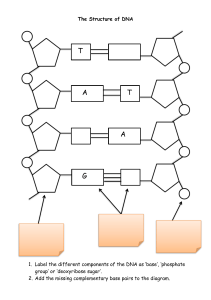
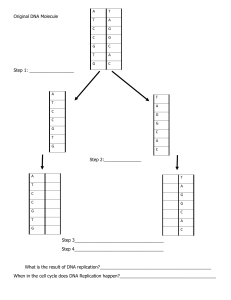
2B: 3 Nucleic acids Introduction Proteins are the actors of cells Each amino acid in the protein: 20 choices Protein of 100 aa = 20100 different possibilities Huge variety of proteins Information for primary structure of proteins is contained in genes Genes made of DNA Transcription mRNA Translation Protein Introduction Nucleic acids = DNA and RNA DNA and RNA are Polynucleotides One Nucleotide Monomer Up to 5 million condensation reactions Polynucleotides Strand of nucleotides Polymer Only in DNA Basic structure of mononucleotides Only in RNA Found both in DNA and RNA There are similitudes between DNA structure and RNA structure There are differences between DNA structure and RNA structure Only in DNA Only inRNA Only in DNA Basic structure of mononucleotides Only in RNA Nucleotides Pentose sugar + Nitrogen base + Phosphate Group Nucleic Acids Polymers of Nucleotides = Polynucleotides Deoxyribonucleic acid Ribonucleic acid DNA RNA Deoxyribose Phosphate Group Nitrogen base (A, C, G, or T) Ribose Phosphate Group Nitrogen base (A, C, G, or U) Basic structure of mononucleotides Only in DNA Only in RNA Nucleotides Pentose sugar + Nitrogen base + Phosphate Group DNA and RNA were first found in nucleus Eukaryotes: DNA never leaves the nucleus (eukaryotes) RNA is produced in nucleus, then leaves nucleus for cytoplasm Nucleic Acids Polymers of Nucleotides = Polynucleotides Prokaryotes: Both DNA and RNA in cytoplasm Deoxyribonucleic acid Ribonucleic acid DNA RNA Deoxyribose Phosphate Group Nitrogen base (A, C, G, or T) Ribose Phosphate Group Nitrogen base (A, C, G, or U) Only in DNA Basic structure of mononucleotides Only in RNA Nucleotides Pentose sugar + Nitrogen base + Phosphate Group Both DNA and RNA contain phosphate groups Related to phosphoric acids Acidify solution Nucleic Acids Polymers of Nucleotides = Polynucleotides Deoxyribonucleic acid Ribonucleic acid DNA RNA Deoxyribose Phosphate Group Nitrogen base (A, C, G, or T) Ribose Phosphate Group Nitrogen base (A, C, G, or U) Basic structure of mononucleotides Only in DNA Only in RNA DNA Nitrogen bases RNA 6 7 1 5 8 00 4 2 9 3 Two rings 4 5 3 00 1 2 6 One ring 00 00 Basic structure of mononucleotides Only in DNA Only in RNA Pentose sugar DNA RNA Ribose Deoxyribose 5’ 5’ 4’ 1’ 3’ 2’ 4’ 1’ 3’ 2’ OH Only in DNA Basic structure of mononucleotides Only in RNA Phosphoric acid / Phosphate group DNA RNA Basic structure of mononucleotides Only in DNA Only in RNA Formation of nucleotide: Two condensation reactions Phosphate linked to 5’ Carbon of pentose By ester bond Base linked to 1’Carbon of pentose By glycosidic bond deoxyribose One out of the 5 nucleotides 3’ Carbon of pentose free for bond with another nucleotide DNA and RNA are polynucleotides Nucleic acids = DNA and RNA DNA and RNA are Polynucleotides One Nucleotide Pentose sugar + Nitrogen base + Phosphate Monomer Up to 5 million condensation reactions Polynucleotides Strand of nucleotides Polymer DNA and RNA are polynucleotides A Polynucleotide = Single STRAND One Nucleotide Sugar + Nitrogen base + Phosphate DNA and RNA are polynucleotides A Polynucleotide = Single STRAND One Nucleotide Sugar + Nitrogen base + Phosphate Sugar-phosphate backbone Never changes Sequence of bases varies DNA and RNA are polynucleotides Bonds between nucleotides= Phosphodiester bonds A Polynucleotide = Single STRAND Nucleotide Sugar + Nitrogen base + Phosphate DNA and RNA are polynucleotides A Polynucleotide = Single STRAND Nucleotide Sugar + Nitrogen base + Phosphate Two nucleotides are bound together: 3’C from nucleotide n with 5’C from nucleotide n+1 DNA and RNA are polynucleotides 5’ A Polynucleotide = Single FirstSTRAND nucleotide 5’C Phosphate free “5’ end” = “5’ Phosphate” Nucleotide Sugar + Nitrogen base + Phosphate A polynucleotide strand has an overall direction 5’ to 3’ or 3’ 3’ to 5’ Last nucleotide 3’C OH free “3’ end” = “3’ OH” Only in DNA Complementary base pairing and the DNA double helix Sugar-phosphate backbone One DNA strand “single-stranded DNA” 5’ end Thymine (T) Adenine (A) Cytosine (C) Guanine (G) 3’ end Phosphate Deoxyribose Nitrogen bases Only in DNA Complementary base pairing and the DNA double helix Sugar-phosphate backbone One DNA strand “single-stranded DNA” ssDNA 5’ end Thymine (T) Adenine (A) Cytosine (C) Guanine (G) 3’ end Phosphate Deoxyribose Nitrogen bases “Double helix” two strands of DNA “double-stranded DNA” dsDNA Only in DNA Complementary base pairing and the DNA double helix Base pairs hold the two DNA strands together A /T G/C A and T are complementary G and C are complementary BASE PAIRS Hydrogen bonds Only in DNA Complementary base pairing and the DNA double helix Sequence second strand deduced from sequence first strand Two strands are complementary Only in DNA Complementary base pairing and the DNA double helix The two strands of DNA are antiparallel (opposite directions) 5’ end 3’ end Hydrogen bond 1 nm 3.4 nm 0.34 nm3’ end 5’ end Structure of RNA Only in RNA Sugar-phosphate backbone One RNA strand “single-stranded RNA” 5’ end Uracil (U) OH RNA is always single-stranded Adenine (A) OH Cytosine (C) OH Guanine (G) OH 3’ end Phosphate ribose Nitrogen bases Structure of RNA Only in RNA Sugar-phosphate backbone One RNA strand “single-stranded RNA” 5’ end Uracil (U) OH mRNA = Messenger RNA Used as a template for protein synthesis Adenine (A) tRNA = Transfer RNA Used for protein synthesis Brings amino acids Cytosine (C) rRNA = Ribosomal RNA Part of Ribosomes OH OH Guanine (G) 3’ end OH Phosphate Deoxyribose Nitrogen bases Only in DNA Structure of DNA and RNA Only in RNA One strand ACG U Two strands ACGT Complementarity Shorter 100-2000 bases Long Millions of base pairs Question: • If there is 30% Adenine, how much Cytosine is present? •There would be 20% Cytosine •Adenine (30%) = Thymine (30%) •Guanine (20%) = Cytosine (20%) •Therefore, 60% A-T and 40% C-G 4: How DNA works The need for DNA replication Cell division requires replication of genetic material Before (almost) each cell division, DNA is replicated DNA replication occurs during the S phase of the cell cycle S = Synthesis of DNA Each strand of the double-stranded DNA is used as a template One double helix….. Two double helices After the cell division, each daughter cell owns the same genetic material The same genetic material as their parent cell No DNA replication between Meiosis I and Meiosis II Process of DNA replication Parent molecule ssDNA New strand ssDNA New strand ssDNA Parent molecule ssDNA Addition of Denaturation Parent molecule dsDNA Parent molecule ssDNA Parent molecule ssDNA New nucleotides Parent molecule ssDNA Parent molecule ssDNA Process of DNA replication Template strand New strand Already added ACG Parental strand New strand = “Template” 5‘ end DNA Polymerase Adds nucleotides One by one The parental strand is used as a template Nitrogenous base Sugar Phosphate To know which nucleotide is to be added next By complementarity A T C G T A G C 3‘ end 3‘ end dTTP) Will be added 5‘ end Process of DNA replication Template strand New strand Already added ACG Parental strand New strand = “Template” 3‘ end 5‘ end Nitrogenous base DNA Polymerase NEEDS the 3’OH from the last added nucleotide to add another nucleotide Via making a phosphodiester bond Sugar Phosphate 3‘ end A T C G T A G C dTTP) Will be added 5‘ end New strand and template strand are antiparallel Process of DNA replication Template strand New strand Already added ACG Parental strand New strand = “Template” 5‘ end DNA replication has an overall direction From 5’ to 3’ of the 3‘ end