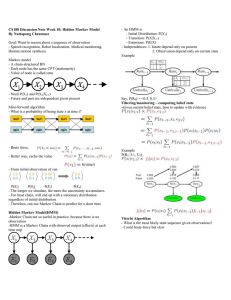
MARKOV CHAIN AND HIDDEN MARKOV MODEL
JIAN ZHANG
JIANZHAN@STAT.PURDUE.EDU
Markov chain and hidden Markov model are probably the simplest models which can be used to model
sequential data, i.e. data samples which are not independent from each other.
Markov Chain
Let I be a countable set. Each i ∈ I is called a state and I is called the state-space. Without loss
of generality we assume I = {1, 2, . . .}, and in most cases we have I a finite set and use P
the notation
I = {1, 2, . . . , k} or I = {S1 , S2 , . . . , Sk }. λ is said to be a distribution on I if 0 ≤ λi < ∞ and i∈I λi = 1.
Definition 1.1. A matrix T ∈ Rk×k is stochastic if each row of T is a probability distribution.
One example of a stochastic matrix is
T =
1−α
β
α
1−β
with α, β ∈ [0, 1]. Figure 1 shows another example of a transition matrix on I = {S1 , S2 , S3 } using finite
state machine.
Figure 1. Finite state machine for a Markov chain X0 → X1 → X2 → · · · → Xn where
the random variables Xi ’s take values from I = {S1 , S2 , S3 }. The numbers T (i, j)’s on the
arrows are the transition probabilities such that Tij = P (Xt+1 = Sj |Xt = Si ).
Definition 1.2. We say that (Xn )n≥0 is a Markov chain with initial distribution λ and transition matrix
T if
(i) X0 has distribution λ;
(ii) for n ≥ 0, conditional on Xn = i, Xn+1 has distribution (Tij : j ∈ I) and is independent of X0 , . . . , Xn−1 .
By the Markov property we have
(1)
P (X0 , . . . , Xn ) =
(2)
=
P (X0 )P (X1 |X0 ) · · · P (Xn |X0 , . . . , Xn−1 )
n
Y
P (X0 )
P (Xt |Xt−1 )
t=1
1
englishMARKOV CHAIN AND HIDDEN MARKOV MODEL
2
which greatly simplifies the joint distribution of X0 , . . . , Xn . Note also that in our definition the process is
homogeneous, i.e. we have P (Xt = Sj |Xt−1 = Si ) = Tij which does not depend on t.
Assume that X takes values from X = {S1 , . . . , Sk }, the behavior of the process can then be described
by a transition matrix T ∈ Rk×k where we have Tij = P (Xt = Sj |Xt−1 = Si ). The set of parameters Θ for
a Markov chain is Θ = {λ, T }.
Graphical Model for Markov Chain.
The Markov chain X0 , . . . , Xn can be represented in terms of a graphical model, where each node represents
a random variable, and the edges indicate conditional dependence structure. Graphical model is a very useful
tool to visualize probabilistic models as well as to design efficient inference algorithms.
Figure 2. Graphical Model for Markov Chain
Random Walk on Graphs.
The behavior of a Markov chain can also be described as a random walk on the graph shown in Figure 1.
Initially a vertice is chosen according to the initial distribution λ and is denoted as SX0 ; at time t the current
position is SXt and the next vertice is chosen with respect to the probability TXt ,. , the Xt -th row of the
transition matrix T .
Many properties of Markov chain can be identified by studying λ and T . For example, the distribution
of X0 is determined by λ, while the distribution of X1 is determined by λT 1, etc.
Hidden Markov Model
A hidden Markov model is an extension of a Markov chain which is able to capture the sequential relations
among hidden variables. Formally we have Zt = (Xt , Yt ) for t = 0, 1, . . . , n with Xt ∈ I and Yt ∈ O =
{O1 , . . . , Ol } such that the joint probability of Z0 , . . . , Zn can be factorized as:
n
Y
(3)
P (Z0 , . . . , Zn ) = [P (X0 )P (Y0 |X0 )]
[P (Xt |Xt−1 )P (Yt |Xt )]
t=1
(4)
=
"
P (X0 )
n
Y
t=1
#"
P (Xt |Xt−1 )
n
Y
t=0
#
P (Yt |Xt ) .
