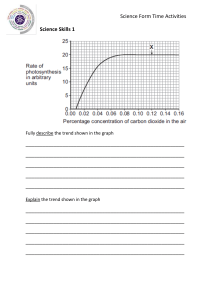
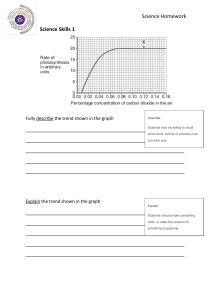
Time Series Cheat Sheet
By Marcelo Moreno - King Juan Carlos University
As part of the Econometrics Cheat Sheet Project
Basic concepts
Definitions
Time series - is a succession of quantitative observations
of a phenomena ordered in time.
There are some variations of time series:
Panel data - consist of a time series for each observation
of a cross section.
Pooled cross sections - combines cross sections from
different time periods.
Stochastic process - sequence of random variables that
are indexed in time.
Components of a time series
Trend - is the long-term general movement of a series.
Seasonal variations - are periodic oscillations that are
produced in a period equal or inferior to a year, and can
be easily identified on different years (usually are the result of climatology reasons).
Cyclical variations - are periodic oscillations that are
produced in a period greater than a year (are the result
of the economic cycle).
Residual variations - are movements that do not follow a recognizable periodic oscillation (are the result of
eventual non-permanent phenomena that can affect the
studied variable in a given moment).
Type of time series models
Static models - the relation between y and x’s is contemporary. Conceptually:
yt = β0 + β1 xt + ut
Distributed-lag models - the relation between y and
x’s is not contemporary. Conceptually:
yt = β0 + β1 xt + β2 xt−1 + ... + βs xt−(s−1) + ut
The long term cumulative effect in y when ∆x is:
β1 + β2 + ... + βs
Dynamic models - a temporal drift of the dependent
variable is part of the independent variables (endogeneity). Conceptually:
yt = β0 + β1 yt−1 + ... + βs yt−s + ut
Combinations of the above, like the rational distributedlag models (distributed-lag + dynamic).
Assumptions and properties
Trends and seasonality
Spurious regression - is when the relation between y and
Under this assumptions, the estimators of the OLS param- x is due to factors that affect y and have correlation with
eters will present good properties. Gauss-Markov as- x, Corr(x, u) ̸= 0. Is the non-fulfillment of ts3.
sumptions extended applied to time series:
Trends
ts1. Parameters linearity and weak dependence.
Two time series can have the same (or contrary) trend, that
a. yt must be a linear function of the β’s.
should lend to a high level of correlation. This, can provoke
b. The stochastic {(xt , yt ) : t = 1, 2, ..., T } is station- a false appearance of causality, the problem is spurious
ary and weakly dependent.
regression. Given the model:
ts2. No perfect collinearity.
y t = β0 + β1 x t + u t
There are no independent variables that are con- where:
stant: Var(xj ) ̸= 0
yt = α0 + α1 Trend + vt
There is not an exact linear relation between indext = γ0 + γ1 Trend + vt
pendent variables.
Adding a trend to the model can solve the problem:
ts3. Conditional mean zero and correlation zero.
yt = β0 + β1 xt + β2 Trend + ut
a. There are no systematic errors: E(ut |x1t , ..., xkt ) = The trend can be linear or non-linear (quadratic, cubic, exE(ut ) = 0 → strong exogeneity (a implies b).
ponential, etc.)
b. There are no relevant variables left out of the Another way is making use of the Hodrick-Prescott filter
model: Cov(xjt , ut ) = 0 for any j = 1, ..., k → to extract the trend (smooth) and the cyclical component.
weak exogeneity.
ts4. Homoscedasticity. The variability of the residuals Seasonality
A time series with can man- y
is the same for any x: Var(ut |x1t , ..., xkt ) = σu2
ts5. No auto-correlation. The residuals do not contain ifest seasonality. That is,
information about other residuals: Corr(ut , us |x) = 0 the series is subject to a seasonal variations or pattern,
for any given t ̸= s.
ts6. Normality. The residuals are independent and iden- usually related to climatology conditions.
tically distributed (i.i.d. so on): u ∼ N (0, σu2 )
ts7. Data size. The number of observations available must For example, GDP (black)
be greater than (k + 1) parameters to estimate. (It is is usually higher in summer and lower in winalready satisfied under asymptotic situations)
ter. Seasonally adjusted set
Asymptotic properties of OLS
ries (red) for comparison.
