Piecewise Normalizing Flows
arXiv:2305.02930v1 [stat.ML] 4 May 2023
H. T. J. Bevins1,2,∗ , Will J. Handley1,2
1
Cavendish Astrophysics, University of Cambridge
Cavendish Laboratory, JJ Thomson Avenue, Cambridge, CB3 0HE
2
Kavli Institute for Cosmology, University of Cambridge
Madingley Road, Cambridge, CB3 0HA
∗
htjb2@cam.ac.uk
Abstract
Normalizing flows are an established approach for modelling complex probability
densities through invertible transformations from a base distribution. However, the
accuracy with which the target distribution can be captured by the normalizing
flow is strongly influenced by the topology of the base distribution. A mismatch
between the topology of the target and the base can result in a poor performance, as
is the case for multi-modal problems. A number of different works have attempted
to modify the topology of the base distribution to better match the target, either
through the use of Gaussian Mixture Models [Izmailov et al., 2020, Ardizzone
et al., 2020, Hagemann and Neumayer, 2021] or learned accept/reject sampling
[Stimper et al., 2022]. We introduce piecewise normalizing flows which divide
the target distribution into clusters, with topologies that better match the standard
normal base distribution, and train a series of flows to model complex multi-modal
targets. The piecewise nature of the flows can be exploited to significantly reduce
the computational cost of training through parallelization. We demonstrate the
performance of the piecewise flows using standard benchmarks and compare the
accuracy of the flows to the approach taken in Stimper et al. [2022] for modelling
multi-modal distributions.
1
Introduction
Normalizing flows (NF) are an effective tool for capturing probability distributions given a set of
target samples. They are bijective and differentiable transformations between a base distribution,
often a standard normal distribution, and the target distribution [Papamakarios et al., 2019].
NFs have been applied successfully in a number of fields such as approximating Boltzmann distributions [Wirnsberger et al., 2020], cosmology [Alsing and Handley, 2021, Bevins et al., 2022a,
Friedman and Hassan, 2022], image generation [Ho et al., 2019, Grcić et al., 2021], audio synthesis
[van den Oord et al., 2018], density estimation [Papamakarios et al., 2017, Huang et al., 2018] and
variational inference [Rezende and Mohamed, 2015] among others.
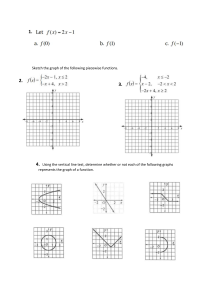
In situations where the target distribution is multi-modal, NFs can take a long time to train well,
and often feature ‘bridges’ between the different modes that are not present in the training data (see
Fig. 1). These bridges arise due to differences between the topology of the base distribution and the
often complex target distribution [Cornish et al., 2019] and is a result of the homeomorphic nature of
the NFs [Runde, 2007].
One approach to deal with multi-modal distributions is to modify the topology of the base distribution.
This was demonstrated in Stimper et al. [2022], in which the authors developed a base distribution
Preprint. Under review.
Target.
MAF
Piecewise MAF
Gaussian Base
Gaussian Base
e.g. Papamakarios et al. 2017
This work
Figure 1: A simple demonstration of the piecewise normalizing flow (NF) described in this paper
and a single NF trained on the same target distribution. We train each NF in the piecewise approach,
of which there are three, and the single NF using early stopping. For the single NF we see bridging
between the different clusters that is not present in the piecewise approach. We use the same MAF
architecture for each network in the piecewise MAF and for the single MAF case.
derived using learned rejection sampling. Typically, the bijective nature of the normalizing flows is
lost when new tools are developed to learn multi-modal probability distributions, however this was
not the case for the resampled base distribution approach discussed in Stimper et al. [2022].
There are a number of other approaches to solve the mismatch between base and target distribution
topologies such as; continuously indexing flows [Cornish et al., 2019], augmenting the space the
model fits in [Huang et al., 2018] and adding stochastic layers [Wu et al., 2020] among others.
