, shipper_key, from_location, to_location.
The shipping fact table also contains two measures, namely dollars sold and units sold.
It is also possible to share dimension tables between fact tables. For example, time, item, and location dimension tables are
shared between the sales and shipping fact table.
Extraction, Transformation, and Loading (ETL)
▪ Data extraction
▪ get data from multiple, heterogeneous, and external sources
▪ Data cleaning
▪ detect errors in the data and rectify them when possible
▪ Data transformation
▪ convert data from legacy or host format to warehouse format
▪ Load
▪ sort, summarize, consolidate, compute views, check integrity, and build indicies and partitions
▪ Refresh
▪ propagate the updates from the data sources to the warehouse
2 Classification:
2.1.1 Basic Concepts,
https://www.datacamp.com/blog/classification-machine-learning
2.1.2 Decision Tree Induction,
https://www.softwaretestinghelp.com/decision-tree-algorithm-examples-data-mining/
2.1.3 Bayes Classification Methods,
2.1.3.1
Naïve Bayes Classifier Algorithm
Naïve Bayes algorithm is a supervised learning algorithm, which is based on Bayes theorem and used for solving classification
problems.
It is mainly used in text classification that includes a high-dimensional training dataset.
Naïve Bayes Classifier is one of the simple and most effective Classification algorithms which helps in building the fast machine
learning models that can make quick predictions.
It is a probabilistic classifier, which means it predicts on the basis of the probability of an object.
Some popular examples of Naïve Bayes Algorithm are spam filtration, Sentimental analysis, and classifying articles.
Why is it called Naïve Bayes?
The Naïve Bayes algorithm is comprised of two words Naïve and Bayes, Which can be described as:
Tasnim (C191267)
7
Naïve: It is called Naïve because it assumes that the occurrence of a certain feature is independent of the occurrence of other features.
Such as if the fruit is identified on the bases of color, shape, and taste, then red, spherical, and sweet fruit is recognized as an apple.
Hence each feature individually contributes to identify that it is an apple without depending on each other.
Bayes: It is called Bayes because it depends on the principle of Bayes' Theorem.
Bayes' Theorem:
Bayes' theorem is also known as Bayes' Rule or Bayes' law, which is used to determine the probability of a hypothesis with prior
knowledge. It depends on the conditional probability.
The formula for Bayes' theorem is given as:
Where,
P(A|B) is Posterior probability: Probability of hypothesis A on the observed event B.
P(B|A) is Likelihood probability: Probability of the evidence given that the probability of a hypothesis is true.
P(A) is Prior Probability: Probability of hypothesis before observing the evidence.
P(B) is Marginal Probability: Probability of Evidence.
Working of Naïve Bayes' Classifier:
Working of Naïve Bayes' Classifier can be understood with the help of the below example:
Suppose we have a dataset of weather conditions and corresponding target variable "Play". So using this dataset we need to decide
that whether we should play or not on a particular day according to the weather conditions. So to solve this problem, we need to
follow the below steps:
Convert the given dataset into frequency tables.
Generate Likelihood table by finding the probabilities of given features.
Now, use Bayes theorem to calculate the posterior probability.
Problem: If the weather is sunny, then the Player should play or not?
Solution: To solve this, first consider the below dataset:
0
Outlook
Play
Rainy
Yes
1
Sunny
2
Overcast
3
Overcast
4
Sunny
5
Rainy
6
Sunny
7
Overcast
8
Rainy
9
Sunny
10
Sunny
11
Rainy
12
Overcast
13
Overcast
Frequency table for the Weather Conditions:
Yes
Yes
Yes
No
Yes
Yes
Yes
No
No
Yes
No
Yes
Yes
Weather
Overcast
Rainy
Sunny
Total
Likelihood table weather condition:
Yes
5
2
3
10
Weather
No
Overcast
0
Rainy
2
Sunny
2
All
4/14=0.29
Applying Bayes'theorem:
Yes
5
2
3
10/14=0.71
P(Yes|Sunny)= P(Sunny|Yes)*P(Yes)/P(Sunny)
P(Sunny|Yes)= 3/10= 0.3
P(Sunny)= 0.35
P(Yes)=0.71
Tasnim (C191267)
No
0
2
2
5
5/14= 0.35
4/14=0.29
5/14=0.35
8
So P(Yes|Sunny) = 0.3*0.71/0.35= 0.60
P(No|Sunny)= P(Sunny|No)*P(No)/P(Sunny)
P(Sunny|NO)= 2/4=0.5
P(No)= 0.29
P(Sunny)= 0.35
So P(No|Sunny)= 0.5*0.29/0.35 = 0.41
So as we can see from the above calculation that P(Yes|Sunny)>P(No|Sunny)
Hence on a Sunny day, Player can play the game.
Advantages of Naïve Bayes Classifier:
Naïve Bayes is one of the fast and easy ML algorithms to predict a class of datasets.
It can be used for Binary as well as Multi-class Classifications.
It performs well in Multi-class predictions as compared to the other Algorithms.
It is the most popular choice for text classification problems.
Disadvantages of Naïve Bayes Classifier:
Naive Bayes assumes that all features are independent or unrelated, so it cannot learn the relationship between features.
Applications of Naïve Bayes Classifier:
It is used for Credit Scoring.
It is used in medical data classification.
It can be used in real-time predictions because Naïve Bayes Classifier is an eager learner.
It is used in Text classification such as Spam filtering and Sentiment analysis.
Types of Naïve Bayes Model:
There are three types of Naive Bayes Model, which are given below:
Gaussian: The Gaussian model assumes that features follow a normal distribution. This means if predictors take continuous values
instead of discrete, then the model assumes that these values are sampled from the Gaussian distribution.
Multinomial: The Multinomial Naïve Bayes classifier is used when the data is multinomial distributed. It is primarily used for
document classification problems, it means a particular document belongs to which category such as Sports, Politics, education, etc.
The classifier uses the frequency of words for the predictors.
Bernoulli: The Bernoulli classifier works similar to the Multinomial classifier, but the predictor variables are the independent
Booleans variables. Such as if a particular word is present or not in a document. This model is also famous for document classification
tasks.
2.1.4 Rule-Based Classification,
IF-THEN Rules
Rule-based classifier makes use of a set of IF-THEN rules for classification. We can express a rule in the following from −
IF condition THEN conclusion
Let us consider a rule R1,
R1: IF age = youth AND student = yes
THEN buy_computer = yes
Points to remember −
The IF part of the rule is called rule antecedent or precondition.
The THEN part of the rule is called rule consequent.
The antecedent part the condition consist of one or more attribute tests and these tests are logically ANDed.
The consequent part consists of class prediction.
Note − We can also write rule R1 as follows −
R1: (age = youth) ^ (student = yes))(buys computer = yes)
If the condition holds true for a given tuple, then the antecedent is satisfied.
Rule Extraction
Here we will learn how to build a rule-based classifier by extracting IF-THEN rules from a decision tree.
Points to remember −
To extract a rule from a decision tree −
One rule is created for each path from the root to the leaf node.
To form a rule antecedent, each splitting criterion is logically ANDed.
The leaf node holds the class prediction, forming the rule consequent.
Tasnim (C191267)
9
2.1.5 Model Evaluation and Selection.
https://neptune.ai/blog/ml-model-evaluation-and-selection
3 Classification Advanced Topics:
3.1.1 Techniques to Improve,
3.1.2 classification Accuracy:
3.1.3 Ensemble Methods
Ensemble learning helps improve machine learning results by combining several models. This approach allows the production of
better predictive performance compared to a single model. Basic idea is to learn a set of classifiers (experts) and to allow them to vote.
Advantage: Improvement in predictive accuracy.
Disadvantage: It is difficult to understand an ensemble of classifiers.
Why do ensembles work?
Dietterich(2002) showed that ensembles overcome three problems –
Statistical Problem –
The Statistical Problem arises when the hypothesis space is too large for the amount of available data. Hence, there are many
hypotheses with the same accuracy on the data and the learning algorithm chooses only one of them! There is a risk that the accuracy
of the chosen hypothesis is low on unseen data!
Computational Problem –
The Computational Problem arises when the learning algorithm cannot guarantees finding the best hypothesis.
Representational Problem –
The Representational Problem arises when the hypothesis space does not contain any good approximation of the target class(es).
Main Challenge for Developing Ensemble Models?
The main challenge is not to obtain highly accurate base models, but rather to obtain base models which make different kinds of
errors. For example, if ensembles are used for classification, high accuracies can be accomplished if different base models misclassify
different training examples, even if the base classifier accuracy is low.
Methods for Independently Constructing Ensembles –
Majority Vote
Bagging and Random Forest
Randomness Injection
Feature-Selection Ensembles
Error-Correcting Output Coding
Methods for Coordinated Construction of Ensembles –
Boosting
Stacking
Reliable Classification: Meta-Classifier Approach
Co-Training and Self-Training
Types of Ensemble Classifier –
Bagging:
Bagging (Bootstrap Aggregation) is used to reduce the variance of a decision tree. Suppose a set D of d tuples, at each iteration i, a
training set Di of d tuples is sampled with replacement from D (i.e., bootstrap). Then a classifier model Mi is learned for each training
set D < i. Each classifier Mi returns its class prediction. The bagged classifier M* counts the votes and assigns the class with the most
votes to X (unknown sample).
Implementation steps of Bagging –
Multiple subsets are created from the original data set with equal tuples, selecting observations with replacement.
A base model is created on each of these subsets.
Tasnim (C191267)
10
Each model is learned in parallel from each training set and independent of each other.
The final predictions are determined by combining the predictions from all the models.
Random Forest:
Random Forest is an extension over bagging. Each classifier in the ensemble is a decision tree classifier and is generated using a
random selection of attributes at each node to determine the split. During classification, each tree votes and the most popular class is
returned.
Implementation steps of Random Forest –
Multiple subsets are created from the original data set, selecting observations with replacement.
A subset of features is selected randomly and whichever feature gives the best split is used to split the node iteratively.
The tree is grown to the largest.
Repeat the above steps and prediction is given based on the aggregation of predictions from n number of trees.
3.1.4 Bayesian Belief Networks,
Bayesian Belief Network is a graphical representation of different probabilistic relationships among random variables in a
particular set. It is a classifier with no dependency on attributes i.e it is condition independent. Due to its feature of jo int
probability, the probability in Bayesian Belief Network is derived, based on a condition — P(attribute/parent) i.e probability of an
attribute, true over parent attribute.
(Note: A classifier assigns data in a collection to desired categories.)
•
Consider this example:
In the above figure, we have an alarm ‘A’ – a node, say installed in a house of a person ‘gfg’, which rings upon two
probabilities i.e burglary ‘B’ and fire ‘F’, which are – parent nodes of the alarm node. The alarm is the parent node of
two probabilities P1 calls ‘P1’ & P2 calls ‘P2’ person nodes.
• Upon the instance of burglary and fire, ‘P1’ and ‘P2’ call person ‘gfg’, respectively. But, there are few drawbacks in this
case, as sometimes ‘P1’ may forget to call the person ‘gfg’, even after hearing the alarm, as he has a tendency to forget
things, quick. Similarly, ‘P2’, sometimes fails to call the person ‘gfg’, as he is only able to hear the alarm, from a
certain distance.
Q) Find the probability that ‘P1’ is true (P1 has called ‘gfg’), ‘P2’ is true (P2 has called ‘gfg’) when the alarm ‘A’ rang, but no
burglary ‘B’ and fire ‘F’ has occurred.
•
Tasnim (C191267)
11
=> P ( P1, P2, A, ~B, ~F) [ where- P1, P2 & A are ‘true’ events and ‘~B’ & ‘~F’ are ‘false’ events]
[ Note: The values mentioned below are neither calculated nor computed. They have observed values ]
Burglary ‘B’ –
• P (B=T) = 0.001 (‘B’ is true i.e burglary has occurred)
• P (B=F) = 0.999 (‘B’ is false i.e burglary has not occurred)
Fire ‘F’ –
• P (F=T) = 0.002 (‘F’ is true i.e fire has occurred)
• P (F=F) = 0.998 (‘F’ is false i.e fire has not occurred)
Alarm ‘A’ –
B
F
P (A=T)
P (A=F)
T
T
0.95
0.05
T
F
0.94
0.06
F
T
0.29
0.71
F
F
0.001
0.999
The alarm ‘A’ node can be ‘true’ or ‘false’ ( i.e may have rung or may not have rung). It has two parent nodes burglary
‘B’ and fire ‘F’ which can be ‘true’ or ‘false’ (i.e may have occurred or may not have occurred) depending upon
different conditions.
Person ‘P1’ –
•
A
P (P1=T)
P (P1=F)
T
0.95
0.05
F
0.05
0.95
The person ‘P1’ node can be ‘true’ or ‘false’ (i.e may have called the person ‘gfg’ or not) . It has a parent node, the
alarm ‘A’, which can be ‘true’ or ‘false’ (i.e may have rung or may not have rung ,upon burglary ‘B’ or fire ‘F’).
Person ‘P2’ –
•
A
P (P2=T)
P (P2=F)
T
0.80
0.20
F
0.01
0.99
The person ‘P2’ node can be ‘true’ or false’ (i.e may have called the person ‘gfg’ or not). It has a parent node, the alarm
‘A’, which can be ‘true’ or ‘false’ (i.e may have rung or may not have rung, upon burglary ‘B’ or fire ‘F’).
Solution: Considering the observed probabilistic scan –
With respect to the question — P ( P1, P2, A, ~B, ~F) , we need to get the probability of ‘P1’. We find it with regard to its parent
node – alarm ‘A’. To get the probability of ‘P2’, we find it with regard to its parent node — alarm ‘A’.
We find the probability of alarm ‘A’ node with regard to ‘~B’ & ‘~F’ since burglary ‘B’ and fire ‘F’ are parent nodes of alar m ‘A’.