Under the econometric model assumptions and the Central This problem is spurious regression. A seasonal adLimit Theorem:
justment can solve it.
Hold (1) to (3a): OLS is unbiased. E(β̂j ) = βj
A simple seasonal adjustment could be creating station Hold (1) to (3): OLS is consistent. plim(β̂j ) = βj (to ary binary variables and adding them to the model. For
(3b) left out (3a), weak exogeneity, biased but consistent) example, for quarterly series (Qqt are binary variables):
Hold (1) to (5): asymptotic normality of OLS (then, yt = β0 + β1 Q2t + β2 Q3t + β3 Q4t + β4 x1t + ... + βk xkt + ut
(6) is necessarily satisfied): u ∼ N (0, σu2 )
Another way is to seasonally adjust (sa) the variables, and
a
Hold (1) to (5): unbiased estimate of σu2 . E(σ̂u2 ) = σu2 then, do the regression with the adjusted variables:
sa
Hold (1) to (5): OLS is BLUE (Best Linear Unbiased zt = β0 + β1 Q2t + β2 Q3t + β3 Q4t + vt → v̂t + E(zt ) = ẑt
sa
sa
sa
ŷt = β0 + β1 x̂1t + ... + βk x̂kt + ut
Estimator) or efficient.
Hold (1) to (6): hypothesis testing and confidence inter- There are much better and complex methods to seasonally
adjust a time series, like the X-13ARIMA-SEATS.
vals can be done reliably.
OLS model assumptions under time series
ts1.6-en - github.com/marcelomijas/econometrics-cheatsheet - CC BY 4.0
Auto-correlation
The residual of any observation, ut , is correlated with the
residual of any other observation. The observations are not
independent. Is the non-fulfillment of ts5.
Corr(ut , us |x) ̸= 0 for any t ̸= s
Consequences
OLS estimators still are unbiased.
OLS estimators still are consistent.
OLS is not efficient anymore, but still a LUE (Linear
Unbiased Estimator).
Variance estimations of the estimators are biased:
the construction of confidence intervals and the hypothesis testing is not reliable.
Detection
Scatter plots - look for scatter patterns on ut−1 vs.
ut .
Ac.
Ac.(+)
Ac.(-)
ut
ut
ut
ut−1
ut−1
ut−1
E
IV
E
IV
0
S
LU
S
LU
NC
CO
IN
ACF
1
NC
CO
IN
Correlogram - composed – Y axis: correlation [-1,1].
of the auto-correlation – X axis: lag number.
function (ACF) and the – Blue lines: ±1.96/T 0.5
partial ACF (PACF).
– MA(q) process. ACF: only the first q coefficients
Under H0 : No auto-correlation:
are significant, the remaining are abruptly canceled.
T · Rû2 t ∼ χ2q
or
T · Rû2 t ∼ χ2p
a
a
PACF: attenuated exponential fast decay or sine
* H1 : Auto-correlation of order q (or p).
waves.
– Ljung-Box Q test:
– AR(p) process. ACF: attenuated exponential fast
* H1 : There is auto-correlation.
decay or sine waves. PACF: only the first p coefficients are significant, the remaining are abruptly can- Correction
Use OLS with a variance-covariance matrix estimaceled.
tor that is robust to heterocedasticity and auto– ARMA(p,q) process. ACF and PACF: the coefcorrelation (HAC), for example, the one proposed by
ficients are not abruptly canceled and presents a fast
Newey-West.
decay.
Use Generalized Least Squares (GLS). Supposing
If the ACF coefficients do not decay rapidly, there is
yt = β0 + β1 xt + ut , with ut = ρut−1 + εt , where |ρ| < 1
a clear indicator of lack of stationarity in mean, which
and εt is white noise.
would lead to take first differences in the original series.