A few other works have attempted to use Gaussian mixture models for the base distribution and have
extended various NF structures to perform classification while training. For example, Izmailov et al.
[2020] showed that a high degree of accuracy can be accomplished if data is classified in modes in
the latent space based on a handful of labelled samples. Ardizzone et al. [2020] uses the information
bottleneck to perform classification via a Gaussian mixture model. Similar ideas were explored in
Hagemann and Neumayer [2021].
Our main contribution is to classify samples from our target distribution using a clustering algorithm
and train normalizing flows on the resultant clusters in a piecewise approach where each piece
constitutes a NF with a Gaussian base distribution. This improves the accuracy of the flow and can in
principle reduce the computational resources required for accurate training for two reasons. Firstly,
it is parallelizable and each piece can be trained simultaneously, and secondly if sufficient clusters
are used, the topology of each piece of the target distributions is closer to that of the Gaussian base
distribution. We compare the accuracy of our results against the approach put forward in Stimper
et al. [2022] using a series of benchmark multi-modal distributions.
2
Normalizing Flows
If we have a target distribution X and a base distribution Z ∼ N (µ = 0, σ = 1) then via a change of
variables we can write
δz
p(x) = p(z) det
.
(1)
δx
If there is a bijective transformation between the two f then z can be approximated by fθ−1 (x) and
the change of variable formula becomes
−1
δfθ (x)
p(x) = p(fθ−1 (x)) det
,
(2)
δx
2
where θ are the parameters describing the transformation from the base to target distribution. Here,
the absolute of the determinant of the Jacobian represents the volume contraction from pZ to pX . The
transformation f corresponds to the normalizing flow, and in our work we use Masked Autoregressive
Flows (MAFs) which were proposed for density estimation by Papamakarios et al. [2017] and are
based on the Masked Autoencoder for Distribution Estimation (MADE) outlined in Germain et al.
[2015]. θ are the weights and biases of the MADE networks that make up the flow.
The N dimensional target distribution is decomposed into a series of one dimensional conditional
distributions
Y
p(x) =
p(xi |x1 , x2 , ..., xi−1 ),
(3)
i
where the index i represents the dimension. Each conditional probability is modelled as a Gaussian
distribution with some standard deviation, σi , and mean, µi , which can be written as
P (xi |x1 , x2 , ..., xi−1 ) = N (µi (x1 , x2 , ..., xi−1 ), σi (x1 , x2 , ..., xi−1 )).
(4)
σi and µi are functions of θ and are output from the network. The optimum values of the network
weights and biases are arrived at by training the network to minimize the KL-divergence between the
target distribution and the reconstructed distribution
D(p(x)||pθ (x)) = −Ep(x) [log pθ (x)] + Ep(x) [log p(x)].
(5)
The second term in the KL divergence is independent of the network and so for a minimization
problem we can ignore this and
−Ep(x) [log pθ (x)] = −
N
1 X
log pθ (xj ),
N j=0
(6)
where j corresponds to a sample in the set of N samples. Our minimization problem becomes
argmax
θ
N
X
log pθ (xj ),
(7)
j=0
or equivalently
argmin −
θ
N
X
log pθ (xj ),
(8)
j=0
and by a change of variables
argmin −
θ
N
X
[log pθ (zj0 ) + log
j=0
δzj0
],
δxj
(9)
where z 0 is a function of θ [Alsing et al., 2019, Stimper et al., 2022] given by
(xj − µj )
zj0 =
.
(10)
σj
Typically, many MADE architectures are chained together to improve the expressivity of the MAF
[Papamakarios et al., 2017].
3
Clustering and Normalizing Flows
We propose a piecewise approach to learning complex multi-modal distributions, in which we
decompose the target distribution into clusters and train individual MAFs on each cluster.
In practice, we have k clusters and for each cluster we train a MAF such that we have a set
x = {x1 , x2 , ..., xk } and pθ = {pθ1 , pθ2 , ..., pθk }.
