Exploratory Data Analysis and
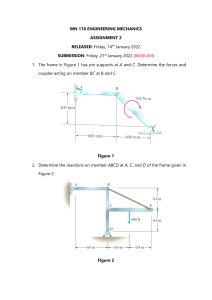
Feature Engineering
AI HPC Curriculum
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
1
Contents
1.
What is Exploratory Data Analysis?
2.
Why Exploratory Data Analysis (EDA)?
3.
Why need to know the shape of the charts
4.
Steps for Exploratory Data Analysis (EDA) ?
5.
Types of variables: Numerical and Categorical
6.
Explore the different Charts Types: univariate, bivariate and multivariate charts
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
2
1. What is Exploratory Data Analysis (EDA)?
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
4
What is exploratory data analysis (EDA)?
•
In statistics, exploratory data analysis (EDA) is an approach to analyzing data
sets to summarize their main characteristics, often with data visualisation
methods.
•
Exploratory data analysis has been promoted by John Tukey since 1970 to
encourage statisticians to explore the data, and possibly formulate hypotheses
that could lead to new data collection and experiments.
•
EDA focuses on checking assumptions required for model fitting and
hypothesis testing, and handling missing values and making transformations
of variables as needed.
Reference:
https://en.wikipedia.org/wiki/Exploratory_data_analysis
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
2. Why Exploratory Data Analysis (EDA)?
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
6
Why Exploratory Data Analysis (EDA)?
The objectives of EDA are to:
▪ Discover the “shape” or characteristics of your data set:
▪ Are there natural “clusters” of data?
▪ Which fields seem to be related or unrelated to each other?
▪ Provide some clues about “interesting” aspects about your data set that warrants deeper
investigation or more data collection
▪ Are there some visible trends (e.g. increase in A is associated with increase in B, or
increase in A is associated with decrease in C)?
▪ Are there any missing data from your prior data collection
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
7
3. Why need to know the shape of the
charts
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
8
Why Need to know the shape of the data?
Doesn’t statistics tells us everything we need
There are lies, damned lies and statistics.
Mark Twain
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
9
Anscombe’s quartet
▪
It is important to plot data and not just look at summary statistics
▪
Anscombe's quartet comprises four datasets (next slide) that have
nearly identical simple statistical properties, yet appear very
different when graphed.
▪
Each dataset consists of eleven (x,y) points. They were constructed
in 1973 by the statistician Francis Anscombe to demonstrate both
the importance of graphing data before analyzing it and the effect of
outliers on statistical properties.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
10
Data (4 sets of data – designed by Francis Ascombe)
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
11
Properties and values of the Data
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
12
Questions: Are properties such as mean and variance of these
Charts similar? What are your observation of the charts below?
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
13
4. Steps in EDA
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
14
Sample: analyse employment engagement
Steps: from loading the data (raw data), understanding the
data (understand and clean), data exploratory to the final
result
Data Wrangling process: To measure employee engagement (explain in next slide)
Data Exploratory
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
15
Data Wrangling process for Employment Engagement (sample)
Data wrangling process flow diagram to understand how accurate
and actionable data can be obtained for business analysts to work
on.
1) Employee Engagement data is in its raw form initially.
2) It gets imported as a DataFrame and is later cleaned.
3) The cleaned data is then transformed into corresponding graphs,
from which insights can be modeled.
4) Based on these insights, we can communicate the final results.
For example, employee engagement can be measured based on
raw data gathered from feedback surveys, employee tenure, exit
interviews, one-on-one meetings, and so on. This data is cleaned
and made into graphs based on parameters such as referrals,
faith in leadership, and scope of promotions.
5) The percentages, that is, insights generated from the graphs,
help us to determine the measure of employee engagement.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
16
Types of variables
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
17
Variable Types
Discrete
Numerical
Continuous
Variables
Nominal
Categorical
Ordinal
Date/Time
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
18
Numerical Variable
▪ Discrete variable: It is a variable that may contain whole numbers
Examples:
▪ Number of items bought by a customer in a supermarket (1 or 2 or 10 items)
▪ Number of pets in the family
▪ Continuous variable: It is a variable that may contain any value within some
range
Examples:
▪ Amount paid by a customer in a supermarket ($32.50, $100.60)
▪ House price ($2,000,000, $500,000)
▪ Time spent surfing a website (3.4 seconds, 5 minutes)
▪ Total profit ratio (0.2, 0.4)
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
19
Categorical Variable
Categorical variables are selected from a group of categories. They are also called labels.