•
From the observed probabilistic scan, we can deduce –
P ( P1, P2, A, ~B, ~F)
= P (P1/A) * P (P2/A) * P (A/~B~F) * P (~B) * P (~F)
= 0.95 * 0.80 * 0.001 * 0.999 * 0.998
= 0.00075
3.1.5 Classification by Backpropagation,
backpropagation:
Backpropagation is a widely used algorithm for training feedforward neural networks. It computes the gradient of the loss function
with respect to the network weights. It is very efficient, rather than naively directly computing the gradient concerning each weight.
This efficiency makes it possible to use gradient methods to train multi-layer networks and update weights to minimize loss; variants
such as gradient descent or stochastic gradient descent are often used.
The backpropagation algorithm works by computing the gradient of the loss function with respect to each weight via the chain rule,
computing the gradient layer by layer, and iterating backward from the last layer to avoid redundant computation of intermediate terms
in the chain rule.
Features of Backpropagation:
•
•
•
•
•
it is the gradient descent method as used in the case of simple perceptron network with the differentiable unit.
it is different from other networks in respect to the process by which the weights are calculated during the learning period of
the network.
training is done in the three stages :
the feed-forward of input training pattern
the calculation and backpropagation of the errorupdation of the weight
Tasnim (C191267)
12
Working of Backpropagation:
Neural networks use supervised learning to generate output vectors from input vectors that the network operates on. It Compares
generated output to the desired output and generates an error report if the result does not match the generated output vector. Then it
adjusts the weights according to the bug report to get your desired output.
Backpropagation Algorithm:
Step 1: Inputs X, arrive through the preconnected path.
Step 2: The input is modeled using true weights W. Weights are usually chosen randomly.
Step 3: Calculate the output of each neuron from the input layer to the hidden layer to the output layer.
Step 4: Calculate the error in the outputs
Backpropagation Error= Actual Output – Desired Output
Step 5: From the output layer, go back to the hidden layer to adjust the weights to reduce the error.
Step 6: Repeat the process until the desired output is achieved.
Parameters :
x = inputs training vector x=(x1,x2,…………xn).
t = target vector t=(t1,t2……………tn).
δk = error at output unit.
δj = error at hidden layer.
α = learning rate.
V0j = bias of hidden unit j.
Training Algorithm :
Step 1: Initialize weight to small random values.
Step 2: While the stepsstopping condition is to be false do step 3 to 10.
Step 3: For each training pair do step 4 to 9 (Feed-Forward).
Step 4: Each input unit receives the signal unit and transmitsthe signal xi signal to all the units.
Step 5 : Each hidden unit Zj (z=1 to a) sums its weighted input signal to calculate its net input
zinj = v0j + Σxivij
( i=1 to n)
Applying activation function zj = f(zinj) and sends this signals to all units in the layer about i.e output units
For each output l=unit yk = (k=1 to m) sums its weighted input signals.
yink = w0k + Σ ziwjk
(j=1 to a)
and applies its activation function to calculate the output signals.
yk = f(yink)
Backpropagation Error :
Step 6: Each output unit yk (k=1 to n) receives a target pattern corresponding to an input pattern then error is calculated as:
δk = ( tk – yk ) + yink
Tasnim (C191267)
13
Step 7: Each hidden unit Zj (j=1 to a) sums its input from all units in the layer above
δinj = Σ δj wjk
The error information term is calculated as :
δj = δinj + zinj
Updation of weight and bias :
Step 8: Each output unit yk (k=1 to m) updates its bias and weight (j=1 to a). The weight correction term is given by :
Δ wjk = α δk zj
and the bias correction term is given by Δwk = α δk.
therefore wjk(new) = wjk(old) + Δ wjk
w0k(new) = wok(old) + Δ wok
for each hidden unit zj (j=1 to a) update its bias and weights (i=0 to n) the weight connection term
Δ vij = α δj xi
and the bias connection on term
Δ v0j = α δj
Therefore vij(new) = vij(old) + Δvij
v0j(new) = v0j(old) + Δv0j
Step 9: Test the stopping condition. The stopping condition can be the minimization of error, number of epochs.
Need for Backpropagation:
Backpropagation is “backpropagation of errors” and is very useful for training neural networks. It’s fast, easy to implement, and
simple. Backpropagation does not require any parameters to be set, except the number of inputs. Backpropagation is a flexible method
because no prior knowledge of the network is required.
Types of Backpropagation
There are two types of backpropagation networks.
Static backpropagation: Static backpropagation is a network designed to map static inputs for static outputs. These types of networks
are capable of solving static classification problems such as OCR (Optical Character Recognition).
Recurrent backpropagation: Recursive backpropagation is another network used for fixed-point learning. Activation in recurrent
backpropagation is feed-forward until a fixed value is reached. Static backpropagation provides an instant mapping, while recurrent
backpropagation does not provide an instant mapping.
Advantages:
It is simple, fast, and easy to program.
Only numbers of the input are tuned, not any other parameter.
It is Flexible and efficient.
No need for users to learn any special functions.
Disadvantages:
It is sensitive to noisy data and irregularities. Noisy data can lead to inaccurate results.
Performance is highly dependent on input data.
Spending too much time training.
The matrix-based approach is preferred over a mini-batch.
https://www.javatpoint.com/pytorch-backpropagation-process-in-deep-neural-network
3.1.6 Support Vector Machines,
https://www.geeksforgeeks.org/support-vector-machine-algorithm/
https://www.javatpoint.com/machine-learning-support-vector-machine-algorithm
3.1.7 Lazy Learners (or Learning from Your Neighbors):
KNN is often referred to as a lazy learner. This means that the algorithm does not use the training data points to do any generalizations. In other
words, there is no explicit training phase. Lack of generalization means that KNN keeps all the training data. It is a non-parametric learning
algorithm because it doesn’t assume anything about the underlying data. Leazy learning is also known as instance-based learning and memorybased learning. It postpones most of the processing and computation until a query or prediction request.
Here, the algorithm stores the training data set in its original form without deriving general rules from it. When we have a new object to process,
the algorithm searches the training data for the most similar objects and uses them to produce the output, like the k-nearest neighbors (kNN)
algorithm:
Tasnim (C191267)
14
In the example above, kNN classifies an unknown point by checking its neighborhood when it arrives as the input.
Difference between eager and lazy learners in data mining
https://www.baeldung.com/cs/lazy-vs-eager-learning
3.1.8 Other Classification Methods
4 Cluster Analysis:
4.1.1 Basic Concepts,
What Is Cluster Analysis?
Cluster analysis or simply clustering is the process of partitioning a set of data objects (or observations) into subsets. Each subset is a
cluster, such that objects in a cluster are similar to one another, yet dissimilar to objects in other clusters. The set of clusters resulting
from a cluster analysis can be referred to as a clustering. In this context, different clustering methods may generate different
clustering on the same data set. The partitioning is not performed by humans, but by the clustering algorithm. Hence, clustering is
useful in that it can lead to the discovery of previously unknown groups within the data.
The basic concept of clustering in data mining is to group similar data objects together based on their characteristics or
attributes.
However, there are several requirements that need to be addressed for effective clustering:
1. Scalability: Clustering algorithms should be able to handle large datasets containing millions or billions of objects. Scalable
algorithms are necessary to avoid biased results that may occur when clustering on a sample of the data.
2. Handling Different Types of Attributes: Clustering algorithms should be able to handle various types of data, including
numeric, binary, nominal, ordinal, and complex data types such as graphs, sequences, images, and documents.
3. Discovery of Clusters with Arbitrary Shape: Algorithms should be capable of detecting clusters of any shape, not just spherical
clusters. This is important when dealing with real-world scenarios where clusters can have diverse and non-standard shapes.
4. Reduced Dependency on Domain Knowledge: Clustering algorithms should minimize the need for users to provide domain
knowledge and input parameters. The quality of clustering should not heavily rely on user-defined parameters, which can be
challenging to determine, especially for high-dimensional datasets.
5. Robustness to Noisy Data: Clustering algorithms should be robust to outliers, missing data, and errors commonly found in realworld datasets. Noise in the data should not significantly impact the quality of the resulting clusters.
6. Incremental Clustering and Insensitivity to Input Order: Algorithms should be capable of incorporating incremental updates
and new data into existing clustering structures without requiring a complete recomputation. Additionally, the order in which
data objects are presented should not drastically affect the resulting clustering.
7. Capability of Clustering High-Dimensionality Data: Clustering algorithms should be able to handle datasets with a large
number of dimensions or attributes, even in cases where the data is sparse and highly skewed.
8. Constraint-Based Clustering: Clustering algorithms should be able to consider and satisfy various constraints imposed by realworld applications. Constraints may include spatial constraints, network constraints, or specific requirements related to the
clustering task.
9. Interpretability and Usability: Clustering results should be interpretable, comprehensible, and usable for users. Clustering
should be tied to specific semantic interpretations and application goals, allowing users to understand and apply the results
effectively.
These requirements highlight the challenges and considerations involved in developing clustering algorithms that can effectively
analyze and group data objects based on their similarities and characteristics.
4.1.2 Partitioning Methods,
The simplest and most fundamental version of cluster analysis is partitioning, which organizes the objects of a set into several
exclusive groups or clusters. To keep the problem specification concise, we can assume that the number of clusters is given as
Tasnim (C191267)
15
background knowledge. This parameter is the starting point for partitioning methods. Formally, given a data set, D, of n objects, and k,
the number of clusters to form, a partitioning algorithm organizes the objects into k partitions (k ≤ n), where each partition represents
a cluster. The clusters are formed to optimize an objective partitioning criterion, such as a dissimilarity function based on distance, so
that the objects within a cluster are “similar” to one another and “dissimilar” to objects in other clusters in terms of the data set
attributes.
The most well-known and commonly used partitioning methods are
▪
The k-Means Method
▪
k-Medoids Method
Centroid-Based Technique:
The K-Means Method The k-means algorithm takes the input parameter, k, and partitions a set of n objects intok clusters so that the resulting
intracluster similarity is high but the inter cluster similarity is low. Cluster similarity is measured in regard to the mean value of the objects in a
cluster, which can be viewed as the cluster’s centroid or center of gravity. The k-means algorithm proceeds as follows
▪
▪
▪
▪
First, it randomly selects k of the objects, each of which initially represents a cluster mean or center.
For each of the remaining objects, an object is assigned to the cluster to which it is the most similar, based on the distance
between the object and the cluster mean
It then computes the new mean for each cluster.
This process iterates until the criterion function converges.
Typically, the square-error criterion is used, defined as
where E is the sum of the square error for all objects in the data set p is the point in space representing a given object mi is the mean of
cluster Ci
The k-means partitioning algorithm: The k-means algorithm for partitioning, where each cluster’s center is represented by the mean
value of the objects in the cluster.
Clustering of a set of objects based on the k-means method
The k-Medoids Method
The k-means algorithm is sensitive to outliers because an object with an extremely large value may substantially distort the distribution
of data. This effect is particularly exacerbated due to the use of the square-error function. Instead of taking the mean value of the objects
in a cluster as a reference point, we can pick actual objects to represent the clusters, using one representative object per cluster.
Each remaining object is clustered with the representative object to which it is the most similar The partitioning method is then performed
based on the principle of minimizing the sum of the dissimilarities between each object and its corresponding reference point. That is,
an absolute-error criterion is used, defined as
where E is the sum of the absolute error for all objects in the data set p is the point in space representing a given object in cluster Cj oj
is the representative object of Cj The initial representative objects are chosen arbitrarily.
The iterative process of replacing representative objects by non representative objects continues as long as the quality of the resulting
clustering is improved. This quality is estimated using a cost function that measures the average dissimilarity between an object and the
representative object of its cluster. To determine whether a non representative object, oj random, is a good replacement for a current
Tasnim (C191267)
16
representative
object,
oj,
the
following
four
cases
are
examined
for
each
of
the
non
representative
objects.
Case 1: p currently belongs to representative object, oj. If ojis replaced by orandomasa representative object and p is closest to one of
the other
representative objects, oi,i≠j, then p is reassigned to oi.
Case 2: p currently belongs to representative object, oj. If ojis replaced by o random as a representative object and p is closest to o
random, then p is reassigned to o random.
Case 3: p currently belongs to representative object, oi, i≠j. If oj is replaced by o random as a representative object and p is still closest
to oi, then the assignment does not change.
Case 4: p currently belongs to representative object, oi, i≠j. If ojis replaced by o randomas a representative object and p is closest to o
random, then p is reassigned to o random.
The k-Medoids Algorithm: The k-medoids algorithm for partitioning based on medoid or central objects.
https://educatech.in/classical-partitioning-methods-in-data-mining
4.1.3 Hierarchical Methods
https://www.saedsayad.com/clustering_hierarchical.htm
4.1.3.1 Hierarchical Clustering
Hierarchical clustering involves creating clusters that have a predetermined ordering from top to bottom. For example, all files and folders on the
hard disk are organized in a hierarchy. There are two types of hierarchical clustering, Divisive and Agglomerative.
Divisive method
In divisive or top-down clustering method we assign all of the observations to a single cluster and then partition the cluster to two least similar
clusters using a flat clustering method (e.g., K-Means). Finally, we proceed recursively on each cluster until there is one cluster for each observation.
There is evidence that divisive algorithms produce more accurate hierarchies than agglomerative algorithms in some circumstances but is
conceptually more complex.
Tasnim (C191267)
17
Agglomerative method
In agglomerative or bottom-up clustering method we assign each observation to its own cluster. Then, compute the similarity (e.g., distance)
between each of the clusters and join the two most similar clusters. Finally, repeat steps 2 and 3 until there is only a single cluster left. The related
algorithm is shown below.
Before any clustering is performed, it is required to determine the proximity matrix containing the distance between each point using a distance
function. Then, the matrix is updated to display the distance between each cluster. The following three methods differ in how the distance between
each cluster is measured.
Single Linkage
In single linkage hierarchical clustering, the distance between two clusters is defined as the shortest distance between two points in each cluster.