(11)
Typically, if our samples for our target distribution have been drawn with some weights (i.e. using
an MCMC [e.g. Foreman-Mackey et al., 2013] or Nested Sampling [Skilling, 2006, Handley et al.,
2015] algorithm) we write our loss function over N samples as
argmin −
θ
N
X
wj log pθ (xj ).
j=0
3
(12)
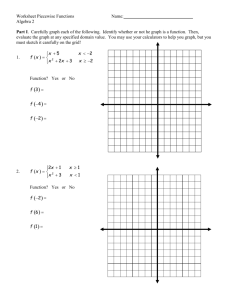
k = 2, s = 0.421
k = 4, s = 0.536
k = 6, s = 0.515
k = 8, s = 0.665
k = 10, s = 0.572
k = 12, s = 0.473
Figure 2: The figure shows how the silhouette score, s, can be used to determine the number of
clusters needed to describe the data. In the example s peaks for eight clusters corresponding to one
for each Gaussian in the circle.
Each set of samples in each cluster has associated weights
w = {w1 , w2 , ..., wk }.
(13)
If we have many clusters then our total loss is given by
X
Nk
N0
N1
X
X
argmin −
w0,j log pθ1 (x0,j ) +
w1,j log pθ2 (x1,j ) + ... +
wk,j log pθk (xk,j ) , (14)
θ
j=0
j=0
j=0
which can be written as
argmin −
θ
NX
Nk
cluster X
k=0
wk,j log pθk (xk,j ).
(15)
j=0
where Ncluster corresponds to the number of clusters.
In our analysis each MAF, pθk (xk ) is trained separately using an ADAM optimizer [Kingma and Ba,
2014]. Since each cluster constitutes a simpler target distribution than the whole and we can train
on different clusters in parallel, we find that we need fewer computing resources when training a
piecewise NF in comparison to training a single NF on the same problem.
To determine the number of clusters needed to best describe the target distribution, we use an average
silhouette score, where the silhouette score for an individual sample is a measure of how similar a
sample is with the samples in its cluster compared to samples outside its cluster [Rousseeuw, 1987].
The silhouette score ranges between -1 and 1 and peaks when the clusters are clearly separated and
well-defined, as in Fig. 2.
Our approach is independent of the choice of clustering algorithm, however in the analysis in this
paper we use K-means [Steinhaus, 1957, MacQueen, 1967].
Once trained, we can draw samples from the clusters in our piecewise normalizing flow with a weight
given by the number of samples in the target cluster relative to the total number of samples in the
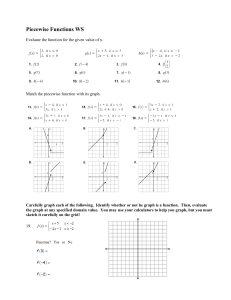
target distribution, wk = Nk /N . This process is shown in Fig. 3 along with the general flow of
classification and training.
4
Piecewise Normalizing Flows
MAFk=1
w1 = N1 /N
N1
MAFk=2
x ∼ p(x)
N
N2
w2 = N2 /N
N3
w3 = N3 /N
x ∼ pθ (x)
Classifier
MAFk=3
w4 = N4 /N
N4
MAFk=4
Figure 3: The figure shows the training and sampling process for our piecewise NFs. From left to
right, we start with a set of samples x drawn from p(x) and classify the samples into clusters using
a K-means algorithm, determining the number of clusters to use based on the silhouette score. We
then train a Masked Autoregressive Flow on each cluster k using a standard normal distribution as
our base. When drawing samples from pθ (x) we select which MAF to draw from using weights
defined according to the ratio of the number of samples in the cluster and the number of samples in
the original target distribution.