▪ Nominal Variable: It is a variable with no specific order.
▪ Examples:
▪ Gender (Male, Female)
▪ Married status (Single, Married, divorce or widowed)
▪ Intended use of loan (car purchase or house renovation)
▪ Ordinal Variable: It is a variable in which categories can be ordered
▪ Examples:
▪ Student’s grade in an exam (A, B, C)
▪ Days of the week (Monday = 1, Tuesday =2)
▪ Educational Level (Primary, Secondary, Polytechnic, University)
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
20
Quiz 1
What is a discrete variable? Choose one answer
o
A discrete variable is a numerical variable where
values are whole number or counts
o
A discrete variable is a numeric variable that
doesn’t want to be on the spotlight
o
A discrete variable is a variable that takes a finite
number of values. For example it take values from 1
to 20.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
21
Quiz 2
Identify an example of a continuous variable? Choose
one answer.
o
Number of children at school
o
Litres of petrol consume by a vehicle by day.
o
Number of students attended Python Programing
class
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
22
Exploratory Data Analysis and
Feature Engineering
AI HPC Curriculum
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
23
Explore the different Chart Types
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
24
Charts Types: Univariate, Bivariate and Trivariate
There are three types of analysis:
Univariate analysis is to examine the distribution of cases on a single variable at
a time, e.g. no of student with academic degree qualification. The purpose of
univariate analysis is to describe. It does not deal with relationships or causes.
Univariate data uses central tendency such as mean, mode or median and
frequency distributions
Bivariate analysis is to examine two variables simultaneously, e.g. the
relationship between height and weight of students. The purpose of bivariate
analysis is to explain the relationships of the two variables. It uses correlations,
comparisons and relationships.
Multivariate analysis is to examine more than two variables simultaneously,
e.g., the relationship between age, salary and race of students. Multivariate
graphs display the relationships among three or more variables.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
25
Univariate Analysis
For visualizing univariate distributions, these are some of the
charts you could consider.
▪
▪
▪
▪
barplot()
countplot()
distplot()
kdeplot()
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
26
Dataset Name: Salary.csv
Size: 3.26 Mbytes
No of variables: 6
No of records: 59 437
sno
District
Salary
Age
English
Education
Gender
0
Brooklyn
120000
31
Only language
Academic degree
Male
1
Brooklyn
45000
28
Only language
Academic degree
Female
2
Manhatten
85000
54
Only language
Academic degree
Male
3
Manhatten
12000
45
Only language
High school diploma
Female
4
Brooklyn
0
75
Very well
Academic degree
Female
5
Manhatten
225000
47
Very well
Academic degree
Male
6
Brooklyn
55000
37
Only language
Academic degree
Female
7
Brooklyn
50000
37
Only language
Academic degree
Male
8
Brooklyn
37000
34
Only language
Academic degree
Female
9
Brooklyn
65000
34
Only language
High school diploma
Male
10
Brooklyn
30000
38
Only language
High school diploma
Male
11
Brooklyn
900
65
Only language
Academic degree
Female
12
Staten Island
175000
65
Only language
Academic degree
Female
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
27
Barplot showing the mean salary of male and female
# Read salary data set and plot a bar chart using seaborn
import numpy as np
import pandas as pd
import seaborn as sns
data= pd.read_csv ("H-Data\salary.csv")
#Each bin of a barplot displays the mean of a variable.
sns.barplot(x="Gender", y="Salary", data=data, palette="dark")
Figure: Barplot with mean value
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
28
Barplot showing the median salary of male and female
# Read salary data set and plot a bar chart using seaborn
import numpy as np
import pandas as pd
import seaborn as sns
data= pd.read_csv ("H-Data\salary.csv")
#Each bin of a barplot displays the median of a variable.