–
If ρ is known, use a quasi-differentiated model:
Formal tests - Generally, H0 : No auto-correlation.
yt − ρyt−1 = β0 (1 − ρ) + β1 (xt − ρxt−1 ) + ut − ρut−1
Supposing that ut follows an AR(1) process:
yt∗ = β0∗ + β1′ x∗t + εt
ut = ρ1 ut−1 + εt
′
where β1 = β1 ; and estimate it by OLS.
where εt is white noise.
–
If ρ is not known, estimate it by -for example– AR(1) t test (exogenous regressors):
ρ̂1
the Cochrane-Orcutt iterative method (Praist = se(ρ̂1 ) ∼ tT −k−1,α/2
Winsten method is also good):
* H1 : Auto-correlation of order one, AR(1).
1. Obtain ût from the original model.
– Durbin-Watson statistic (exogenous regressors and
2. Estimate ût = ρût−1 + εt and obtain ρ̂.
residual normality):
Pn
2
3.
Create a quasi-differentiated model:
(û −û
)
d = t=2Pnt û2t−1 ≈ 2 · (1 − ρ̂1 ) , 0 ≤ d ≤ 4
y
t
t=1
t − ρ̂yt−1 = β0 (1 − ρ̂) + β1 (xt − ρ̂xt−1 ) + ut − ρ̂ut−1
* H1 : Auto-correlation of order one, AR(1).
yt∗ = β0∗ + β1′ x∗t + εt
d= 0 2 4
′
where β1 = β1 ; and estimate it by OLS.
ρ ≈ 1 0 -1
4.
Obtain û∗t = yt − (β̂0∗ + β̂1′ xt ) ̸= yt − (β̂0∗ + β̂1′ x∗t ).
f (d)
5. Repeat from step 2. The method finish when the
estimated parameters vary very little between iterRej. H0
Accept H0
Rej. H0
ations.
AR(+)
AR(-)
No AR
If not solved, look for high dependence in the series.
0
-1
dL
dU
2
4−
d
U
4−
d
L
4
PACF
1
0
-1
Conclusions differ between auto-correlation processes.
– Durbin’s h (endogenous regressors):
q
T
h = ρ̂ · 1−T
·υ
where υ is the estimated variance of the coefficient associated to the endogenous variable.
* H1 : Auto-correlation of order one, AR(1).
– Breusch-Godfrey test (endogenous regressors): it
can detect MA(q) and AR(p) processes (εt is w. noise):
* MA(q): ut = εt − m1 ut−1 − ... − mq ut−q
* AR(p): ut = ρ1 ut−1 + ... + ρp ut−p + εt
ts1.6-en - github.com/marcelomijas/econometrics-cheatsheet - CC BY 4.0
Stationarity and weak dependence
Stationarity means stability of the joints distributions of
a process as time progresses. It allows to correctly identify the relations –that stay unchange with time– between
variables.
Stationary and non-stationary processes
Stationary process (strong stationarity) - is the one
in that the probability distributions are stable in time:
if any collection of random variables is taken, and
then, shifted h periods, the joint probability distribution
should stay unchanged.
Non-stationary process - is, for example, a series with
trend, where at least the mean changes with time.
Covariance stationary process - is a weaker form of
stationarity:
– E(xt ) is constant.
– Var(xt ) is constant.
– For any t, h ≥ 1, the Cov(xt , xt+h ) depends only of h,
not of t.
Strong dependence time series
Most of the time, economics series are strong dependent (or
high persistent in time). Some special cases of unit root
processes, I(1):
Random walk - an AR(1) process with ρ1 = 1.
yt = yt−1 + et
where {et : t = 1, 2, ..., T } is an i.i.d. sequence with zero
mean and σe2 variance (the latter changes with time).
Weak dependence time series
The process is not stationary, is persistent.
It is important because it replaces the random sampling Random walk with a drift - an AR(1) process with
assumption, giving for granted the validity of the Central
ρ1 = 1 and a constant.