For example, the distance between clusters “r” and “s” to the left is equal to the length of the arrow between their two closest points.
Complete Linkage
In complete linkage hierarchical clustering, the distance between two clusters is defined as the longest distance between two points in each cluster.
For example, the distance between clusters “r” and “s” to the left is equal to the length of the arrow between their two furthest points.
Average Linkage
In average linkage hierarchical clustering, the distance between two clusters is defined as the average distance between each point in one cluster to
every point in the other cluster. For example, the distance between clusters “r” and “s” to the left is equal to the average length each arrow
between connecting the points of one cluster to the other.
Tasnim (C191267)
18
Example: Clustering the following 7 data points.
X1
X2
A
10
5
B
1
4
C
5
8
D
9
2
E
12
10
F
15
8
G
7
7
Step 1: Calculate distances between all data points using Euclidean distance function. The shortest distance is between data points C and G.
A
B
C
D
E
B
9.06
C
5.83
5.66
D
3.16
8.25
E
5.39 12.53
F
5.83 14.56 10.00 16.16
3.61
G
3.61
5.83
F
7.21
7.28 14.42
6.71
2.24
8.60
8.06
Step 2: We use "Average Linkage" to measure the distance between the "C,G" cluster and other data points.
A
B
C,G
D
B
9.06
C,G
4.72
6.10
D
3.16
8.25
E
5.39
12.53
6.50 14.42
F
5.83
14.56
9.01 16.16
Step 3:
Tasnim (C191267)
E
6.26
3.61
19
A,D
B
C,G
B
8.51
C,G
5.32
6.10
E
6.96
12.53
6.50
F
7.11
14.56
9.01
E
3.61
Step 4:
A,D
B
C,G
B
8.51
C,G
5.32
6.10
E,F
6.80
13.46
Step 5:
A,D,C,G
B
B
6.91
E,F
6.73
Step 6:
A,D,C,G,E,F
B
Final dendrogram:
Tasnim (C191267)
9.07
13.46
7.65
20
4.1.4 Density-Based Methods deletion.
What is Density-based clustering?
Density-Based Clustering refers to one of the most popular unsupervised learning methodologies used in model building and machine
learning algorithms. The data points in the region separated by two clusters of low point density are considered as noise. The
surroundings with a radius ε of a given object are known as the ε neighborhood of the object. If the ε neighborhood of the object
comprises at least a minimum number, MinPts of objects, then it is called a core object.
https://www.javatpoint.com/density-based-clustering-in-data-mining
5 Segment 5
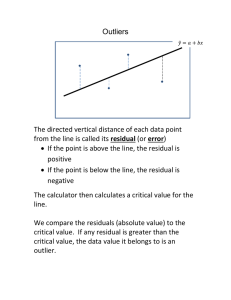
5.1 Outliers Detection and Analysis:
an outlier is an object that deviates significantly from the rest of the objects. They can be caused by measurement or execution
error. The analysis of outlier data is referred to as outlier analysis or outlier mining.
Why outlier analysis?
Most data mining methods discard outliers’ noise or exceptions, however, in some applications such as fraud detection, the rare
events can be more interesting than the more regularly occurring one and hence, the outlier analysis becomes important in suc h
case.
Why Should You Detect Outliers?
In the machine learning pipeline, data cleaning and preprocessing is an important step as it helps you better understand the data.
During this step, you deal with missing values, detect outliers, and more.
As outliers are very different values—abnormally low or abnormally high—their presence can often skew the results of statistical
analyses on the dataset. This could lead to less effective and less useful models.
But dealing with outliers often requires domain expertise, and none of the outlier detection techniques should be applied without
understanding the data distribution and the use case.
For example, in a dataset of house prices, if you find a few houses priced at around $1.5 million—much higher than the median house
price, they’re likely outliers. However, if the dataset contains a significantly large number of houses priced at $1 million and above—
they may be indicative of an increasing trend in house prices. So it would be incorrect to label them all as outliers. In this case, you
need some knowledge of the real estate domain.
The goal of outlier detection is to remove the points—which are truly outliers—so you can build a model that performs well on unseen
test data. We’ll go over a few techniques that’ll help us detect outliers in data.
How to Detect Outliers Using Standard Deviation
When the data, or certain features in the dataset, follow a normal distribution, you can use the standard deviation of the data, or the
equivalent z-score to detect outliers.
In statistics, standard deviation measures the spread of data around the mean, and in essence, it captures how far away from the mean
the data points are.
For data that is normally distributed, around 68.2% of the data will lie within one standard deviation from the mean. Close to 95.4%
and 99.7% of the data lie within two and three standard deviations from the mean, respectively.
Let’s denote the standard deviation of the distribution by σ, and the mean by μ.
One approach to outlier detection is to set the lower limit to three standard deviations below the mean (μ - 3*σ), and the upper limit to
three standard deviations above the mean (μ + 3*σ). Any data point that falls outside this range is detected as an outlier.
As 99.7% of the data typically lies within three standard deviations, the number of outliers will be close to 0.3% of the size of the
dataset.
5.2 Outliers Detection Methods
Outlier detection methods can be categorized in two orthogonal ways: based on the availability of domain expert-labeled data and
based on assumptions about normal objects versus outliers. Let's summarize each category and provide an example for each model:
Categorization based on the availability of labeled data:
Tasnim (C191267)
21
a. Supervised Methods: If expert-labeled examples of normal and/or outlier objects are available, supervised methods can be used.
These methods model data normality and abnormality as a classification problem. For example, a domain expert labels a sample of
data as either normal or outlier, and a classifier is trained to recognize outliers based on these labels.
Example: In credit card fraud detection, historical transactions are labeled as normal or fraudulent by domain experts. A supervised
method can be trained to classify new transactions as either normal or fraudulent based on the labeled training data.
b. Unsupervised Methods: When labeled examples are not available, unsupervised methods are used. These methods assume that
normal objects follow a pattern more frequently than outliers. The goal is to identify objects that deviate significantly from the
expected patterns.
Example: In network intrusion detection, normal network traffic is expected to follow certain patterns. Unsupervised methods can
analyze network traffic data and identify deviations from these patterns as potential intrusions.
c. Semi-Supervised Methods: In some cases, a small set of labeled data is available, but most of the data is unlabeled. Semi-supervised
methods combine the use of labeled and unlabeled data to build outlier detection models.
Example: In anomaly detection for manufacturing processes, some labeled normal samples may be available, along with a large
amount of unlabeled data. Semi-supervised methods can leverage the labeled samples and neighboring unlabeled data to detect
anomalies in the manufacturing process.
Categorization based on assumptions about normal objects versus outliers:
a. Statistical Methods: Statistical or model-based methods assume that normal data objects are generated by a statistical model, and
objects not following the model are considered outliers. These methods estimate the likelihood of an object being generated by the
model.
Example: Using a Gaussian distribution as a statistical model, objects falling into regions with low probability density can be
considered outliers.
b. Proximity-Based Methods: Proximity-based methods identify outliers based on the proximity of an object to its neighbors in feature
space. If an object's neighbors are significantly different from the neighbors of most other objects, it can be classified as an outlier.
Example: By considering the nearest neighbors of an object, if its proximity to these neighbors deviates significantly from the
proximity of other objects, it can be identified as an outlier.
c. Clustering-Based Methods: Clustering-based methods assume that normal data objects belong to large and dense clusters, while
outliers belong to small or sparse clusters or do not belong to any cluster at all.
Example: If a clustering algorithm identifies a small cluster or data points that do not fit into any cluster, these points can be
considered outliers.
These are general categories of outlier detection methods, and there are numerous specific algorithms and techniques within each
category. The examples provided illustrate the application of each method in different domains, highlighting their utilization in outlier
detection.
5.2.1
Mining Contextual and Collective
Contextual outlier
The main concept of contextual outlier detection is to identify objects in a dataset that deviate significantly within a specific context. Contextual
attributes, such as spatial attributes, time, network locations, and structured attributes, define the context in which outliers are evaluated.
Behavioral attributes, on the other hand, determine the characteristics of an object and are used to assess its outlier status within its context.
There are two categories of methods for contextual outlier detection based on the identification of contexts:
1. Transforming Contextual Outlier Detection to Conventional Outlier Detection: In situations where contexts can be clearly identified, this
method involves transforming the contextual outlier detection problem into a standard outlier detection problem. The process involves
two steps. First, the context of an object is identified using contextual attributes. Then, the outlier score for the object within its context
is calculated using a conventional outlier detection method.
For example, in customer-relationship management, outlier customers can be detected within the context of customer groups. By grouping
customers based on contextual attributes like age group and postal code, comparisons can be made within the same group using conventional
outlier detection techniques.
2. Modeling Normal Behavior with Respect to Contexts: In applications where it is difficult to explicitly partition the data into contexts, this
method focuses on modeling the normal behavior of objects with respect to their contexts. A training dataset is used to train a model
that predicts the expected behavior attribute values based on contextual attribute values. To identify contextual outliers, the model is
applied to the contextual attributes of an object, and if its behavior attribute values significantly deviate from the predicted values, it is
considered an outlier.
For instance, in an online store recording customer browsing behavior, the goal may be to detect contextual outliers when a customer purchases
a product unrelated to their recent browsing history. A prediction model can be trained to link the browsing context with the expected behavior,
and deviations from the predicted behavior can indicate contextual outliers.
In summary, contextual outlier detection expands upon conventional outlier detection by considering the context in which objects are evaluated.
By incorporating contextual information, outliers that cannot be detected otherwise can be identified, and false alarms can be reduced.
Contextual attributes play a crucial role in defining the context, and various methods, such as transforming the problem or modeling normal
behavior, can be employed based on the availability and identification of contexts.
Collective outlier:
Collective outlier detection aims to identify groups of data objects that, as a whole, deviate significantly from the entire dataset. It involves
examining the structure of the dataset and relationships between multiple data objects. There are two main approaches for collective outlier
detection:
Tasnim (C191267)
22
Reducing to Conventional Outlier Detection: This approach identifies structure units within the data, such as subsequences, local areas, or
subgraphs. Each structure unit is treated as a data object, and features are extracted from them. The problem is then transformed into outlier
detection on the set of structured objects. A structure unit is considered a collective outlier if it deviates significantly from the expected trend in
the extracted features.
Modeling Expected Behavior of Structure Units: This approach directly models the expected behavior of structure units. For example, a Markov
model can be learned from temporal sequences. Subsequences that deviate significantly from the model are considered collective outliers.
The structures in collective outlier detection are often not explicitly defined and need to be discovered during the outlier detection process. This
makes it more challenging than conventional and contextual outlier detection. The exploration of data structures relies on heuristics and can be
application-dependent.
Overall, collective outlier detection is a complex task that requires further research and development.
Outlier detection process:
The outlier detection process involves identifying and flagging data objects that deviate significantly from the expected patterns or
behaviors of the majority of the dataset. While the specific steps may vary depending on the approach or algorithm used, the general
outlier detection process can be outlined as follows:
1. Data Preparation: This step involves collecting and preparing the dataset for outlier detection. It may include data cleaning,
normalization, and handling missing values or outliers that are already known.
2. Feature Selection/Extraction: Relevant features or attributes are selected or extracted from the dataset to represent the
characteristics of the data objects. Choosing appropriate features is crucial for effective outlier detection.
3. Define the Expected Normal Behavior: The next step is to establish the expected normal behavior or patterns of the data
objects. This can be done through statistical analysis, domain knowledge, or learning from a training dataset.
4. Outlier Detection Algorithm/Application: An outlier detection algorithm or technique is applied to the dataset to identify
potential outliers. There are various approaches available, including statistical methods (e.g., z-score, boxplot), distance-based
methods (e.g., k-nearest neighbors), density-based methods (e.g., DBSCAN), and machine learning-based methods (e.g.,
isolation forest, one-class SVM).
5. Outlier Score/Threshold: Each data object is assigned an outlier score or measure indicating its degree of deviation from the
expected behavior. The outlier score can be based on distance, density, probability, or other statistical measures. A threshold
value is set to determine which objects are considered outliers based on their scores.
6. Outlier Identification/Visualization: Objects with outlier scores exceeding the threshold are identified as outliers. They can be
flagged or labeled for further analysis. Visualization techniques, such as scatter plots, heatmaps, or anomaly maps, can be used
to visually explore and interpret the detected outliers.
7. Validation/Evaluation: The detected outliers should be validated and evaluated to assess their significance and impact. This
may involve domain experts reviewing the flagged outliers, conducting further analysis, or performing outlier impact analysis
on the overall system or process.
8. Iteration and Refinement: The outlier detection process may require iterations and refinements based on feedback, domain
knowledge, or additional data. This allows for continuous improvement and adaptation to changing data patterns or
requirements.
It's important to note that outlier detection is a complex task, and the effectiveness of the process depends on the quality of the data,
the selection of appropriate features, and the choice of an appropriate outlier detection method for the specific dataset and application.
Why outlier can be more important than normal data?
Let's consider a dataset representing monthly sales revenue for a retail company over the course of a year. The dataset contains 12 data
points, one for each month.
Normal Data: January: $10,000 February: $12,000 March: $11,000 April: $10,500 May: $10,200 June: $10,300 July: $10,400 August:
$10,100 September: $10,200 October: $10,100 November: $10,000 December: $10,300
Outlier Data: January: $10,000 February: $12,000 March: $11,000 April: $10,500 May: $10,200 June: $10,300 July: $10,400 August:
$10,100 September: $10,200 October: $10,100 November: $10,000 December: $100,000
In this example, the normal data represents the regular monthly sales revenue for the retail company. These values are consistent,
within a certain range, and can be considered as the expected or typical sales figures.
However, in December, there is an outlier data point where the sales revenue is $100,000, which is significantly higher than the other
months. This can be due to a variety of reasons, such as a one-time large order from a major client, a seasonal spike in sales, or an
error in data entry.
