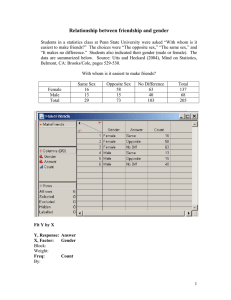
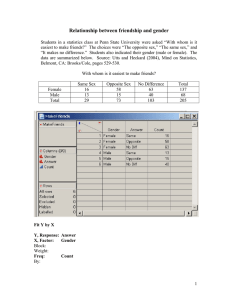
The t-test Inferences about Population Means Questions • What is the main use of the t-test? • How is the distribution of t related to the unit normal? • When would we use a t-test instead of a ztest? Why might we prefer one to the other? • What are the chief varieties or forms of the ttest? • What is the standard error of the difference between means? What are the factors that influence its size? More Questions • Identify the appropriate to version of t to use for a given design. • Compute and interpret t-tests appropriately. • Given that H 0 : 75; H1 : 75; s y 14; N 49; t(.05, 48) 2.01 construct a rejection region. Draw a picture to illustrate. Background • The t-test is used to test hypotheses about means when the population variance is unknown (the usual case). Closely related to z, the unit normal. • Developed by Gossett for the quality control of beer. • Comes in 3 varieties: • Single sample, independent samples, and dependent samples. What kind of t is it? • Single sample t – we have only 1 group; want to test against a hypothetical mean. • Independent samples t – we have 2 means, 2 groups; no relation between groups, e.g., people randomly assigned to a single group. • Dependent t – we have two means. Either same people in both groups, or people are related, e.g., husband-wife, left hand-right hand, hospital patient and visitor. Single-sample z test • For large samples (N>100) can use z to test hypotheses about means. ( X X )2 ( X ) zM est. M • Suppose est . M sX N N 1 N H 0 : 10; H1 : 10; s X 5; N 200 • Then est. M • If sX 5 5 .35 N 200 14.14 X 11 z (11 10) 2.83; 2.83 1.96 p .05 .35 The t Distribution We use t when the population variance is unknown (the usual case) and sample size is small (N<100, the usual case). If you use a stat package for testing hypotheses about means, you will use t. The t distribution is a short, fat relative of the normal. The shape of t depends on its df. As N becomes infinitely large, t becomes normal. Degrees of Freedom For the t distribution, degrees of freedom are always a simple function of the sample size, e.g., (N-1). One way of explaining df is that if we know the total or mean, and all but one score, the last (N-1) score is not free to vary. It is fixed by the other scores. 4+3+2+X = 10. X=1. Single-sample t-test With a small sample size, we compute the same numbers as we did for z, but we compare them to the t distribution instead of the z distribution. H 0 : 10; H1 : 10; s X 5; N 25 est. M sX 5 1 N 25 X 11 t t (.05,24) 2.064 (c.f. z=1.96) Interval = (11 10) 1 1 1<2.064, n.s. X tˆ M 11 2.064(1) [8.936, 13.064] Interval is about 9 to 13 and contains 10, so n.s. Review How are the distributions of z and t related? Given that H 0 : 75; H1 : 75; s y 14; N 49; t(.05, 48) 2.01 construct a rejection region. Draw a picture to illustrate. Difference Between Means (1) • Most studies have at least 2 groups (e.g., M vs. F, Exp vs. Control) • If we want to know diff in population means, best guess is diff in sample means. • Unbiased: E( y1 y2 ) E( y1) E( y2 ) 1 2 • Variance of the Difference: var( y y ) 2 2 • Standard Error: diff M1 M2 1 2 2 M1 M2 2 Difference Between Means (2) • We can estimate the standard error of the difference between means. est. diff est. M2 1 est. M2 2 • For large samples, can use z ( X1 X 2 ) ( 1 2 ) H 0 : 1 2 0; H1 : 1 2 0 zdiff est diff X 10; N 100; SD 2 1 1 1 X 2 12; N 2 100; SD2 3 est. diff z diff 4 9 13 .36 100 100 100 2 (10 12) 0 5.56; p .05 .36 .36 Independent Samples t (1) ( y1 y2 ) ( 1 2 ) est diff • Looks just like z: tdiff • df=N1-1+N2-1=N1+N2-2 • If SDs are equal, estimate is: diff 1 1 N1 N 2 N N 2 1 2 2 2 Pooled variance estimate is weighted average: 2 [( N1 1)s12 ( N 2 1)s22 ] /[1 /( N1 N 2 2)] Pooled Standard Error of the Difference (computed): est. diff ( N1 1) s12 ( N 2 1) s22 N1 N 2 N1 N 2 2 N N 1 2 Independent Samples t (2) est. diff tdiff ( N1 1) s12 ( N 2 1) s22 N1 N 2 2 ( y1 y2 ) ( 1 2 ) est diff N1 N 2 N N 1 2 H 0 : 1 2 0; H1 : 1 2 0 y1 18; s12 7; N1 5 y2 20; s22 5.83; N 2 7 est. diff t diff 4(7) 6(5.83) 12 1.47 5 7 2 35 (18 20) 0 2 1.36; n.s. 1.47 1.47 tcrit = t(.05,10)=2.23 Review What is the standard error of the difference between means? What are the factors that influence its size? Describe a design (what IV? What DV?) where it makes sense to use the independent samples t test. Dependent t (1) Observations come in pairs. Brother, sister, repeated measure. 