Distribution
Two Moons
Circle of Gaussians
Two Rings
KL-Divergence
MAF
Real NVP
Gaussian Base
Resampled Base
e.g. Papamakarios et al. [2017] Stimper et al. [2022]
0.026 ± 0.041
−0.002 ± 0.012
0.365 ± 0.352
0.081 ± 0.157
0.071 ± 0.557
0.025 ± 0.103
Piecewise MAF
Gaussian Base
This work
0.001 ± 0.013
0.017 ± 0.022
0.005 ± 0.095
Table 1: The table shows the KL-divergence between the target samples for a series of multimodal
distributions and the equivalent representations with a MAF only, a real NVP with a resampled base
distribution [e.g Stimper et al., 2022] and a piecewise MAF. The corresponding distributions are
shown in Fig. 4 and we have used early stopping for training. We find that our piecewise approach is
competitive to the approach detailed in Stimper et al. [2022] for modelling multi-modal probability
distributions. We are effectively modifying the topology of the target distribution to be more like the
base distribution by splitting it in to clusters, whereas Stimper et al. [2022] modified the topology of
the base distribution to be more like the target distribution. Negative KL divergences are a result of
the Monte Carlo nature of the calculation.
4
Benchmarking
We test our piecewise normalising flow on a series of multi-modal problems that are explored in
Stimper et al. [2022]. For each, we model the distribution using a single MAF with a Gaussian
base distribution, a real NVP with a resampled base distribution as in Stimper et al. [2022] and our
piecewise MAF approach. We then calculate the Kullback-Leibler divergence between the original
target distribution and the trained flows.
The log-probability of our piecewise MAF for a sample, x, is given by
log pθ (x) = log
X
Nk
k=0
5
exp(log pθk (x)) ,
(16)
from which we can calculate the Kullback-Leibler divergence and an associated Monte Carlo error
pθ (x)
pθ (x)
1
± √ σ log
,
(17)
Dkl = log
p(x) pθ (x)
p(x) pθ (x)
N
where p(x) is the target distribution, x ∼ pθ (x) and σ(f )g is the standard deviation of f with respect
to g.
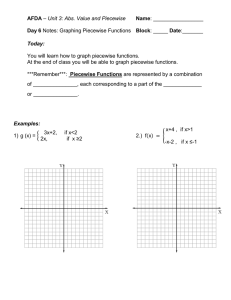
We show the target distributions and samples drawn from each type of flow, a MAF, a piecewise
MAF and a real NVP with a resampled base distribution, in Fig. 4 and report the corresponding
KL-divergences in Tab. 1. We train each flow ten times and calculate an average KL-divergence
for each flow and distribution. We add the associated Monte Carlo errors in quadrature to get an
error on the mean KL-divergence. We find that our piecewise approach outperforms the resampled
base distribution approach of Stimper et al. [2022] for all but one of our benchmarks, where the
models are consistent. We use the code available at https://github.com/VincentStimper/
resampled-base-flows to fit the Real NVP flows and a modified version of the code MARGARINE
[Bevins et al., 2022b,a] available at https://github.com/htjb/margarine to fit the masked
autoregressive flows and piecewise equivalents.
Piecewise MAF
Gaussian Base
This work
Two Rings
Circle of Gaussians
Two Moons
Target
MAF
Gaussian Base
Real NVP
e.g. Papamakarios
Resampled Base
et al. 2017
Stimper et al. 2022
Figure 4: The graph shows a series of multimodal target distributions as 2D histograms of samples in
the first column and three representations of this distribution produced with three different types of
normalizing flow. We use early stopping, as described in the main text, to train all the normalizing
flows. The second column shows a simple Masked Autoregressive Flow with a Gaussian base
distribution based on the work in Papamakarios et al. [2017] and the later two columns show two
approaches to improve the accuracy of the model. The first is from Stimper et al. [2022] and uses
a Real NVP flow to model the distributions while resampling the base distribution to better match
the topology of the target distribution. In the last column, we show the results from our piecewise
normalizing flows where we have effectively modified the topology of the target distribution to better
match the Gaussian base distribution by performing clustering.