Now, let's analyze why this outlier can be more important than the normal data:
1. Financial Impact: The outlier value of $100,000 represents a substantial increase in sales revenue compared to the normal
monthly figures. This can have a significant positive impact on the company's financial performance for the year, contributing
to higher profits, improved cash flow, and potentially influencing important financial decisions.
2. Decision Making: The outlier value can influence strategic decisions within the company. For example, if the company is
considering expansion, investment in marketing campaigns, or allocating resources for the upcoming year, the exceptional
sales revenue in December would carry more weight and influence these decisions.
3. Performance Evaluation: In performance evaluations and goal setting, the outlier value can significantly affect assessments and
targets. For instance, if the company's sales team has monthly targets based on the normal data, the outlier value in December
might lead to adjustments in expectations, incentives, or bonuses.
4. Anomaly Detection: Identifying and understanding the cause of the outlier value is crucial. It could be indicative of underlying
factors that need attention, such as unusual market conditions, customer behavior, or operational inefficiencies. Addressing and
managing these factors can help maintain or replicate the outlier's positive impact in future periods.
Tasnim (C191267)
23
5. Industry Comparison: Outliers can also be important when comparing performance against industry benchmarks or
competitors. In this case, if the company's December sales revenue significantly exceeds industry norms, it could signify a
competitive advantage, market dominance, or differentiation in the industry.
In summary, the outlier value of $100,000 in December represents a significant deviation from the normal monthly sales revenue. It
can have a substantial impact on financial performance, decision making, goal setting, anomaly detection, and industry positioning.
Understanding and leveraging the insights from this outlier value can be crucial for the company's success and growth.
OR,
Outliers can be more important than normal data in certain contexts due to the following reasons:
Anomalies and Errors: Outliers often represent unusual or unexpected events, errors, or anomalies in the data. They can indicate data
quality issues, measurement errors, or abnormal behavior that needs attention. Identifying and addressing these outliers can improve
data integrity and the overall quality of analysis or decision-making.
Critical Events: Outliers may correspond to critical events or situations that have a significant impact on the system or process being
analyzed. These events could include rare occurrences, extreme values, or exceptional behavior that require special attention. By
identifying and understanding these outliers, appropriate actions can be taken to mitigate risks or leverage opportunities associated
with such events.
Fraud and Security: Outliers can be indicative of fraudulent activities, security breaches, or malicious behavior. Detecting outliers in
financial transactions, network traffic, or user behavior can help identify potential fraud, intrusion attempts, or other security threats.
Early detection and intervention can minimize the impact of these incidents and protect the integrity of systems or processes.
Unexplored Insights: Outliers often represent data points that do not conform to typical patterns or expected behaviors. Exploring and
analyzing these outliers can provide valuable insights and uncover hidden relationships, trends, or new knowledge. Outliers may lead
to the discovery of new market segments, innovative ideas, or scientific breakthroughs that were previously unknown or unexplored.
Decision-making and Optimization: Outliers can influence decision-making processes and optimization strategies. In certain cases,
outliers may represent exceptional or unique situations that require specific treatment or tailored approaches. Ignoring outliers or
treating them as noise can lead to suboptimal decisions or missed opportunities for improvement.
Monitoring and Control: Outliers can serve as signals for monitoring and control systems. By continuously monitoring data streams or
processes for outliers, it becomes possible to detect deviations from expected norms and trigger timely interventions or adjustments.
This proactive approach helps maintain system performance, prevent failures, and ensure operational efficiency.
It is important to note that not all outliers are equally important or require immediate action. The significance of an outlier depends on
the specific domain, problem context, and desired outcomes. Careful analysis, domain knowledge, and expert judgment are necessary
to determine the importance of outliers and decide on appropriate actions based on their impact and relevance to the problem at hand.
6 From class lecture:
6.1 K-Nearest Neighbor (KNN) Algorithm for Machine Learning
o
K-Nearest Neighbour is one of the simplest Machine Learning algorithms based on Supervised Learning technique.
o
K-NN algorithm assumes the similarity between the new case/data and available cases and put the new case into the category that is
most similar to the available categories.
o
K-NN algorithm stores all the available data and classifies a new data point based on the similarity. This means when new data appears
then it can be easily classified into a well suite category by using K- NN algorithm.
o
K-NN algorithm can be used for Regression as well as for Classification but mostly it is used for the Classification problems.
o
K-NN is a non-parametric algorithm, which means it does not make any assumption on underlying data.
o
It is also called a lazy learner algorithm because it does not learn from the training set immediately instead it stores the dataset and at
the time of classification, it performs an action on the dataset.
o
KNN algorithm at the training phase just stores the dataset and when it gets new data, then it classifies that data into a category that is
much similar to the new data.
o
Example: Suppose, we have an image of a creature that looks similar to cat and dog, but we want to know either it is a cat or dog. So for
this identification, we can use the KNN algorithm, as it works on a similarity measure. Our KNN model will find the similar features of the
new data set to the cats and dogs images and based on the most similar features it will put it in either cat or dog category.
o
Why do we need a K-NN Algorithm?
Tasnim (C191267)
24
Suppose there are two categories, i.e., Category A and Category B, and we have a new data point x1, so this data point will lie in which of these
categories. To solve this type of problem, we need a K-NN algorithm. With the help of K-NN, we can easily identify the category or class of a
particular dataset. Consider the below diagram:
o
How does K-NN work?
The K-NN working can be explained on the basis of the below algorithm:
o
Step-1: Select the number K of the neighbors
o
Step-2: Calculate the Euclidean distance of K number of neighbors
o
Step-3: Take the K nearest neighbors as per the calculated Euclidean distance.
o
Step-4: Among these k neighbors, count the number of the data points in each category.
o
Step-5: Assign the new data points to that category for which the number of the neighbor is maximum.
o
Step-6: Our model is ready.
Suppose we have a new data point and we need to put it in the required category. Consider the below image:
o
Firstly, we will choose the number of neighbors, so we will choose the k=5.
o
Next, we will calculate the Euclidean distance between the data points. The Euclidean distance is the distance between two points,
which we have already studied in geometry. It can be calculated as:
o
By calculating the Euclidean distance we got the nearest neighbors, as three nearest neighbors in category A and two nearest neighbors
in category B. Consider the below image:
Tasnim (C191267)
25
o
As we can see the 3 nearest neighbors are from category A, hence this new data point must belong to category A.
o
How to select the value of K in the K-NN Algorithm?
Below are some points to remember while selecting the value of K in the K-NN algorithm:
o
There is no particular way to determine the best value for "K", so we need to try some values to find the best out of them. The most
preferred value for K is 5.
o
A very low value for K such as K=1 or K=2, can be noisy and lead to the effects of outliers in the model.
o
Large values for K are good, but it may find some difficulties.
o
Advantages of KNN Algorithm:
o
It is simple to implement.
o
It is robust to the noisy training data
o
It can be more effective if the training data is large.
o
Disadvantages of KNN Algorithm:
o
Always needs to determine the value of K which may be complex some time.
o
The computation cost is high because of calculating the distance between the data points for all the training samples.
6.2 Apriori vs FP-Growth in Market Basket Analysis – A Comparative Guide
Apriori is a Join-Based algorithm and FP-Growth is Tree-Based algorithm for frequent itemset mining or frequent pattern mining for
market basket analysis.
various machine learning concepts are used to make things easier and profitable. When it comes to marketing strategies it becomes
very important to learn the behaviour of different customers regarding different products and services. It can be any kind of product or
service the provider needs to satisfy the customers to make more and more profits. Machine learning algorithms are now capable of
making inferences about consumer behaviour. Using these inferences a provider can indirectly influence any customer to buy more
than he wants.
Arranging items in a supermarket to recommend related products on E-Commerce platforms can affect the profit level for providers
and satisfaction level for consumers. This arrangement can be done mathematically or using some algorithms. In this article we are
going to discuss the two most basic algorithms of market basket analysis, one is Apriori and the other one is FP-Growth. The major
points to be discussed in this article are listed below.
Table of content
Association Rule Learning
Frequent Itemset Mining(FIM)
Apriori
FP-Growth
Comparing Apriori and FP-Growth
Let us understand these concepts in detail.
Association Rule Learning
In machine learning, association rule learning is a method of finding interesting relationships between the variables in a large dataset.
This concept is mainly used by supermarkets and multipurpose e-commerce websites. Where it is used for defining the patterns of
selling different products. More formally we can say it is useful to extract strong riles from a large database using any measure of
interestingness.
In supermarkets, association rules are used for discovering the regularities between the products where the transaction of the products
are on a large scale. For example, the rule {comb, hair oil}→{mirror} represents that if a customer is buying comb and hair oil
together then there are higher chances that he will buy the mirror also. Such rules can play a major role in marketing strategies.
Let’s go through an example wherein in a small database we have 5 transactions and 5 products like the following.
transaction
product1
product2
product3
product4
product5
1
1
1
0
0
0
2
0
0
1
0
0
3
0
0
0
1
1
4
1
1
1
0
0
5
0
1
0
0
0
Here in the database, we can see that we have different transaction id for every transaction and 1 represents the inclusion of the
product in the transaction, and 0 represents that in the transaction the product is not included. Now in transaction 4, we can see that it
includes product 1, product 2, and product 3. By analyzing this we can decide a rule {product 2, product 3} →{product 1}, where it
will indicate to us that customers who are buying product 2 and product 3 together are likely to buy product 1 also.
To extract a set of rules from the database we have various measures of significance and interest. Some of the best-known measures
are minimum thresholds on support and confidence.
Support
Tasnim (C191267)
26
Support is a measure that indicates the frequent appearance of a variable set or itemset in a database. Let X be the itemset and T a set
of transactions in then the support of X with respect to T can be measured as
Basically, the above measure tells the proportion of T transactions in the database which contains the item set X. From above the
given table support for itemset {product 1, product 2} will be ⅖ or 0.4. Because the itemset has appeared only in 2 transactions and
the total count of transactions is 5.
Confidence
Confidence is a measure that indicates how often a rule appears to be true. Let A rule X ⇒ Y with respect to a set of transaction T, is
the proportion of the transaction that contains X and Y at the same transaction, where X and Y are itemsets. In terms of support, the
confidence of a rule can be defined as
conf(X⇒Y) = supp(X U Y)/supp(X).
For example, in the given table confidence of rule {product 2, product 3} ⇒ {product 1} is 0.2/0.2 = 1.0 in this database. This means
100% of the time the customer buys product 2 and product 3 together, product 1 bought as well.
So here we have seen the two most known measures of interestingness. Instead of these terms, we have some more measures like lift
conviction, all confidence, collective strength, and leverage which have their meaning and importance. This article is basically
dependent on having an overview of the techniques of frequent itemset mining. Which we will discuss in our next part.
Frequent Itemset Mining(FIM)
Frequent Itemset Mining is a method that comes under the market basket analysis. Above in the article, we have an overview of the
association rules which tells us how rules are important for market basket analysis in accordance with the interestingness. Now in this
part, we will see an introduction to Frequent Itemset mining which aims at finding the regularities in the transactions performed by the
consumers. In terms of the supermarket, we can say regularities in the shopping behaviour of customers.
Basically, frequent itemset mining is a procedure that helps in finding the sets of products that are frequently bought together. Found
frequent itemsets can be applied on the procedure of recommendation system, fraud detection or using them we can improve the
arrangement of the products in the shelves.
The algorithms for Frequent Itemset Mining can be classified roughly into three categories.
Join-Based algorithm
Tree-Based algorithms
Pattern Growth algorithms
Where the join based algorithms expand the items list into a larger itemset to a minimum threshold support value which defines by the
user, the tree-based algorithm uses a lexicographic tree that allows mining of itemsets in a variety of ways like depth-first order and
the pattern growth algorithms make itemsets depends on the currently identified frequent patterns and expand them.
Now we can classify and find frequent itemset using the following algorithms:
Image source
Next in the article will have an overview of a classical Apriori Algorithm and FP Growth Algorithm.
Apriori
The apriori algorithm was proposed by Agrawal and Srikant in 1994. It is designed to work on the database which consists of
transaction details. This algorithm finds ( n + 1) itemsets from n items by using an iterative level-wise search technique. For example,
let’s take a look at the table of transaction details of the 5 items.
Transaction ID
T100
T200
T300
T400
T500
Tasnim (C191267)
List of items
I1, I2, I5
I2, I4
I2, I3
I1, I2, I4
I1, I3
27
T600
I2, I3
T700
I1, I3
T800
I1, I2, I3, I5
T900
I1, I2, I3
In the process of Frequent Itemset Mining, the Apriori algorithm first considers every single item as an itemset and counts the support
from their frequency in the database, and then captures those who have support equal to or more than the minimum support threshold.
In this process extraction of each frequent itemset requires the scanning of the entire database by the algorithm until no more itemsets
are left with more than the minimum threshold support.
Image source
In the above image, we can see that the minimum support threshold is 2 so in the very first step items with support 2 are considered
for the further steps of the algorithms. And in the further steps also it is sending the item sets having minimum support count 2, for
further processing.
Let’s see how we can implement this algorithm using python. For implementation, I am making a dataset of 11 products and using the
mlxtend library for making a Frequent dataset using the apriori algorithm.
dataset = [['product7', 'product9', 'product8', 'product6', 'product4', 'product11'],
['product3', 'product9', 'product8', 'product6', 'product4', 'product11'],
['product7', 'product1', 'product6', 'product4'],
['product7', 'product10', 'product2', 'product6', 'product11'],
['product2', 'product9', 'product9', 'product6', 'product5', 'product4']]
Importing the libraries.
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
Making the right format of the dataset for using the apriori algorithm.
con = TransactionEncoder()
con_arr = con.fit(dataset).transform(dataset)
df = pd.DataFrame(con_arr, columns = con.columns_)
df
Output:
Tasnim (C191267)
28
Next, I will be making itemsets with at least 60% support.
from mlxtend.frequent_patterns import apriori
apriori(df, min_support=0.6, use_colnames=True)
Output:
Here we can see the itemsets with minimum support of 60% with the column indices which can be used for some downstream
operations such as making marketing strategies like giving some offers in buying combinations of products.
