Linear Programming Lecture Notes: Introduction & Simplex Method
advertisement

Week 1
1 OR Ib in context
2 Introduction of the LP-problem
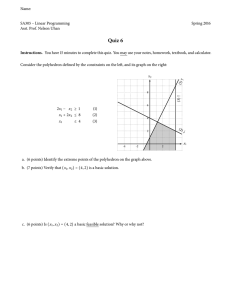
2.1 The Wyndor Glass problem
Decision variables: the variables we need to decide the values for
Objective function: the function that we want to optimize
Restrictions: limitations you need to take into account when deciding on the values of the
decision variables
The objective function and the restrictions should be linear.
The decision variables should be nonnegative.
2.2 Properties of the LP
2.3 Modelling with LP: Notation and Definitions in LP
Modelling a verbally described practical problem as an LP starts with an appropriate choice
of decision variables (usually x,y and z, usually with subindices). After that, we specify the
(linear) objective function of the form
The coefficients (c) are called objective
coefficients. We want to maximize or minimize the objective function (specify with max/min)
in front of the function. Then, the restrictions are constructed. They appear as equalities and
inequalities. Every restriction consists of a left hand side, which is a linear function of the
decision variables and a right hand side that is a constant (usually b with subindex i to
indicate in belongs to the i-th restriction). For the coefficients of the decision variables we
use letter a with subindices ij to indicate that it belongs to the i-th restriction and variable xj.
We call such restrictions functional restrictions (constraints). Besides these, we most often
also have extra restrictions that variables need to be non-negative; xj ≥ 0 (sign constraints or
non-negativity constraints).
Values for all decision variables such that each of the restrictions is satisfied form a feasible
solution. The set of all feasible solutions is called the feasible region. If the feasible region
is non-empty the problem is feasible. Otherwise it is called infeasible.
The generic LP-problem is, written in symbols, as follows, where we have n variables and m
functional restrictions.
You can also write it in vector notation and matrix notation (page 5 of lecture notes).
2.4 Polly’s diet problem
2.5 Inventory-Production Planning
2.6 Energy plant
2.7 A Game as an LP
2.8 The Transhipment Problem
2.9 The Shortest Path Problem
3 Towards a solution method: a geometric interpretatio
We will first study the geometric structure of the feasible regions as a basis for the study of
the simplex method for solving LP-problems.
Typically, the feasible region of an LP problem is a convex set and the optimal solution is
attained in an extreme point of this convex set.
In what follows it may help you to understand all the notions by 3-dimensionally thinking of a
diamond. Each of these inequalities forms a so-called halfspace.
From what we have now learned, the feasible region of an LP-problem is defined as the
intersection of a (finite) number of halfspaces.
The reverse is also true, so any convex set is the intersection of a (possibly infinite)
collection of halfspaces. If the collection is finite, as it is for feasible regions of LP-problems,
then the convex set is called a polyhedron. So, the feasible region of every LP-problem is a
polyhedron: The
A polyhedron does not need to be bounded. A bounded polyhedron is also called a
polytope. There are also LP-problems with unbounded feasible regions.
Every halfspace is defined (and bounded) by a hyperplane.
As we have seen in the Wyndor Glass example, extreme points are the candidates for
optimal solutions. Every point in Rn is determined by the intersection of n linear independent
hyperplanes (equalities). This means that every extreme point of the feasible region of an
LP-problem is determined by n linearly independent hyperplanes that define the boundary of
the polyhedron.
Any feasible point that is determined by n linearly independent bounding hyperplanes is
called basic feasible solution (important notion in the solution method!). Nearly every
polyhedron and certainly every polytope has extreme points.
The simplex method that we will study for solving LP-problems moves from extreme point to
an improving neighbouring extreme point, etc.
Two extreme points are neighbours if the set of hyperplanes on which they lie differ in only
one, they have n − 1 hyperplanes in common. The intersection of n − 1 hyperplanes in Rn is
a line, a 1- dimensional vector space.
The segment of this line between the two neighbouring extreme points of the polyhedron is
called an edge of the polyhedron.
Together the extreme points and the edges form the skeleton of the polyhedron.
Now we can turn these geometric insights into the algebraic simplex method. Basic
component of the method is Gauss-Jordan eliminations for solving systems of linear
equalities. But in LP problems we mostly see inequalities, no equalities. However, we will
show how to turn every LP-problem into its standard form, in which all constraints are
equalities.
4 Optimal solutions and extreme points
In this section we will see that we can prove the intuition that, if the LP has a finite optimal
value then there is an extreme point of the feasible polyhedron which is an optimum. Proofs
in the notes below will not be asked on an exam.
However, for solution methods an algebraic definition is much more useful, which views an
extreme point as a point on the intersection of a number of hyperplanes that bound the
polyhedron.
Hyperplanes or linear constraints are linearly independent if the ai ’s in their description
are linearly independent. In the Rn any point is determined by the
intersection of n linearly independent n−1-dimensional hyperplanes. Any extreme point of a
polyhedron P in IRn is defined as the intersection of n linearly independent hyperplanes that
are bounding P, among them being all on which P lies entirely.
We say that a constraint is tight or active or supporting in a point of P if it is satisfied with
equality in that point. In LP a point that represents a feasible solution in which n linearly
independent constraints are tight is called a basic feasible solution.
Two remarks:
Firstly, two different basic feasible solutions are said to be adjacent on the polyhedron P if
they share n−1 out of the n hyperplanes or active constraints that define each of them.
Secondly, the last theorem implies that there are a finite number, at most O(m^n), of extreme
points in any polyhedron P, since P is the intersection of a finite number m of halfspaces.