2 diff M2 1 M2 2 2 cov( y1 , y2 ) Problem solved by finding diffs between pairs Di=yi1-yi2. (D ) D i N s 2 D D E(D ) t est. MD 2 ( D D ) i N 1 est. MD df=N(pairs)-1 sD N Dependent t (2) Brother 5 7 3 y 5 sD Sister 7 8 3 y6 2 ( D D ) N 1 1 Diff 2 1 0 (D D )2 1 0 1 D 1 est. MD 1 / 3 .58 D E(D ) 1 t 1.72 est. MD .58 Assumptions • The t-test is based on assumptions of normality and homogeneity of variance. • You can test for both these (make sure you learn the SAS methods). • As long as the samples in each group are large and nearly equal, the t-test is robust, that is, still good, even tho assumptions are not met. Review • Describe a design where it makes sense to use a single-sample t. • Describe a design where it makes sense to use a dependent samples t. Strength of Association (1) • Scientific purpose is to predict or explain variation. • Our variable Y has some variance that we would like to account for. There are statistical indexes of how well our IV accounts for variance in the DV. These are measures of how strongly or closely associated our Ivs and DVs are. • Variance accounted for: 2 2 2 ( ) 2 Y 2 Y|X 1 2 2 Y 4 Y Strength of Association (2) • How much of variance in Y is associated with the IV? 2 2 Y 2 Y|X 2 Y ( 1 2 ) 2 4 Y2 Compare the 1st (left-most) curve with the curve in the middle and the one on the right. In each case, how much of the variance in Y is associated with the IV, group membership? More in the second comparison. As mean diff gets big, so does variance acct. 0.4 0.3 0.2 0.1 0.0 -4 -2 0 2 4 6 Association & Significance • Power increases with association (effect size) and sample size. • Effect size: d ( X X ) / • Significance = effect size X sample (X ) ( X X ) t size. t 1 1 (independent samples) p 2 1 1 N N 2 1 p2 2 (single sample) 2 N td N Increasing sample size does not increase effect size (strength of association). It decreases the standard error so power is greater, |t| is larger. Estimating Power (1) • If the null is false, the statistic is no longer distributed as t, but rather as noncentral t. This makes power computation difficult. • Howell introduces the noncentrality parameter delta to use for estimating power. For the one-sample t, d n Recall the relations between t and d on the previous slide Estimating Power (2) • Suppose (Howell, p. 231) that we have 25 people, a sample mean of 105, and a hypothesized mean and SD of 100 and 15, respectively. Then d 105 100 1 / 3 .33 15 Howell presents an appendix where delta is related to d n .33 25 1.65 power. For power = .8, alpha = .05, delta must be 2.80. To power .38 solve for N, we compute: 2.8 2 d n; n 8.48 71.91 d .33 2 2 Estimating Power (3) • Dependent t can be cast as a single sample t using difference scores. • Independent t. To use Howell’s method, the result is n per group, so double it. Suppose d = .5 (medium effect) and n =25 per group. d n 25 .50 .5 12.5 1.77 2 2 2.8 n 2 2 62.72 d .5 2 2 Need 63 per group. From Howell’s appendix, the value of delta of 1.77 with alpha = .05 results in power of .43. For a power of .8, we need delta = 2.80 SAS Proc Power – single sample example proc power; onesamplemeans test=t nullmean = 100 The POWER Procedure mean = 105 One-sample t Test for Mean stddev = 15 Fixed Scenario Elements power = .8 Distribution Normal Method Exact ntotal = . ; Null Mean 100 run; Mean 105 Standard Deviation 15 Nominal Power 0.8 Number of Sides 2 Alpha 0.05 Computed N Total Actual N Power Total 0.802 73 ; 2 sample t Power Calculate sample size proc power; twosamplemeans meandiff= .5 stddev=1 power=0.8 ntotal=.; run; Two-sample t Test for Mean Difference Fixed Scenario Elements Distribution Normal Method Exact Mean Difference 0.5 Standard Deviation 1 Nominal Power 0.8 Number of Sides 2 Null Difference 0 Alpha 0.05 Group 1 Weight 1 Group 2 Weight 1 Computed N Total Actual N Power Total 0.801 128 2 sample t Power • proc power; • twosamplemeans • meandiff = 5 [assumed difference] • stddev =10 [assumed SD] • sides = 1 [1 tail] • ntotal = 50 [25 per group] • power = .; *[tell me!]; • run; The POWER Procedure Two-Sample t Test for Mean Difference Fixed Scenario Elements Distribution Method Number of Sides Mean Difference Standard Deviation Total Sample Size Null Difference Alpha Group 1 Weight Group 2 Weight Normal Exact 1 5 10 50 0 0.05 1 1 Computed Power Power 0.539 Typical Power in Psych • Average effect size is about d=.40. • Consider power for effect sizes between .3 and .6. What kind of sample size do we need for power of .8? proc power; twosamplemeans meandiff= .3 to .6 by .1 stddev=1 power=.8 ntotal=.; plot x= power min = .5 max=.95; run; Typical studies are underpowered. Two-sample t Test for 1 Computed N Total Mean Actual N Index Diff Power Total 1 0.3 0.801 352 2 0.4 0.804 200 3 0.5 0.801 128 4 0.6 0.804 90 Power Curves Why a whopper of an IV is helpful. 600 Total Sample Size 500 400 300 200 100 0 0.5 0.6 0.7 0.8 Power Mean Diff 0.3 0.4 0.5 0.6 0.9 1.0 Review • About how many people total will you need for power of .8, alpha is .05 (two tails), and an effect size of .3? • You can only afford 40 people per group, and based on the literature, you estimate the group means to be 50 and 60 with a standard deviation within groups of 20. What is your power estimate?