Now let’s have a look at FP Growth Algorithm.
Frequent Pattern Growth Algorithm
As we have seen in the Apriori algorithm that it was generating the candidates for making the item sets. Here in the FP-Growth
algorithm, the algorithm represents the data in a tree structure. It is a lexicographic tree structure that we call the FP-tree. Which is
responsible for maintaining the association information between the frequent items.
After making the FP-Tree, it is segregated into the set of conditional FP-Trees for every frequent item. A set of conditional FP-Trees
further can be mined and measured separately. For example, the database is similar to the dataset we used in the apriori algorithm. For
that, the table of every conditional FP-Tree will look like the following.
item
Conditional pattern base
Conditional FP-Tree
Frequent pattern generated
I5
{{I2, I1: 1}, {I2, I1, I3: 1}}
{I2: 2, I1: 2}
{I2, I5: 2}, {I1, I5: 2}, {I2, I1, I5:
2}
I4
{{I2, I1: 1}, {I2: 1}}
{I2: 2}
{I2, I4: 2}
I3
{{I2, I1: 2}, {I2: 2}, {I1:
2}}
{I2: 4, I1: 2}, {I1:
2}
{I2, I3: 4}, {I1, I3: 4}, {I2, I1, I3:
2}
I1
{{I2: 4}}
{I2: 4}
{I2, I1: 4}
Based on the above table, the image below represents the frequent items as following:
Tasnim (C191267)
29
Image source
Here we can see that the support for I2 is seven. Where it came with I1 4 times with I3, 2 times, and with I4 it came one time. Where
in apriori algorithm was scanning tables, again and again, to generate the frequent set, here a one time scan is sufficient for generating
the itemsets.
The conditional FP-Tree for I3 will look like the following image.
Image source
Let’s see how we can implement it using python. As we did above, again we will use the mlxtend library for the implementation of
FP_growth. I am using similar data to perform this.
from mlxtend.frequent_patterns import fpgrowth
frequent_itemsets = fpgrowth(df, min_support=0.6, use_colnames=True)
frequent_itemsets
Output:
Here we can see in comparison of apriori where the frequent itemset was in similar series as the data frame series was in input but here
in FP-growth, the series we have is in descending order of support value.
Comparing Apriori and FP-Growth Algorithm
One of the most important features of any frequent itemset mining algorithm is that it should take lower timing and memory. Taking
this into consideration, we have a lot of algorithms related to FIM algorithms. These two Apriori and FP-Growth algorithms are the
most basic FIM algorithms. Other algorithms in this field are improvements of these algorithms. There are some basic differences
between these algorithms let’s take a look at
Apriori
Apriori generates the frequent patterns by making the
itemsets using pairing such as single item set, double itemset,
triple itemset.
FP Growth
FP Growth generates an FP-Tree for making
frequent patterns.
Apriori uses candidate generation where frequent subsets
are extended one item at a time.
FP-growth generates conditional FP-Tree for
every item in the data.
Tasnim (C191267)
30
Since apriori scans the database in each of its steps it
becomes time-consuming for data where the number of
items is larger.
A converted version of the database is saved in the memory
FP-tree requires only one scan of the
database in its beginning steps so it consumes
less time.
Set of conditional FP-tree for every item is
saved in the memory
It uses breadth-first search
It uses a depth-first search.
In the above table, we can see the differences between the Apriori and FP-Growth algorithms.
Advantages Of FP Growth Algorithm
1. This algorithm needs to scan the database only twice when compared to Apriori which scans the transactions for each iteration.
2. The pairing of items is not done in this algorithm and this makes it faster.
3. The database is stored in a compact version in memory.
4. It is efficient and scalable for mining both long and short frequent patterns.
Disadvantages Of FP-Growth Algorithm
1. FP Tree is more cumbersome and difficult to build than Apriori.
2. It may be expensive.
3. When the database is large, the algorithm may not fit in the shared memory.
Advantages of Apriori Algorithm
1. Easy to understand algorithm
2. Join and Prune steps are easy to implement on large itemsets in large databases
Disadvantages Apriori Algorithm
1. It requires high computation if the itemsets are very large and the minimum support is kept very low.
2. The entire database needs to be scanned.
6.3 Random Forest Algorithm
Random Forest is a popular machine learning algorithm that belongs to the supervised learning technique. It can be used for both
Classification and Regression problems in ML. It is based on the concept of ensemble learning, which is a process of combining
multiple classifiers to solve a complex problem and to improve the performance of the model.
As the name suggests, "Random Forest is a classifier that contains a number of decision trees on various subsets of the given
dataset and takes the average to improve the predictive accuracy of that dataset." Instead of relying on one decision tree, the
random forest takes the prediction from each tree and based on the majority votes of predictions, and it predicts the final output.
The greater number of trees in the forest leads to higher accuracy and prevents the problem of overfitting.
The below diagram explains the working of the Random Forest algorithm:
o
Note: To better understand the Random Forest Algorithm, you should have knowledge of the Decision Tree Algorithm.
o
Assumptions for Random Forest
Since the random forest combines multiple trees to predict the class of the dataset, it is possible that some decision trees may
predict the correct output, while others may not. But together, all the trees predict the correct output. Therefore, below are two
assumptions for a better Random forest classifier:
o
There should be some actual values in the feature variable of the dataset so that the classifier can predict accurate results rather
than a guessed result.
o
The predictions from each tree must have very low correlations.
o
Why use Random Forest?
Below are some points that explain why we should use the Random Forest algorithm:
<="" li="">
o
It takes less training time as compared to other algorithms.
Tasnim (C191267)
31
o
It predicts output with high accuracy, even for the large dataset it runs efficiently.
o
It can also maintain accuracy when a large proportion of data is missing.
o
How does Random Forest algorithm work?
Random Forest works in two-phase first is to create the random forest by combining N decision tree, and second is to make
predictions for each tree created in the first phase.
The Working process can be explained in the below steps and diagram:
Step-1: Select random K data points from the training set.
Step-2: Build the decision trees associated with the selected data points (Subsets).
Step-3: Choose the number N for decision trees that you want to build.
Step-4: Repeat Step 1 & 2.
Step-5: For new data points, find the predictions of each decision tree, and assign the new data points to the category that wins the
majority votes.
The working of the algorithm can be better understood by the below example:
Example: Suppose there is a dataset that contains multiple fruit images. So, this dataset is given to the Random forest classifier.
The dataset is divided into subsets and given to each decision tree. During the training phase, each decision tree produces a
prediction result, and when a new data point occurs, then based on the majority of results, the Random Forest classifier predicts the
final decision. Consider the below image:
o
Applications of Random Forest
There are mainly four sectors where Random forest mostly used:
1. Banking: Banking sector mostly uses this algorithm for the identification of loan risk.
2. Medicine: With the help of this algorithm, disease trends and risks of the disease can be identified.
3. Land Use: We can identify the areas of similar land use by this algorithm.
4. Marketing: Marketing trends can be identified using this algorithm.
o
Advantages of Random Forest
o
Random Forest is capable of performing both Classification and Regression tasks.
o
It is capable of handling large datasets with high dimensionality.
o
It enhances the accuracy of the model and prevents the overfitting issue.
o
Disadvantages of Random Forest
o
Although random forest can be used for both classification and regression tasks, it is not more suitable for Regression tasks.
6.4 Regression Analysis in Machine learning
Regression analysis is a statistical method to model the relationship between a dependent (target) and independent (predictor)
variables with one or more independent variables. More specifically, Regression analysis helps us to understand how the value
of the dependent variable is changing corresponding to an independent variable when other independent variables are held
fixed. It predicts continuous/real values such as temperature, age, salary, price, etc.
We can understand the concept of regression analysis using the below example:
Example: Suppose there is a marketing company A, who does various advertisement every year and get sales on that. The
below list shows the advertisement made by the company in the last 5 years and the corresponding sales:
Tasnim (C191267)
32
Now, the company wants to do the advertisement of $200 in the year 2019 and wants to know the prediction about the sales
for this year. So to solve such type of prediction problems in machine learning, we need regression analysis.
Regression is a supervised learning technique which helps in finding the correlation between variables and enables us to
predict the continuous output variable based on the one or more predictor variables. It is mainly used for prediction,
forecasting, time series modeling, and determining the causal-effect relationship between variables.
In Regression, we plot a graph between the variables which best fits the given datapoints, using this plot, the machine learning
model can make predictions about the data. In simple words, "Regression shows a line or curve that passes through all the
datapoints on target-predictor graph in such a way that the vertical distance between the datapoints and the regression line
is minimum." The distance between datapoints and line tells whether a model has captured a strong relationship or not.
Some examples of regression can be as:
o
Prediction of rain using temperature and other factors
o
Determining Market trends
o
Prediction of road accidents due to rash driving.
What Is Simple Linear Regression?
Simple linear regression is a statistical method for establishing the relationship between two variables using a straight line. The line is
drawn by finding the slope and intercept, which define the line and minimize regression errors.
The simplest form of simple linear regression has only one x variable and one y variable. The x variable is the independent variable
because it is independent of what you try to predict the dependent variable. The y variable is the dependent variable because it depends
on what you try to predict.
y = β0 +β1x+ε is the formula used for simple linear regression.
y is the predicted value of the dependent variable (y) for any given value of the independent variable (x).
B0 is the intercept, the predicted value of y when the x is 0.
B1 is the regression coefficient – how much we expect y to change as x increases.
x is the independent variable ( the variable we expect is influencing y).
e is the error of the estimate, or how much variation there is in our regression coefficient estimate.
Simple linear regression establishes a line that fits your data, but it does not guarantee that the line is good enough. For example, if
your data points have an upward trend and are very far apart, then simple linear regression will give you a downward-sloping line,
which will not match your data
Simple Linear Regression vs. Multiple Linear Regression
When predicting a complex process's outcome, it's best to use multiple linear regression instead of simple linear regression. But it is
not necessary to use complex algorithms for simple problems.
A simple linear regression can accurately capture the relationship between two variables in simple relationships. But when dealing
with more complex interactions that require more thought, you need to switch from simple to multiple regression.
A multiple regression model uses more than one independent variable. It does not suffer from the same limitations as the simple
regression equation, and it is thus able to fit curved and non-linear relationships.
https://www.simplilearn.com/what-is-simple-linear-regression-in-machine-learning-article
•
What Is Multiple Linear Regression (MLR)?
One of the most common types of predictive analysis is multiple linear regression. This type of analysis allows you to understand the
relationship between a continuous dependent variable and two or more independent variables.
The independent variables can be either continuous (like age and height) or categorical (like gender and occupation). It's important to
note that if your dependent variable is categorical, you should dummy code it before running the analysis.
Tasnim (C191267)
33
•
Formula and Calculation of Multiple Linear Regression
Several circumstances that influence the dependent variable simultaneously can be controlled through multiple regression
analysis. Regression analysis is a method of analyzing the relationship between independent variables and dependent variables.
Let k represent the number of variables denoted by x1, x2, x3, ……, xk.
For this method, we assume that we have k independent variables x1, . . . , xk that we can set, then they probabilistically determine an
outcome Y.
Furthermore, we assume that Y is linearly dependent on the factors according to
Y = β0 + β1x1 + β2x2 + · · · + βkxk + ε
•
The variable yi is dependent or predicted
•
The slope of y depends on the y-intercept, that is, when xi and x2 are both zero, y will be β0.
•
The regression coefficients β1 and β2 represent the change in y as a result of one-unit changes in xi1 and xi2.
•
βp refers to the slope coefficient of all independent variables
•
ε term describes the random error (residual) in the model.
Where ε is a standard error, this is just like we had for simple linear regression, except k doesn’t have to be 1.
We have n observations, n typically being much more than k.
For i th observation, we set the independent variables to the values xi1, xi2 . . . , xik and measure a value yi for the random variable
Yi.
Thus, the model can be described by the equations.
Yi = β0 + β1xi1 + β2xi2 + · · · + βkxik + i for i = 1, 2, . . . , n,
Where the errors i are independent standard variables, each with mean 0 and the same unknown variance σ2.
Altogether the model for multiple linear regression has k + 2 unknown parameters:
β0, β1, . . . , βk, and σ 2.
When k was equal to 1, we found the least squares line y = βˆ 0 +βˆ 1x.
It was a line in the plane R 2.
Now, with k ≥ 1, we’ll have a least squares hyperplane.
y = βˆ 0 + βˆ 1x1 + βˆ 2x2 + · · · + βˆ kxk in Rk+1.
The way to find the estimators βˆ 0, βˆ 1, . . ., and βˆ k is the same.
Take the partial derivatives of the squared error.
Q = Xn i=1 (yi − (β0 + β1xi1 + β2xi2 + · · · + βkxik))2
When that system is solved we have fitted values
yˆi = βˆ 0 + βˆ 1xi1 + βˆ 2xi2 + · · · + βˆ kxik for i = 1, . . . , n that should be close to the actual values yi.
Polynomial Regression
Polynomial Regression is a regression algorithm that models the relationship between a dependent(y) and independent variable(x) as
nth degree polynomial. The Polynomial Regression equation is given below:
y= b0+b1x1+ b2x12+ b2x13+...... bnx1n
It is also called the special case of Multiple Linear Regression in ML. Because we add some polynomial terms to the Multiple Linear
regression equation to convert it into Polynomial Regression.
It is a linear model with some modification in order to increase the accuracy.
The dataset used in Polynomial regression for training is of non-linear nature.
It makes use of a linear regression model to fit the complicated and non-linear functions and datasets.
Hence, "In Polynomial regression, the original features are converted into Polynomial features of required degree (2,3,..,n) and
then modeled using a linear model."