In other words, the X0 , . . . , Xn is a Markov chain and Yt is independent of all other variables given Xt . The
set of parameters for a HMM Θ = {λ, T, Γ} where Γ ∈ Rk×l is defined as Γij = P (Yt = Oj |Xt = Si ). If
P (Yt |Xt ) is assumed to be a Multinomial distribution, then the total number of parameters for a HMM is
(k − 1) + k(k − 1) + k(l − 1). Figure 3 shows the graphical model for HMM, from which we can easily see
the conditional independence structure of all variables (X0 , Y0 ), . . . , (Xn , Yn ).
Figure 3. Graphical Model for Hidden Markov Model
1We assume λ ∈ R1×k to be a row vector.
englishMARKOV CHAIN AND HIDDEN MARKOV MODEL
3
HMM is suitable for situations where the observed sequences Y0 , . . . , Yn are influenced by a hidden Markov
chain X0 , . . . , Xn . For example, in speech recognition, we observe the phoneme sequences Y0 , . . . , Yn . The
sequence of Y0 , . . . , Yn can be thought as noisy observations of the underlying words X0 , . . . , Xn . In this
case, we would like to infer the unknown words based on the observation sequence Y0 , . . . , Yn .
Three Fundamental Problems in HMM
There are three basic problems of interest for the hidden Markov model:
• Problem 1 : Given an observation sequence y0 y1 . . . yn and the model parameters Θ = {λ, T, Γ}, how
to efficiently compute P (Y = y|Θ) = P (Y0 = y0 , . . . , Yn = yn |Θ), the probability of the observation
sequence given the model?
• Problem 2 : Given an observation sequence y0 y1 . . . yn and the model parameters Θ = {λ, T, Γ}, how
to find the optimal sequence of states x0 x1 . . . xn in the sense of maximizing P (X = x|Θ, Y = y) =
P (X0 = x0 , . . . , Xn = xn |Θ, Y0 = y0 , . . . , Yn = yn )?
• Problem 3 : How to estimate the model parameters Θ = {λ, T, Γ} by maximizing P (Y = y|Θ)?
Forward-Backward Algorithm.
The solution of problem 1 can be computed as
P (Y = y|Θ)
X
=
P (X = x|Θ)P (Y = y|Θ, X = x)
x
(5)
=
XX
x0
···
x1
X
xn
"
P (X0 = x0 )
n
Y
P (Xt = xt |Xt−1 = xt−1 )
t=1
n
Y
#
P (Yt = yt |Xt = xt )
t=0
However, the total number of possible hidden sequences x is large and thus direct computation is very
expensive. Intuitively, we want to move some of the sums inside the product to reduce the computation.
The basic idea of the forward algorithm is as follows. First, the forward variable αt (i) is defined by
(6)
αt (i) = P (y0 , . . . , yt , Xt = Si )
is the probability of observing a partial sequence y0 , . . . , yt and ending up in state Si . We have
(7)
(8)
αt+1 (i) =
=
(9)
(10)
=
=
(11)
=
P (y0 , . . . , yt+1 , Xt+1 = Si )
P (Xt+1 = Si )P (y0 , . . . , yt+1 |Xt+1 = Si )
P (Xt+1 = Si )P (yt+1 |Xt+1 = Si )P (y0 , . . . , yt |Xt+1 = Si )
P (yt+1 |Xt+1 = Si )P (y0 , . . . , yt , Xt+1 = Si )
X
P (y0 , . . . , yt , Xt = xt , Xt+1 = Si )
P (yt+1 |Xt+1 = Si )
xt
(12)
=
P (yt+1 |Xt+1 = Si )
X
P (Xt+1 = Si |Xt = xt )P (y0 , . . . , yt , Xt = xt )
xt
(13)
=
Γi,yt+1
k
X
Tj,i αt (j).
j=1
Initially we have α0 (i) = λi Γi,y0 and the final solution is
(14)
P (Y = y|Θ) =
k
X
αn (i).
i=1
The backward algorithm can be constructed similarly by defining the backward variable
βt (i) = P (yt+1 , . . . , yn |Xt = Si ).
englishMARKOV CHAIN AND HIDDEN MARKOV MODEL
4
Viterbi Algorithm.
