AP Statistics: Confidence Intervals & Hypothesis Tests Summary
advertisement

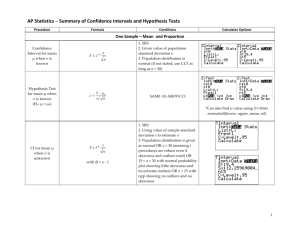
AP Statistics – Summary of Confidence Intervals and Hypothesis Tests Procedure Formula Conditions Calculator Options One Sample – Mean and Proportion Confidence Interval for mean µμ when σ is known ! ±" ! ! # 1. SRS 2. Given value of population standard deviation σ 3. Population distribution is normal (if not stated, use CLT as long as n > 30) Hypothesis Test for mean µμ when σ is known (Ho: µμ = µμo) CI for mean µμ when σ is unknown != " !µ# ! $ ! ±" ! # $ with df = n -­‐‑ 1 SAME AS ABOVE CI *Can also find p-­‐‑value using 2nd-­‐‑Distr normalcdf(lower, upper, mean, sd) 1. SRS 2. Using value of sample standard deviation s to estimate σ 3. Population distribution is given as normal OR n > 30 (meaning t procedures are robust even if skewness and outliers exist) OR 15 < n < 30 with normal probability plot showing little skewness and no extreme outliers OR n < 15 with npp showing no outliers and no skewness 1 AP Statistics – Summary of Confidence Intervals and Hypothesis Tests Procedure Formula Conditions Calculator Options One Sample – Mean and Proportion – Continued Test for mean µμ when σ is unknown (Ho: µμ = µμo) CI for proportion p " !µ# $ % != SAME AS ABOVE CI with df = n -­‐‑ 1 pˆ ± z * *Can also find p-­‐‑value using 2nd-­‐‑Distr tcdf(lower, upper, df) pˆ (1 -­‐ pˆ ) n 1. SRS 2. Population is at least 10 times n 3. Counts of success npˆ and failures n(1 -­‐ pˆ ) are both at least 10 (these counts verify the use of the normal approximation) Test for proportion p (Ho: p = po) z= pˆ -­‐ po po (1 -­‐ po ) n 1. SRS 2. Population is at least 10 times n 3. Counts of success npo and failures n(1 -­‐ po ) are both at least 10 (these counts verify the use of the normal approximation) *Can also find p-­‐‑value using 2nd-­‐‑Distr normalcdf(lower, upper, mean, sd) 2 AP Statistics – Summary of Confidence Intervals and Hypothesis Tests Procedure Formula Conditions Calculator Options Two Samples – Means and Proportions CI for mean µμ1-­‐‑µμ2 when σ is unknown Test for mean µμ 1-­‐‑ µμ2 when σ is unknown (Ho: µμ1 = µμ2) ( x1 -­‐ x2 ) ± t * s12 s22 + n1 n2 with df read from calculator or use conservative estimate that df = n – 1 where n is the smaller of n1 or n2 t= ( x1 -­‐ x2 ) s12 s22 + n1 n2 1. Populations are independent 2. Both samples are from SRSs 3. Using value of sample standard deviation s to estimate σ 4. Population distributions are given as normal OR n1 + n2 > 30 (meaning t procedures are robust even if skewness and outliers exist) OR 15 < n1 + n2 < 30 with normal probability plots showing little skewness and no extreme outliers OR n1 + n2 < 15 with npps showing no outliers and no skewness SAME AS ABOVE CI *Can also find p-­‐‑value using 2nd-­‐‑Distr tcdf(lower, upper, df) where df is either conservative estimate or value using long formula that calculator does automatically! with df read from calculator 3 AP Statistics – Summary of Confidence Intervals and Hypothesis Tests Procedure Formula Conditions Calculator Options Two Samples – Means and Proportions – Continued != Test for proportion p1 – p2 ! ""# ! "" $ % "# # %' $ ""# !#! ""# %$$ + '' # $# $$ '& where pˆ c = 1-­‐‑3 are SAME AS ABOVE CI 4. Counts of success n1 pˆ c and n2 pˆ c and failures n1 (1-­‐ pˆ c ) and n2 (1-­‐ pˆ c ) are all at least 5 (these counts verify the use of the normal approximation) x1 + x2 n1 + n2 *Can also find p-­‐‑value using 2nd-­‐‑Distr normalcdf(lower, upper, mean, sd) where mean and sd are values from numerator and denominator of the formula for the test statistic Categorical Distributions "! ! " #! " G. of Fit (GOF) – 1 sample, 1 variable Independence – 1 sample, 2 variables Homogeneity – 2 samples, 2 variables (GOF) df = # categories – 1 (Independence/Homogeneity) df = (# rows – 1) (# columns – 1) !! = " Chi Square Test 1. All expected counts are at least 1 2. No more than 20% of expected counts are less than 5 *Can also find p-­‐‑value using 2nd-­‐‑Distr x2cdf(lower, upper, df) 4 AP Statistics – Summary of Confidence Intervals and Hypothesis Tests Procedure Formula Conditions Calculator Options Slope b ± t * sb where !" = CI for β Test for β ! " ! # ! # "# 1. For any fixed x, y varies according to a normal distribution 2. Standard deviation of y is same for all x values ! " # # ! #$ %" " !" with df = n -­‐‑ 2 and ! = t= b with df = n – 2 sb SAME AS ABOVE CI *You will typically be given computer output for inference for regression Variable Legend – here are a few of the commonly used variables Variable µμ σ x s z Meaning population mean mu population standard deviation sigma sample mean x-­‐‑bar sample standard deviation test statistic using normal distribution Variable CLT SRS npp p p̂ Meaning Central Limit Theorem Simple Random Sample Normal Probability Plot (last option on stat plot) population proportion sample proportion p-­‐‑hat z* critical value representing confidence level C pˆ c combined (pooled) sample proportion for two proportion z test t test statistic using t distribution t* n critical value representing confidence level C (e.g., 95%) sample size Matched Pairs – same as one sample procedures but one list is created from the difference of two matched lists (i.e. pre and post test scores of left and right hand measurements) Conditions – show that they are met (i.e. substitute values in and show sketch of box plot or npp) ... don’t just list them 5