The need of Polynomial Regression in ML can be understood in the below points:
If we apply a linear model on a linear dataset, then it provides us a good result as we have seen in Simple Linear Regression, but if
we apply the same model without any modification on a non-linear dataset, then it will produce a drastic output. Due to which loss
function will increase, the error rate will be high, and accuracy will be decreased.
So for such cases, where data points are arranged in a non-linear fashion, we need the Polynomial Regression model. We can
understand it in a better way using the below comparison diagram of the linear dataset and non-linear dataset.
Tasnim (C191267)
34
In the above image, we have taken a dataset which is arranged non-linearly. So if we try to cover it with a linear model, then we can
clearly see that it hardly covers any data point. On the other hand, a curve is suitable to cover most of the data points, which is of the
Polynomial model.
Hence, if the datasets are arranged in a non-linear fashion, then we should use the Polynomial Regression model instead of Simple
Linear Regression.
Note: A Polynomial Regression algorithm is also called Polynomial Linear Regression because it does not depend on the variables,
instead, it depends on the coefficients, which are arranged in a linear fashion.
Equation of the Polynomial Regression Model:
Simple Linear Regression equation:
Multiple Linear Regression equation:
Polynomial Regression equation:
y = b0+b1x
.........(a)
y= b0+b1x+ b2x2+ b3x3+....+ bnxn
y= b0+b1x + b2x2+ b3x3+....+ bnxn
.........(b)
..........(c)
When we compare the above three equations, we can clearly see that all three equations are Polynomial equations but differ by the
degree of variables. The Simple and Multiple Linear equations are also Polynomial equations with a single degree, and the Polynomial
regression equation is Linear equation with the nth degree. So if we add a degree to our linear equations, then it will be converted into
Polynomial Linear equations.
https://www.javatpoint.com/machine-learning-polynomial-regression
6.5 Confusion Matrix in Machine Learning
The confusion matrix is a matrix used to determine the performance of the classification models for a given set of test data. It can only
be determined if the true values for test data are known. The matrix itself can be easily understood, but the related terminologies may
be confusing. Since it shows the errors in the model performance in the form of a matrix, hence also known as an error matrix. Some
features of Confusion matrix are given below:
o
For the 2 prediction classes of classifiers, the matrix is of 2*2 table, for 3 classes, it is 3*3 table, and so on.
o
The matrix is divided into two dimensions, that are predicted values and actual values along with the total number of
predictions.
o
Predicted values are those values, which are predicted by the model, and actual values are the true values for the given
observations.
o
It looks like the below table:
The above table has the following cases:
o
True Negative: Model has given prediction No, and the real or actual value was also No.
o
True Positive: The model has predicted yes, and the actual value was also true.
o
False Negative: The model has predicted no, but the actual value was Yes, it is also called as Type-II error.
o
False Positive: The model has predicted Yes, but the actual value was No. It is also called a Type-I error.
o
Need for Confusion Matrix in Machine learning
o
It evaluates the performance of the classification models, when they make predictions on test data, and tells how good our
classification model is.
o
It not only tells the error made by the classifiers but also the type of errors such as it is either type-I or type-II error.
o
With the help of the confusion matrix, we can calculate the different parameters for the model, such as accuracy, precision, etc.
Example: We can understand the confusion matrix using an example.
Tasnim (C191267)
35
Suppose we are trying to create a model that can predict the result for the disease that is either a person has that disease or not. So, the
confusion matrix for this is given as:
From the above example, we can conclude that:
o
The table is given for the two-class classifier, which has two predictions "Yes" and "NO." Here, Yes defines that patient has the
disease, and No defines that patient does not has that disease.
o
The classifier has made a total of 100 predictions. Out of 100 predictions, 89 are true predictions, and 11 are incorrect
predictions.
o
The model has given prediction "yes" for 32 times, and "No" for 68 times. Whereas the actual "Yes" was 27, and actual "No"
was 73 times.
o
Calculations using Confusion Matrix:
We can perform various calculations for the model, such as the model's accuracy, using this matrix. These calculations are given
below:
o
Classification Accuracy: It is one of the important parameters to determine the accuracy of the classification problems. It
defines how often the model predicts the correct output. It can be calculated as the ratio of the number of correct predictions
made by the classifier to all number of predictions made by the classifiers. The formula is given below:
o
Misclassification rate: It is also termed as Error rate, and it defines how often the model gives the wrong predictions. The
value of error rate can be calculated as the number of incorrect predictions to all number of the predictions made by the
classifier. The formula is given below:
o
Precision: It can be defined as the number of correct outputs provided by the model or out of all positive classes that have
predicted correctly by the model, how many of them were actually true. It can be calculated using the below formula:
o
Recall: It is defined as the out of total positive classes, how our model predicted correctly. The recall must be as high as
possible.
o
F-measure: If two models have low precision and high recall or vice versa, it is difficult to compare these models. So, for this
purpose, we can use F-score. This score helps us to evaluate the recall and precision at the same time. The F-score is maximum
if the recall is equal to the precision. It can be calculated using the below formula:
Other important terms used in Confusion Matrix:
o
Null Error rate: It defines how often our model would be incorrect if it always predicted the majority class. As per the
accuracy paradox, it is said that "the best classifier has a higher error rate than the null error rate."
o
ROC Curve: The ROC is a graph displaying a classifier's performance for all possible thresholds. The graph is plotted
between the true positive rate (on the Y-axis) and the false Positive rate (on the x-axis).
7 Exercise:
Which of the following schema is best suitable for data warehouse?
Snowflake schemas are good for data warehouses, star schemas are better for datamarts with simple relationships.
On one hand, star schemas are simpler, run queries faster, and are easier to set up. On the other hand, snowflake
schemas are less prone to data integrity issues, are easier to maintain, and utilize less space. star schema more popular
than snowflake schema. A star schema is easier to design and implement than a snowflake schema. A star schema
can be more efficient to query than a snowflake schema, because there are fewer JOINs between tables. A star schema
can require more storage space than a snowflake schema, because of the denormalized data.
Tasnim (C191267)
36
What is class imbalance problem in machine learning? How do measure the performance of a class-imbalance
algorithm with example.
The class imbalance problem typically occurs when there are many more instances of some classes than others. In
such cases, standard classifiers tend to be overwhelmed by the large classes and ignore the small ones. Class
imbalance is normal and expected in typical ML applications. For example: in credit card fraud detection, most
transactions are legitimate, and only a small fraction are fraudulent.
measure the performance of a class-imbalance algorithm with example.
Measuring the performance of a class-imbalance algorithm requires using appropriate evaluation metrics that
consider the imbalance in the dataset. Here are some commonly used metrics:
Confusion Matrix: A confusion matrix is a table that summarizes the performance of a classifier. It lists the true
positive (TP), true negative (TN), false positive (FP), and false negative (FN) predictions for each class.
Precision: Precision measures the proportion of true positive predictions out of all positive predictions. It is calculated
as TP / (TP + FP).
Recall: Recall measures the proportion of true positive predictions out of all actual positive cases. It is calculated as
TP / (TP + FN).
F1-score: The F1-score is the harmonic mean of precision and recall. It provides a balanced measure of both metrics
and is often used when the classes are imbalanced.
Area Under the Receiver Operating Characteristic (ROC) curve (AUC-ROC): The ROC curve is a graphical
representation of the classifier's performance at different thresholds. It plots the true positive rate (sensitivity) against
the false positive rate (1-specificity) for different threshold values. The AUC-ROC is the area under the ROC curve.
It provides a single number that summarizes the overall performance of the classifier.
Here is an example to illustrate the performance evaluation of a class-imbalance algorithm:
Suppose we have a dataset with 1,000 instances, where 900 instances belong to the negative class and 100 instances
belong to the positive class. We want to classify whether an instance belongs to the positive or negative class. We
train a classifier using this dataset and evaluate its performance using the confusion matrix, precision, recall, F1score, and AUC-ROC metrics.
Suppose the classifier predicts 20 instances as positive and 980 instances as negative. The confusion matrix is as
follows:
Predicted Negative Predicted Positive
Actual Negative
880
20
Actual Positive
0
100
From the confusion matrix, we can calculate the precision, recall, F1-score, and AUC-ROC metrics as follows:
Precision = TP / (TP + FP) = 100 / (100 + 20) = 0.833
Recall = TP / (TP + FN) = 100 / (100 + 0) = 1.000
F1-score = 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.833 * 1.000) / (0.833 + 1.000) = 0.909
AUC-ROC = 0.940
In this example, the classifier achieved high precision and recall values, indicating that it performed well in detecting
the positive class. The F1-score indicates that the classifier achieved a good balance between precision and recall.
The high AUC-ROC value suggests that the classifier has a good overall performance.
How to compare the performance of two classifiers in machine learning.
The performance of two classifiers in machine learning can be compared using evaluation metrics such as accuracy,
precision, recall, F1-score, and AUC-ROC. The classifiers should be trained on the same dataset using the same
hyperparameters and features, and the evaluation metrics should be computed using cross-validation techniques. The
results should be compared to determine which classifier performs better, taking into consideration the domainspecific requirements and objectives.
What is class imbalance problem in machine learning? How do measure the performance of a class-imbalance
algorithm with example.
Tasnim (C191267)
37
The class imbalance problem typically occurs when there are many more instances of some classes than others. In
such cases, standard classifiers tend to be overwhelmed by the large classes and ignore the small ones. Class
imbalance is normal and expected in typical ML applications. For example: in credit card fraud detection, most
transactions are legitimate, and only a small fraction are fraudulent.
measure the performance of a class-imbalance algorithm with example.
Measuring the performance of a class-imbalance algorithm requires using appropriate evaluation metrics that
consider the imbalance in the dataset. Here are some commonly used metrics:
Confusion Matrix: A confusion matrix is a table that summarizes the performance of a classifier. It lists the true
positive (TP), true negative (TN), false positive (FP), and false negative (FN) predictions for each class.
Precision: Precision measures the proportion of true positive predictions out of all positive predictions. It is
calculated as TP / (TP + FP).
Recall: Recall measures the proportion of true positive predictions out of all actual positive cases. It is calculated as
TP / (TP + FN).
F1-score: The F1-score is the harmonic mean of precision and recall. It provides a balanced measure of both metrics
and is often used when the classes are imbalanced.
Area Under the Receiver Operating Characteristic (ROC) curve (AUC-ROC): The ROC curve is a graphical
representation of the classifier's performance at different thresholds. It plots the true positive rate (sensitivity) against
the false positive rate (1-specificity) for different threshold values. The AUC-ROC is the area under the ROC curve.
It provides a single number that summarizes the overall performance of the classifier.
Here is an example to illustrate the performance evaluation of a class-imbalance algorithm:
Suppose we have a dataset with 1,000 instances, where 900 instances belong to the negative class and 100 instances
belong to the positive class. We want to classify whether an instance belongs to the positive or negative class. We
train a classifier using this dataset and evaluate its performance using the confusion matrix, precision, recall, F1score, and AUC-ROC metrics.
Suppose the classifier predicts 20 instances as positive and 980 instances as negative. The confusion matrix is as
follows:
Predicted Negative
Predicted Positive
Actual Negative
880
20
Actual Positive
0
100
From the confusion matrix, we can calculate the precision, recall, F1-score, and AUC-ROC metrics as follows:
Precision = TP / (TP + FP) = 100 / (100 + 20) = 0.833
Recall = TP / (TP + FN) = 100 / (100 + 0) = 1.000
F1-score = 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.833 * 1.000) / (0.833 + 1.000) = 0.909
AUC-ROC = 0.940
In this example, the classifier achieved high precision and recall values, indicating that it performed well in detecting
the positive class. The F1-score indicates that the classifier achieved a good balance between precision and recall.
The high AUC-ROC value suggests that the classifier has a good overall performance.
what is cross validation in machine learning
Cross-validation is a technique for evaluating ML models by training several ML models on subsets of the available
input data and evaluating them on the complementary subset of the data. Use cross-validation to detect overfitting,
ie, failing to generalize a pattern. It is a statistical method of evaluating and comparing learning algorithms by
dividing data into two segments: one used to learn or train a model and the other used to validate the model.
Extra - [For example, setting k = 2 results in 2-fold cross-validation. In 2-fold cross-validation, we randomly shuffle
the dataset into two sets d0 and d1, so that both sets are equal size (this is usually implemented by shuffling the data
array and then splitting it in two).]
Tasnim (C191267)
38
How to compare the performance of two classifiers in machine learning.
The performance of two classifiers in machine learning can be compared using evaluation metrics such as accuracy,
precision, recall, F1-score, and AUC-ROC. The classifiers should be trained on the same dataset using the same
hyperparameters and features, and the evaluation metrics should be computed using cross-validation techniques. The
results should be compared to determine which classifier performs better, taking into consideration the domainspecific requirements and objectives.
support vector machine always tries to maintain maximum margin for classification. explain it with proper
sketch
https://vitalflux.com/svm-algorithm-maximum-margin-classifier/
consider about Agora super shop. based on "Agora" develop & draw a sample data cube
A data cube is a multidimensional representation of data that allows for multidimensional analysis. It consists of dimensions,
hierarchies, and measures. Each dimension represents a different aspect or attribute of the data, and hierarchies define the levels of
detail within each dimension. Measures are the numeric values that can be analyzed or aggregated.
Let's consider a sample data cube for a super shop:
Dimensions:
1. Time: Date, Month, Year
2. Product: Product ID, Product Category, Product Subcategory
3. Store: Store ID, Store Location, Store Size
Hierarchies within Dimensions:
1. Time: Year > Month > Date
2. Product: Product Category > Product Subcategory
3. Store: Store Location > Store Size
Measures:
1. Sales Quantity
2. Sales Revenue
3. Profit
4. Discount Amount
Visual representation of the data cube:
Write short notes on (any four)
Elbow method, Fact- Constellation Schema, Decision tree,
Information entropy, Reinforcement learning
Elbow Method: The elbow method is a popular technique used to determine the optimal number of clusters in a
clustering algorithm. It works by plotting the within-cluster sum of squares (WCSS) against the number of clusters,
and identifying the "elbow" point in the plot where the change in WCSS starts to level off. This point represents the
optimal number of clusters, as adding more clusters beyond this point does not lead to a significant reduction in
WCSS.