sns.barplot(x="Gender", y="Salary", data=data, estimator=np.median, palette="dark")
Figure: Barplot with median value
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
29
Countplot showing the number of staff with the varies qualification
# Read salary data set and plot a bar chart using countplot() function
import numpy as np
import pandas as pd
import seaborn as sns
data= pd.read_csv ("H-Data\salary.csv")
# Countplot function counts the no. of observations per category
# and displays the results as a bar chart
sns.countplot(x="Education", data=data, palette="pastel")
Figure: Countplot
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
30
Countplot showing education and gender
# A horizontal bar charts for education level and gender.
# Use countplot() function and hue parameter
import numpy as np
import pandas as pd
import seaborn as sns
data= pd.read_csv ("H-Data\salary.csv")
sns.countplot(y="Education", hue="Gender", data=data, palette="pastel")
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
31
Dataset Name: tips.csv
Size: 8 Kbytes
No of variables: 7
No of records: 244
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
32
Distplot() to plot a histogram
• Plot a histogram. The size of the bin is 2
#Use distplot() function to plot a histogram
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
data = sns.load_dataset("tips")
sns.displot(data, x="tip",binwidth=2)
plt.title ("Amount of tips received(US$)")
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
33
Kernel Density Estimation (KDE)
• KDE shows the probability density function of the variable. A continuous curve
is drawn to generate a smooth density estimation for the whole data. The area
between the density curve and horizontal x-axis is 1.
# Use kdeplot() function to generate a chart where
# Draw a chart with random samples from a normal distribution
import numpy as np
import pandas as pd
import seaborn as sns
x=np.random.normal(size=50)
sns.kdeplot(x, shade=True)
Figure: Kdeplot()
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
34
Bivariate Analysis
▪
For visualizing bivariate distributions, these are some charts
you could consider:
•
jointplot()
•
regplot()
•
Implot()
•
pairplot()
•
violinplot()
•
squarify.plot()
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
35
Dataset Name: tips.csv
Size: 8 Kbytes
No of variables: 7
No of records: 244
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
36
Jointplot showing the relationship between two variables
• Use jointplot() function to draw a plot of two variables with bivariate and
univariate graphs.
# use jointplot() function – to draw scatter plot and marginal histograms to analyse the distribution
of each measure.
#Use jointplot()
import pandas as pd
import seaborn as sns
tips = sns.load_dataset("tips")
g = sns.jointplot(x="total_bill", y="tip", data=tips)
Figure: scatter plot with marginal histograms
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
37
regplot() or implot() to plot relationship between 2 variables
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
df = sns.load_dataset('tips')
sns.regplot(x = "total_bill", y = "tip", data = df)
sns.lmplot(x = "total_bill", y = "tip", data = df)
plt.show()
One Insight:
There is a positive correlation between total bill and tip.
The higher the amount of total bill (eg US$30)
the higher the amount of tip (US$4) will be given
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
38
Dataset Name: basic_details.csv
Size: 1 Kbytes
No of variables: 4
No of records: 10
Height
150
143
123
165
176
189
194
142
134
146
Weight
76
64
86
35
86
47
76
46
87
46
Age
25
27
28
43
63
21
56
67
39
48
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
Groups
A
A
A
B
B
B
C
C
C
C
39
Visualize pairwise relationships (pairplot())
• This function creates a matrix where off-diagonal elements visualise the relationship between
each pair of variables and the diagonal elements show the marginal distributions
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
mydata = pd.read_csv("basic_details.csv")
sns.set(style="ticks", color_codes=True)
Figure: Seaborn pair plot and hue
#use pairplot() function, add a hue variable changes the marginal plot to KDE
g = sns.pairplot(mydata, hue="Groups", palette="coolwarm")
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
40
Plot using violinplot()
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
41
What is violin plot?
•
A Violin Plot is used to visualise the distribution of the data and
its probability density.
•
This chart is a combination of a Box Plot and a Density Plot that
is rotated and placed on each side, to show the distribution
shape of the data. The white dot in the middle is the median
value and the thick black bar in the centre represents the
interquartile range. The thin black line extended from it
represents the upper (max) and lower (min) adjacent values in
the data.
•
With violin plot, you can see if the distribution is bimodal or
multimodal. While Violin Plots display more information, they
can be noisier than a Box Plot.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
42
Method 1: Plot violin plot using violinplot()
•
It combines the box plots with the kernel density estimation
procedure.
•
It provides a richer description of the variable’s distribution
•
The quartile and whisker values from the box plot are shown
inside the violin.