6
Each flow in our piecewise approach is composed of a chain of six MADE networks each with two
hidden layers of 50 nodes. For all but the ‘Two Rings’ benchmark, where we increase the number of
MADEs to 10, our individual MAF has the same structure as the networks used in the piecewise flow.
As described, we use the silhouette score to determine the number of clusters needed to describe each
data set and find that we need two clusters to describe the ‘Two Moons’ distribution, eight to describe
the ‘Circle of Gaussians’ and 14 to describe the ‘Two Rings’ distribution.
We use early stopping to train all the flows in the paper, including the real NVP resampled base
models from Stimper et al. [2022]. For the single MAF and real NVP, we use 20% of the samples
from our target distribution as test samples. We early stop when the minimum test loss has not
improved for 2% of the maximum iterations requested, 10,000 for all examples in this paper, and
roll back to the optimum model. For the piecewise MAF, we split each cluster into training and test
samples and perform early stopping on each cluster according to the same criterion, meaning that
each cluster is trained for a different number of epochs.
All the experiments in this paper were run on an Apple MacBook Pro with an M2 chip and 8GB
memory.
5
Limitations
Normalizing flows are useful because they are bijective and differentiable, however these properties
are sometimes lost when trying to tackle multi-modal distributions. Our piecewise approach is
differentiable, provided that the optimization algorithm used to classify the samples from the target
distribution into clusters is also differentiable and k, the number of clusters, is fixed during training.
Differentiability is lost if k changes, however, one can imagine an improved k picking algorithm
where k is determined through minimisation of the loss in equation (15). This is left for future work.
Our piecewise approach is bijective if we know the cluster that our sample has been drawn from.
In other words, there is a one to one mapping between a set of real numbers drawn from an N
dimensional base distribution to a set of real numbers on the N dimensional target distribution plus a
cluster number, n ∈ N
N
RN
(18)
N (µ=0,σ=1) ⇐⇒ Rpθ (x) × N.
With an improved k picking algorithm then the dependence on the cluster number could be relinquished.
Our approach is also limited by the complexity of the target distribution and the number of clusters
required to describe the distribution. However, the complexity of the target distribution also impacts
other methods, such as the resampled base approach of Stimper et al. [2022], and the number of
required clusters is an issue of computational power which can be overcome by training each NF in
parallel.
6
Conclusions
In this work, we demonstrate a new method for accurately learning multi-modal probability distributions with normalizing flows through the aid of an initial classification of the target distribution into
clusters.
Normalizing flows generally struggle with multi-modal distributions because there is a significant
difference in the topology of the base distribution and the target distribution to be learnt. By dividing
our target distribution up into clusters, we are essentially, for each piece, making the topology of the
target distribution more like the topology of our base distribution, leading to an improved expressivity.
Stimper et al. [2022] by contrast, resampled the base distribution so that it and the target distribution
shared a more similar topology. We find that both approaches perform well on our benchmark tests,
but that our piecewise approach is better able to capture the structure of two of the distributions when
training with early stopping. The piecewise nature of our approach allows the MAFs to be trained in
parallel.
Bias in machine learning is currently an active area of concern and research [e.g. Jiang and Nachum,
2020, Mehrabi et al., 2021]. While we have focused on normalizing flows for probability density
estimation in this work, we believe that the general approach has wider applications. One can imagine
7
dividing a training data set into different classes and training a series of generative models to produce
new data. However, instead of drawing samples from each model based on the number of samples in
the original class split, as is done here, one could draw samples based on user defined weights that
give equal weight to each generative model. As such, one can begin to overcome some selection
biases when training machine learning models. Of course the ‘user determined’ nature of the weights
could be used to introduce more bias into the modelling, therefore the method through which they are
derived would have to be explicit and ethically sound.
For the time being, through the combination of clustering and normalizing flows, we are able to
produce accurate representations of complex multi-modal probability distributions.