Fact-Constellation Schema: Fact-Constellation Schema is a data modeling technique used in data warehousing to
represent complex, multi-dimensional data structures. It involves organizing data into a set of fact tables and
dimension tables, where the fact tables contain measures of interest (such as sales revenue) and the dimension tables
provide context for these measures (such as time, geography, and product). The schema enables efficient querying
and analysis of data across multiple dimensions.
Decision Tree: A decision tree is a popular machine learning algorithm that can be used for both classification and
regression tasks. It works by recursively splitting the data into subsets based on the features that are most informative
for the task at hand, until a stopping criterion is met (such as a maximum depth or minimum number of samples per
leaf). The resulting tree can be used to make predictions for new data by traversing the tree from the root to a leaf
node based on the values of its features.
Tasnim (C191267)
39
Information Entropy: Information entropy is a measure of the amount of uncertainty or randomness in a system. In
machine learning, it is commonly used to measure the impurity of a node in a decision tree, where a higher entropy
implies greater uncertainty about the class labels of the data points in that node. The entropy of a node is calculated
as the sum of the negative log probabilities of each class label, weighted by their relative frequencies in the node.
Reinforcement Learning: Reinforcement learning is a type of machine learning where an agent learns to interact with
an environment to maximize a reward signal. The agent takes actions in the environment based on its current state,
receives feedback in the form of rewards or penalties, and updates its behavior to improve its future performance.
Reinforcement learning has been successfully applied in a wide range of domains, including game playing, robotics,
and control systems.
Types of Neural Networks and Definition of Neural Network
The nine types of neural networks are:
1.
2.
3.
4.
5.
6.
7.
8.
9.
Perceptron
Feed Forward Neural Network
Multilayer Perceptron
Convolutional Neural Network
Radial Basis Functional Neural Network
Recurrent Neural Network
LSTM – Long Short-Term Memory
Sequence to Sequence Models
Modular Neural Network
Here is a brief description of each of the nine types of neural networks, along with an example, advantages, disadvantages, and applications:
1. Perceptron:
•
Description: The perceptron is the simplest form of a neural network with a single layer of artificial neurons.
•
Example: Binary classification tasks, such as predicting whether an email is spam or not.
•
Advantages: Simple and easy to understand, computationally efficient.
•
Disadvantages: Limited to linearly separable problems, cannot learn complex patterns.
•
Applications: Pattern recognition, binary classification.
2. Feed Forward Neural Network:
•
Description: Also known as a multilayer perceptron (MLP), it consists of multiple layers of interconnected neurons.
•
Example: Handwritten digit recognition, image classification.
•
Advantages: Can learn complex patterns, universal approximation capability.
•
Disadvantages: Requires a large amount of training data, prone to overfitting.
•
Applications: Image recognition, speech recognition, natural language processing.
3. Multilayer Perceptron:
•
Description: Similar to a feed-forward neural network, it consists of multiple layers of interconnected neurons.
•
Example: Credit scoring, sentiment analysis.
•
Advantages: Can handle nonlinear problems, good generalization capability.
•
Disadvantages: Requires careful tuning of parameters, prone to overfitting.
•
Applications: Pattern recognition, regression, classification.
4. Convolutional Neural Network (CNN):
•
Description: Designed for processing structured grid-like data, such as images, by applying convolution operations.
•
Example: Image classification, object detection.
•
Advantages: Can automatically learn hierarchical features, translation-invariant.
•
Disadvantages: Requires a large amount of training data, computationally expensive.
•
Applications: Computer vision, image recognition, autonomous driving.
5. Radial Basis Functional Neural Network (RBFNN):
•
Description: Utilizes radial basis functions to model the hidden layer and linear combination in the output layer.
•
Example: Time series prediction, function approximation.
•
Advantages: Fast learning, good generalization ability.
•
Disadvantages: Sensitivity to network architecture, may overfit with insufficient data.
Tasnim (C191267)
40
•
Applications: Pattern recognition, time series analysis, control systems.
6. Recurrent Neural Network (RNN):
•
Description: Processes sequential data by using feedback connections, allowing information to persist.
•
Example: Speech recognition, language translation.
•
Advantages: Handles sequential data well, captures temporal dependencies.
•
Disadvantages: Gradient vanishing/exploding problem, computationally expensive.
•
Applications: Natural language processing, speech recognition, time series prediction.
7. LSTM - Long Short-Term Memory:
•
Description: A type of recurrent neural network designed to mitigate the vanishing gradient problem by using memory cells.
•
Example: Sentiment analysis, text generation.
•
Advantages: Captures long-term dependencies, handles variable-length sequences.
•
Disadvantages: Requires a large amount of training data, computationally expensive.
•
Applications: Natural language processing, speech recognition, time series analysis.
8. Sequence to Sequence Models:
•
Description: Utilizes an encoder-decoder architecture to transform one sequence into another.
•
Example: Machine translation, chatbots.
•
Advantages: Handles variable-length sequences, preserves semantic information.
•
Disadvantages: Requires large amounts of training data, complex architecture.
•
Applications: Machine translation, speech recognition, text summarization.
9. Modular Neural Network:
•
Description: Consists of multiple independent neural network modules that work together to solve a complex problem.
•
Example: Autonomous robots,
https://www.mygreatlearning.com/blog/types-of-neural-networks/
7.1.1.1
K means:
Cluster the following eight points (with (x, y) representing locations) into three clusters:
A1(2, 10), A2(2, 5), A3(8, 4), A4(5, 8), A5(7, 5), A6(6, 4), A7(1, 2), A8(4, 9)
Initial cluster centers are: A1(2, 10), A4(5, 8) and A7(1, 2).
The distance function between two points a = (x1, y1) and b = (x2, y2) is defined asΡ(a, b) = |x2 – x1| + |y2 – y1|
Use K-Means Algorithm to find the three cluster centers after the second iteration.
Solution-
We follow the above discussed K-Means Clustering Algorithm-
Iteration-01:
We calculate the distance of each point from each of the center of the three clusters.
The distance is calculated by using the given distance function.
The following illustration shows the calculation of distance between point A1(2, 10) and each of the center of the three clusters-
Calculating Distance Between A1(2, 10) and C1(2, 10)-
Ρ(A1, C1)
Tasnim (C191267)
41
= |x2 – x1| + |y2 – y1|
= |2 – 2| + |10 – 10|
=0
Calculating Distance Between A1(2, 10) and C2(5, 8)-
Ρ(A1, C2)
= |x2 – x1| + |y2 – y1|
= |5 – 2| + |8 – 10|
=3+2
=5
Calculating Distance Between A1(2, 10) and C3(1, 2)-
Ρ(A1, C3)
= |x2 – x1| + |y2 – y1|
= |1 – 2| + |2 – 10|
=1+8
=9
In the similar manner, we calculate the distance of other points from each of the center of the three clusters.
Next,
We draw a table showing all the results.
Using the table, we decide which point belongs to which cluster.
The given point belongs to that cluster whose center is nearest to it.
Given Points
Distance from
center (2, 10) of
Cluster-01
Distance from
center (5, 8) of
Cluster-02
Distance from
center (1, 2) of
Cluster-03
Point belongs
to Cluster
A1(2, 10)
A2(2, 5)
A3(8, 4)
A4(5, 8)
A5(7, 5)
A6(6, 4)
A7(1, 2)
A8(4, 9)
0
5
12
5
10
10
9
3
5
6
7
0
5
5
10
2
9
4
9
10
9
7
0
10
C1
C3
C2
C2
C2
C2
C3
C2
From here, New clusters are-
Cluster-01:
First cluster contains pointsA1(2, 10)
Cluster-02:
Second cluster contains points-
Tasnim (C191267)
42
A3(8, 4)
A4(5, 8)
A5(7, 5)
A6(6, 4)
A8(4, 9)
Cluster-03:
Third cluster contains pointsA2(2, 5)
A7(1, 2)
Now,
We re-compute the new cluster clusters.
The new cluster center is computed by taking mean of all the points contained in that cluster.
For Cluster-01:
We have only one point A1(2, 10) in Cluster-01.
So, cluster center remains the same.
For Cluster-02:
Center of Cluster-02
= ((8 + 5 + 7 + 6 + 4)/5, (4 + 8 + 5 + 4 + 9)/5)
= (6, 6)
For Cluster-03:
Center of Cluster-03
= ((2 + 1)/2, (5 + 2)/2)
= (1.5, 3.5)
This is completion of Iteration-01.
Iteration-02:
We calculate the distance of each point from each of the center of the three clusters.
The distance is calculated by using the given distance function.
The following illustration shows the calculation of distance between point A1(2, 10) and each of the center of the three clusters-
Calculating Distance Between A1(2, 10) and C1(2, 10)-
Ρ(A1, C1)
= |x2 – x1| + |y2 – y1|
= |2 – 2| + |10 – 10|
Tasnim (C191267)
43
=0
Calculating Distance Between A1(2, 10) and C2(6, 6)-
Ρ(A1, C2)
= |x2 – x1| + |y2 – y1|
= |6 – 2| + |6 – 10|
=4+4
=8
Calculating Distance Between A1(2, 10) and C3(1.5, 3.5)-
Ρ(A1, C3)
= |x2 – x1| + |y2 – y1|
= |1.5 – 2| + |3.5 – 10|
= 0.5 + 6.5
=7
In the similar manner, we calculate the distance of other points from each of the center of the three clusters.
Next,
We draw a table showing all the results.
Using the table, we decide which point belongs to which cluster.
The given point belongs to that cluster whose center is nearest to it.
Given Points
Distance from
center (2, 10) of
Cluster-01
Distance from
center (6, 6) of
Cluster-02
Distance from
center (1.5, 3.5) of
Cluster-03
Point belongs to
Cluster
A1(2, 10)
A2(2, 5)
A3(8, 4)
A4(5, 8)
A5(7, 5)
A6(6, 4)
A7(1, 2)
A8(4, 9)
0
5
12
5
10
10
9
3
8
5
4
3
2
2
9
5
7
2
7
8
7
5
2
8
C1
C3
C2
C2
C2
C2
C3
C1
From here, New clusters are-
Cluster-01:
First cluster contains pointsA1(2, 10)
A8(4, 9)
Cluster-02:
Second cluster contains pointsA3(8, 4)
Tasnim (C191267)
44
A4(5, 8)
A5(7, 5)
A6(6, 4)
Cluster-03:
Third cluster contains pointsA2(2, 5)
A7(1, 2)
Now,
We re-compute the new cluster clusters.
The new cluster center is computed by taking mean of all the points contained in that cluster.
For Cluster-01:
Center of Cluster-01
= ((2 + 4)/2, (10 + 9)/2)
= (3, 9.5)
For Cluster-02:
Center of Cluster-02
= ((8 + 5 + 7 + 6)/4, (4 + 8 + 5 + 4)/4)
= (6.5, 5.25)
For Cluster-03:
Center of Cluster-03
= ((2 + 1)/2, (5 + 2)/2)
= (1.5, 3.5)
This is completion of Iteration-02.
After second iteration, the center of the three clusters areC1(3, 9.5)
C2(6.5, 5.25)
C3(1.5, 3.5)
Tasnim (C191267)
45
7.1.1.2
Confusion Matrix
Tasnim (C191267)
46
Tasnim (C191267)
47
7.1.1.3
FP Growth Algorithm
association-rule mining algorithm was developed named Frequent Pattern Growth Algorithm. It overcomes the disadvantages of the Apriori
algorithm by storing all the transactions in a Trie Data Structure. Consider the following data:-
The above-given data is a hypothetical dataset of transactions with each letter representing an item. The frequency of each individual item is
computed:-
Tasnim (C191267)
48
Let the minimum support be 3. A Frequent Pattern set is built which will contain all the elements whose frequency is greater than or equal to the
minimum support. These elements are stored in descending order of their respective frequencies. After insertion of the relevant items, the set L
looks like this:L = {K : 5, E : 4, M : 3, O : 3, Y : 3}
Now, for each transaction, the respective Ordered-Item set is built. It is done by iterating the Frequent Pattern set and checking if the current
item is contained in the transaction in question. If the current item is contained, the item is inserted in the Ordered-Item set for the current
transaction. The following table is built for all the transactions:
Now, all the Ordered-Item sets are inserted into a Trie Data Structure.
a) Inserting the set {K, E, M, O, Y}:
Here, all the items are simply linked one after the other in the order of occurrence in the set and initialize the support count for each item as 1.
b) Inserting the set {K, E, O, Y}:
Till the insertion of the elements K and E, simply the support count is increased by 1. On inserting O we can see that there is no direct
link between E and O, therefore a new node for the item O is initialized with the support count as 1 and item E is linked to this new
node. On inserting Y, we first initialize a new node for the item Y with support count as 1 and link the new node of O with the new
node of Y.
c) Inserting the set {K, E, M}:
Here simply the support count of each element is increased by 1.
Tasnim (C191267)
49
d) Inserting the set {K, M, Y}:
Similar to step b), first the support count of K is increased, then new nodes for M and Y are initialized and linked accordingly.
e) Inserting the set {K, E, O}:
Here simply the support counts of the respective elements are increased. Note that the support count of the new node of item O is
increased.
Now, for each item, the Conditional Pattern Base is computed which is path labels of all the paths which lead to any node of the
given item in the frequent-pattern tree. Note that the items in the below table are arranged in the ascending order of their frequencies.
Tasnim (C191267)
50
Now for each item, the Conditional Frequent Pattern Tree is built. It is done by taking the set of elements that is common in all the
paths in the Conditional Pattern Base of that item and calculating its support count by summing the support counts of all the paths in
the Conditional Pattern Base.