# Use violinplot() function
import pandas as pd
import seaborn as sns
data= pd.read_csv ("salary.csv")
sns.violinplot(x="Education", y="Age", data=data)
Figure: Seaborn violin plot
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
43
Method 2: Plot violin plot using catplot() and kind=“violin”
# Use catplot() function and kind="violin"
import pandas as pd
import seaborn as sns
data= pd.read_csv ("H-data\salary.csv")
Figure: catplot() and kind=“violin”
sns.catplot(x="Education", y="Age", data=data, kind='violin')
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
44
Two insights from the violinplot
• The grouped violin plot shows female chicks tend to weigh less than males
in each feed type category.
• The median weight difference is more pronounced for linseed-fed chicks
than soybean-fed chicks.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
45
Use Squarify to plot Tree Map
•
Squarify library is built on top of Matplotlib
•
Tree maps display hierarchical data as a set of nested
rectangles.
•
Each group is represented by a rectangle. Each area is
proportional to its value
•
Use color schemes, if it is possible to represent hierarchies:
groups, subgroups and so on.
•
Compare to pie charts, tree maps efficiently use space.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
46
Dataset Name: Water_usage.csv
Size: 1 Kbytes
No of variables: 2
No of records: 6
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
47
Use squarify library to plot a tree map
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import squarify
data = pd.read_csv('H-Data/water_usage.csv')
#green shades for the diff rectangles
greens= sns.light_palette("green", 6)
prec = '(' + data.Percentage.astype(str) + '%)'
#Use squarify to plot our data, label it and add colours.
squarify.plot(sizes=data.Percentage,
label= data.Usage ,
value = prec ,color= greens)
plt.axis("off") #remove axes
plt.title('Water Usage', fontsize=16, fontweight="bold") #add title
plt.show()
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
48
Multivariate Analysis
For multivariate analysis, it looks at more than two variables and their
relationship. Use facetgrid to plot multivariate charts.
About facegrid plot
•
It is useful for visualizing multiple variables separately.
•
It can be drawn with up to 3 dimensions; row, col and hue
•
The row and col correspondence to the rows and columns of an array
•
The hue shows with different colors
•
The FacetGrid class has to be initialized with a DataFrame and the
names of the variables that form the row, column or hue dimensions of
the grid
•
The variables should be categorical or discrete
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
49
Plot facetgrid with scatter plot
Two insights:
1) The employees that
worked in Manhatten
District, and with age range
from 30 to 70 have higher
annual salary of between
US$200K to US$400 K as
compared to other districts
2) The annual salary for
empolyees who worked in
Bronx district is lower; the
salary is in general, less
than US$200K as
compared to other districts.
Figure: FacetGrid
with scatter plots
© 2022 National Supercomputing Centre (NSCC) Singapore.
rights reserved.
All
50
Summary – Exploratory Data Analysis
At the end of this section on Exploratory Data Analysis (EDA), you should
be able to:
▪
▪
Understand the need for exploratory data analysis (EDA)
Know how to plot Univariate, Bivariate and Multivariate charts
© 2022 National Supercomputing Centre (NSCC) Singapore. All rights reserved.
51
Exploratory Data Analysis and
Feature Engineering
AI HPC Curriculum
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
52
7. What is Feature Engineering?
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
53
What is a Feature?
▪ A “feature” is an attribute. Data is it’s core. Features are derived from data. It is a measurable input that can
be used in a predictive model.
▪ A dataset is a collection of data, usually presented in a tabular form. Each column represents a particular
variable or attribute, and each row corresponds to a given observation of the data. Below is an example of
Titanic dataset. There are some alternative teams for column, row and value.
▪ Column or field or attribute or variable or feature
▪ Row or record or object or instance
▪ Value or data
▪ In predictive modelling, attributes or variables are the input variables/predictors and target attribute is the
output variable whose value is determined by the values of the input variables/predictors and function of the
predictive model. In the above example, the input variables are pclass, sex, age and the output variable is
survived.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
54
What is Feature Engineering?
▪ Feature engineering is the process of using domain knowledge of the data to create
features that make machine learning algorithms work. Feature engineering is a
machine learning technique that leverages data to create new variables that aren’t in
the training set. It can produce new features for both supervised and unsupervised
learning, with the goal of simplifying and speeding up data transformations while
also enhancing model accuracy. For the example below, :Hourofday is a new
column/variable created.