Nitrogenous base Sugar Phosphate new strand 3‘ end A T C G T A G C dTTP) Will be added 5‘ end Multiple sites The DNA double helix has to be “opened/unwound” To access the information of both strands To know which nucleotides have to be added, and in the right order The replication starts at a Replication 5’ end fork opened by DNA Helicase 3’ end Strands from template Base pairs still held by hydrogen bonds Nucleotide to be added at the 3’end of the new strand 3’ end New strands 5’ end 3’ end 5’ end 5’ end 3’ end Multiple sites Two replication forks make a replication eye/bubble Multiple sites The speed of DNA replication in humans is about 50 nucleotides per second per replication fork The whole human Genome can be copied only in a few hours because there are many replication eyes at the same time The speed of DNA replication in bacteria is much higher (1000 nucleotides per second) The whole bacterial Genome can be copied only in a few minutes. Multiple sites Many sites for DNA replication (replication forks) in Eukaryotes DNA replication only happens during the S phase of the cell cycle Eukaryotes have LONG chromosomes Replication speed: 50 nucleotides per second 3000 nucleotides per minute Longest chromosome of Drosophila (fly) 6.5 x 107 (650 000 000) nucleotides. If only one replication fork, time needed is 150 DAYS This chromosome is replicated in 4 minutes !! The replication of this chromosome uses 54 000 replication forks Three models for DNA replication? Watson and Crick’s model = semiconservative replication Two other models: the conservative model and the dispersive model. Old DNA NewDNA Three models for DNA replication? Which of the three models is right ? Experiments in the late 1950s Matthew Meselson and Franklin Stahl Three models for DNA replication? Centrifugation Centrifugation of DNA DNA DNA Three models for DNA replication? Bacteria: Fast growing One generation = 20 minutes Fast DNA replication All DNA contains… 15N ONLY centrifugation Three models for DNA replication? Old DNA 15N NewDNA 14N New DNA is lighter than old DNA Three models for DNA replication? Old DNA 15N NewDNA 14N New DNA is lighter than old DNA Three models for DNA replication? Old DNA 15N NewDNA 14N New DNA is lighter than old DNA Three models for DNA replication? Old DNA 15N NewDNA 14N New DNA is lighter than old DNA Three models for DNA replication? Old DNA 15N NewDNA 14N New DNA is lighter than old DNA Three models for DNA replication? Old DNA 15N NewDNA 14N New DNA is lighter than old DNA Three models for DNA replication? Old DNA 15N NewDNA 14N New DNA is lighter than old DNA Three models for DNA replication? Old DNA 15N NewDNA 14N New DNA is lighter than old DNA Three models for DNA replication? Old DNA 15N NewDNA 14N New DNA is lighter than old DNA Three models for DNA replication? Old DNA 15N NewDNA 14N New DNA is lighter than old DNA Three models for DNA replication? “Semi-conservative”: KEEP 50% After each DNA Replication, Each double helix contains One strand from the parent molecule One newly made strand Original double helix New strands Review of DNA Replication Important things to remember To ‘copy’ each strand of the double-stranded DNA To “copy” = to complement DNA Helicase breaks hydrogen bonds between paired bases DNA Polymerase adds nucleotides One by one DNA Ligase joins short new strands together into one DNA replication is semi-conservative Bases are added at the 3’OH end of the NEW strand From the 5’P end to the 3’ OH end of the NEW strand From the 3’ OH end to the 5’P end of the TEMPLATE strand 5:Genetic Code The need for a genetic code • Proteins are the actors of cells • Each protein: 20 choices Protein of 100 aa = 20100 different possibilities • Huge variety of proteins • Information for primary structure of proteins is contained in genes Genes made