The main result is the translation of our intuition from the previous section and is the basic
justification of the idea behind the simplex method.
Week 2 The simplex method
The simplex method is a method that solves any LP-problem. Therefore a standard problem
format has been selected, in which every LP-problem can be translated.
1 The standard LP-model
The simplex method is based on the standard LP-model. This model has the following
properties:
• The objective is maximization (this property is not crucial)
• All functional restrictions are equalities
• All decision variables are non-negative
So, every standard LP-problem is formulated as:
for appropriate choices of c, A, and b.
We will show how to transform any LP-problem into a standard LP-problem.
- If the restrictions are inequalities:
If less than:
. We add a non-negative slack variable si to the left hand
side of the restriction:
. We also add the non-negativity constraint
.
If more than:
. We subtract a non-negative surplus variable ti from the
left hand side of the restriction:
constraint
-
. We also add the non-negativity
.
If decision variables non-positive or unrestricted:
2 Extreme points in the standard LP-model
As we noticed, an extreme point is a point in which a set of n linearly independent
inequalities bounding the feasible region are met with equality. In the standard LP there are
m equalities that have to be satisfied for every feasible point, hence also for every extreme
point. Notice that we assume that m < n, because otherwise the m equations are either
dependent or have no solution.
Assumption 2.1 rank(A) = m
This means that the remaining n−m equalities in an extreme point have to come from the
non-negativity constraints. Thus in every extreme point n−m decision variables must have
value 0. Therefore in any extreme point m decision variables remain that may have any
other value. The n-m variables that are set to 0 in a basic feasible solution are called the
non-basic variables of that solution. The remaining m are called the basic variables.
Their values can be resolved, under linear independence conditions.
Let xB be the m-vector of the basic variables, then the columns of A corresponding to these
variables is denoted by B. B is a basis if and only if its m column-vectors are linearly
independent. In this case B is non-singular and we have learned that the system Bx = b has
unique solution
.
The resulting solution x is called a basic solution. If xB ≥ 0 the solution is called a basic
feasible solution.
See page 3 of the lecture notes for the example of Wyndor Glass.
This basic feasible solution will serve as the starting solution of the simplex method.
Like in the Wyndor Glass, if all original constraints were ≤ inequalities and the right hand
side constants were all non-negative, then every functional constraint receives a slack
variable and choosing the set of all m slack variables as the set of basic variables and all
original decision variables as non-basic variables gives a basic feasible solution. We will
come back to finding a starting solution in cases it is not that straightforward.
We now continue our search for the optimal solution by the simplex method.
3 An improvement step
We will try to improve our starting solution.
Rewriting the objective function of the Wyndor Glass example with all the variable on the left
side gives:
We represent this function together with the other
functional inequalities in the following table:
Such a table (simplex tableau) completely characterizes the solution of an LP-problem. The
columns under the z-row corresponding to s1, s2, and s3 form the basis matrix B, which is
the identity, and hence also B^−1
They form a basis for the space spanned by the columns of the left hand side coefficient
matrix. In the very first column of the table we show from which row the basic variable gets
its value after setting all non-basic variables to 0. Indeed, all variables not displayed in the
very first column are non-basic and have value 0.
We will call the top-row of the tableau the z-rowand the other rows 1, 2, ..., m.
The objective coefficients of x1 and x2 are positive. This is exhibited by negative numbers in
the z-row.
In the simplex method only one of the two is increased at a time. By increasing x1 we bring it
inside the basis and therefore in this iteration of the simplex method we call x1 the entering
variable.
Because we are only interested in extreme points (basic feasible solutions) one of the three
variables s1, s2, and s3 will have to leave the basis. Which one is discovered by
investigating how much we can raise the value of x1 before one of the three basic variables
becomes 0.
For example, in the row of s1, one unit increase in x1 means 1 unit decrease in the slack
variable s1. S1 equals 4, so we can increase x1 by 4 before s1 becomes negative. In the
row of s2 there is no x1. In row of s3 1 unit increase in x1 means 3 units decrease of s3. S3
equals 18, so we can increase x1 by 6 (18/3) before s3 becomes negative.
Comparing the bounds on the increase of x1 by the 1st and the 3rd restriction yields that we
can increase x1 by min{4 , 6}. This comparison is called the minimum ratio test.
Setting x1 to 4 forces s1 = 0. Hence s1 leaves the basis and is therefore in this iteration the
leaving variable.
The new solution becomes x1 = 4, x2 = 0, s1 = 0, s2 = 12, s3 = 18 − 3 × 4 = 6. The new
basis variables are x1, s2 and s3. Non-basic are x2 and s1.
Now we have a new solution, but we want to improve the solution further.
We can show the new solution in a table again. Now we want to increase x2. We can do that
by decreasing s3 (in the row of s3) or decrease x1 (if we decrease x1, s3 increases and we
can use a bigger portion of s3 for increasing x2). We made x1 basic at the expense of s1.
The column of the entering variable (x1 in this case) is called the pivot column. The row
corresponding to the leaving variable (s1 in this case) is called the pivot row. The element
in the pivot column and the pivot row is called pivot element.
Now we turn the column of x1 in the tableau into a unit vector with a 1 in the position of the
pivot element and 0’s everywhere else, including the z-row.
This yields the following tableau:
As you see, we can read the new solution in the tableau. z = 12, x1 = 4, s2 = 12, and s3 = 6.
The non-basic variables x2 and s1 have value 0.
The columns under the z-row of the basic variables x1, s2, s3 are no longer the basis matrix
B, but instead form the identity matrix. This means that by the Gauss-Jordan row operations
we have transformed the new basis matrix
into
.