▪ Feature engineering is the process of selecting, manipulating, and transforming
raw data into features that can be used in supervised learning. All the values are
numeric. For example, male is transformed to value “1” and female is transformed to
value “0”
▪ Feature engineering is the act of converting raw observations into desired features
using either statistical or machine learning approaches.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
55
Feature Engineering Process
Feature engineering in machine learning consists of four main steps. The goal is to
create and select features that will achieve the most accurate ML algorithm.
▪ Feature Creation: Creating features involves creating new variables which will
be most helpful for our model. This can be adding or removing some features.
Example, adding a new variable such as Hourofday column/variable.
▪ Transformation: Feature transformation is simply a function that transforms
features from one representation to another. For example, female is represented
by value “0” and male is represented by value “1”. The goal here is to plot and
visualise data, add new features or reduce features used, speed up training, or
increase the accuracy of a certain model.
▪ Feature Extraction: Feature extraction is the process of extracting features from
a data set to identify useful information. Without distorting the original
relationships. It reduces the amount of data into manageable quantities for
algorithms to process. Principal components analysis is an example of feature
extraction.
▪ Feature Selection: It is the process of selectively reducing the number of input
variables. Feature algorithms analyse features for relevance and use a scoring
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
method to rank the features and decide
which should be removed
56
Feature Engineering Process
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
57
8. Importance of Feature Engineering
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
58
Importance Of Feature Engineering
▪ Feature Engineering is a very important step in machine learning. Feature
engineering refers to the process of designing artificial features into an
algorithm. These artificial features are then used by that algorithm in order to
improve its performance, or in other words reap better results. Data scientists
spend most of their time with data, and it becomes important to make models
accurate.
▪ When feature engineering activities (feature engineering and feature selection)
are done correctly, the resulting dataset is optimal and contains all of the
important factors or key information that affect the business problem. The
outcome is accurate predictive models and the useful insights.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
59
9. Missing data Imputation techniques
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
60
Objectives
Understand the different techniques for missing data imputation
▪ Learn missing data imputation with pandas
▪ Learn how to implement it with scikit-learn and feature-engine
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
61
Missing data imputation techniques – use Pandas
What is imputation?
Imputation is to replace missing data with statistical estimates of the
missing values. The goal is to produce a data set that we can use to
train machine leaning models. Below are techniques to impute
missing values for both numerical and categorical variables.
Numerical Variables
▪ Mean Imputation
▪ Median Imputation
Categorical Variables
▪ Frequent category imputation
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
62
Numerical Variables: Mean and median imputation
Price (impute missing data
using mean)
Price
100
90
50
Mean = 76
Median = 80
60
80
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
100
90
50
76
60
76
80
63
Numerical Variables: When to use mean and median for
imputation
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
64
Categorical Variables: Frequent Category Imputation
▪ Mode Imputation – replace missing values for a variable by the mode or the most frequent occurrence
values for that variable.
Make
Toyota
Make
Mode = Toyota
Toyota
Toyota
Toyota
BMW
BMW
Fiat
Fiat
Toyota
Audi
Audi
Toyota
Fiat
Fiat
Toyota
Toyota
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
65
When to use mode imputation technique
When to use mode imputation technique
▪ Data is missing completely at random
▪ No more than 5% of the variable contains missing data
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
66
Missing data imputation – Feature-Engine
What is feature-engine in Python?
▪ Feature Engine is a Python library with multiple transformers to engineer and
select features for use in machine learning models. Feature-engine's
transformers follow scikit-learn's functionality with fit () and transform () methods
to first learn the transforming parameters from data and then transform the data.
To learn more about feature-engine,click the URL below
https://feature-engine.readthedocs.io/en/latest/index.html
In jupyter notenbook, Install feature engine library
pip install feature_engine
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
67
Advantages of feature-engine library
▪ It allows you to implement specific engineering steps to specific feature subsets
▪ It works with scikit-learn (Scikit-learn is an open source machine learning library
that supports supervised and unsupervised learning. It also provides various
tools for model fitting, data pre-processing, model selection and evaluation, and
many other utilities)
▪ It allows you to design and store a feature engineering pipeline for different
variable groups. Pipeline is from obtaining data, cleaning data, EDA, Modelling
the data and interpreting the data.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
68
Exploratory Data Analysis and
Feature Engineering
AI HPC Curriculum
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
69
10. Categorical Variable Encoding
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
70
Categorical Variable Encoding
When you are working on Machine Learning Algorithms, the input variables have to be
numerical
▪ Categorical variables need to be converted or encoded into a number
Categorical encoding refers to replacing the category strings by a numerical representation
Objectives of categorical variable encoding:
▪ To produce variables that can be used to train machine learning model
▪ To build predictive features from categories
Common encoding categorical variables techniques:
▪ Dummy variable encoding
▪ One-hot encoding of frequent categories
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
71
Categorical Variable Encoding: Dummy variables encoding
Table 2: Dummy variable encoding “Red” color is encoded as [1 0] vector of size 2
“Blue” color is encoded as [0 1] vector or size 2
“Yellow” color is encoded as [0 0] vector of size 2
In summary, a categorical variable is encoded by creating
K-1 binary variable where K is the number of distinct categories
In the above example, the “Color” column is the original column.