of DNA Transcription mRNA Translation Protein The need for a genetic code There are many types of RNAs tRNAs = transfer RNA rRNAs = Ribosomal RNA mRNAs = Messenger RNA etc… ONLY mRNA are used in translation rRNAs = ribosomal RNAs are parts of ribosomes tRNA = transfer RNAs bring amino acid to the ribosome to elongate a protein being made . The need for a genetic code Why the word “Translation” ? From one language to another From “mRNA language” to “protein language” Goal of translation ? Use the information in mRNA to make protein = Translate the sequence in mRNA to know the sequence of protein that has to be made The need for a genetic code How to know which amino acid is needed? Out of 20 possibilities When we can only use nucleotides Out of only 4 nucleotides ??? We need a CODE The Genetic code The genetic code Four different bases are used to be translated into a combination of 20 different amino acids One base Combinations of two bases Combinations of three bases A C G U 41 = Four combinations Not enough AA AC AG AU CA CC CG CU GA GC GG GU UA UC UG UU 42 = 16 combinations Not enough AAA AAC AAG AAU ACA ACC ACG ACU ....... UUA UUC UUG UUU 43 = 64 combinations Enough + EXTRA The genetic code Triplet = codon The genetic code The need for a genetic code An overview of gene expression Characteristics of the genetic code The genetic code 1. Is degenerate 2. Contains “punctuation codons” 3. Is non-overlapping 4. Is more-or-less universal The genetic code is degenerate •There are four bases, so there are 64 different codons (triplets) possible (43 = 64), yet there are only 20 amino acids that commonly occur in biological proteins • This is why the code is said to be degenerate: multiple codons can code for the same amino acids • The degenerate nature of the genetic code can limit the effect of mutations Characteristics of the genetic code 1. The genetic code is degenerate The genetic code requires at least 20 codons minimum It contains 64 codons Contains more information than required While Methionine and Tryptophane are encoded by single codons All other amino acids are encoded by more than one codon “Degeneracy” = the third base of the codon looks less important than the first and second bases e.g. Phenylalanine encoded by UUU and UUC e.g. Proline encoded by CCU, CCC, CCA and CCG Characteristics of the genetic code 1. The genetic code is degenerate Transfer RNAs = tRNAs tRNAs bring/transfer the amino acids One given tRNA always brings the SAME amino acid When making the protein, the mRNA sequence is used as a template First codon – First amino acid is brought Second codon – Second amino acid is brought etc… The tRNAs recognise the codons How ? Using the complementarity of bases between mRNA and tRNAs Characteristics of the genetic code 1. The genetic code is degenerate An anticodon is complementary to a codon Genetic code is degenerate One amino acid will be attached to One tRNA - one anticodon (TRP and Met) Or More than one tRNA – more than one anticodon (LEU – 6 tRNAs – 6 anticodons) Characteristics of the genetic code 2. The genetic code contains “punctuation codons” 2.1 The three stop codons Three codons do not encode any amino acids UAA UAG UGA If they are “read” by the ribosome, translation will end They do not attract any tRNA+amino acid They attract a release factor = a protein that can fit in the ribosome where new tRNA+amino acid enter the ribosome Presence of release factor in ribosome ends translation The last amino acid is encoded by the codon just before the stop codon Characteristics of the genetic code 2. The genetic code contains “punctuation codons” 2.2 The Start/Methionine codon The codon AUG encodes the amino acid Methionine AND The codon AUG marks the position where translation starts CONFUSION ? What if a mRNA contains several AUG