From the Conditional Frequent Pattern tree, the Frequent Pattern rules are generated by pairing the items of the Conditional
Frequent Pattern Tree set to the corresponding to the item as given in the below table.
For each row, two types of association rules can be inferred for example for the first row which contains the element, the rules K -> Y
and Y -> K can be inferred. To determine the valid rule, the confidence of both the rules is calculated and the one with confidence
greater than or equal to the minimum confidence value is retained.
7.1.1.4 Aprirori Algorithm
Step 1: Data in the database
Step 2: Calculate the support/frequency of all items
Step 3: Discard the items with minimum support less than 2
Step 4: Combine two items
Step 5: Calculate the support/frequency of all items
Step 6: Discard the items with minimum support less than 2/3
Step 6.5: Combine three items and calculate their support.
Step 7: Discard the items with minimum support less than 2 /3
Example -1
Let’s see an example of the Apriori Algorithm.
Find the frequent itemsets and generate association rules on this. Assume that minimum support threshold (s = 33.33%) and
minimum confident threshold (c = 60%)
Let’s start,
Tasnim (C191267)
51
There is only one itemset with minimum support 2. So only one itemset is frequent.
Frequent Itemset (I) = {Hot Dogs, Coke, Chips}
Association rules,
[Hot Dogs^Coke]=>[Chips] //confidence = sup(Hot Dogs^Coke^Chips)/sup(Hot Dogs^Coke) = 2/2*100=100% //Selected
[Hot Dogs^Chips]=>[Coke] //confidence = sup(Hot Dogs^Coke^Chips)/sup(Hot Dogs^Chips) = 2/2*100=100% //Selected
[Coke^Chips]=>[Hot Dogs] //confidence = sup(Hot Dogs^Coke^Chips)/sup(Coke^Chips) = 2/3*100=66.67% //Selected
[Hot Dogs]=>[Coke^Chips] //confidence = sup(Hot Dogs^Coke^Chips)/sup(Hot Dogs) = 2/4*100=50% //Rejected
[Coke]=>[Hot Dogs^Chips] //confidence = sup(Hot Dogs^Coke^Chips)/sup(Coke) = 2/3*100=66.67% //Selected
[Chips]=>[Hot Dogs^Coke] //confidence = sup(Hot Dogs^Coke^Chips)/sup(Chips) = 2/4*100=50% //Rejected
There are four strong results (minimum confidence greater than 60%)
Example -2
Let’s see another example of the Apriori Algorithm.
Find the frequent itemsets on this. Assume that minimum support (s = 3)
Tasnim (C191267)
52
There is only one itemset with minimum support 3. So only one itemset is frequent.
Frequent Itemset (I) = {Coke, Chips}
7.1.1.5
SVM
Suppose we are given the following positively labeled data points in 2D space: ((3, 1), (3, -1), (6, 1), (6, -1)) and the following
negatively labeled data points in 2D space: ((1, 0), (0,1), (0, -1), (- 1,0)). In addition, three support vectors are {(1, 0), (3, 1), (3, 1),) Apply Support Vector Machine to classify data objects (2, 1). 06
Positively labeled data points in 2D space :
{(3,1), (3,-1), (6,1),(6,-1)}
Positively labeled data points in 2D space :
{(1,0), (0,1), (0,-1),(-1,0)}
support vectors are {(1, 0), (3, 1), (3, -1)
3
Here, S1= (10), S2= (31), S3= (−1
)
Each vector augmented with 1
3
̌ = (10), 𝑆2
̌ = (31), 𝑆3
̌ = (−1
)
Here, 𝑆1
1
1
1
̌ 𝑆1
̌ + α2 𝑆2
̌ 𝑆1
̌ + α3 𝑆3
̌ 𝑆1
̌ =-1______________________(i)
α1 𝑆1
̌ 𝑆2
̌ + α2 𝑆2
̌ 𝑆2
̌ + α3 𝑆3
̌ 𝑆2
̌ =+1______________________(ii)
α1 𝑆1
̌ 𝑆3
̌ + α2 𝑆2
̌ 𝑆3
̌ + α3 𝑆3
̌ 𝑆3
̌ =+1______________________(iii)
α1 𝑆1
from equation (i),
1
1
3
1
3
1
1
1
1
1
1
1
α1 (0) , (0), + α2 (1) (0)+ α3 (−1) (0),=-1
α1(1+0+1) + α2 (3+0+1) + α3 (3-0+1) =-1
2 α1 + 4α2+ 4α3=-1-------------------------(Iv)
Tasnim (C191267)
53
from equation (ii),
1
3
3
3
3
3
1
1
1
1
1
1
α1 (0) (1)+ α2 (1) (1), + α3 (−1) (1)=1
α1(3+0+1) + α2 (9+1+1) + α3 (9-0+1) =1
3 α1 + 11α2+ 9α3=+1-------------------------(v)
from equation (iii),
1
3
3
3
3
3
1
1
1
1
1
1
α1 (0) (−1)α2 (1) (−1), + α3(−1) (−1)=+1
α1(3-0+1) + α2 (9-1+1) + α3 (9+1+1) =1
4 α1 +9α2+ 11α3=+1-------------------------(vi)
From equation (iv), (v), (vi)
α1 = -3.5
α2 =0.75
α3=0.75
̌
Wight vector, 𝑤
̂=∑𝑖 αi𝑆𝑖
̌ + α2 𝑆2
̌ + α3 𝑆3
̌
= α1 𝑆1
1
3
3
1
1
1
=-3.5(0)+0.75(1)+0.75(−1)
1
=( 0 )
−2
The vector is augmented with bias,
Hyperplane equation, y=wx+b
With (10) and b= -2
Here (10) means, line will be parallel to y axis,
So, the decision line will be on 2, (-2)
Means in first quadrant in 2 axis and data object (2,1) will be classified as w(21) =(10)(21) =(2+0) =2 so the data object will be on the
positive class.
https://www.youtube.com/watch?v=ivPoCcYfFAw
7.1.1.6
Decision Tree
RID
age
Income
student
credit rating
Class: buys computer
1
youth
High
no
fair
no
2
youth
High
no
excellent
no
3
middle aged
High
no
fair
yes
4
senior
Medium
no
fair
yes
5
senior
Low
yes
fair
yes
6
senior
Low
yes
excellent
no
7
middle aged
Low
yes
excellent
yes
8
youth
Medium
no
fair
no
9
youth
Low
yes
fair
yes
10
senior
Medium
yes
fair
yes
11
youth
Medium
yes
excellent
yes
12
middle aged
Medium
no
excellent
yes
13
middle aged
High
yes
fair
yes
14
senior
Medium
no
excellent
no
Build a Decision Tree for the given data using information gain.
Entropy before partition:
5
5
9
5
E(s) = - 14log214- 14log214 =0.94
Now calculate entropy for each attribute
Tasnim (C191267)
youth
Middle age
senior
yes
2
4
3
no
3
0
2
54
Attribute (Age):
2
2 3
3
E(youth)= - 5log25- 5log25 =0.97
4
4 0
3 2
2
0
E (Middle age) = - 4log24- 4log24 =0
3
E(senior)= - 5log25- 5 log25 =0.97
Information gain (Age):
Using formula: G (S, A) = Entropy (S)-∑𝑣∈𝑣𝑎𝑙𝑢𝑒𝑠(𝐴)
5
4
|𝑆𝑣|
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣)
𝑆
5
G (S, Age) = 0.94- ((14 *0.97) + (14 *0) +(14 *0.97)) =0.24
Attribute (Income):
2
2 2
2
E(High)= - 4log24- 4log24 =1
4
4 2
High
medium
low
2
E (medium) = - 6log2 6-6log26 =0.92
3
3 1
yes
2
4
3
no
2
2
1
Yes
6
3
No
1
4
1
E (low)= - 4log24- 4 log24 =0.81
Information gain (Income):
Using formula: G (S, A) = Entropy (S)-∑𝑣∈𝑣𝑎𝑙𝑢𝑒𝑠(𝐴)
4
6
|𝑆𝑣|
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣)
𝑆
4
G (S, Income) = 0.94- ((14 *1) + (14 *0.92) +(14 *0.81)) =0.028
Attribute (Student):
6
6 1
1
E(yes)= - 7log27- 7log27 =0.59
3
3 0
4
E (No) = - 7log27- 4log27 =0.98
yes
no
Information gain (Student):
Using formula: G (S, A) = Entropy (S)-∑𝑣∈𝑣𝑎𝑙𝑢𝑒𝑠(𝐴)
7
|𝑆𝑣|
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣)
𝑆
7
G (S, Student) = 0.94- ((14 *0.59) + (14 *0.98)) =0.15
Attribute (Credit rating):
6
6 2
2
8
8 8
8
3
3 3
E (fair)= - log2 - log2 =0.81
3
E (excellent) = - 6log26- 6log26 =1
fair
excellent
Information gain (Credit rating):
Using formula: G (S, A) = Entropy (S)-∑𝑣∈𝑣𝑎𝑙𝑢𝑒𝑠(𝐴)
8
|𝑆𝑣|
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣)
𝑆
6
G (S, Credit rating) = 0.94- ((14 *0.81) + (14 *0) =0.048
Information gain for all attribute:
Attribute
Age
Income
Student
Credit Rating
Tasnim (C191267)
Information gain
0.24
0.028
0.15
0.048
Yes
6
3
No
2
3
55
Second iteration omit age only for youth
ID
Income
Student
Credit rating
Class: Buy Computer
1
high
no
fair
no
2
high
no
Excellent
no
8
medium
no
fair
no
9
low
yes
fair
yes
11
medium
yes
Excellent
yes
2
2 3
3
E(s) = - 5log25- 5log25 =0.97
Attribute (Income):
0
0 2
2
E(High)= - 2log22- 2log22 = 1
1
1 1
High
medium
low
1
E (medium) = - 2log22- 2log22 = 1
1
1 0
yes
0
1
1
no
2
1
0
Yes
2
0
No
0
3
0
E (low)= - 1log21- 1 log21 =0
Information gain (Income):
Using formula: G (S, A) = Entropy (S)-∑𝑣∈𝑣𝑎𝑙𝑢𝑒𝑠(𝐴)
2
2
|𝑆𝑣|
𝑆
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣)
1
G (S, Income) = 0.94- ((5 *0) + ((5 *1) +((5*0)) =0.57
Attribute (Student):
2
2 0
0
E(yes)= - 2log22- 2log22 =0
0
0 3
3
3
3 3
3
E (No) = - log2 - log2 =0
yes
no
Information gain (Student):
Using formula: G (S, A) = Entropy (S)-∑𝑣∈𝑣𝑎𝑙𝑢𝑒𝑠(𝐴)
2
|𝑆𝑣|
𝑆
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣)
3
G (S, Student) = 0.97- ((5 *0) + (5 *0)) =0.97
Attribute (Credit rating):
1
1 2
2
1
1 1
E (fair)= - 3log23- 3log23 =0.92
1
E (excellent) = - 2log22- 2log22 =1
fair
excellent
Information gain (Credit rating):
Using formula: G (S, A) = Entropy (S)-∑𝑣∈𝑣𝑎𝑙𝑢𝑒𝑠(𝐴)
3
2
|𝑆𝑣|
𝑆
G (S, Credit rating) = 0.94- ((5 *0.92) + (5 *0) =0.018
Tasnim (C191267)
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣)
Yes
2
1
No
2
1
56
Attribute
Income
Student
Credit Rating
Information gain
0.57
0.97
0.018
Second iteration omit age only for Senior
3
ID
Income
Student
Credit rating
Class: Buy Computer
4
medium
no
fair
yes
5
low
yes
fair
yes
6
low
yes
Excellent
no
10
medium
yes
fair
yes
14
medium
no
Excellent
no
3 2
2
E(s) = - 5log25- 5log25 =0.97
Attribute (Income):
2
2 1
1
E (medium) = - 3log23- 3log23 = 0.92
1
1 1
medium
low
1
E (low)= - 2log22- 2 log22 =0
yes
2
1
no
1
1
Yes
2
1
No
1
1
Information gain (Income):
Using formula: G (S, A) = Entropy (S)-∑𝑣∈𝑣𝑎𝑙𝑢𝑒𝑠(𝐴)
3
|𝑆𝑣|
𝑆
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣)
2
G (S, Income) = 0.94- ((5 *0.92) + ((5 *0) =0.18
Attribute (Student):
2
2 1
1
E(yes)= - 3log23- 3log23 =0.92
1
1 1
1
E (No) = - 2log22- 2log22 =1
yes
no
Information gain (Student):
Using formula: G (S, A) = Entropy (S)-∑𝑣∈𝑣𝑎𝑙𝑢𝑒𝑠(𝐴)
3
|𝑆𝑣|
𝑆
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣)
2
G (S, Student) = 0.97- ((5 *0.92) + (5 *1)) =0.018
Attribute (Credit rating):
3
3 0
0
E (fair)= - 3log23- 3log23 =0
fair
excellent
Tasnim (C191267)
Yes
3
0
No
0
2
57
0
0 2
2
E (excellent) = - 2log22- 2log22 =0
Information gain (Credit rating):
Using formula: G (S, A) = Entropy (S)-∑𝑣∈𝑣𝑎𝑙𝑢𝑒𝑠(𝐴)
3
|𝑆𝑣|
𝑆
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣)
2
G (S, Credit rating) = 0.94- ((5 *0) + (5 *0) =0.97
Attribute
Income
Student
Credit Rating
7.1.1.7 Naïve bias
https://www.youtube.com/watch?v=XzSlEA4ck2I
7.1.1.8
Delta rule:
Tasnim (C191267)
Information gain
0.018
0.018
0.97
58
7.1.1.9
Back propagation
Tasnim (C191267)


![[#GEOD-114] Triaxus univariate spatial outlier detection](http://s3.studylib.net/store/data/007657280_2-99dcc0097f6cacf303cbcdee7f6efdd2-300x300.png)