References
Justin Alsing and Will Handley. Nested sampling with any prior you like. Monthly Notices of the
Royal Astronomical Society, 505(1):L95–L99, July 2021. doi: 10.1093/mnrasl/slab057.
Justin Alsing, Tom Charnock, Stephen Feeney, and Benjamin Wandelt. Fast likelihood-free cosmology with neural density estimators and active learning. Monthly Notices of the Royal Astronomical
Society, 488(3):4440–4458, September 2019. doi: 10.1093/mnras/stz1960.
Lynton Ardizzone, Radek Mackowiak, Carsten Rother, and Ullrich Köthe. Training normalizing
flows with the information bottleneck for competitive generative classification. Advances in Neural
Information Processing Systems, 33:7828–7840, 2020.
Harry Bevins, Will Handley, Pablo Lemos, Peter Sims, Eloy de Lera Acedo, and Anastasia Fialkov.
Marginal Bayesian Statistics Using Masked Autoregressive Flows and Kernel Density Estimators
with Examples in Cosmology. arXiv e-prints, art. arXiv:2207.11457, July 2022a.
Harry T. J. Bevins, William J. Handley, Pablo Lemos, Peter H. Sims, Eloy de Lera Acedo, Anastasia
Fialkov, and Justin Alsing. Removing the fat from your posterior samples with margarine. arXiv
e-prints, art. arXiv:2205.12841, May 2022b. doi: 10.48550/arXiv.2205.12841.
Robert Cornish, Anthony L. Caterini, George Deligiannidis, and A. Doucet. Relaxing bijectivity
constraints with continuously indexed normalising flows. In International Conference on Machine
Learning, 2019.
Daniel Foreman-Mackey, David W. Hogg, Dustin Lang, and Jonathan Goodman. emcee: The MCMC
Hammer. Publications of the Astronomical Society of the Pacific, 125(925):306, March 2013. doi:
10.1086/670067.
Roy Friedman and Sultan Hassan. HIGlow: Conditional Normalizing Flows for High-Fidelity HI
Map Modeling. arXiv e-prints, art. arXiv:2211.12724, November 2022. doi: 10.48550/arXiv.2211.
12724.
Mathieu Germain, Karol Gregor, Iain Murray, and Hugo Larochelle. MADE: Masked Autoencoder
for Distribution Estimation. arXiv e-prints, art. arXiv:1502.03509, February 2015. doi: 10.48550/
arXiv.1502.03509.
Matej Grcić, Ivan Grubišić, and Siniša Šegvić. Densely connected normalizing flows. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in
Neural Information Processing Systems, volume 34, pages 23968–23982. Curran Associates,
Inc., 2021. URL https://proceedings.neurips.cc/paper_files/paper/2021/file/
c950cde9b3f83f41721788e3315a14a3-Paper.pdf.
Paul Hagemann and Sebastian Neumayer. Stabilizing invertible neural networks using mixture
models. Inverse Problems, 37(8):085002, 2021.
W. J. Handley, M. P. Hobson, and A. N. Lasenby. POLYCHORD: next-generation nested sampling.
Monthly Notices of the Royal Astronomical Society, 453(4):4384–4398, November 2015. doi:
10.1093/mnras/stv1911.
8
Jonathan Ho, Xi Chen, Aravind Srinivas, Yan Duan, and Pieter Abbeel. Flow++: Improving flowbased generative models with variational dequantization and architecture design. In Kamalika
Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on
Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2722–2730.
PMLR, 09–15 Jun 2019. URL https://proceedings.mlr.press/v97/ho19a.html.
Chin-Wei Huang, David Krueger, Alexandre Lacoste, and Aaron Courville. Neural autoregressive flows. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International
Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research,
pages 2078–2087. PMLR, 10–15 Jul 2018. URL https://proceedings.mlr.press/v80/
huang18d.html.