codons ? Start translation at each AUG? Multiple proteins out of one single mRNA? Only the first AUG is THE start codon Any other AUG is used for Methionine All proteins have Methionine as their first amino acid Characteristics of the genetic code 3. The genetic code is non-overlapping In a mRNA molecule, codons are consecutive. The non-overlapping nature of the genetic code means that each base is only read once. The adjacent codons do not overlap A non-overlapping code means that the same letter is not used for two different codons; in other words, no single base can take part in the formation of more than one codon Characteristics of the genetic code 3. The genetic code is non-overlapping An anticodon is complementary to a codon Genetic code is non-overlapping A tRNA matches one codon, then the next tRNA matches the next codon Characteristics of the genetic code 4. The genetic code is more-or-less universal All organisms use the same genetic code The same triplet codes code for the same amino acids in all living things (meaning that genetic information is transferable between species) exception = mitochondria in humans A few exceptions (reality) Consequence: Transgenic organisms are possible The universal nature of the genetic code is why genetic engineering , the transfer of genes from one species to another is possible 6: Protein Synthesis Key Players • mRNA carries the information from a gene in DNA. • Ribosomes, made of rRNA, consist of subunits and carry out an enzyme-like role. • tRNA carries specific amino acids to the ribosome. Transcription • RNA polymerase is the enzyme responsible for making mRNA copies of genes. DNA unzips at the site of the gene that is needed. Transcription • RNA polymerase matches bases in the sense strand with RNA bases, building a strand of mRNA that carries the information encoded in the DNA. Transcription • Encoded in DNA is a signal telling RNA polymerase where to stop. Transcription ends at that point. Transcription • The completed mRNA primary transcript then undergo mRNA processing and moves from the nucleus to the ribosomes for translation. Translation • Initiation begins with a tRNA bearing methionine (met) attaching to one of the ribosomal units. The codon for methionine is a universal “start” codon for “reading” the mRNA strand. Translation • The ribosomal unit binds to mRNA where the code for met is located (AUG). The anticodon (UAC) of the tRNA matches the “start” codon on mRNA (AUG). Translation • The larger ribosomal subunit now binds to the smaller unit, forming a ribosomal complex. The tRNA binds to the first active site on the ribosome. Translation may now begin. Translation • The second codon in mRNA (GUU) matches the anticodon of a tRNA carrying the amino acid valine (CAA). The second tRNA binds to the second active site on the large subunit. Translation • A catalytic site on the larger subunit binds the two amino acids together using dehydration synthesis, forming a peptide bond between them. Translation • The first tRNA now detaches and goes of to find another met in the cytoplasm. The mRNA chain shifts over one codon, placing the second codon (CAU) over the second active site. Translation • A tRNA with an anticodon (GUA) matching the exposed codon (CAU) moves onto the ribosome. This tRNA carries histidine (his). Translation • A new peptide bond forms between val and his on the catalytic site. The tRNA that carried val will detach and find another val in the cytoplasm. The mRNA strand will then shift over one more codon. Translation • The process continues until the ribosome finds a “stop” codon. The subunits detach from one another, the mRNA is released, and the polypeptide chain moves down the ER for further processing. The initial met is removed and the chain is folded into its final shape. Summary