Limit Theorem (requires stationarity and a form of weak
yt = β0 + yt−1 + et
dependence). Weakly dependent processes are also known
where {et : t = 1, 2, ..., T } is an i.i.d. sequence with zero
as integrated of order zero, I(0).
mean and σe2 variance.
Weak dependence - restricts how close the relationship
The process is not stationary, is persistent.
between xt and xt+h can be as the time distance between
I(1) detection
the series increases (h).
An stationary time process {xt : t = 1, 2, ..., T } is Augmented Dickey-Fuller (ADF) test - where H0 :
the process is unit root, I(1).
weakly dependent when xt and xt+h are almost indepen Kwiatkowski–Phillips–Schmidt–Shin (KPSS) test dent as h increases without a limit.
where H0 : the process have no unit root, I(0).
A covariance stationary time process is weakly depen-
Cointegration
When two series are I(1), but a linear combination of
them is I(0). If the case, the regression of one series over
the other is not spurious, but expresses something about
the long term relation. Variables are called cointegrated if
they have a common stochastic trend.
For example: {xt } and {yt } are I(1), but yt − βxt = ut
where {ut } is I(0). (β get the name of cointegration parameter).
Heterocedasticity on time series
The assumption affected is ts4, which leads OLS to be
not efficient.
Some tests that work could be the Breusch-Pagan or
White’s, where H0 : No heterocedasticity. It is important
for the tests to work that there is no auto-correlation (so
first, it is imperative to test for it).
ARCH
An auto-regressive conditional heterocedasticity (ARCH),
is a model to analyze a form of dynamic heterocedasticity,
dent if the correlation between xt and xt+h tends to 0 fast Transforming unit root to weak dependent
where the error variance follows an AR(p) process.
enough when h → ∞ (they are not asymptotically corre- Unit root processes are integrated of order one, I(1).
Given the model:
lated).
This means that the first difference of the process is
yt = β0 + β1 zt + ut
Some examples of stationary and weakly dependent time weakly dependent or I(0) (and usually, stationary). For
where, there is AR(1) and heterocedasticity:
series are:
example, a random walk:
E(u2t |ut−1 ) = α0 + α1 u2t−1
Moving average - {xt } is a moving average of order one
y
∆yt = yt − yt−1 = et
GARCH
MA(q):
where {et } = {∆yt } is i.i.d.
A general auto-regressive conditional heterocedasticity
xt = et + m1 et−1 + ... + mq et−q
(GARCH), is a model similar to ARCH, but in this case,
where {et : t = 0, 1, ..., T } is an i.i.d. sequence with zero Getting the first difference
the error variance follows an ARMA(p,q) process.
mean and σe2 variance.
of a series also deletes its
Auto-regressive process - {xt } is an auto-regressive trend.
process of order one AR(p):
Predictions
For example,
a series
xt = ρ1 xt−1 + ... + ρp xt−p + et
with a trend (black), and
Two types of prediction:
where {et : t = 0, 1, ..., T } is an i.i.d. sequence with zero it’s first difference (red).
Of the mean value of y for a specific value of x.
2
mean and σe variance.
Of an individual value of y for a specific value of x.
t
If |ρ1 | < 1, then {xt } is an AR(1) stable process that
is weakly dependent. It is stationary in covariance, When an I(1) series is strictly positive, it is usually con- If the values of the variables (x) approximate to the mean
values (x), the confidence interval amplitude of the predicCorr(xt , xt−1 ) = ρ1 .
verted to logarithms before taking the first difference. That
ARMA process - is a combination of the two above. is, to obtain the (approx.) percentage change of the series: tion will be shorter.
yt − yt−1
{xt } is an ARMA(p,q):
∆ log(yt ) = log(yt ) − log(yt−1 ) ≈
xt = et + m1 et−1 + ... + mq et−q + ρ1 xt−1 + ... + ρp xt−p
yt−1
A series with a trend cannot be stationary, but can
be weakly dependent (and stationary if the series is detrended).
ts1.6-en - github.com/marcelomijas/econometrics-cheatsheet - CC BY 4.0