Pavel Izmailov, Polina Kirichenko, Marc Finzi, and Andrew Gordon Wilson. Semi-supervised
learning with normalizing flows. In International Conference on Machine Learning, pages 4615–
4630. PMLR, 2020.
Heinrich Jiang and Ofir Nachum. Identifying and correcting label bias in machine learning. In
International Conference on Artificial Intelligence and Statistics, pages 702–712. PMLR, 2020.
Diederik P. Kingma and Jimmy Ba.
abs/1412.6980, 2014.
Adam: A method for stochastic optimization.
CoRR,
J. B. MacQueen. Some methods for classification and analysis of multivariate observations. In
L. M. Le Cam and J. Neyman, editors, Proc. of the fifth Berkeley Symposium on Mathematical
Statistics and Probability, volume 1, pages 281–297. University of California Press, 1967.
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. A survey
on bias and fairness in machine learning. ACM Comput. Surv., 54(6), jul 2021. ISSN 0360-0300.
doi: 10.1145/3457607. URL https://doi.org/10.1145/3457607.
George Papamakarios, Theo Pavlakou, and Iain Murray. Masked autoregressive flow for density
estimation. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and
R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/
file/6c1da886822c67822bcf3679d04369fa-Paper.pdf.
George Papamakarios, Eric T. Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji
Lakshminarayanan. Normalizing flows for probabilistic modeling and inference. J. Mach. Learn.
Res., 22:57:1–57:64, 2019.
Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. In Francis Bach
and David Blei, editors, Proceedings of the 32nd International Conference on Machine Learning,
volume 37 of Proceedings of Machine Learning Research, pages 1530–1538, Lille, France, 07–09
Jul 2015. PMLR. URL https://proceedings.mlr.press/v37/rezende15.html.
Peter J. Rousseeuw. Silhouettes: A graphical aid to the interpretation and validation of cluster
analysis. Journal of Computational and Applied Mathematics, 20:53–65, 1987. ISSN 0377-0427.
doi: https://doi.org/10.1016/0377-0427(87)90125-7. URL https://www.sciencedirect.com/
science/article/pii/0377042787901257.
V. Runde. A Taste of Topology. Springer, 2007.
John Skilling. Nested sampling for general Bayesian computation. Bayesian Analysis, 1(4):833 –
859, 2006. doi: 10.1214/06-BA127. URL https://doi.org/10.1214/06-BA127.
Hugo Steinhaus. Sur la division des corps matériels en parties. Bull. Acad. Pol. Sci., Cl. III, 4:
801–804, 1957. ISSN 0001-4095.
Vincent Stimper, Bernhard Schölkopf, and Jose Miguel Hernandez-Lobato. Resampling base distributions of normalizing flows. Proceedings of The 25th International Conference on Artificial
Intelligence and Statistics, 151:4915–4936, 28–30 Mar 2022. URL https://proceedings.mlr.
press/v151/stimper22a.html.
9
Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu,
George van den Driessche, Edward Lockhart, Luis Cobo, Florian Stimberg, Norman Casagrande,
Dominik Grewe, Seb Noury, Sander Dieleman, Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex
Graves, Helen King, Tom Walters, Dan Belov, and Demis Hassabis. Parallel WaveNet: Fast
high-fidelity speech synthesis. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th
International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning
Research, pages 3918–3926. PMLR, 10–15 Jul 2018. URL https://proceedings.mlr.press/
v80/oord18a.html.
Peter Wirnsberger, Andrew J. Ballard, George Papamakarios, Stuart Abercrombie, Sébastien
Racanière, Alexander Pritzel, Danilo Jimenez Rezende, and Charles Blundell. Targeted free
energy estimation via learned mappings. The Journal of Chemical Physics, 153(14):144112, 2020.
doi: 10.1063/5.0018903. URL https://doi.org/10.1063/5.0018903.
Hao Wu, Jonas Köhler, and Frank Noé. Stochastic normalizing flows. Advances in Neural Information
Processing Systems, 33:5933–5944, 2020.
10