The “Color” variable has 3 values, “Red”, :Blue” and “Yellow”, i.e., K = 3.
The number of dummy variables is 3-1 = 2.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
The “Color” column is replaced
by 2 new
columns.
rights reserved.
72
Categorical Variable Encoding: One-hot encoding
What is one-hot encoding?
One-hot encoding is used to convert categorical variables into a format that
can be readily used by machine learning algorithms. The basic idea of onehot encoding is to create new variables that take on values 0 and 1 to represent
the original categorical values.
Below example, the “Color” column is the original column. The “Color” variable
has 3 values, “Red”, :Blue” and “Yellow”. The Color column is being replaced
with 3 new columns.
One-hot encoding of variables = number of values
“Red” color is encoded as [1 0 0] vector of size 3
Table 1: One-hot encoding
“Blue” color is encoded as [0 1 0] vector or size 3
© 2022 National
Supercomputing
Centre (NSCC)
Singapore. All as [0 0 1] vector of size 3
“Yellow”
color
is encoded
rights reserved.
73
When and advantages of dummy encoding and one-hot
encoding
When to use one-hot encoding and dummy encoding
▪ Both types of encoding can be used to encode ordinal and nominal categorical
variables.
▪ Dummy variable encoding is typically used in data analysis
▪ One-host encoding is used in automated tools such as Azure Machine Learning
Studio or Python library
Advantages of dummy encoding over one-hot encoding
▪ Dummy encoding adds fewer dummy variables than one-hot encoding
▪ Dummy encoding removes a duplicate category in each categorical variable.
This avoids the dummy variable trap.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
74
Why you should not use label variable encoding?
What is label variable coding?
▪ Label Encoding refers to converting the labels into a numeric form so as to
convert them into machine-readable form. Suppose we have a column weight in
some dataset
Weight
Heavy
Average
Light
Weight
0
1
2
Apply label encoding, the
weight column is converted
into
0 is the label for Heavy
1 is the label for Average
2 is the label for light
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
75
Limitation of Label Encoding
Label encoding assigned a unique number (starting from 0) to each class of data.
It leads to the generation of priority issues in the training data sets.
A label with a high value may consider to have a high priority and one with a low
value has a lower priority. But this is not true as there is no such priority relation
between the weights.
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
76
Summary of Feature Engineering
You learnt the following under feature engineering:
• What is Feature Engineering?
• Importance of Feature Engineering
• Missing data imputation techniques: Numerical and Categorical variables
• Categorical Variable Encoding: Dummy variable encoding, One-hot encoding
and label encoding
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
77
Summary of topic 2: EDA and Feature Engineering
Your Learnt the following:
1.
What is Exploratory Data Analysis?
2.
Why Exploratory Data Analysis (EDA)?
3.
Why need to know the shape of the charts
4.
Steps for Exploratory Data Analysis (EDA) ?
5.
Types of variables: Numerical and Categorical
6.
Explore the different Charts Types: univariate, bivariate and multivariate charts
7. What is Feature Engineering?
8. Importance of Feature Engineering
9. Missing data imputation techniques
10. Categorical variable encoding
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
78
References
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
79
References
▪ Mario Dobler and Tim GroBmann (2019), Data Visualization with Python, Packt Publishing
▪ Guozhu Dong and Huan Liu, Fea(2018), Feature Engineering for Machine Learning and Data Analytics,
CRC Press
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
80
Thank You
Thank You for Your Attention
© 2022 National Supercomputing Centre (NSCC) Singapore. All
rights reserved.
81