The solution of problem 2 can be written as
x∗
(15)
=
arg max P (X = x|Y = y, Θ)
=
arg max P (X = x, Y = y, Θ).
x
(16)
x
A formal technique for finding the best state sequence x∗ based on dynamic programming is known as the
Viterbi algorithm. Define the quantity
(17)
δt (i) =
max
x0 ,...,xt−1
P (x0 , . . . , xt−1 , Xt = Si , y0 , . . . , yt |Θ),
which is the highest probability along a single path at time t ending at state Si . We have
(18)
δt+1 (j) =
(19)
=
max {δt (i)P (Xt+1 = Sj |Xt = Si )P (Yt+1 = yt+1 |Xt+1 = Sj )}
i
max δt (i)Tij Γj,yt+1 .
i
Initially we have δ0 (i) = λi Γi,y0 and the final highest probability is P ∗ = maxSi ∈I δn (i). To find the optimal
sequence x∗ we need to define some auxiliary variables ψt+1 (j) which stores the optimal path:
(20)
ψt+1 (j) = arg max δt (i)Tij Γj,yt+1 = arg max {δt (i)Tij } ,
i
i
for t = 1, 2, . . . , n. The final optimal path can be traced back by using x∗n = arg maxi δn (i) and x∗t =
ψt+1 (x∗t+1 ) for t = n − 1, . . . , 0.
Baum-Welch Algorithm.
Let Θ = (λ, T, Γ) represent all of the parameters of the HMM model. Given m observation sequences
y1 , . . . , ym , the parameters can be estimated by maximizing the (log)-likelihood:
m
Y
(21)
p(Y = yl |Θ)
Θ̂ = arg max
Θ
(22)
l=1
= arg max
Θ
(23)
m
X
log p(Y = yl |Θ)
l=1
= arg max
Θ
m
X
log
l=1
X
x0
···
X
λx0
xnl
nl
Y
Txt ,xt+1
t=1
nl
Y
Γxt ,ytl
t=0
.
In principle, the above equation can be maximized using standard numerical optimization methods to find
Θ̂. In practice, the above estimation is often solved by the well-known Baum-Welch algorithm, which is a
special case of the Expectation Maximization (EM) algorithm. Details will be discussed after we introduce
the EM algorithm.
Learning with (x, y).
There are often cases where we are able to know both the state sequences and the observation sequences.
That is, given m pairs of sequences (x1 , y1 ), . . . , (xm , ym ), we want to estimate parameters λ, T and Γ. Since
the state sequences are observed (and thus the summation over x is not needed any more), the maximum
likelihood estimation Θ̂ can be computed easily in this case:
m
X
(24)
log p(Y = yl , X = xl |Θ)
Θ̂ = arg max
Θ
(25)
=
arg max
Θ
(26)
=
arg max
Θ
l=1
m
X
(
log λxl0
l=1
(m
X
l=1
nl
Y
Txlt ,xlt+1
t=1
log λxl0 +
nl
m X
X
l=1 t=1
nl
Y
t=0
Γxlt ,ytl
)
log Txlt ,xlt+1 +
nl
m X
X
l=1 t=0
log Γxlt ,ytl
)
which is straightforward to solve by adding the constraints that λ and each row of T and Γ are probability
distributions.
englishMARKOV CHAIN AND HIDDEN MARKOV MODEL
5
Discussion
HMM has been applied to many applications such as speech recognition, robotics, bio-informatics, etc,
and it is also the simplest example of what is known as Dynamic Bayesian Networks (DBN) or directed
graphical models. More complicated models (generalizations of HMM) include: factorial HMM, HMM
decision trees, etc. Other related models include Conditional Random Field (CRF) which is a member of
undirected graphical models.
References
[1] J. Norris. Markov Chains. Cambridge University Press, 1997.
[2] M. Jordan. An Introduction to Graphical Models. unpublished manuscript, 2001.
[3] L. Rabiner. A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the
IEEE, 77(2), 1989.